
チェーンレプリケーションの使用例を引き続き検討します。 最初の部分で基本的な定義とアーキテクチャを説明しました。2番目の部分を読む前に、それをよく理解することをお勧めします。
この記事では、次のシステムについて学習します。
- Hibariは、erlangで作成された分散型のフォールトトレラントリポジトリです。
- HyperDexは、2次属性によるクイック検索と範囲検索をサポートする分散キー値ストレージです。
- ChainReaction-因果性+一貫性およびジオレプリケーション。
- 追加の外部監視/再構成プロセスを使用せずに分散システムを構築します。
5.ひばり
Hibariは、アーランで記述された分散型フォールトトレラントKVリポジトリです。 チェーンレプリケーション(基本的なアプローチ)を使用します。 厳密な一貫性を実現します。 テストでは、Hibariは高いパフォーマンスを示します-2ユニットサーバーで1秒あたり数千の更新が達成されました(1Kbリクエスト)
5.1アーキテクチャ
データの配置には、一貫したハッシュが使用されます。 ストレージの基礎は、物理ブロックと論理ブロックです。 物理ブリックは、Linux、おそらくEC2インスタンス、一般的にはVM全体を備えたサーバーです。 論理ブリックは、クラスタのメインプロセスが機能するリポジトリインスタンスであり、各ブロックは1つのチェーン内のノードです。 次の例では、クラスターは各物理ブロックに2つの論理ブロックを配置するように構成され、チェーンの長さは2です。
マスタープロセス(最初の部分の定義を参照)は管理サーバーと呼ばれます 。
データは単に名前空間に分割する役割を果たす「テーブル」に格納され、各テーブルは少なくとも1つのチェーンに格納され、各チェーンは1つのテーブルにのみデータを格納します。
Hibariクライアントは、すべてのチェーン(およびすべてのテーブル)のすべてのヘッドとテールのリストを含む更新を管理サーバーから受信します。 したがって、顧客はどの論理ノードにリクエストを送信するかをすぐに把握できます。
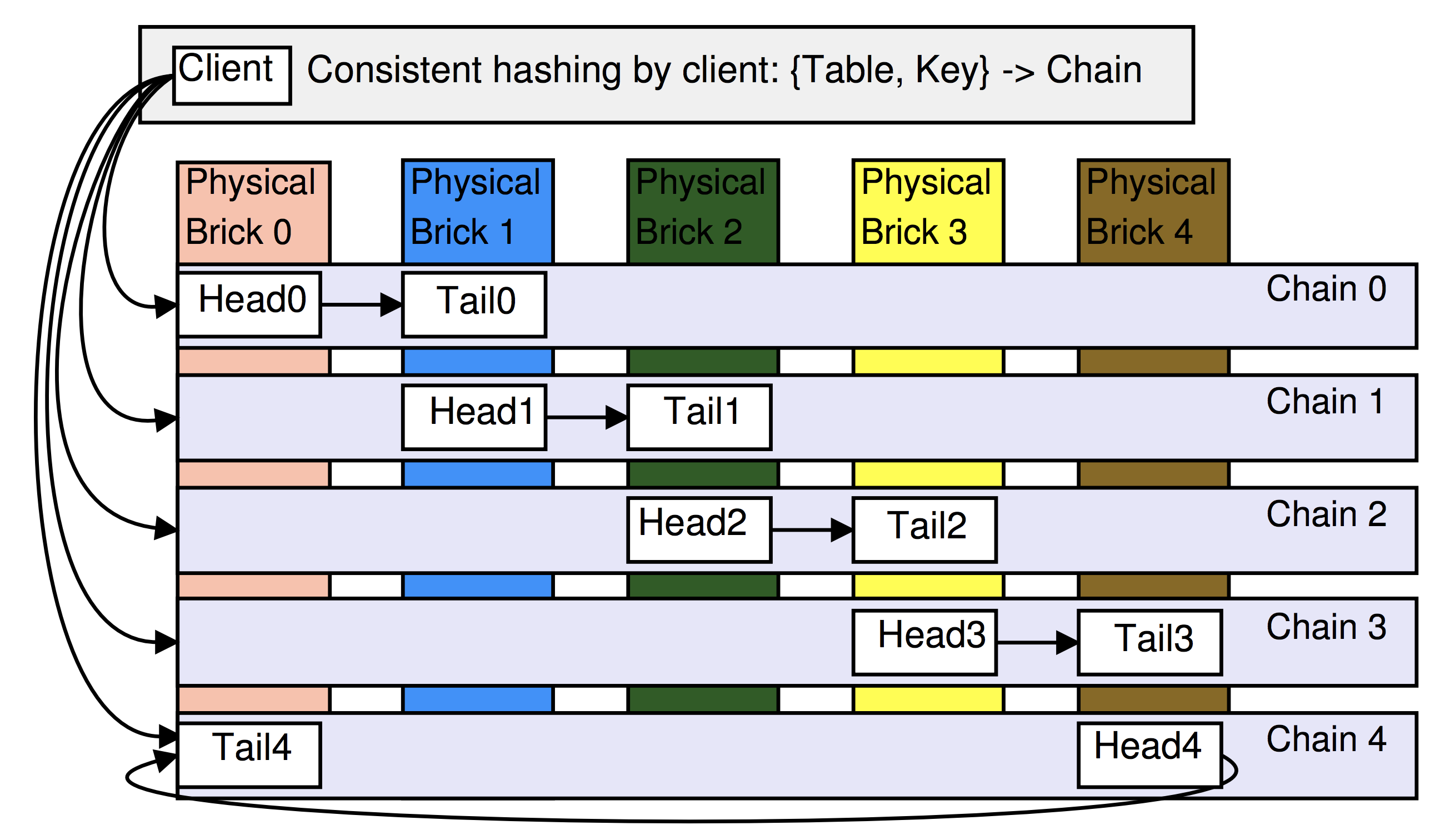
5.2ハッシュ
ひばりはペアを使用します キーを保存するチェーンの名前を決定する テーブルで :キー 間隔にマッピング (MD5を使用)、1つのチェーンが担当するセクションに分割されます。 セクションは、チェーンの「重量」に応じて、異なる幅にすることができます。次に例を示します。

したがって、一部の物理ブロックが非常に強力な場合、その上にあるチェーンには、より広いセクションを割り当てることができます(さらに多くのキーがそれらに落ちます)。
6. HyperDex
このプロジェクトの目標は、他の一般的なソリューション(BigTable、Cassandra、Dynamo)とは異なり、セカンダリ属性のクイック検索をサポートし、範囲検索を迅速に実行できる分散Key-Valueストレージを構築することでした。 たとえば、以前に検討されたシステムでは、特定の範囲内のすべての値を検索するには、すべてのサーバーを通過する必要があり、これは明らかに受け入れられません。 HyperDexはHyperspace Hashingを使用してこの問題を解決します。
6.1アーキテクチャ
ハイパースペースハッシュのアイデアは、 各属性が1つの座標軸に対応する2次元空間。 たとえば、オブジェクト(名、姓、電話番号)の場合、スペースは次のようになります。
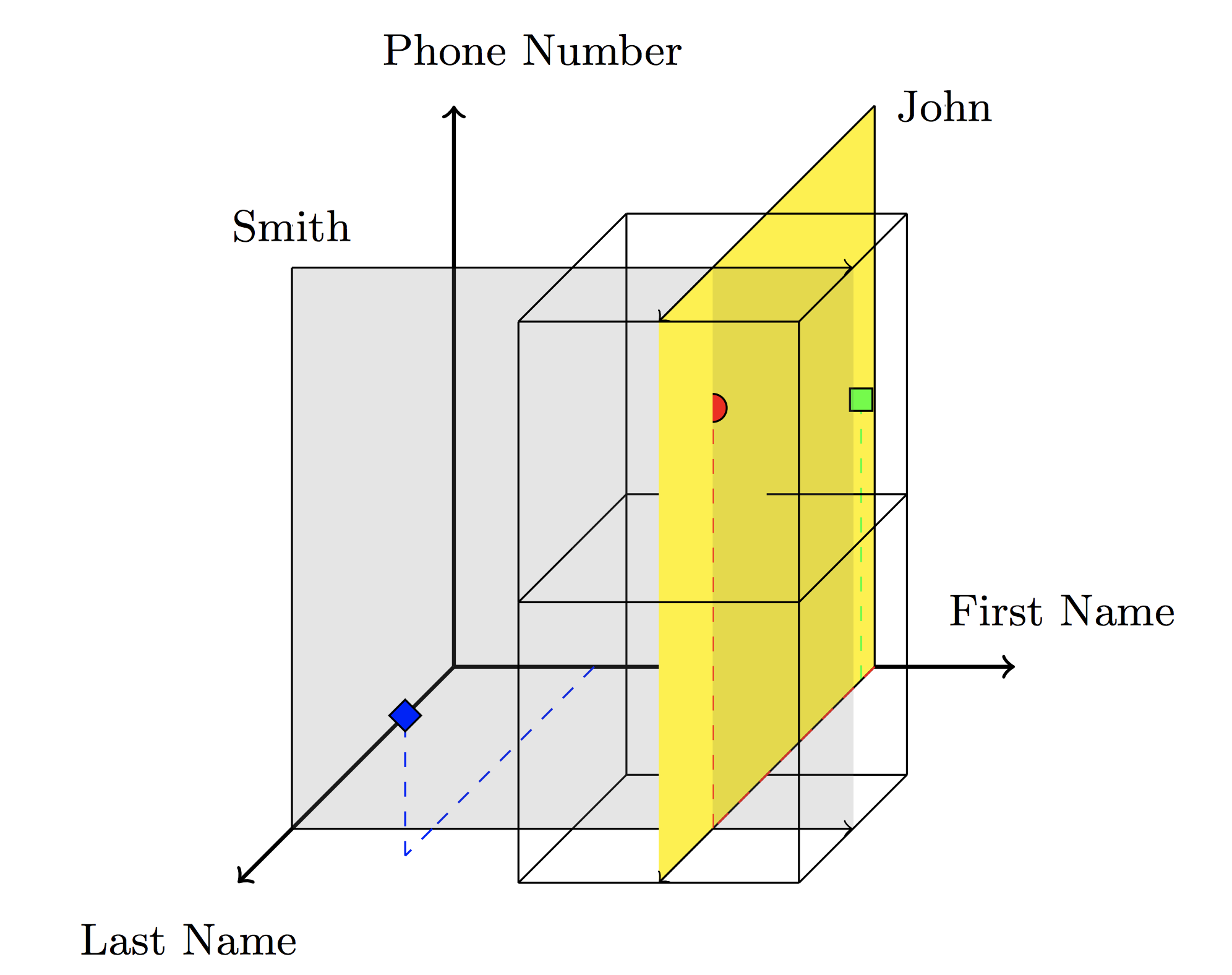
灰色の超平面はすべてのキーを通過し、姓=スミス、黄色-すべてのキー、名=ジョンを通過します。 これらの平面の交差点は、Johnという名前とSmithという名前の人々の電話番号の検索クエリに対する応答を形成します。 だからの要求 属性が返す 次元部分空間。
サーチスペースはに分かれています 次元のばらばらの領域。各領域は単一のサーバーに割り当てられます。 リージョンからの座標を持つオブジェクトは、このリージョンのサーバーに保存されます。 したがって、オブジェクトとサーバーの間にハッシュが構築されます。
検索クエリ(範囲別)により、結果のハイパープレーンに含まれる領域が決定されるため、ポーリングされるサーバーの数が最小限に抑えられます。
このアプローチには1つの問題があります。必要なサーバーの数は、属性の数から指数関数的に増加します。 if属性 その後、あなたが必要 サーバー。 この問題を解決するため、HyperDexはハイパースペースのパーティションを、それぞれ属性のサブセットを持つサブスペース(より低い次元)に適用します。

6.2レプリケーション
厳密な一貫性を確保するために、著者はチェーンレプリケーションに基づく特別なアプローチを開発しました。 値に依存するチェーンでは、対応する属性をハッシュすることで後続の各ノードが決定されます。 たとえば、キー 最初にキースペースにハッシュされ( ポイントリーダーとも呼ばれるヘッドチェーンが取得されます)、次に $インライン$ "John" $インライン$ 対応する軸上の座標などに。 (更新の例については、下の画像を参照してください。 )
すべての更新は、リクエストを整理するポイントリーダーを通過します(線形化可能性)。

更新がリージョンの変更につながる場合、最初に古いバージョンの直後に新しいバージョンが書き込まれます(更新を参照) )、テールからACKを受信すると、前のサーバーから古いバージョンへのリンクが変更されます。 同時リクエストを行うには(例: そして )一貫性ポイントに違反していない場合リーダーは、受信した場合、サーバーにバージョニングおよびその他のメタ情報を追加します 前に 注文が混乱しているので、待つ必要があると判断できます 。
7. ChainReaction
因果+収束モデルが使用され、因果(因果)収束に競合のない収束の条件が追加されます。 因果的収束を実現するために、メタデータが各リクエストに追加され、すべての因果依存キーのバージョンを示します。 ChainReactionを使用すると、複数のデータセンターでジオレプリケーションを実行でき、CRAQのアイデアをさらに発展させます。
7.1アーキテクチャ
FAWNのアーキテクチャは、わずかな変更で使用されます-各DCはデータサーバー -バックエンド(データストレージ、レプリケーション、DHTリングの形成)およびクライアントプロキシ -フロントエンド(特定のノードへの要求の送信)で構成されます。 各キーは、R連続ノードに複製され、チェーンを形成します。 読み取り要求はテールによって処理され、書き込みはヘッドによって処理されます。

7.2 1つのデータセンター
チェーンレプリケーションから生じる重要な特性の1つに注意してください-ノードが 一部のクライアント操作と因果的整合性があり、その後、以前のすべてのノードも-と同じです。 だから、操作 サイトで最後に見た 、その後、すべての因果依存(から )読み取り操作は、先頭から次のノードでのみ実行できます 。 すぐに 末尾で実行されます-読み取り制限はありません。 DCのテールによって実行された書き込み操作を示します DC-Write-Stable(d)など 。
各クライアントは、クライアントが要求したすべてのキーのリスト(メタデータ)を形式(キー、バージョン、chainIndex)で保存します。ここで、chainIndexは、キーキーの最後の要求に応答したチェーン内のノードの位置です。 メタデータは、クライアントがDC-Write-Stable(d)であるかどうかを認識していないキーについてのみ保存されます 。
7.2.1書き込み操作
操作がDC-Write-Stable(d)になったら、読み取り要求は以前のバージョンを読み取ることができません。
各書き込み要求について、最後の書き込み操作が追加される前に読み取り操作が実行されたすべてのキーのリスト。 クライアントプロキシがリクエストを受信するとすぐに、メタデータからすべてのキーの末尾でブロッキング読み取りを実行します(同じバージョンまたは新しいバージョンの存在の確認を待っています、つまり、因果一貫性の条件を満たします)。 確認が受信されると、対応するチェーンのヘッドに書き込み要求が送信されます。

新しい値が保存されると チェーンのノードの場合、通知はクライアントに送信されます(最後のノードのインデックスとともに)。 クライアントはchainIndexを更新し、送信されたキーのメタデータを次のように削除します それらがDC-Write-Stable(d)であることが知られるようになりました。 並行して、記録はさらに続けられます- 遅延伝播 。 したがって、最初の書き込み操作が優先されます。 ノード。 tailがキーの新しいバージョンを保存するとすぐに、通知がクライアントに送信され、チェーンのすべてのノードに送信されて、キーが安定しているとマークされます。
7.2.2読み取り操作
クライアントプロキシが読み取り要求を送信します 負荷を分散しながら、回路内のノード。 応答として、ノードは値とこの値のバージョンを送信します。 応答はクライアントに送信されますが、次の場合:
- バージョンが安定している場合、新しいchainIndexはチェーンのサイズと等しくなります。
- バージョンが新しい場合、新しいchainIndex = index。
- それ以外の場合、chainIndexは変更されません。
7.2.3ノードのフェイルオーバー
これは基本的なアプローチとほぼ完全に同じですが、場合によってはクライアントのchainIndexが無効になるという事実にいくつかの違いがあります-これはリクエストを実行するときに簡単に決定され(このバージョンにはキーがありません)、リクエストはチェーンのヘッドにリダイレクトされ、目的のバージョンのノードを検索します
7.3いくつかの( )データセンター(ジオレプリケーション)
単一サーバーアーキテクチャのアルゴリズムを基本とし、それらを最小限に適合させます。 まず、メタデータで、バージョンとchainIndexの値だけでなく、N次元のバージョン付きベクトルが必要です。
DC-Write-Stable(d)と同様の方法でGlobal-Write-Stableを定義します。書き込み操作は、すべてのDCのテールで実行された場合、Global-Write-Stableと見なされます。
各DCに新しいコンポーネントが表示されます-remote_proxy 、そのタスクは他のDCから更新を受信/送信することです。
7.3.1サーバーでの書き込み操作の実行 )
最初は単一サーバーアーキテクチャに似ています-読み取りのブロッキング、最初の書き込みを実行します チェーンの結び目。 この時点で、クライアントプロキシはクライアントに新しいベクターchainIndexを送信します。 -意味があります 。 次-いつものように。 最後の追加操作-更新はremote_proxyに送信され、複数の要求を蓄積してからすべてを送信します。
ここで2つの問題が発生します。
- 異なるDCからの異なる更新プログラム間の依存関係を確認する方法は?
各remote_proxyは、ローカルバージョンベクトルを格納します 寸法 、送受信された更新の数を保存し、各更新で送信します。 したがって、別のDCから更新を受信すると、remote_proxyはカウンターをチェックし、ローカルカウンターが少ない場合、対応する更新が受信されるまで操作はブロックされます。 - 他のDCでこの操作の依存関係を提供する方法は?
これは、ブルームフィルターを使用して実現されます。 クライアントプロキシから書き込み/読み取り操作を実行すると、メタデータに加えて、ブルームフィルターも各キーに送信されます(応答フィルターと呼ばれます)。 これらのフィルターはAccessedObjectsリストに保存され、書き込み/読み取り操作を要求するとき、メタデータは送信されたキーをフィルターにかけます(依存フィルターと呼ばれます)。 同様に、書き込み操作の後、対応するフィルターは削除されます。 書き込み操作を別のDCに送信すると、この要求の依存関係フィルターと応答フィルターも送信されます。
さらに、このすべての情報を受信したリモートDCは、応答フィルターの設定ビットがいくつかのクエリフィルターの設定ビットと一致する場合、そのような操作が潜在的に偶発的に依存することを確認します。 潜在的に-ブルームフィルターのため。
7.3.2読み取り操作
単一サーバーアーキテクチャと同様に、スカラーの代わりにchainIndexベクトルを使用するように調整し、DCでキーが失われる可能性があります(更新が非同期であるため)-要求を待機するか、別のDCにリダイレクトします。
7.3.3競合の解決
メタデータのおかげで、因果依存の操作は常に正しい順序で実行されます(このためにプロセスをブロックする必要がある場合があります)。 しかし、異なるDCでの競争上の変化は、競合につながる可能性があります。 このような状況を解決するために、各更新操作にペアが存在する最終書き込み優先が使用されます どこで -プロキシでの時間 -DCのID。
7.3.4ノード障害の処理
単一サーバーアーキテクチャに似ています。
8.スケーラブルレプリケーションプロトコルの設計でシャーディングを活用する
この調査の目的は、クラスターを再構成/監視するための外部マスタープロセスを使用せずに、シャードとレプリケーションを備えた分散システムを構築することです。
現在の主なアプローチでは、著者には次のような欠点があります。
複製:
- プライマリ/バックアップ-プライマリが誤って失敗と識別された場合、状態に矛盾が生じます。
- Quorum Intersection-クラスターの再構成中に状態の不一致が生じる可能性があります。
厳格な一貫性:
- プロトコルは、必要に応じて多数決アルゴリズム(Paxosなど)に依存します 結び目を落とす ノード。
ノード障害の検出:
- P / BおよびCRは、フェイルストップモデルを使用した障害ノードの完全な検出の存在を意味します。これは実際には達成できず、適切なスキャン間隔を選択する必要があります。
- ZooKeeperでも同じ問題が発生します-多数のクライアントでは、構成を更新するのにかなりの時間(> 1秒)が必要です。
著者によって提案されたElastic replicationと呼ばれるアプローチには、これらの欠点がなく、次の特徴があります。
- 厳密な一貫性。
- 落下に耐える ノードには 結び目。
- 一貫性を失わずに再構成します。
- 多数決に基づく合意プロトコルの必要はありません。
概要プレート:

8.1レプリカの構成
各シャードは、構成のシーケンスを定義します たとえば、新しい構成には、何らかの種類の落ちたレプリカが含まれていません
構成シーケンスの各要素は以下で構成されます。
- レプリカ-レプリカのセット。
- orderer-特別な役割を持つレプリカのID(以下を参照)。
各シャードは、レプリカのセットで表されます(構造- )、つまり 「シャード」と「レプリカ」の役割を分けません。
各レプリカには次のデータが格納されます。
- conf-このレプリカが属する構成のID。
- orderer-このレプリカは、この構成の発注者です。
- モード-レプリカモード、3つのいずれか: (非-からのすべてのレプリカ )、 (からのすべてのレプリカ )、 。
- 履歴-実際のレプリカデータに対する一連の操作 (または単なる条件)。
- 安定-このレプリカによって修正される履歴プレフィックスの最大長。 明らかに、 。
レプリカ注文者の主な目的は、残りのレプリカにリクエストを送信し、最大の履歴プレフィックスを維持することです。

8.2シャードの構成
破片は、 弾性バンドと呼ばれるリングに結合されます。 各シャードは1つのリングにのみ属します。 すべての破片の先駆者 特別な役割を果たします-彼は彼のためのシーケンサーです。 シーケンサーの仕事は、レプリカに障害が発生した場合に、後継サーバーに新しい構成を提供することです。

次の2つの条件が必要です。
- 各エラスティックバンドには、少なくとも1つのシャードと1つの作業レプリカがあります。
- 各弾性バンドには、すべてのレプリカが機能するシャードが少なくとも1つあります。
2番目の条件は厳しすぎるように見えますが、マスタープロセスが決して落ちないという「従来の」条件と同等です。
8.3チェーンレプリケーションの使用
ご想像のとおり、レプリカはチェーンとして構成されています(基本的なアプローチ)-注文者が先頭にいますが、わずかな違いがあります。
- CRで障害が発生した場合、ERでノードがチェーンからスローされ(新しいノードに置き換えられます)、新しいチェーンが作成されます。
- CRの読み取り要求は、テールで、ERで処理されます。書き込み要求と同じ方法でチェーン全体を通過します。
8.5障害発生時の再構成
- レプリカは、シャードのレプリカとシーケンサーシャードのレプリカの両方によって監視されます。
- 障害が検出されるとすぐに、レプリカはこれに関するコマンドを送信します。
- Sequencerが新しい構成を送信します(レプリカの障害はありません)。
- 状態をエラスティックバンドと同期する新しいレプリカが作成されます。
- その後、シーケンサーは追加されたレプリカとともに新しい構成を送信します。