ルイス・ボルヘスの バビロニア図書館からの引用から始めましょう。
引用
「宇宙-図書館と呼ばれることもある-巨大な、おそらく無限の数の六角形のギャラリーで構成され、幅の広い換気室が低いレールで囲まれています。 各六角形から、2つの上階と2つの下階が見えます-無限に。
「ライブラリは、正確な中心が六角形の1つにあるボールであり、表面にはアクセスできません。 各六角形の各壁には5つの棚があり、各棚には同じ形式の32冊の本があり、各本には410ページ、各ページには40行、各行には約80の黒文字があります。 本の背に文字がありますが、それらはページが言うことを定義したり、予知したりしません。 この矛盾は、かつては不可解であるように思えました。」
ランダムな六角形を入力し、任意の壁に移動し、任意の棚を見て、最も好きな本を取ると、あなたは動揺する可能性が最も高くなります。 結局のところ、あなたはそこでの人生の意味を知ることを期待していましたが、奇妙なキャラクターのセットを見ました。 しかし、そんなに早く動揺しないでください! 本のほとんどは、25文字のすべての可能なバリエーションの組み合わせ検索であるため、意味がありません( ボルゲスが彼のライブラリで使用したのはこのアルファベットですが、読者はライブラリに任意の数の文字があることがわかります )。 図書館の主な法則は、絶対に同一の本が2冊も存在しないため、その数は有限であり、図書館もいつかは終了するというものです。 ボルヘスは、図書館が定期的であると信じていました。
引用
「恐らく恐怖と老いが私を欺いているかもしれませんが、人類-唯一のもの-は絶滅に近づいており、図書館は生き残るだろうと考えています:照らされた、無人の、無限の、絶対に動かず、貴重なボリュームで満たされ、役に立たず、壊れず、神秘的です。 私は無限に書きました。 私はこの言葉を修辞学への愛からは設定しませんでした。 世界は無限だと仮定するのは理にかなっていると思います。 それが限られていると考える人は、廊下、階段、六角形のどこかが未知の理由で終わることができることを認めています-そのような仮定はばかげています。 境界なしにそれを想像する人は、可能な本の数が限られていることを忘れています。 この古くからある問題に対するこのような解決策を提案することを敢えてします。ライブラリは無限であり、定期的です。 永遠の放浪者があらゆる方向への旅に出た場合、彼は何世紀も後に同じ本が同じ混乱で繰り返されることを確認することができます(繰り返されると秩序になります-秩序)。 この優雅な希望は私の孤独を明るくします。」
ナンセンスと比較して、人が少なくとも何らかの形で内容を理解できる本はほとんどありませんが、これは図書館が人が発明したすべてのテキストを含むという事実を変更しません。 さらに、子供の頃から、シンボルのシーケンスには意味があるものとそうでないものを考慮することに慣れています。 実際、ライブラリのコンテキストでは、それらの間に違いはありません。 しかし、理にかなっているもののパーセンテージははるかに低く、それを言語と呼びます。 これは人々の間のコミュニケーションの手段です。 どの言語にも数万個の単語しか含まれておらず、そのうちの70%が強度を知っているため、書籍の組み合わせ検索のほとんどを解釈できないことがわかります。 そして、誰かがアポフェニアに苦しみ、ランダムなキャラクターのセットでさえ隠された意味を見ます。 しかし、これはステガノグラフィにとっては良い考えです! さて、私はコメントでこのトピックについて議論し続けています。
このライブラリの実装に進む前に、興味深い事実に驚かされます:Louis Borgesのバビロニアライブラリを再作成する場合、そのボリュームは目に見えるUniverse 10 ^ 611338(!)Timesのボリュームを超えるため、成功しません。 さらに大きなライブラリで何が起こるかについて、私は考えることさえ怖いです。
ライブラリの実装
モジュールの説明
ちょっとした紹介は終わりました。 しかし、それは意味がないわけではありません。今、あなたはバビロニアの図書館がどのようなものであるかを理解し、読むことはより興味深いだけです。 しかし、私は元のアイデアから逃げ、「ユニバーサル」ライブラリを作成したかったのです。これについては後で説明します。 Node.jsの下にJavaScriptを記述しますが、ライブラリは何ができますか?
- 目的のテキストをすばやく見つけて、ライブラリ内の場所を表示します
- 本のタイトルを定義する
- 適切なタイトルの本をすばやく見つける
さらに、それは普遍的、すなわち ライブラリパラメータは、必要に応じて変更できます。 さて、最初にモジュールのコード全体を表示し、詳細に分析し、それがどのように機能するかを確認し、いくつかの言葉を話すと思います。 Githubリポジトリ
メインファイルはindex.jsで、ライブラリのロジック全体が記述されています。このファイルの内容について説明します。
let sha512 = require(`js-sha512`);
sha512ハッシュアルゴリズムを実装するモジュールを接続します。 あなたには奇妙に思えるかもしれませんが、それでも私たちにとって有用です。
モジュールの出力は何ですか? 関数を返します。呼び出しは、必要なすべてのメソッドを含むライブラリオブジェクトを返します。 すぐに返すことはできますが、関数にパラメーターを渡して「必要な」ライブラリを取得する場合、ライブラリの管理はそれほど便利ではありません。 これにより、「ユニバーサル」ライブラリを作成できます。 ES6スタイルで記述しようとするので、私の矢印関数はパラメーターとしてオブジェクトを受け入れます。その後、オブジェクトは必要な変数に分解されます。
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { // ... };
次に、パラメーターを調べます。 標準的な数値パラメーターとして、私は素数を選択することにしました。
- lengthOfPage-数、1ページの文字数。 デフォルトは4819です。この数を因数分解すると、61と79が得られます。79文字の61行、またはその逆ですが、最初のオプションを好みます。
- lengthOfTitle-数、本のタイトルのタイトルの文字数。
- digs-文字列、この文字列の長さに等しい底を持つ数字の可能な数字。 この番号は何のためですか? これには、移動先の六角形の番号(識別子)が含まれます。 デフォルトでは、小文字のラテン語と0〜9の数字です。 ほとんどのテキストはここでエンコードされるため、数千ビット(ページ上の文字数に応じて)になりますが、文字ごとに処理されます。
- アルファベット -文字列、ライブラリに表示する文字。 それらで満たされます。 すべてが正しく機能するためには、アルファベットの文字数は、六角形を識別する数字の可能な桁数の行の文字数と等しくなければなりません。
- wall-番号、最大壁番号、デフォルト5
- シェルフ -番号、最大シェルフ番号、デフォルト7
- ボリューム -番号、最大ブック番号、デフォルトは31
- page-番号、最大ページ番号、デフォルト421
ご覧のとおり、これはルイス・ボルヘスの本物のバビロニア図書館に少し似ています。 しかし、私はそれらを見る方法になることができる「ユニバーサル」ライブラリを作成することをすでに何度も言っています(したがって、16進数は何らかの方法で解釈することができます、たとえば、目的のライブラリが格納されている場所の識別子だけ情報)。 バビロニアの図書館はその一つに過ぎません。 しかし、それらすべてには多くの共通点があります。1つのアルゴリズムがパフォーマンスを担当します。
ページ検索および表示アルゴリズム
あるアドレスに行くと、ページのコンテンツが表示されます。 同じアドレスに再度アクセスすると、コンテンツはまったく同じになります。 ライブラリのこのプロパティは、擬似乱数を生成するアルゴリズムを提供します- 線形合同法 。 アドレスを生成するためにキャラクターを選択する必要がある場合、または逆にページのコンテンツを作成する必要がある場合、それが役立ち、ページ数、棚などが穀物として使用されます。 私のPRNG構成:m = 2 ^ 32(4294967296)、a = 22695477、c =1。また、実装では、数値生成の原則のみが線形合同法から残り、残りは変更されることも追加したいと思います。 プログラムリストをさらに移動します。
コード
module.exports = ({ lengthOfPage = 4819, lengthOfTitle = 31, digs = '0123456789abcdefghijklmnopqrstuvwxyz', alphabet = ', .', wall = 5, shelf = 7, volume = 31, page = 421, } = {}) => { let seed = 13; // const rnd = (min = 1, max = 0) => { // // min max seed = (seed * 22695477 + 1) % 4294967296; // // return min + seed / 4294967296 * (max - min); // // }; const pad = (s, size) => s.padStart(size, `0`); // // let getHash = str => parseInt(sha512(str).slice(0, 7), 16); // const mod = (a, b) => ((a % b) + b) % b; // const digsIndexes = {}; // // digs const alphabetIndexes = {}; // // alphabet Array.from(digs).forEach((char, position) => { // digs digsIndexes[char] = position; // // }); Array.from(alphabet).forEach((char, position) => { // alphabet alphabetIndexes[char] = position; // // }); return { // };
ご覧のように、PRNGグレインは番号を受信するたびに変化し、結果はいわゆる参照ポイント(グレイン)に直接依存します。グレインはその後、数値が興味を持ちます。 (アドレスを生成するか、ページのコンテンツを取得します)
getHash関数は、参照ポイントの生成に役立ちます。 いくつかのデータからハッシュを取得し、7文字を取得し、10進数システムに変換するだけで完了です!
mod関数は、%演算子と同じように動作します。 ただし、配当が<0の場合(このような状況が発生する可能性があります)、 mod関数は特別な構造のため正の数を返します。アドレスでページのコンテンツを受信するときにアルファベット文字列から文字を正しく選択するためにこれが必要です。
そして、最後のデザートコードは返されたライブラリオブジェクトです。
コード
return { wall, shelf, volume, page, lengthOfPage, lengthOfTitle, search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random()* this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }, searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }, searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }, getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }, getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); } };
最初に、前に説明したライブラリのプロパティを書き込みます。 main関数が呼び出された後でも変更できます(原則として、コンストラクターと呼ばれますが、私のコードはライブラリのクラス実装に弱く似ているため、「main」という単語に限定します)。 おそらく、この動作は完全に適切ではなく、柔軟です。 次に、各メソッドを調べます。
検索方法
search(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random() * this.volume + 1 ^ 0)}`, 2), page = pad(`${(Math.random() * this.page + 1 ^ 0)}`, 3), locHash = getHash(`${wall}${shelf}${volume}${page}`), hex = ``, depth = Math.random() * (this.lengthOfPage - searchStr.length) ^ 0; for (let i = 0; i < depth; i++){ searchStr = alphabet[Math.random() * alphabet.length ^ 0] + searchStr; } seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]] || -1, rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}-${+page}`; }
ライブラリ内のsearchStr文字列のアドレスを返します。 これを行うには、 壁、棚、ボリューム、ページをランダムに選択します 。 ボリュームとページにもゼロが埋め込まれ、目的の長さになります。 次に、それらを文字列に連結してgetHash関数に渡します。 結果のlocHashは開始点、つまり 穀物。
予測不能性を高めるため、アルファベットの擬似ランダム文字でsearchStrの 深さを補い、シードシードをlocHashに設定します 。 この段階では、ラインをどのように補完するかは問題ではないため、組み込みのJavaScript PRNGを使用できます。これは重要ではありません。 拒否することもできますので、興味のある結果は常にページの上部に表示されます。
残っているのは、六角形の識別子を生成することだけです。 searchStr行の各文字に対して、アルゴリズムを実行します。
- alphabetIndexesオブジェクトからアルファベットのインデックス文字の番号を取得します。 そうでない場合は-1を返しますが、これが発生した場合は間違いなく何か間違ったことをしていることになります。
- PRNGを使用して、0からアルファベットの長さの範囲で擬似乱数randを生成します。
- 新しいインデックスを計算します。これは、シンボルインデックスの数と擬似乱数randの合計として計算され、 digsの長さを法として除算されます。
- したがって、六角形の識別子の桁-newChar ( digsから取得)を取得しました。
- newCharを16進数識別子16進数に追加します
16進数の生成が完了すると、目的の文字列が含まれている場所の完全なアドレスを返します。 アドレスコンポーネントはハイフンで区切られます。
SearchExactlyメソッド
searchExactly(text) { const pos = Math.random() * (this.lengthOfPage - text.length) ^ 0; return this.search(`${` `.repeat(pos)}${text}${` `.repeat(this.lengthOfPage - (pos + text.length))}`); }
このメソッドは、 検索メソッドと同じことをすべて行いますが、すべての空きスペースを埋めます( 検索文字列searchStrをlengthOfPage文字の長さにします)スペース。 そのようなページを表示すると、テキスト以外には何も表示されていないように見えます。
SearchTitleメソッド
searchTitle(searchStr) { let wall = `${(Math.random() * this.wall + 1 ^ 0)}`, shelf = `${(Math.random() * this.shelf + 1 ^ 0)}`, volume = pad(`${(Math.random()* this.volume + 1 ^ 0)}`, 2), locHash = getHash(`${wall}${shelf}${volume}`), hex = ``; searchStr = searchStr.substr(0, this.lengthOfTitle); searchStr = searchStr.length == this.lengthOfTitle ? searchStr : `${searchStr}${` `.repeat(this.lengthOfTitle - searchStr.length)}`; seed = locHash; for (let i = 0; i < searchStr.length; i++){ let index = alphabetIndexes[searchStr[i]], rand = rnd(0, alphabet.length), newIndex = mod(index + parseInt(rand), digs.length), newChar = digs[newIndex]; hex += newChar; } return `${hex}-${wall}-${shelf}-${+volume}`; }
searchTitleメソッドは、 searchStrという本の住所を返します。 内部では、 searchに非常に似ています 。 違いは、 locHashを計算するときに、ページを使用してその名前をブックにバインドしないことです。 ページに依存するべきではありません。 searchStrはlengthOfTitleに切り捨てられ、必要に応じてスペースが埋め込まれます。 同様に、六角形の識別子が生成され、受信したアドレスが返されます。 任意のテキストの正確なアドレスを検索するときのように、ページが存在しないことに注意してください。 したがって、あなたが発明した名前で本の内容を知りたい場合は、行きたいページを決めてください。
GetPageメソッド
getPage(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}${pad(addressArray[4], 3)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfPage) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfPage); }
検索方法の反対。 そのタスクは、ページのコンテンツを指定されたアドレスに戻すことです。 これを行うには、区切り文字「-」を使用してアドレスを配列に変換します。 これで、六角形の識別子、壁、棚、本、ページなどの住所コンポーネントの配列ができました。 locHashは、 検索メソッドで行ったのと同じ方法で計算します。 アドレスを生成したときと同じ番号を取得します。 これは、PRNGが同じ数値を生成することを意味します。ソーステキストに対する変換の可逆性を保証するのは、この動作です。 計算するには、六角形識別子の各シンボル(事実上、これは数字です)でアルゴリズムを実行します。
- 文字列digsの インデックスを計算します 。 digsIndexesから取得します。
- PRNGを使用して、0からこの美しい数字の数字を含む文字列の長さに等しい大きな数字の数体系の基数までの範囲の擬似乱数randを生成します。 すべてが明らかです。
- ソーステキストnewIndexの文字位置をindexとrandの差として計算し、アルファベットの長さを法として除算します。 差が負になる可能性があり、通常の除算モジュロは負のインデックスを与えますが、これは私たちには適さないため、モジュロ除算の修正バージョンを使用します。 (上記の式から絶対値を取得するオプションを試すことができます。これは負の数の問題も解決しますが、実際にはまだテストされていません)
- ページのテキストの文字はnewCharで、アルファベットからインデックスを取得します。
- 結果にテキスト文字を追加します。
この段階で得られた結果は常にページ全体を埋めるわけではないため、現在の結果から新しい粒子を計算し、アルファベットの文字で空のスペースを埋めます。 PRNGは、シンボルの選択に役立ちます。
これにより、ページコンテンツの計算が完了し、最大長にトリミングすることを忘れずに、それを返します。 おそらく、入力アドレスで六角形の識別子が不当に大きい可能性があります。
GetTitleメソッド
getTitle(address) { let addressArray = address.split(`-`), hex = addressArray[0], locHash = getHash(`${addressArray[1]}${addressArray[2]}${pad(addressArray[3], 2)}`), result = ``; seed = locHash; for (let i = 0; i < hex.length; i++) { let index = digsIndexes[hex[i]], rand = rnd(0, digs.length), newIndex = mod(index - parseInt(rand), alphabet.length), newChar = alphabet[newIndex]; result += newChar; } seed = getHash(result); while (result.length < this.lengthOfTitle) { result += alphabet[parseInt(rnd(0, alphabet.length))]; } return result.substr(result.length - this.lengthOfTitle); }
まあ、物語は同じです。 PRNGグレインの計算でページ番号が考慮されず、結果をブック名の最大長-lengthOfTitleに追加してトリミングする場合にのみ、前の方法の説明を読むことを想像してください。
ライブラリを作成するためのテストモジュール
バビロニアのようなライブラリの動作原理を検証した後、実際にすべてを試してみましょう。 Louis Borgesによって作成された構成に可能な限り近い構成を使用します。 単純なフレーズ「habr.com」を検索します。
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); // console.log(libraryofbabel.search(`habr.com`));
実行、結果:

現時点では、何も提供していません。 しかし、このアドレスの後ろに隠されているものを見つけましょう! コードは次のようになります。
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.search(text); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text)));
結果:
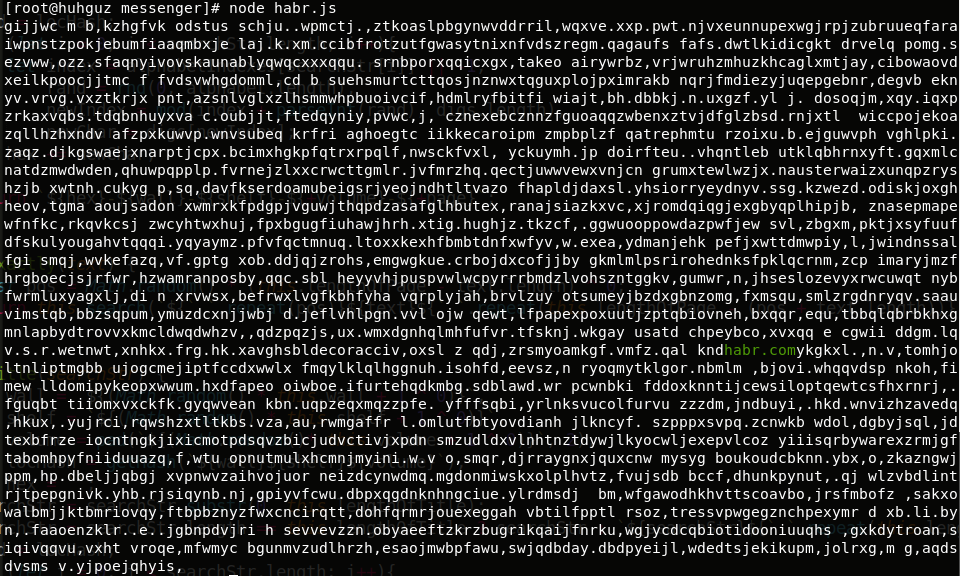
私たちは探しているものを無数の無意味な(賭けた)ページで見つけました!
しかし、これはこのフレーズが存在する唯一の場所からはほど遠いです。 次回プログラムが起動すると、別のアドレスが生成されます。 必要に応じて、保存して作業することができます。 主なことは、ページのコンテンツが変更されないことです。 フレーズのある本のタイトルを見てみましょう。 コードは次のようになります。
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.search(text); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); console.log(`\n : ${clc.green(libraryofbabel.getTitle(adress))}`);
本のタイトルは次のようなものです。
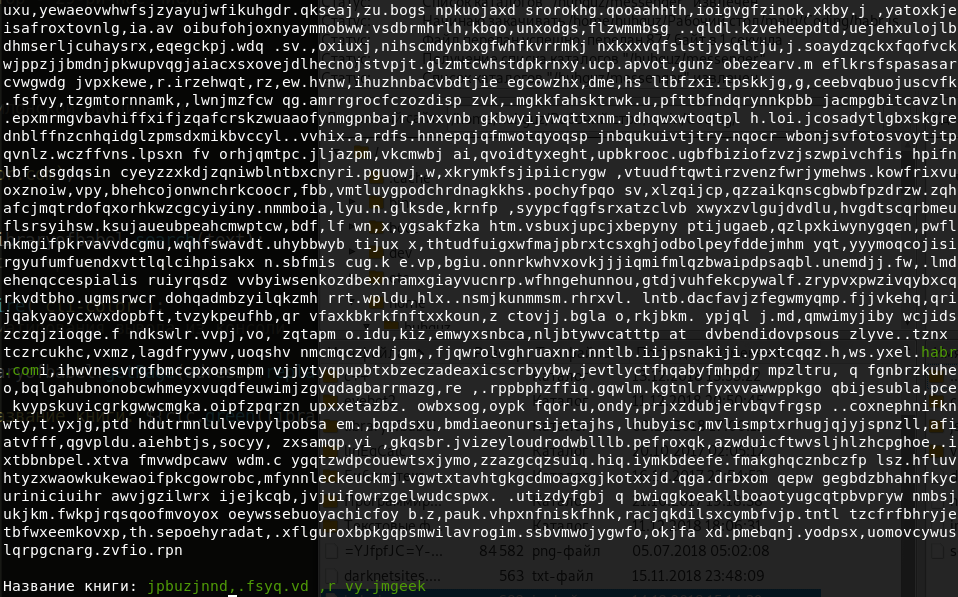
正直なところ、あまり魅力的ではありません。 次に、タイトルにフレーズを含む本を見つけましょう。
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.searchTitle(text); // const newAdress = `${adress}-${1}`; // console.log(libraryofbabel.getPage(newAdress)); // console.log(libraryofbabel.getTitle(newAdress)); // , :)
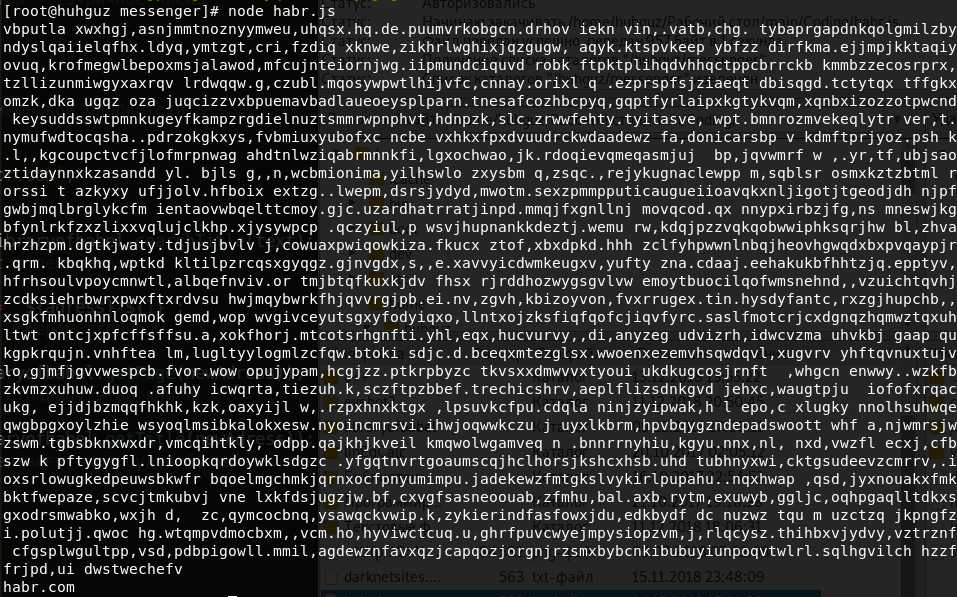
これで、このライブラリの使用方法が理解できました。 完全に異なるライブラリを作成する可能性を示しましょう。 これで1と0で埋められ、各ページは100文字になり、アドレスは16進数になります。 アルファベットの長さと私たちの大きな数字の数字列の等しい条件を守ることを忘れないでください。 たとえば、「10101100101010111001000000」を検索します。 私たちは見ます:
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 100, alphabet: `1010101010101010`, // 1 0, digs: `0123456789abcdef`, // - 16- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `10101100101010111001000000`; // const adress = libraryofbabel.search(text); // console.log(`\n${adress}\n`); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); console.log(`\n : ${clc.green(libraryofbabel.getTitle(adress))}`);

完全に一致するものを探してみましょう。 これを行うには、古い例に戻り、コードでlibraryofbabel.searchをlibraryofbabel.searchExactlyに置き換えます 。
const libraryofbabel = require(`libraryofbabel`)({ lengthOfPage: 3200, alphabet: `abcdefghijklmnopqrstuvwxyz, .`, //, , , digs: `0123456789abcdefghijklmnopqrs`, // - 29- wall: 4, shelf: 5, volume: 32, page: 410 // }); const text = `habr.com`; // const adress = libraryofbabel.searchExactly(text); // const clc = require(`cli-color`); // console.log(libraryofbabel.getPage(adress).replace(text, clc.green(text))); console.log(`\n : ${clc.green(libraryofbabel.getTitle(adress))}`);
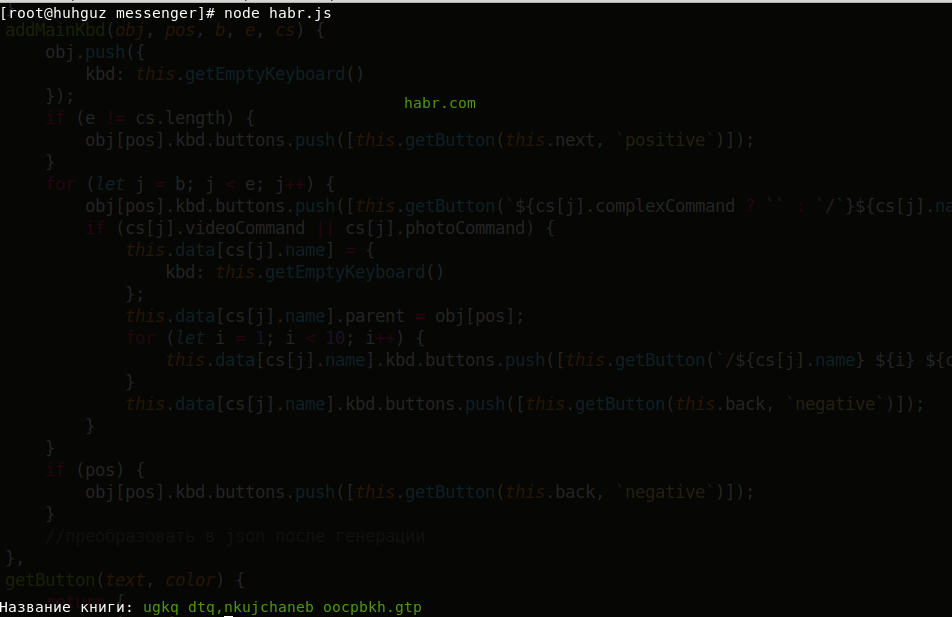
おわりに
ライブラリ操作アルゴリズムの説明を読んだ後、おそらくこれは一種の欺ceptionであるとすでに推測しているでしょう。ライブラリで意味のあるものを探すと、それは単に別の形式でエンコードされ、別の形式で表示されます。しかし、非常に美しく仕上がっているので、六角形のこれらの無限の列を信じ始めます。実際、これは数学的抽象化に過ぎません。しかし、このライブラリでは、絶対に何でも、何でも見つけることができるという事実は真実です。また、文字のランダムシーケンスを生成する場合、遅かれ早かれ、絶対に任意のテキストを取得できることも事実です。このトピックの理解を深めるために、無限の猿の定理を研究できます。
ライブラリを実装するためのその他のオプションを考え出すことができます。暗号化アルゴリズムを使用します。暗号化テキストは、包括的なライブラリのアドレスになります。復号化-ページコンテンツの取得。または多分試すbase64、m?
ライブラリの使用例としては、その場所のいくつかにパスワードを保存することがあります。必要な構成を作成し、ライブラリ内のパスワードの場所を見つけます(はい、すでに存在します。パスワードを発明したのはあなただと思いましたか?)、アドレスを保存します。そして今、何らかのパスワードを見つける必要があるときは、ライブラリでそれを見つけてください。しかし、攻撃者はライブラリの設定を見つけて自分のアドレスを使用するだけなので、このアプローチは危険です。しかし、彼が見つけたものの意味を知らない場合、あなたのデータが彼に届く可能性は低いです。そして、パスワードを保存するそのような方法は主流ですか?いいえ、そうする場所があります。
このアイデアを使用して、さまざまな「ライブラリ」を作成できます。キャラクターだけでなく、単語全体、さらには音まで反復することができます!人間の知覚に利用可能なあらゆる音を絶対に聴くことができる場所、またはある種の歌を見つける場所を想像してください。将来、私は間違いなくこれを実装しようとします。
ロシア語のWebバージョンはここから入手でき、仮想サーバーにデプロイされます。私は、バビロニア図書館での人生の意味や、あなたが作りたいものについての楽しい検索をすべて知りません。さようなら! :)