
データセットにテキストドキュメントが含まれ、テキスト分類子をトレーニングするためにラベルが使用される場合、 テキスト分類はNLPおよび教師による指導で最も一般的なタスクの1つです。
NLPの観点から、テキストを分類するタスクは、単語の埋め込みを使用して単語レベルの表現をトレーニングし、次に分類の関数として使用されるテキストレベルの表現をトレーニングすることによって達成されます。
コーディングベースの方法のタイプでは、分類のための小さな詳細とキーは無視されます(テキストレベルでの一般的な表現は、単語レベルで表現を圧縮することによって研究されるため)。
テキストレベルのマッチングを使用したエンコーディングベースのテキスト分類方法
EXAM-新しいテキスト分類方法
山東大学とシンガポール国立大学の研究者は、テキスト分類タスクに単語レベルのマッチング信号を含む新しいテキスト分類モデルを提案しました 。 彼らの方法は、相互作用メカニズムを使用して、単語レベルで詳細なヒントを分類プロセスに導入します。
より正確な単語レベルのマッチング信号を含めるという問題を解決するために、研究者は、単語とクラス間の対応推定値を明示的に計算することを提案しました 。
基本的な考え方は、単語レベルで対応するキーを保持する単語レベルの表現から相互作用行列を計算することです。 このマトリックスの各エントリは、単語と特定のクラス間の対応の評価です。
EXAM-EXplicit interAction Model( GitHub )と呼ばれる提案されたテキスト分類構造には、3つの主要なコンポーネントが含まれています。
- ワードレベルエンコーダ、
- 相互作用層
- 集約層。
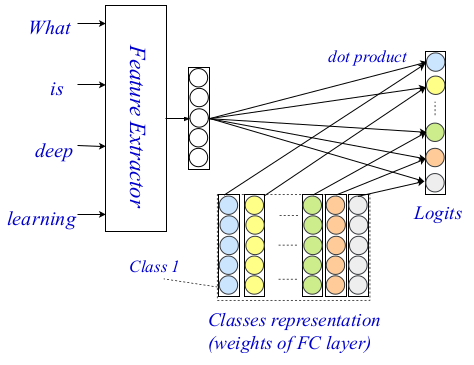
この3層アーキテクチャにより、小さく一般的な信号とヒントの両方を使用してテキストをエンコードおよび分類できます。 アーキテクチャ全体を以下の画像に示します。

EXAMアーキテクチャ
過去には、NLPコミュニティでワードレベルのエンコーダーが広く研究されており、非常に強力なエンコーダーが登場しました。 著者は、単語レベルでエンコーダとしてsovermennyメソッドを使用し、彼らの研究では、彼らのアーキテクチャの他の2つのコンポーネントである対話レベルと集約レベルを詳細に説明します。
提案された方法の相互作用層、主な貢献、および新規性は、よく知られている相互作用メカニズムに基づいています。 研究者は、 トレーニング済みのプレゼンテーションマトリックスを使用して各クラスをエンコードし、後でクラス間の相互作用の推定値を計算できるようにします。 最終スコアは、対象の単語と各クラス間の相互作用の関数として点積を使用して付けられます。 計算の複雑さが増したため、より複雑な関数は考慮されませんでした。
レイヤーの視覚化
最後に、シンプルで完全に接続された2層MLPを集約層として使用します。 また、CNNやLSTMなど、より複雑なレベルの集約をここで使用できることも言及しています。 MLPは、相互作用行列と単語レベルのエンコードを使用して最終的な分類ロジットを計算するために使用されます。 クロスエントロピーは、最適化のために損失の関数として使用されます。
成績
テキスト分類のために提案されたフレームワークを評価するために、研究者はマルチクラスおよびマルチタグ条件の両方で広範な実験を実施しました。 彼らは彼らの方法が現代の関連する現代の方法よりはるかに優れていることを示しています。
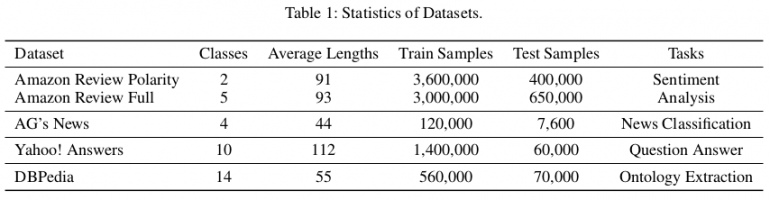
評価に使用されたデータセットの統計
評価するために、3つの異なる基本タイプのモデルを確立します。
- 属性の開発に基づくモデル。
- 深いキャラクターベースのモデル
- 深い単語ベースのモデル。
著者らは、公開されている参照データセット(Zhang、Zhao、およびLeCun 2015)を使用して、提案された方法を評価しました。 合計で、気分の分析、ニュース、質問と回答の分類、およびオントロジーの抽出のタスクにそれぞれ対応する6セットの分類テキストデータがあります。 この記事では、EXAMがAG、Yahという3つのデータセットの中で最高のパフォーマンスを達成していることを示しています。 A.およびDBP。 評価と他の方法との比較は、以下の表で見ることができます。
![マルチクラスドキュメント分類タスクのテストセット精度[%]および他の方法との比較](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

結論
この作業は、自然言語処理(NLP)の分野への重要な貢献です。 これは、より正確な単語レベルの一致プロンプトをディープニューラルネットワークモデルのテキスト分類に導入する最初の作業です。 提案されたモデルは、複数のデータセットの最新のメトリックを提供します。
翻訳-スタニスラフ・リトヴィノフ