
毎日、150万人がさまざまな製品をOzonで検索しており、それぞれのサービスで同様の製品(掃除機にさらに強力なものが必要な場合)または関連するもの(歌う恐竜にバッテリーが必要な場合)を選択する必要があります。 製品の種類が多すぎる場合、Word2Vecモデルは問題の解決に役立ちます。 私たちは、それがどのように機能し、任意のオブジェクトのベクトル表現を作成する方法を理解しています。
やる気
モデルを構築してトレーニングするために、各オブジェクトが固定長のベクトルになり、近いベクトルが近いオブジェクトに対応する場合、機械学習の埋め込み手法標準を使用します。 ほぼすべての既知のモデルでは、入力データが固定長であることが必要です。ベクトルのセットは、入力データをこの形式にする簡単な方法です。
最初の埋め込み方法の1つはword2vecです。 この方法をタスクに適合させ、製品を単語として、ユーザーセッションを文章として使用します。 すべてが明確な場合は、結果を自由に確認してください。
次に、モデルのアーキテクチャとその仕組みについて説明します。 私たちは商品を扱っているので、一方では十分な情報を含み、もう一方では機械学習アルゴリズムで理解できるような商品の説明を作成する方法を学ぶ必要があります。
Webサイトでは、各製品にカードがあります。 タイトル、テキストの説明、機能、写真で構成されています。 また、ユーザーと製品との相互作用に関するデータもあります。ビュー、バスケットへの追加、お気に入りはログに保存されます。
ベクター製品の説明を作成するには、根本的に異なる2つの方法があります。
-コンテンツの使用-畳み込みニューラルネットワークを使用して、写真、リカレントネットワーク、または単語の袋から特徴を抽出し、テキストの説明を分析します。
-製品とのユーザーインタラクションに関するデータの使用:データとともにバスケットに表示/追加される製品と頻度。
2番目の方法に焦点を当てます。
Prod2Vecモデルのデータ
最初に、使用するデータを把握しましょう。 サイト上のすべてのユーザーのクリックを自由に使用できます。ユーザーのセッション、つまり、隣接するクリックの間隔が30分以内の一連のクリックに分割できます。 モデルをトレーニングするために、約1億のユーザーセッションのデータを使用します。各セッションでは、バスケットの製品の表示と追加にのみ関心があります。
実際のユーザーセッションの例:

セッションの各製品はそのコンテキストに対応します-ユーザーがこのセッションでバスケットに追加したすべての製品、およびこれで表示される製品。 prod2vecモデルは、類似した製品が類似したコンテキストを持っていることが最も多いという仮定に基づいています。
例:

したがって、仮定が当てはまる場合、たとえば、同じ電話モデルの場合は、同様のコンテキスト(同じ電話)になります。 製品ベクトルを作成して、この仮説をテストします。
モデルProd2Vec
製品の概念とそのコンテキストを紹介するとき、モデル自体について説明します。 これは、完全に接続された2つの層を持つニューラルネットワークです。 最初のレイヤーの入力の数は、ベクトルを構築する製品の数に等しくなります。 入り口にある各製品は、単一のユニットを持つゼロのベクトル(この製品の辞書内の場所)によってエンコードされます。
最初の層の出力にあるニューロンの数は、取得するベクトルの次元に等しくなります。たとえば、64です。最後の層の出力にも、商品の数に等しい数のニューロンがあります。

製品を知って、コンテキストを予測するようにモデルをトレーニングします。 このアーキテクチャはSkip-gramと呼ばれます(代替方法はCBOWで、コンテキストに応じて製品を予測します)。 トレーニング中、商品は入り口に配達され、商品はそのコンテキスト(対応する場所にユニットがあるゼロのベクトル)から出力されることが期待されます。
実際、これはマルチクラス分類であり、クロスエントロピー損失を使用してモデルをトレーニングできます。 コンテキストからの単語と単語のペアの場合、次のように記述されます。
どこで -コンテキストからの製品のネットワーク予測、 -商品の総数 -製品のネットワーク予測 。
モデルをトレーニングした後、2番目のレイヤーを破棄できます。ベクトルを取得する必要はありません。 最初の層の重みの行列(商品数のサイズx 64)は、製品ベクトルの辞書です。 各製品は長さ64の行列の1行に対応します-これは製品に対応するベクトルで、他のアルゴリズムで使用できます。
ただし、この手順は多数の製品では機能しません。 そして、私たちはそれらを思い出します、150万。
Prod2Vecが機能しない理由
-損失関数には、指数を取るという多くの操作が含まれています-これは、計算上、長く不安定です。
-結果として、すべてのネットワークの重みに対して勾配が考慮されます-数千万になる可能性があります。
これらの問題を解決するには、ネガティブサンプリング法が適しています。これを使用して、製品のコンテキストを予測するだけでなく、ネットワークが正確にコンテキストにない製品を予測しないことも教えます。 これを行うには、否定的な例を生成する必要があります。製品ごとに、予測する必要がない製品を選択します。 そして、ここで大量の商品の入手可能性が私たちを助けます。 製品のランダムペアを選択する場合、コンテキストから製品になる可能性は非常にわずかです。
その結果、コンテキスト内の製品ごとに、コンテキストに含まれない5〜10個の製品をランダムに生成します。 さらに、商品は均一な分布ではなく、発生頻度に比例してサンプリングされます。
損失関数は、バイナリ分類で使用される関数に似ています。 コンテキストからの1つの単語と単語のペアの場合、次のようになります。
これらの表記法で コンテキストからの積に対応する第2層の重み行列の列を示し、 -ランダムに選択された製品についても同じ メイン製品に対応する最初のレイヤーのウェイトマトリックスの行です(これはまさにそのために構築しているベクトルです)。 機能 。
前のバージョンとの違いは、各反復ですべてのネットワークウェイトを更新する必要はなく、少数の製品に対応するものだけを更新する必要があることです(最初の製品は予測対象であり、残りはそのコンテキストからの製品またはランダムに選択された製品です) 同時に、各反復で膨大な数の指数関数的なキャプチャを取り除きました。
結果として得られるモデルの品質を向上させる別の手法は、サブサンプリングです。 この場合、希少な商品に最適な結果を得るために、トレーニングのために意図的に頻繁に見つけられない商品を取ります。
結果
関連製品
そこで、商品のベクトルを取得する方法を学びました。次に、モデルの妥当性と適用性を確認する必要があります。
次の図は、製品と、コサインの近接度測定値の最も近い近傍を示しています。
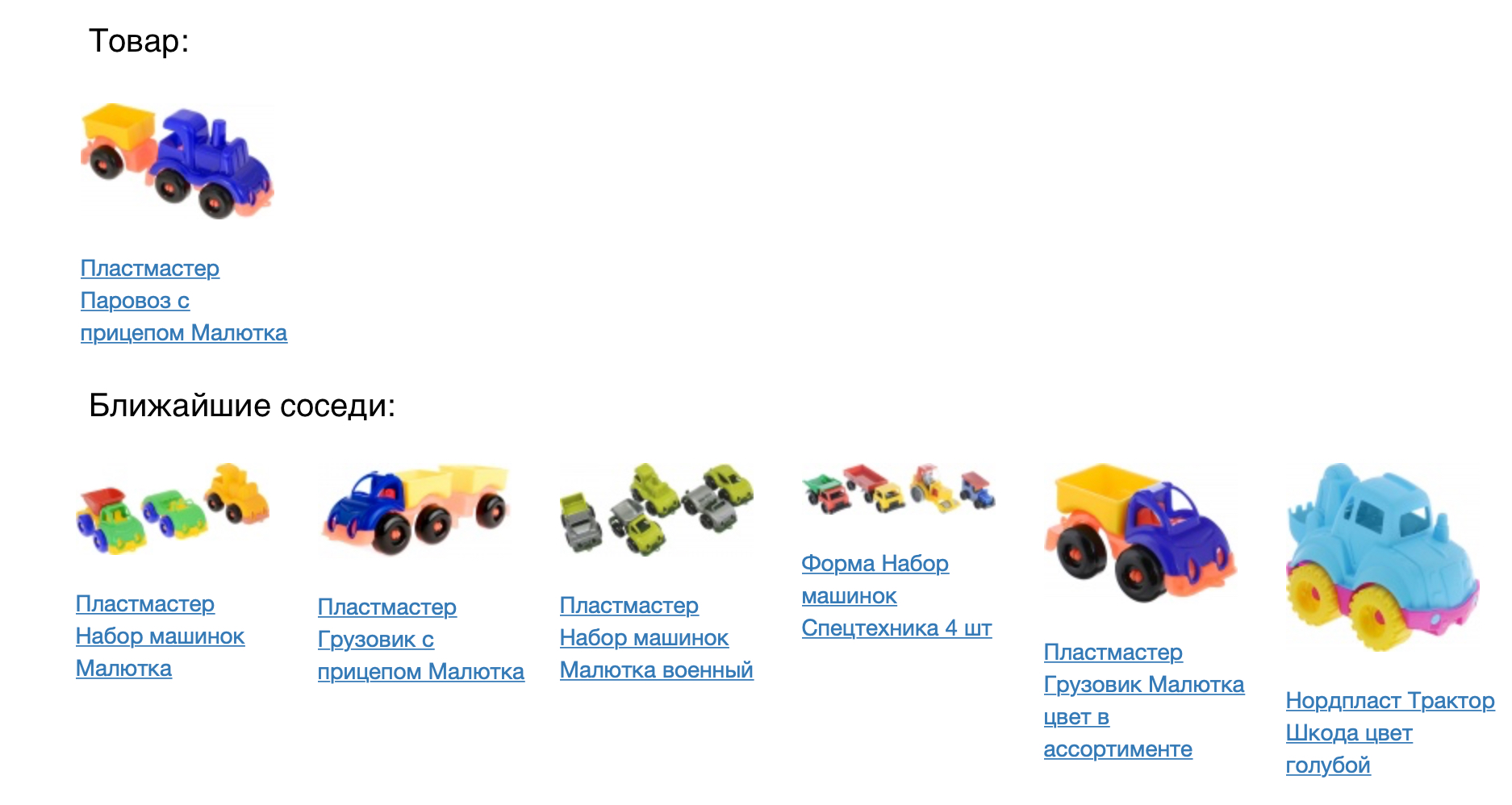
結果は良好に見えますが、モデルがどれほど優れているかを数値で確認する必要があります。 このため、製品の推奨事項のタスクに適用しました。 製品ごとに、構築されたベクトル空間に来ることをお勧めします。 共同ビューの統計とバスケットへのアイテムの追加に基づいて、prod2vecモデルをはるかに単純なモデルと比較しました。 セッションの各製品について、7つの推奨事項のリストが取られました。 セッションで推奨されるすべての製品の組み合わせを、人が実際にバスケットに追加したものと比較しました。 prod2vecを使用して、セッションの40%以上で、少なくとも1つの製品を推奨し、それをバスケットに追加しました。 比較のために、より単純なアルゴリズムは34%の品質を示しています。
結果のベクトル記述により、最も近いものを検索できるだけではありません(品質は劣りますが、より単純なモデルで実行できます)。 モデルを使用して、どのような興味深い副次的な結果を表示できるかを検討できます。
ベクトル演算
ベクトルが商品の本当の意味を持っていることを説明するために、それらに対してベクトル演算を使用することができます。 たとえば、word2vecの教科書の例(王-男+女=女王)のように、どの製品がプリンターから掃除機のダストバッグとほぼ同じ距離にあるかを自問することができます。 常識的には、何らかの消耗品、つまりカートリッジである必要があります。 私たちのモデルはそのようなパターンをキャッチできます:

製品空間の視覚化
結果をよりよく理解するために、平面上の商品のベクトル空間を視覚化して、次元を2に減らします(この例では、t-SNEを使用しました)。

関連製品がクラスターを形成していることは明らかです。 たとえば、寝室の布地、男性と女性の服、靴がはっきりと見える。 繰り返しになりますが、このモデルはユーザーと商品とのやり取りの履歴に基づいてのみ構築され、トレーニング時に画像またはテキストの説明の類似性を使用しなかったことに注意してください。
スペースの図から、モデルを使用して、商品のアクセサリを選択する方法も確認できます。 これを行うには、たとえば、Tシャツにはスポーツ用品、暖かいセーターにはキャップを勧めるなど、最も近いクラスターから商品を取り出す必要があります。
計画
現在、製品の推奨を計算するために、本番環境でprod2vecモデルを導入しています。 また、取得したベクトルは、当社チームが従事する他の機械学習アルゴリズムの機能として使用できます(製品の需要予測、検索とカタログでのランキング、個人的な推奨事項)。
将来的には、サイトで受け取った埋め込みをリアルタイムで実装する予定です。 表示されたすべての製品について、次の製品がセッション内にあり、パーソナライズされた配信に即座に反映されます。 また、ベクトルの記述に従って画像分析と類似性分析をモデルに統合することも計画しています。これにより、結果のベクトルの品質が大幅に向上します。
最善の方法(またはリメイク)を知っている場合は、訪問してください(さらに良い仕事)。
参照:
- ミコロフ、トーマス、他 「単語やフレーズの分散表現とその構成性。」 神経情報処理システムの進歩。 2013年。
- Grbovic、ミハイロなど 「受信トレイでのeコマース:大規模な製品の推奨事項」 知識発見とデータマイニングに関する第21回ACM SIGKDD国際会議の議事録。 ACM、2015年。
- Grbovic、Mihajlo、およびHaibin Cheng。 「Airbnbでの検索ランキングに埋め込みを使用したリアルタイムパーソナライゼーション。」 知識発見とデータマイニングに関する第24回ACM SIGKDD国際会議の議事録。 ACM、2018。