現在、ダーシャクリボルチコ(10年生の名前)がモスクワの寄宿学校に移り、他に何を設計すべきかを尋ねられました。 彼女のキャリアのこの段階で、彼女はマトリックス乗算のための収縮期配列に基づいてニューラルネットワーク用のハードウェアアクセラレータを設計する必要があると思います。 Verilogハードウェア記述言語とIntel FPGA FPGAを使用しますが、安価なMAX10ではなく、大規模なシストリックアレイを収容するためにより高価なものを使用します。
その後、ハードウェアソリューションのパフォーマンスを、schoolMIPSプロセッサで実行されているプログラム、およびデスクトップコンピューターで実行されているPythonプログラムと比較します。 テスト例として、小さなマトリックスからの数字の認識を使用します。

実際、このエクササイズのすべての部分はすでに異なる人々によって開発されていますが、全体のポイントは、これを単一の文書化されたエクササイズに入れて、オンラインコースおよび実際の競技会の基礎として使用できることです:
1)この種のオンラインコース(レジスタ転送+ニューラルネットワークのレベルでハードウェアを設計する)は、RUSNANOの教育部門であるeNanoに興味があります。上級者向けのライトコース。 ここチャールズと私は彼らのオフィスにいます:

2) NTIオリンピックはオリンピアードの基地に興味があるかもしれません。私は数週間前にモスクワでこの問題に触れました。 このような例では、オリンピックの参加者は、さまざまなアクティベーション機能用のハードウェアを追加できます。 NTIオリンピックの同僚は次のとおりです。

したがって、ダーシャがこれを開発すれば、彼女は理論的に説明された加速器をRUSNANOとNTIオリンピックに導入することができます。 私はそれが彼女の学校の管理にとって有益だと思います-それはテレビで見られるか、一般的にインテルFPGAコンテストに送られるでしょう。 カリフォルニア州サンタクララで開催されたインテルFPGAコンテストの決勝戦で、サンクトペテルブルクから来たロシア人のカップルを以下に示します。

それでは、プロジェクトの技術面について話しましょう。 収縮期質量加速器のアイデアは、エディターのHabra Vyacheslav Golovanov SLY_Gによって翻訳された記事に記載されています。 なぜ TPU はディープラーニングに適しているのですか?
これは、ニューラルネットワークのデータフローグラフがどのように単純な認識を探しているかです。

乗算と加算を実行するプリミティブな計算要素:

そのような要素の強くパイプライン化された構造、行列乗算のためのこのシストリック配列は次のとおりです。

インターネットでは、VerilogとVHDLにシストリック配列の実装を含む多数のコードがあります。たとえば、コードはこのブログ投稿の下にあります。

module top(clk,reset,a1,a2,a3,b1,b2,b3,c1,c2,c3,c4,c5,c6,c7,c8,c9); parameter data_size=8; input wire clk,reset; input wire [data_size-1:0] a1,a2,a3,b1,b2,b3; output wire [2*data_size:0] c1,c2,c3,c4,c5,c6,c7,c8,c9; wire [data_size-1:0] a12,a23,a45,a56,a78,a89,b14,b25,b36,b47,b58,b69; pe pe1 (.clk(clk), .reset(reset), .in_a(a1), .in_b(b1), .out_a(a12), .out_b(b14), .out_c(c1)); pe pe2 (.clk(clk), .reset(reset), .in_a(a12), .in_b(b2), .out_a(a23), .out_b(b25), .out_c(c2)); pe pe3 (.clk(clk), .reset(reset), .in_a(a23), .in_b(b3), .out_a(), .out_b(b36), .out_c(c3)); pe pe4 (.clk(clk), .reset(reset), .in_a(a2), .in_b(b14), .out_a(a45), .out_b(b47), .out_c(c4)); pe pe5 (.clk(clk), .reset(reset), .in_a(a45), .in_b(b25), .out_a(a56), .out_b(b58), .out_c(c5)); pe pe6 (.clk(clk), .reset(reset), .in_a(a56), .in_b(b36), .out_a(), .out_b(b69), .out_c(c6)); pe pe7 (.clk(clk), .reset(reset), .in_a(a3), .in_b(b47), .out_a(a78), .out_b(), .out_c(c7)); pe pe8 (.clk(clk), .reset(reset), .in_a(a78), .in_b(b58), .out_a(a89), .out_b(), .out_c(c8)); pe pe9 (.clk(clk), .reset(reset), .in_a(a89), .in_b(b69), .out_a(), .out_b(), .out_c(c9)); endmodule module pe(clk,reset,in_a,in_b,out_a,out_b,out_c); parameter data_size=8; input wire reset,clk; input wire [data_size-1:0] in_a,in_b; output reg [2*data_size:0] out_c; output reg [data_size-1:0] out_a,out_b; always @(posedge clk)begin if(reset) begin out_a<=0; out_b<=0; out_c<=0; end else begin out_c<=out_c+in_a*in_b; out_a<=in_a; out_b<=in_b; end end endmodule
このコードは最適化されておらず、一般的に不器用であることに注意してください(そして、プロとして書かれていない-投稿のソースは@(posedge clk)のブロック割り当てを使用しています-私はそれを修正しました)。 たとえば、Dashaは、Verilog生成構文を使用して、よりエレガントなコードを作成できます。
ニューラルネットワーク(プロセッサとシストリックアレイ)の2つの極端な実現に加えて、Dashaは、プロセッサより高速ですが、シストリックアレイのような乗算演算ほど貪欲ではない他のオプションを検討できます。 確かに、これは小学生ではなく、学生の可能性が高いです。
1つのオプションは、Out-of-Orderプロセッサーのように、多数の並列機能ブロックを備えた実行デバイスです。

別のオプションは、いわゆる粗粒度再構成可能アレイです。これは、それぞれが小さなプログラムを持つ準プロセッサ要素のマトリックスです。 これらのプロセッサエレメントはFPGA / FPGAセルに理想的に似ていますが、個々の信号ではなく、バスとレジスタのビット/番号のグループで動作します-TensorFlowを加速し、NVidiaと競合するハードウェアAIの主要プレーヤーの誕生からのライブレポートを参照してください。 。
今ダーシャからの元の手紙:
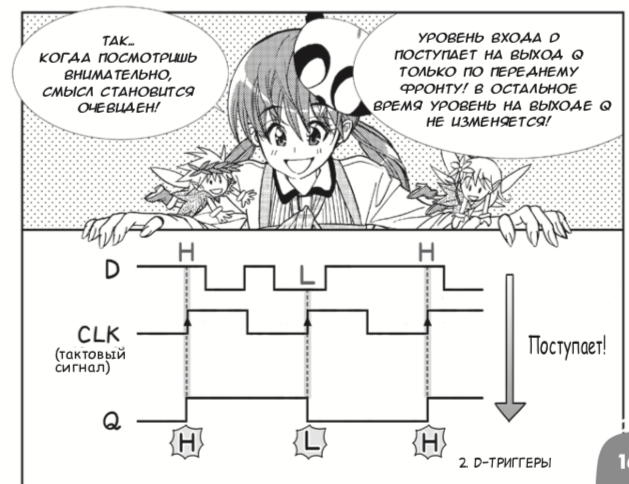
こんにちは、ユーリ。ダーシャは、私と、 David HarrisとSarah Harrisの著書「Digital Circuitry and Computer Architecture」の助けを借りて、Verilogとレジスタレベルの設計を教えました。 ただし、あなたが男子生徒であり、基本的な概念を非常に簡単なレベルで理解したい場合、出版社DMK-Pressはあなたのために、天野秀治と目黒浩二によって作成されたデジタル回路に関する日本の漫画2013のロシア語翻訳をリリースしました。 プレゼンテーションの軽微な形式にもかかわらず、この本は論理要素とDトリガーを正しく紹介し、 それをFPGAにバインドします 。
2017年、私はあなたのワークショップでLSHUPの学校で勉強し、2017年10月に、同年10月にトムスクで開催された会議に参加し、SchooolMIPSプロセッサに乗算ユニットを組み込むことに専念しました。
この作業を続けたいと思います。 現時点では、私は学校でこのトピックを小さなコースワークとみなす許可を得ることができました。 この仕事を続けるのを手伝う機会はありますか?
PS作業は特定の形式で行われるため、トピックの紹介と文献レビューを書く必要があります。 そのようなリソースを念頭に置いている場合は、このトピックの開発の歴史、建築哲学などに関する情報を入手できるソースをアドバイスしてください。
加えて、私がモスクワの寄宿学校に住んでいる瞬間には、やり取りしやすいかもしれません。
よろしく
ダリア・クリボルチコ。
ノボシビルスク地方の若手プログラマー向けサマースクールは 、DashaがVerilog、FPGA、レジスタ転送開発手法(Register Transfer Level-RTL)を学んだ場所です。


トムスクでのカンファレンスでのダーシャのスピーチは、10年生のアルセニーチェゴダエフと一緒です。
Dashaが私と、FPGAに実装するためのschoolMIPS教育プロセッサコアの主な作成者であるStanislav Zhelnio sparfと話し合った後:

schoolMIPSプロジェクトのドキュメントはhttps://github.com/MIPSfpga/schoolMIPSにあります 。 このトレーニングプロセッサコアの最も単純な構成では、Verilogに300行しかありませんが、中間層の産業用組み込みコアには約30万行あります。 それでも、Dashaは、プロセッサに新しい命令を追加すると、デコーダと実行デバイスを同じように変更する、業界のデザイナーの仕事がどのように見えるかを感じることができました。
結論として、サマースクールと将来の申請者向けのFPGA上のプロセッサーを備えたオリンピックの作成に興味を持っているサマラ大学イリヤ・クドリャフツェフの学部長の写真を紹介します。

そして、来年すでにそのようなサマースクールを計画しているゼレノグラードMIETの従業員の写真:

RUSNANOの資料とNTIオリンピックの可能な資料、およびHSE MIEM、モスクワ州立大学、 カザンイノポリスのプログラムでのFPGAおよびマイクロアーキテクチャの実装で過去数年にわたって達成された成果は、いずれもうまくいくはずです。