



この記事では、2つのトランスパイラーのチェーンが実行する最も興味深い変換について説明し(1つ目は Pythonコードを新しいプログラミング言語11lのコードに変換し、2つ目はコードをC ++の11lに変換します)、パフォーマンスを他の加速ツールと比較します/ Pythonコードの実行(PyPy、Cython、Nuitka)。
スライスとスライスを範囲で置き換える
| Python | 11l |
| |
s[(len)-2]
末尾からのインデックスの明示的な指示が、
s[(len)-2]
ではなく
s[(len)-2]
に必要です。
- たとえば、
s[i-1]
で前の文字を取得する必要がある場合、i = 0の場合、このような/エラーの代わりにこのレコードは文字列の最後の文字をサイレントに返します[ そして実際、このerror- commitに遭遇しました ] 。 -
i = s.find(":")
後の式s[i:]
は、文字列[ 最初の文字から始まる文字列の ''部分ではなく、文字列の最後の文字が取得される場合 ] Pythonのfind()
関数で-1
を返す ことも間違っていると思います[ null / Noneを返す必要があります。-1が必要な場合は、明示的に記述する必要がありますi = s.find(":") ?? -1
] ] ) - 文字列の最後の
n
文字を取得するs[-n:]
書き込みは、n = 0の場合は正しく機能しません。
比較演算子のチェーン
一見、Python言語の優れた機能ですが、実際には、
in
演算子と範囲を使用することで簡単に破棄/ディスペンスできます。
a < b < c
| b in a<..<c
|
a <= b < c
| b in a..<c
|
a < b <= c
| b in a<..c
|
0 <= b <= 9
| b in 0..9
|
リストの理解
同様に、判明したように、Pythonのもう1つの興味深い機能であるリスト内包表記を拒否できます。
リストの理解を称賛し、 `filter()`と `map()`を放棄することさえ提案している間 、私はそれを見つけました:
- Pythonのリストの理解を見たすべての場所で、関数 `filter()`と `map()`で簡単に取得できます。
dirs[:] = [d for d in dirs if d[0] != '.' and d != exclude_dir] dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) '[' + ', '.join(python_types_to_11l[ty] for ty in self.type_args) + ']' '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' # Nested list comprehension: matrix = [ [1, 2, 3, 4], [5, 6, 7, 8], [9, 10, 11, 12], ] [[row[i] for row in matrix] for i in range(4)] list(map(lambda i: list(map(lambda row: row[i], matrix)), range(4)))
- 11lの `filter()`と `map()`はPythonよりもきれいに見えるその結果、11lのリスト内包表記の必要性は実際になくなります[ リスト内包表記の
dirs[:] = filter(lambda d: d[0] != '.' and d != exclude_dir, dirs) dirs = dirs.filter(d -> d[0] != '.' & d != @exclude_dir) '[' + ', '.join(map(lambda ty: python_types_to_11l[ty], self.type_args)) + ']' '['(.type_args.map(ty -> :python_types_to_11l[ty]).join(', '))']' outfile.write("\n".join(x[1] for x in fileslist if x[0])) outfile.write("\n".join(map(lambda x: x[1], filter(lambda x: x[0], fileslist)))) outfile.write(fileslist.filter(x -> x[0]).map(x -> x[1]).join("\n"))
filter()
および/またはmap()
と の 置き換えは、Pythonコードを11lに自動的に変換するときに実行されます ] 。
if-elif-elseチェーンをスイッチに変換します
Pythonにはswitchステートメントが含まれていませんが、これは11lで最も美しい構造の1つであるため、switchを自動的に挿入することにしました。
| Python | 11l |
|
|
完全を期すために、ここに生成されたC ++コードがあります
switch (instr[i]) { case u'[': nesting_level++; break; case u']': if (--nesting_level == 0) goto break_; break; case u''': ending_tags.append(u"'"_S); break; // '' case u''': assert(ending_tags.pop() == u'''); break; }
小さな辞書をネイティブコードに変換する
Pythonコードの次の行を検討してください。
tag = {'*':'b', '_':'u', '-':'s', '~':'i'}[prev_char()]
ほとんどの場合、この形式の記録は[ パフォーマンスの点で ]非常に効果的ではありませんが、非常に便利です。
11lでは、この行に対応するエントリ[ そしてPythonトランスポーター→11lによって取得 ]は便利です[ Pythonほどエレガントではありませんが]だけでなく、高速です:
var tag = switch prev_char() {'*' {'b'}; '_' {'u'}; '-' {'s'}; '~' {'i'}}
上記の行は次のように翻訳されます。
[ ラムダ関数呼び出しは、最適化プロセス中にC ++コンパイラーによってインラインでコンパイルされ、演算子のチェーンのみがauto tag = [&](const auto &a){return a == u'*' ? u'b'_C : a == u'_' ? u'u'_C : a == u'-' ? u's'_C : a == u'~' ? u'i'_C : throw KeyError(a);}(prev_char());
?/:
ままになり
?/:
]
変数が割り当てられた場合、辞書はそのまま残ります:
| Python | |
| 11l |
|
| C ++ |
|
外部変数をキャプチャする
Pythonでは、変数はローカルではないが[ 現在の関数の外] で取得する必要があることを示すために、非ローカルキーワードが使用されます[ そうでなければ、たとえば、
found = True
は、値を割り当てるのではなく、新しいローカル変数
found
を作成するものとして扱われます既存の外部変数 ] 。
11lでは、これに@プレフィックスが使用されます。
| Python | 11l |
|
|
auto writepos = 0; auto write_to_pos = [..., &outfile, &writepos](const auto &pos, const auto &npos) { outfile.write(...); writepos = npos; };
グローバル変数
外部変数と同様に、Pythonでグローバル変数を宣言することを忘れると[ グローバルキーワードを使用して ] 、目に見えないバグが発生します。
|
|
break_label_index
「宣言されていない
break_label_index
変数」エラーを
break_label_index
します。
現在のコンテナアイテムのインデックス/番号
Python関数の
enumerate
が返す変数の順序を忘れてしまいます{最初に値、次にインデックス、またはその逆}。 Rubyのアナログ動作
each.with_index
は覚えやすいです:インデックスを使用すると、インデックスは値の前ではなく値の後に来ることを意味します。 しかし、11lでは、ロジックはさらに覚えやすくなっています。
| Python | 11l |
|
|
性能
PCマークアップからHTMLへの変換プログラムはテストプログラムとして使用され、PCマークアップ記事のソースコードはソースデータとして使用されます[ この記事は現在PCマークアップに最も多く書かれているため ] 、10回繰り返されます。 48.8キロバイトの記事ファイルサイズ488Kbから取得。
以下は、対応するPythonコードの実行方法が元の実装[ CPython ]よりも高速である回数を示すグラフです 。
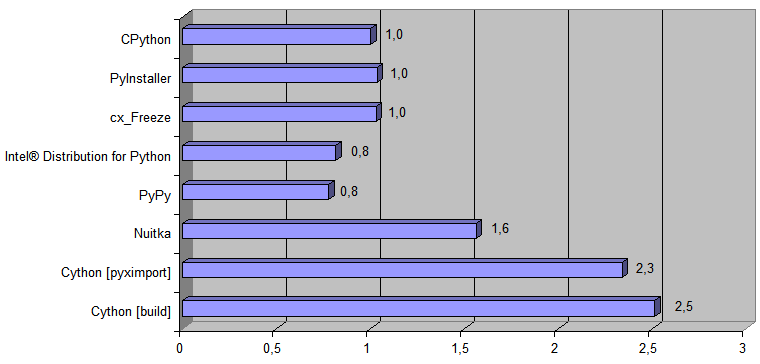
次に、Python→11l→C ++トランスポーターによって生成された実装を図に追加します。 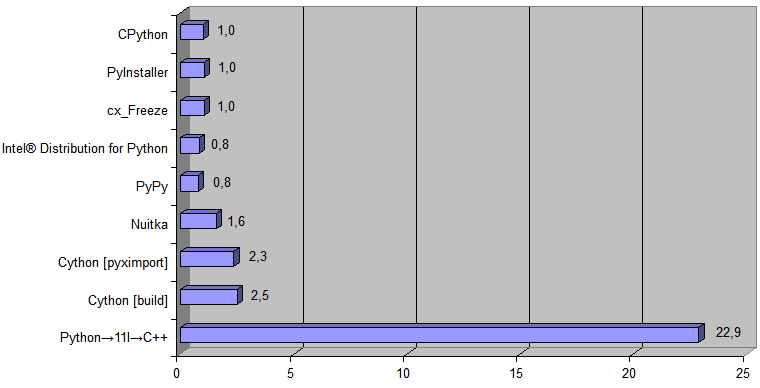
ランタイム[ 488Kbファイル変換時間 ]は、CPythonでは868ミリ秒、生成されたC ++コードでは38ミリ秒でした[ 今回は本格的な[ つまり、 RAM内のデータを操作するだけではなく ]オペレーティングシステムとすべての入出力によってプログラムを実行する[ ソースファイル[ .pq ]を読み取り、新しいファイル[ .html ]をディスクに保存する ] ] 。
Shed Skinも試してみたかったのですが、ローカル機能をサポートしていません。
Numbaも使用できませんでした(「不明なオペコードLOAD_BUILD_CLASSの使用」エラーがスローされます)。
これは、パフォーマンスを比較するために使用されるプログラムのアーカイブです( Windowsの場合 ) (Python 3.6以降が必要で、次のPythonパッケージが必要です:pywin32、cython)。
ランタイム[ 488Kbファイル変換時間 ]は、CPythonでは868ミリ秒、生成されたC ++コードでは38ミリ秒でした[ 今回は本格的な[ つまり、 RAM内のデータを操作するだけではなく ]オペレーティングシステムとすべての入出力によってプログラムを実行する[ ソースファイル[ .pq ]を読み取り、新しいファイル[ .html ]をディスクに保存する ] ] 。
Shed Skinも試してみたかったのですが、ローカル機能をサポートしていません。
Numbaも使用できませんでした(「不明なオペコードLOAD_BUILD_CLASSの使用」エラーがスローされます)。
これは、パフォーマンスを比較するために使用されるプログラムのアーカイブです( Windowsの場合 ) (Python 3.6以降が必要で、次のPythonパッケージが必要です:pywin32、cython)。
PythonのソースとPythonトランスパイラーの出力-> 11lおよび11l-> C ++: