WCDの簡単な図:
データの品質に対する信頼を確保するには、定期的な調整プロセスが必要であることを理解しました。 もちろん、各技術レベルで自動化され、データの品質とその収束を垂直および水平の両方で確認できるようになっています。 その結果、さまざまなベンダーの調整を管理するための3つの既成プラットフォームを同時にレビューし、独自のプラットフォームを作成しました。 この投稿で経験を共有します。
完成したプラットフォームのマイナス面は誰にでも知られています:価格、柔軟性の制限、機能を追加および修正する能力の欠如。 長所-MDMパーツ(ゴールドデータなど)、トレーニング、サポートも終了します。 これに感謝して、すぐに購入を忘れて、ソリューションの開発に集中しました。
私たちのシステムの中核はPythonで書かれており、結果を保存、記録、保存するためのメタデータデータベースはOracleにあります。 Pythonには多くのライブラリがあり、Hive(pyhive)、GreenPlum(pgdb)、Oracle(cx_Oracle)接続に最低限必要なものを使用します。 別のタイプのソースを接続しても問題になりません。
結果のデータセット(結果セット)を結果テーブルOracleに入れ、外出中に調整のステータス(SUCCESS / ERROR)を評価します。 APEXは、結果の視覚化が構築される結果のテーブルで構成され、メンテナンスと管理の両方に便利です。
リポジトリでチェックを実行するには、データをダウンロードするInformaticaオーケストラが使用されます。 ダウンロード成功ステータスを受信すると、このデータは自動的に検証され始めます。 クエリのパラメーター化とWCDメタデータを使用すると、テーブルセットに対してクエリ調整テンプレートを使用できます。
次に、このプラットフォームに実装された調整について説明します。
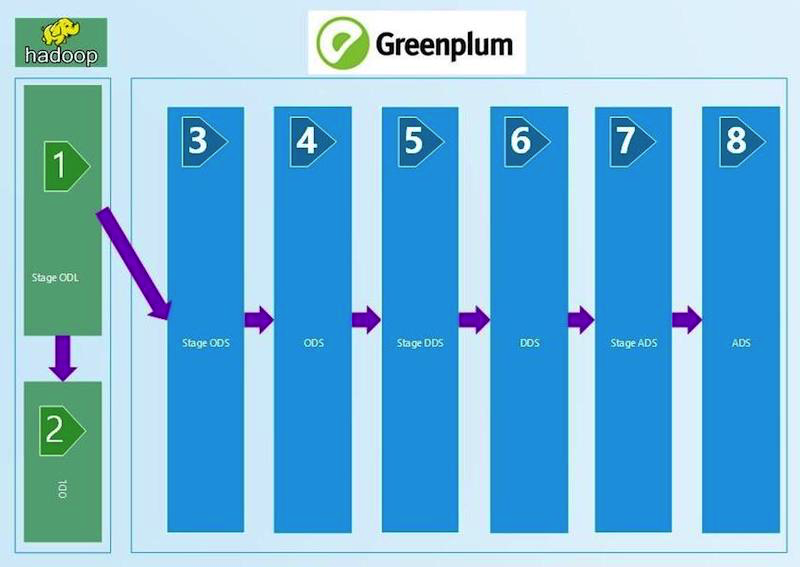
WCDの入力とレイヤーのデータ量を特定のフィルターの適用と比較する、技術的な調整から始めました。 WCD入力に送られたctlファイルを取得し、そこからレコード数を読み取り、ステージODLおよび/またはステージODS(図の1、2、3)上のテーブルと比較します。 検証基準は、レコード数(カウント)が等しいことで定義されます。 数量が収束した場合、結果はSUCCESS、no-ERRORおよびエラーの手動分析になります。
この一連の技術的な調整は、レコードの数と比較して、ADSレイヤー(図の8)まで拡張されます。 フィルターはレイヤー間で変更されます。これは、ロードの種類(DIM(リファレンスブック)、HDIM(履歴リファレンスブック)、FACT(実際の発生表)など)、およびSCDとレイヤーのバージョンによって異なります。 表示層に近いほど、より高度なフィルタリングアルゴリズムが使用されます。
Pythonの入力に対しても技術チェックが実行され、キーフィールドの重複が検出されました。 GreenPlumでは、データベースシステムツールによってキーフィールド(PK)が重複から保護されていません。 そこで、PKメタデータからロードされたテーブルのフィールドを読み取り、それらの重複をチェックするSQLスクリプトを生成するPythonスクリプトを作成しました。 このアプローチの柔軟性により、1つまたは複数のフィールドで構成されるPKを使用できます。これは非常に便利です。 このような調整は、STG ADSレイヤーにまで及びます。
unique_check import sys import os from datetime import datetime log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") def do_check(args, context): tab = args[0] data = [] fld_str = "" try: sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn FROM src_column@meta_data WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,) for fld in context['ora_get_data'](context['ora_con'], sql): fld_str = fld_str + (fld_str and ",") + fld[1] if fld_str: config = context['script_config'] con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname']) sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq; """ % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str ) data.extend(context['pg_get_data'](con_gp, sql)) con_gp.close() except Exception as e: raise return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]] if __name__ == '__main__': sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))
一意性調整Pythonコードの例。 呼び出し、接続パラメーターの転送、および結果の結果テーブルへの格納は、Pythonの制御モジュールによって実行されます。
NULL値がない場合の調整は、前のものと同様に構築され、Pythonでも行われます。 空の(NULL)値を持つことができないロードメタデータフィールドから読み取り、それらの完全性をチェックします。 調整は、DDSレイヤーの前に使用されます(最初の図の6)。
ストレージへの入り口では、入力に到着するデータパケットの傾向分析も実装されます。 新しいパッケージが到着したときに受信したデータの量は、履歴テーブルに入力されます。 データの量が大幅に変化すると、テーブルとSI(ソースシステム)の責任者は(計画で)メールで通知を受け取り、データパケットがウェアハウスに入る前にAPEXでエラーを確認し、SIでこの理由を見つけます。
STG(STAGE)_ODSとODS(オペレーションデータレイヤー)(図の3と4)の間に、技術的な削除フィールドが表示され(削除インジケーター= deleted_ind)、SQLクエリを使用してその正確性もチェックします。 欠落した入力は、ODSで削除済みとしてマークする必要があります。
調整スクリプトの結果は、エラーがゼロになると予想されます。 提示された調整の例では、パラメーター〜#PKG_ID#〜はPython制御ブロックを介して渡され、タイプ〜P_JOIN_CONDITION〜および〜PERIOD_COL〜のパラメーターはテーブルメタデータから読み込まれ、テーブル名自体は起動パラメーターから〜TABLE〜が読み込まれます。
以下はパラメータ化された調整です。 タイプHDIMのSTG_ODSとODS間のSQL調整コードの例:
select package_id as pkg_id, 'T_~TABLE~' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.T_~TABLE~ src left join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y' where ~#PKG_ID#~ = 0 or src.package_id = ~#PKG_ID#~ ) aa, (select sum (case when src.~PK~ is null then 1 else 0 end) as not_deleted_in_ods, max (tgt.load_dttm) as max_load_dttm from EDW_STG_ODS.T_~TABLE~ src right join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ where tgt.deleted_ind = 0 and tgt.active_ind ='Y' and tgt.~PERIOD_COL~ between (select min(~PERIOD_COL~) from EDW_STG_ODS.T_~TABLE~ where ~#PKG_ID#~ = 0 or package_id = ~#PKG_ID#~) and (select max(~PERIOD_COL~) from EDW_STG_ODS.T_~TABLE~ where ~#PKG_ID#~ = 0 or package_id = ~#PKG_ID#~) ) bb where 1=1
パラメーターが置換されたHDIMタイプのSTG_ODSとODS間のSQL調整コードの例:
--------------HDIM_CHECKS--------------- select package_id as pkg_id, 'TABLE_NAME' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.ACTION_ID is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.TABLE_NAME src left join EDW_ODS.TABLE_NAME tgt on SRC.PK_ID=TGT.PK_ID and tgt.active_ind ='Y' where 709083887 = 0 or src.package_id = 709083887 ) aa, (select sum (case when src.PK_ID is null then 1 else 0 end) as not_deleted_in_ods, max (tgt.load_dttm) as max_load_dttm from EDW_STG_ODS.TABLE_NAME src right join EDW_ODS.TABLE_NAME tgt on SRC.PK_ID =TGT.PK_ID where tgt.del_ind = 0 and tgt.active_ind ='Y' and tgt.DATE_SYS between (select min(DATE_SYS) from EDW_STG_ODS.TABLE_NAME where 70908 = 0 or package_id = 70908) and (select max(DATE_SYS) from EDW_STG_ODS.TABLE_NAME where 70908 = 0 or package_id = 70908) ) bb where 1=1
ODS以降、履歴はディレクトリに保持されるため、交差点やギャップがないかどうかを確認する必要があります。 これは、履歴内の不正な値の数をカウントし、結果のテーブルに結果のエラー数を書き込むことで実行されます。 テーブルに履歴エラーがある場合は、手動で検索する必要があります。 調整は、ダウンロードの種類-HDIM(履歴リファレンスガイド)に依存します。 ディレクトリの履歴の正確性をADSレイヤーに調整します。
DDSレイヤー(最初の図の6)では、異なるSI(ソースシステム)が1つのテーブルに結合され、異なるソースシステムからのデータをリンクするための代理キーを生成するためのHUBテーブルが表示されます。 stage-layerと同様のpython-checkを使用して、一意性を確認します。
DDSレイヤーでは、HUBテーブルと結合した後、キーフィールドにタイプ0、-1、-2の値が表示されなかったことを確認する必要があります。これは、テーブルの不正確なマージ、データの不足を意味します。 HUBテーブルに必要なデータがない場合に表示される可能性があります。 そして、これは手動解析の間違いです。
ADSショーケースレイヤーのデータの最も複雑な調整(最初の図の8)。 得られた結果の収束における完全な信頼のために、発生額の集計のためのソースシステムによる検証がここに展開されます。 一方では、累積発生額を含む指標のクラスがあります。 WCDのウィンドウから1か月分収集します。 一方、ソースシステムから同じ料金の集計を取得します。 1%以下の不一致または特定の合意された絶対値は許容されます。 調整によって取得された結果セットは、特別に作成されたデータセットに配置され、Oracleテーブルになります。 データの比較は、Oracleビューで行われます。 APEXでの結果の視覚化。 データセット全体(結果セット)が存在するため、エラーがある場合、結果の詳細なデータをより深く分析して分析し、矛盾が発生した特定の記事を見つけ、その理由を探すことができます。
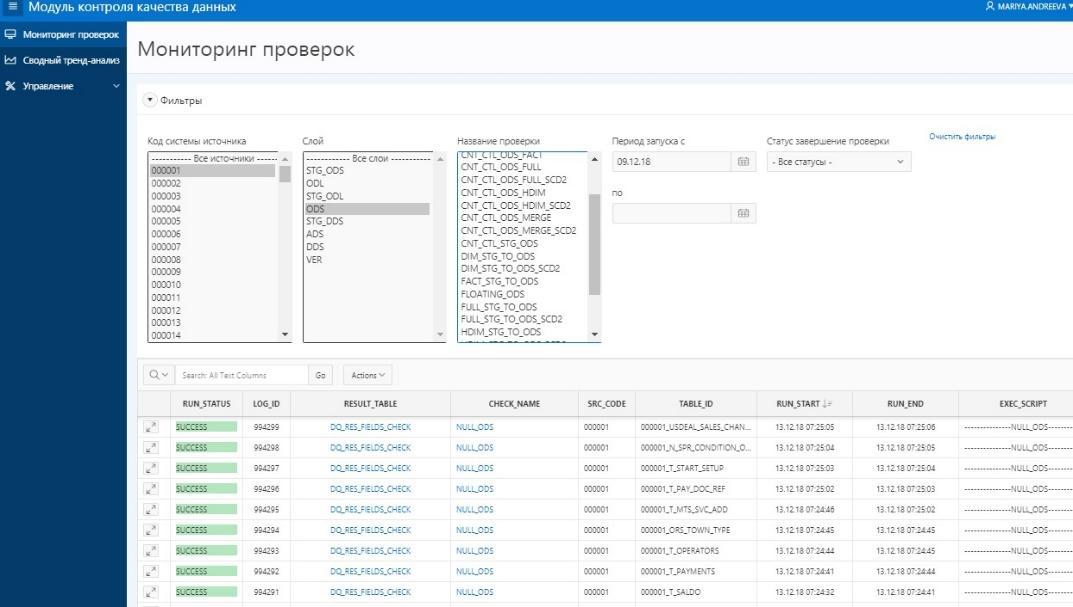
APEXでのユーザーへの調整結果の表示
現時点では、データを調整するための実用的で積極的に使用されているアプリケーションを取得しています。 もちろん、調整の量と質の両方、およびプラットフォーム自体の開発をさらに発展させる予定です。 独自の開発により、機能を十分に迅速に変更および修正できます。
この記事は、ロステレコムのデータ管理チームによって作成されました