
昨年12月、AlphaZero人工知能会社DeepMindを使用した新しいチェスエンジンの信じられないほどのパワーに関するニュースの波がありました。 本日、彼らはこのエンジンの更新バージョンの驚くべき結果を発表しました。
AlphaZeroが世界で最も強力なチェスエンジンの1つであることは間違いありません。
更新されたAlphaZeroは、1000試合での新しい試合でStockfish 8を破りました。結果は155勝、6敗、839引きです。
また、AlphaZeroは、不均等な時間制御を行う一連のゲームでStockfishを上回り、10回のハンディキャップがあっても従来のエンジンを打ち負かしました。
DeepMindによると、追加の試合で、新しいAlphaZeroは2018年1月13日にStockfishの「最新の開発バージョン」を上回り、Stockfish 8との試合とほぼ同じ結果を示しました。
DeepMindによると、彼らの機械学習エンジンは、「強力なデビューブックを使用するStockfishバリアント」に対するすべての試合にも勝利しました。 デビューの本を追加することで、ストックフィッシュは助けになったようです。ストックフィッシュはAlphaZeroが黒をプレイしたときに最終的にかなりの数のゲームに勝ちましたが、試合に勝つには十分ではありませんでした。
結果はサイエンス誌の記事に掲載され、選ばれたチェスメディアによって提供された。
1000ゲームでの試合は2018年初頭に開催されました。 試合では、AlphaZeroとStockfishに各ゲームの3時間と1ターンあたり15秒の利益が与えられました。 この時間管理は、昨年の試合の結果に対する最大の議論の1つになりそうです。つまり、2017年には、1移動あたり1分の時間管理がAlphaZeroにとって大きな利点でした。
3時間に15秒の増加を加えた場合、このような議論は意味がありません。これは、チェスエンジンにとって膨大なプレイ時間であるためです。 不均等な時間のゲームでは、10対1の時間比でもAlphaZeroが優勢でした。 Stockfishは30対1の比率でのみ勝ち始めました。
AlphaZeroの結果、ゲームの時間が不均等になると、従来のチェスエンジンよりも強力であるだけでなく、より効率的な移動検索も使用されることがわかります。 DeepMindによると、AlphaZeroはモンテカルロツリー検索を使用して、ストックフィッシュの6000万件に対して、毎秒約60,000件の位置を探索します。
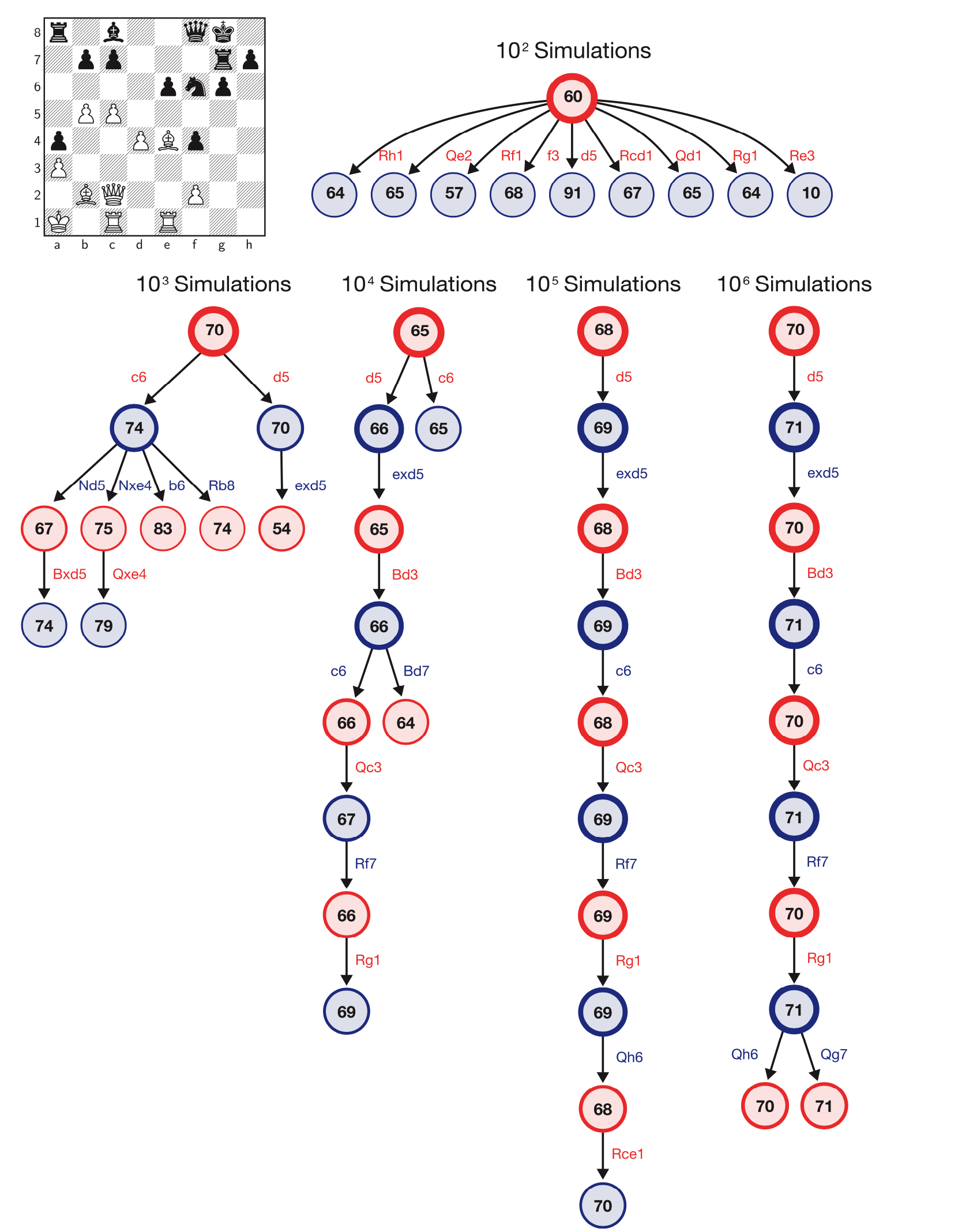
AlphaZeroは、検索アルゴリズムの図を移動します。 Scienceの記事からのDeepMindの画像。
記事によると、更新されたAlphaZeroアルゴリズムは、チェス、将gi、囲threeの3つの複雑なゲームで同一です。 AlphaZeroのこのバージョンは、簡単なゲームルールから始めて、何時間も自己学習した後、3つのゲームすべての最高のコンピューターエンジンを打ち負かすことができました。
DeepMindは、マッチから210のゲームをリリースしました 。 こちらからダウンロードできます 。
新しいAlphaZeroバージョンでは、ゲームのルールから始めて、機械学習法を使用してチェスをプレイし、ニューラルネットワークを絶えず更新するようになりました。 DeepMindによると、5,000 TPU(Googleテンソルプロセッサ、AI専用の集積回路)を使用して独立プレイ用の最初のゲームセットを生成し、その後16のTPUを使用してニューラルネットワークをトレーニングしました。
チェスの合計トレーニング時間はゼロから9時間かかりました。 DeepMindによると、新しいAlphaZeroはStockfishを上回るためにわずか4時間のトレーニングが必要でした。 9時間で、彼は世界チェスチャンピオンよりもはるかに先を行きました。
ゲーム自体では、Stockfishは44個のプロセッサを使用し、AlphaZeroは4台のTPUと44個のプロセッサコアを備えた1台のマシンを使用しました。
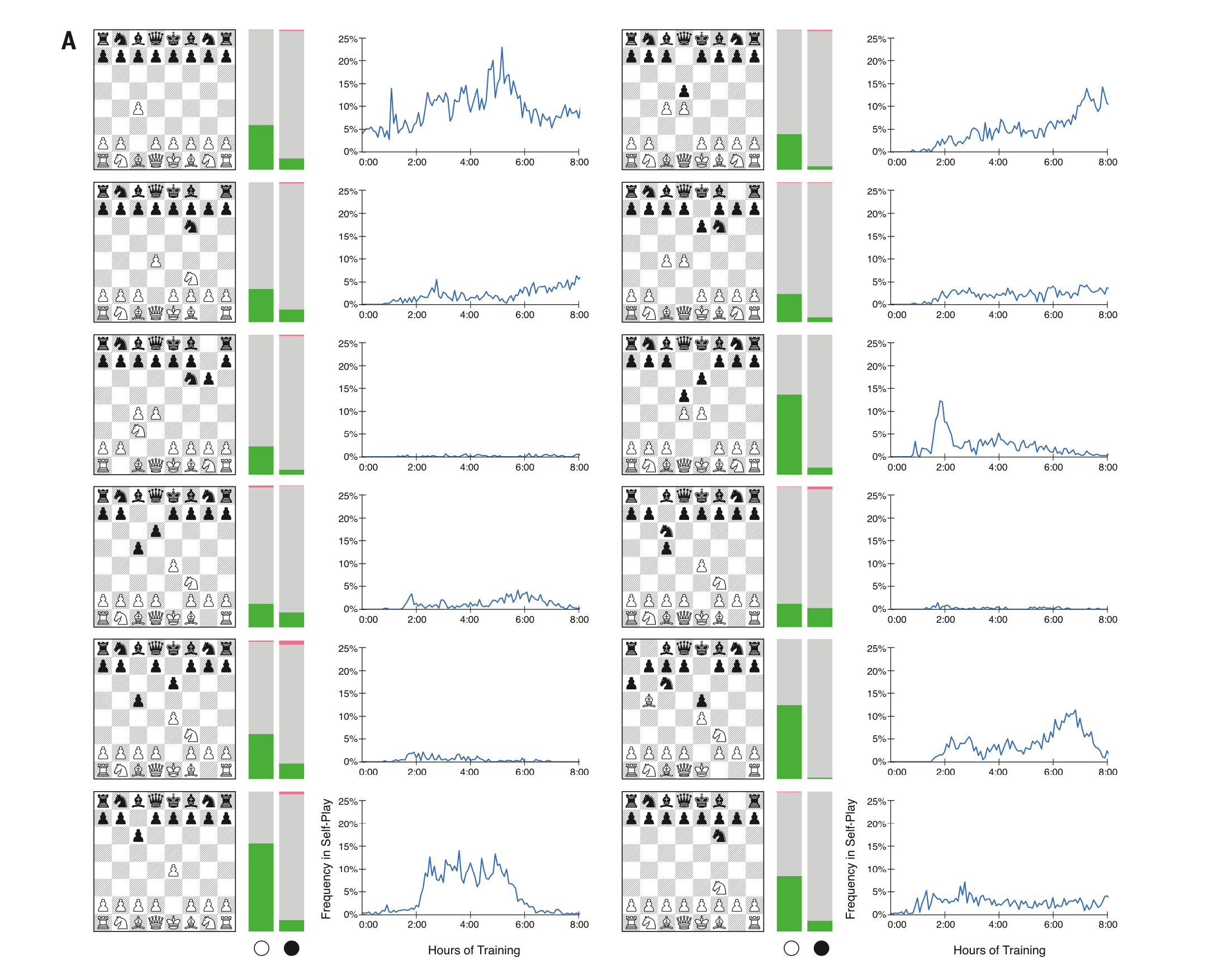
AlphaZero vs. Stockfishは、最も人気のあるデビューをもたらします。 左側では、AlphaZeroは白を再生します。 右側-黒。
DeepMind自身は、記事でプログラムのユニークなプレイスタイルに言及しています。
「いくつかのゲームで、AlphaZeroは長期的な戦略的優位性のためにピースを犠牲にしました。これは、以前のチェスプログラムで使用されていたルールベースのレーティングよりもコンテキスト上のポジションレーティングがあることを示唆しています」とDeepMindの研究者は述べています。
AIはまた、3つの異なるゲームで同じバージョンのAlphaZeroを使用することの重要性を強調し、ゲームインテリジェンス全体の突破口としてそれを宣伝しました。
「これらの結果は、人工知能の長年の野望を実現することに近づきます。あらゆるゲームをマスターすることを学ぶことができる一般的なゲームシステムです」と、DeepMindの研究者は述べています。