前回の投稿で、私はKubernetesについて、 ThoughtSpotがそれを独自の開発サポートニーズにどのように使用しているかについて話しました。 今日は短いことについての会話を続けたいと思いますが、それは最近起こったそれほど興味深いデバッグ履歴ではありません。 この記事は、コンテナ化!=仮想化という事実に基づいています。 さらに、最適化されたcgroup制限と高いマシンパフォーマンスでも、コンテナ化されたプロセスがリソースを奪い合う方法を示します。
以前、Kubernetes内部クラスターでのb CI / CDの開発に関連する一連の操作を開始しました 。 すべて問題ありませんが、「dockerized」アプリケーションを起動すると、パフォーマンスが急激に低下します。 けちくさではありませんでした。各コンテナには、ポッド構成で設定される計算能力とメモリ(5 CPU / 30 GB RAM)に制限がありました。 このようなパラメータを持つ仮想マシンでは、テスト用の小さなデータセット(10 Kb)からのすべてのリクエストが飛ぶでしょう。 ただし、72 CPU / 512 GB RAMを搭載したDocker&Kubernetesでは、製品の3〜4コピーを起動し、その後ブレーキがかかりました。 数ミリ秒で完了していたリクエストが1〜2秒間ハングし、CIタスクパイプラインであらゆる種類の障害が発生しました。 私は多くのデバッグをしなければなりませんでした。
原則として、Dockerでアプリケーションをパッケージ化するときのあらゆる種類の構成エラーが疑われます。 ただし、少なくとも何らかの減速を引き起こす可能性のあるものは見つかりませんでした(ベアハードウェアまたは仮想マシンでのインストールと比較した場合)。 すべてが正しいようです。 次に、 Sysbenchパッケージのすべての種類のテストを試しました。 CPU、ディスク、メモリのパフォーマンスを確認しました。すべてがベアメタルと同じでした。 当社製品の一部のサービスには、すべてのアクションに関する詳細情報が保存されます。その後、パフォーマンスのプロファイリングに使用できます。 原則として、一部の呼び出しでリソース(CPU、RAM、ディスク、ネットワーク)が不足している場合、時間の重大な障害が記録されます。したがって、正確に速度が低下する場所とその場所を見つけます。 ただし、この場合は何も起こりませんでした。 一時的な割合は、実際の構成と違いはありませんでした。唯一の違いは、各コールがベアメタルよりもはるかに遅いことです。 問題の本当の原因を示すものは何もありません。 これを突然見つけたとき、私たちはあきらめようとしていました 。
この記事では、同じマシンでDocker内で実行すると、原則として2つの軽いプロセスが互いに殺し、リソース制限が非常に控えめな値に設定された場合、著者は同様の不可解なケースを分析します。 2つの重要な結論を下しました。
- 主な理由は、Linuxカーネル自体にあります。 カーネル内のdentryキャッシュオブジェクトの構造により、1つのプロセスの動作が
__d_lookup_loop
カーネルへの呼び出しを大幅に抑制し、別のプロセスのパフォーマンスに直接影響しました。 - 著者は
perf
を使用してカーネルのバグを検出しました。 これまで使用したことのない素晴らしいデバッグツールです(申し訳ありません!)。
perf(perf_eventsまたはperfツールと呼ばれることもあります。以前はLinux、PCLのパフォーマンスカウンターとして知られていました)は、カーネルバージョン2.6.31から利用可能なLinuxパフォーマンス分析ツールです。 ユーザースペース管理ユーティリティのperfは、コマンドラインから使用でき、サブコマンドのコレクションです。
システム全体(カーネルおよびユーザースペース)の統計プロファイリングを提供します。 このツールは、ハードウェアおよびソフトウェア(hrtimerなど)プラットフォーム、トレースポイント、および動的サンプル(kprobesやuprobeなど)のパフォーマンスカウンターをサポートします。 2012年に、2人のIBMエンジニアが、perf(OProfileとともに)をLinuxで最もよく使用される2つのパフォーマンスカウンタープロファイリングツールの1つとして認識しました。
だから私たちは考えた:多分同じことを持っている? コンテナで数百の異なるプロセスを開始しましたが、すべて同じコアを使用していました。 私たちはトレイルにいると感じました! perf
で武装し、デバッグを繰り返し、最終的に最も興味深い発見を待っていました。
以下は、正常(高速)マシン(左)およびコンテナ内(右)で実行されているThoughtSpotの最初の10秒間のperf
エントリです。
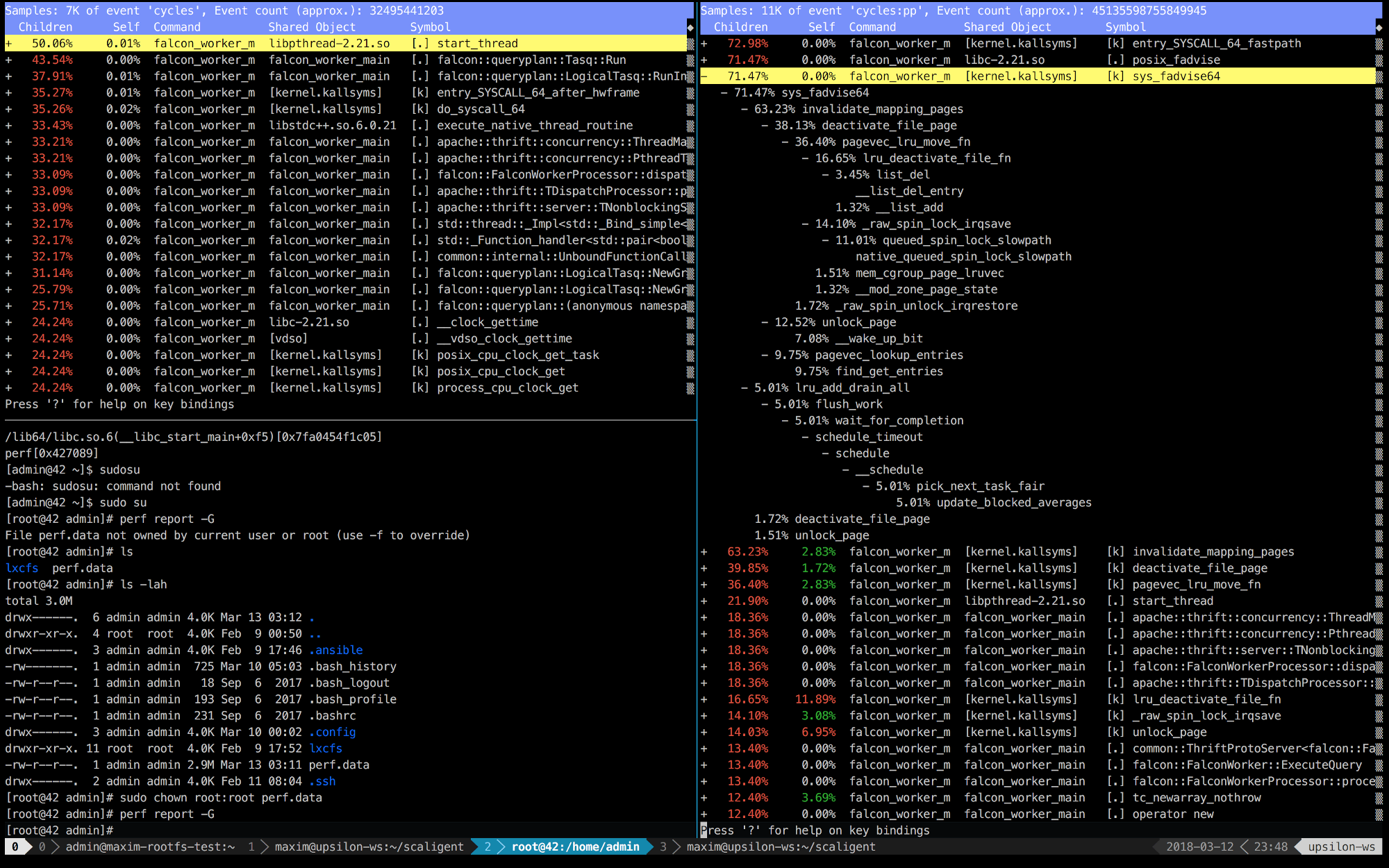
右側では、最初の5つの呼び出しがカーネルに接続されていることがすぐにわかります。 時間は主にカーネルスペースに費やされますが、左側では、ほとんどの時間がユーザースペースで実行される独自のプロセスに費やされます。 しかし、最も興味深いのは、 posix_fadvise
呼び出しに常に時間がかかることです。
プログラムはposix_fadvise()を使用し、将来の特定のパターンに従ってファイルデータにアクセスする意図を宣言します。 これにより、カーネルは必要な最適化を実行できます。
この呼び出しはあらゆる状況で使用されるため、問題の原因を明示的に示すものではありません。 しかし、コードを掘り下げてみたところ、理論的にはシステム内のすべてのプロセスに影響を与える場所が1つだけ見つかりました。
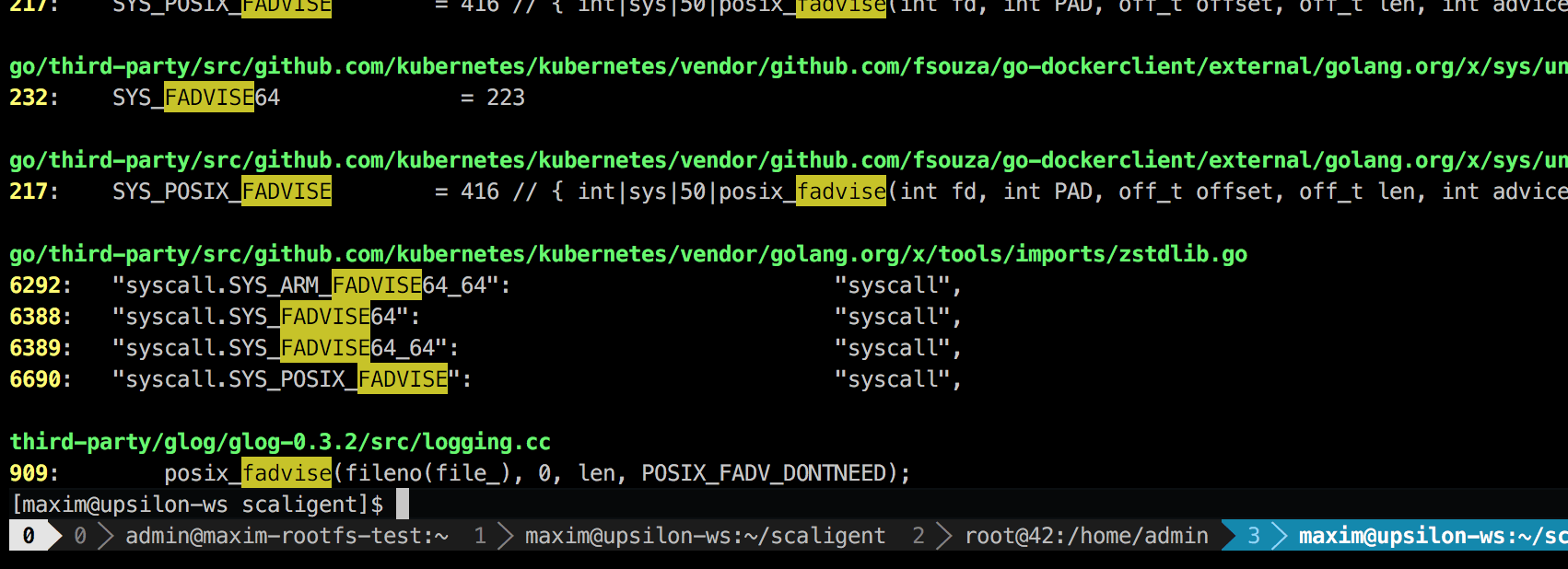
これは、 glog
と呼ばれるサードパーティのロギングライブラリです。 プロジェクトに使用しました。 具体的には、この行( LogFileObject::Write
)は、おそらくライブラリ全体の最も重要なパスです。 これは、すべてのイベント「ファイルへのログ」(ファイルへのログ)に対して呼び出され、製品の多くのインスタンスは非常に頻繁にログに記録されます。 ソースコードをざっと見てみると、-- --drop_log_memory=false
パラメーターを設定することでfadviseパーツを無効にできることが示唆されています。
if (file_length_ >= logging::kPageSize) { // don't evict the most recent page uint32 len = file_length_ & ~(logging::kPageSize — 1); posix_fadvise(fileno(file_), 0, len, POSIX_FADV_DONTNEED); } }
もちろん、私たちはこれを行って...そしてブルズアイで!
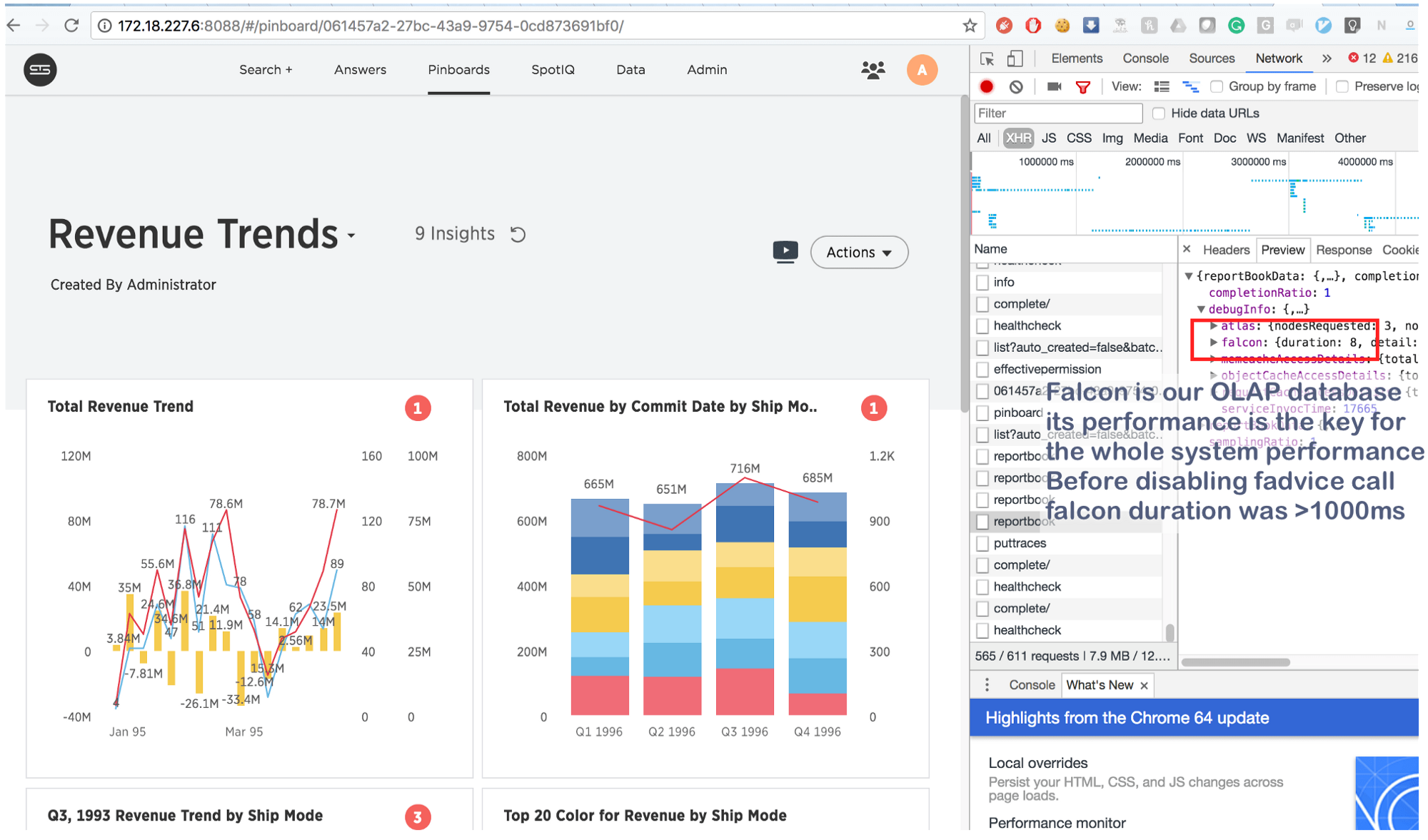
数秒かかっていたことが、今では8 (8!)ミリ秒で完了しています。 少しグーグルで、私たちはこれを見つけました: https : //issues.apache.org/jira/browse/MESOS-920またこれ: https : //github.com/google/glog/pull/145 、これは再び確認されました抑制の本当の原因についての私たちの予感。 ほとんどの場合、同じことが仮想マシン/ベアメタルでも発生しましたが、マシン/コアごとにプロセスのコピーが1つあったため、fadviseの呼び出し強度ははるかに低く、追加のリソース消費がないことを説明しました。 ロギングプロセスを3〜4倍に増やし、それらの共通のコアを1つ強調すると、fadviseが本当に停止することがわかりました。
そして結論として:
この情報は新しいものではありませんが、何らかの理由で多くの人が主なことを忘れています:コンテナーの場合、「分離」プロセスはCPU 、 RAM 、 ディスクスペース 、 ネットワークだけでなく、 すべてのコアリソースを奪い合います 。 また、カーネルは非常に複雑な構造であるため、クラッシュはどこでも発生する可能性があります(たとえば、 Sysdigの記事の__d_lookup_loopなど )。 ただし、これは、コンテナが従来の仮想化よりも悪いことや良いことを意味するものではありません。 彼らは彼らのタスクを解決する優れたツールです。 覚えておいてください。カーネルは共有リソースであり、カーネル空間での予期しない競合をデバッグする準備ができています。 さらに、このような競合は、攻撃者が「細くなった」分離を突破し、コンテナ間に隠れたチャネルを作成する絶好の機会です。 そして最後に、 perf
があります。これは、システムで何が起こっているかを示し、パフォーマンスの問題をデバッグするのに役立つ優れたツールです。 Dockerで負荷の高いアプリケーションを実行する予定がある場合は、 perf
を学ぶのに時間をかけるようにしてください。