クライアントが製品を購入する傾向があることだけでなく、購入に影響するものを理解している場合、販売効率の改善を目的とした企業戦略を将来構築することができます。
または、モデルは、患者がすぐに病気になると予測しました。 そのような予測の精度はそれほど高くありません。 モデルには多くの要因が隠されていますが、モデルがこのような予測を行った理由の説明は、医師が新しい症状に注意を払うのに役立ちます。 したがって、モデル自体の精度が高すぎなければ、モデルの適用範囲を広げることができます。
この投稿では、 SHAPテクニックについてお話したいと思います。これにより、さまざまなモデルの内部を見ることができます。
線形モデルの場合、予測子の下の係数の絶対値が大きくなればなるほど、この予測子はより重要になり、同じ勾配ブースティングの特徴の重要性を説明することははるかに難しくなります。
なぜそのような図書館が必要だったのか

sklearnスタックのxgboost、lightGBMパッケージには、「木製モデル」の機能の重要性(機能の重要性)を評価するための組み込みメソッドがありました。
- ゲイン
このメジャーは、モデルに対する各機能の相対的な貢献度を示します。 計算のために、各ツリーを調べ、ノードのパーティションにつながる機能と、メトリック(Gini不純性、情報ゲイン)に従ってモデルの不確実性がどの程度減少するかを各ツリーノードで調べます。
各機能について、その寄与はすべてのツリーで合計されます。
- カバー
各フィーチャの観測値の数を示します。 たとえば、4つの機能、3つのツリーがあります。 ツリーのノードのフィーチャ1には、ツリー1、2、および3の観測値がそれぞれ10、5、および2含まれているとし、このフィーチャの重要度は17(10 + 5 + 2)になります。
- 頻度
ツリーのノードでこの機能が検出される頻度、つまり、各ツリーの各機能のノードに分割されたツリーの総数が考慮されます。
これらすべてのアプローチの主な問題は、この機能がモデル予測にどの程度正確に影響するかが明確でないことです。 たとえば、銀行のクライアントがローンを返済する際の支払能力を評価するには、収入のレベルが重要であることを学びました。 しかし、どのように正確に? 収益がモデル予測にどの程度偏っているか?
もちろん、収入のレベルを変更することにより、いくつかの予測を行うことができます。 しかし、他の機能をどうするのでしょうか? 結局のところ、私たちは他の機能とは独立して、平均値で収入の影響を理解する必要がある状況にいることに気づきます。
ある種の平均的な銀行顧客が「真空状態」にあります。 収入の変化に応じてモデル予測はどのように変化しますか?
ここでは、 SHAPライブラリーが役立ちます。
SHAPを使用して機能の重要性を計算します
SHAPライブラリでは、機能の重要性を評価するために、Shapley値が計算されます (アメリカの数学者の名前とライブラリの名前が付けられます)。
機能の重要性を評価するために、この機能を使用して 、または使用せずにモデル予測を評価します。
先史時代の少し

シャプレイの意味はゲーム理論に由来します。
シナリオを考えてみましょう。人々のグループがカードをプレイします。 寄付に応じて賞金をどのように分配するのですか?
多くの仮定が行われます。
- 各プレイヤーの報酬額は、賞金プールの合計に等しくなります
- 2人のプレイヤーがゲームに均等に貢献した場合、同等の報酬を受け取ります。
- プレイヤーが貢献していない場合、彼は報酬を受け取りません。
- プレーヤーが2つのゲームを費やした場合、合計報酬は各ゲームの報酬の量で構成されます
プレイヤーとしてモデルの機能を、モデルの最終予測として賞金プールを提示します。
例を見てみましょう。
i番目の機能のシャプレー値を計算するための式:
$$ display $$ \ begin {equation *} \ phi_ {i}(p)= \ sum_ {S \サブセットeq N / \ {i \}} \ frac {| S |!(n-| S | -1) !} {n!}(p(S \ cup \ {i \})-p(S))\ end {equation *} $$ display $$
ここに:
i番目の機能を備えたモデルの予測であり、
-これは、i番目の機能のないモデルの予測です。
-機能の数、
-i番目の機能のない任意の機能セット
i番目の特徴のShapley値は、可能なすべての特徴の組み合わせ(すべての特徴の不在を含む)で各データサンプル(たとえば、サンプルの各クライアント)に対して計算され、得られた値は法を合計し、i番目の特徴の最終的な重要性が取得されます。
これらの計算は非常に高価であるため、さまざまな最適化アルゴリズムが内部で使用されます。詳細については、上記のgithubのリンクを参照してください。
xgboostのドキュメントからバニラの例を取り上げます 。
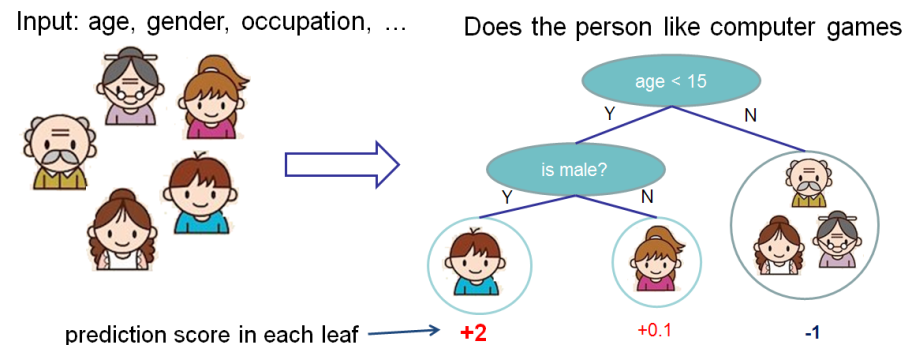
人がコンピューターゲームを好むかどうかを予測するための機能の重要性を評価したいと思います。
この例では、簡単にするために、年齢(年齢)と性別(性別)の2つの機能があります。 性別(性別)の値は0と1です。
ボビー(ツリーの左端のノードにいる小さな男の子)を取り上げて、特徴年齢(年齢)に対するシャプレーの値を計算します。
S機能には2つのセットがあります。
-機能なし
-機能の性別のみがあります。
機能値がない状況
データサンプルに機能がない場合、つまり、すべての機能で値がNULLの場合、異なるモデルは異なる動作をします。
この場合、モデルは木の枝で予測を平均化する、つまり、特徴のない予測は 。
年齢の知識を追加すると、モデルの予測は次のようになります。 。
結果として、機能がない場合のShapleyの価値:
性別を知っている状況
ボビー用 フィーチャの年齢なしで、フィーチャの性別のみが等しい予測 。 年齢がわかっている場合、予測は左端のツリー、つまり2です。
その結果、この場合のシャプレーの価値は次のとおりです。
$$ display $$ \ begin {equation *} \ frac {| S |!(n-| S | -1)!} {n!}(p(S \ cup \ {i \})-p(S) )= \ frac {1(2-1-1)!} {2!}(1.975)= 0.9875 \ end {equation *} $$ display $$
要約する
フィーチャの年齢(年齢)に対するShapleyの合計値:
$$ display $$ \ begin {equation *} \ phi_ {Age Bobby} = 0.9875 + 0.5125 = 1.5 \ end {equation *} $$ display $$
実際のビジネス例
SHAPライブラリには、モデルの妥当性を評価するために、ビジネスとアナリスト自身の両方のモデルを簡単かつ簡単に説明するのに役立つ豊富な視覚化機能があります。
プロジェクトの1つで、会社からの従業員の流出を分析しました。 使用されたモデルはxgboostでした。
Pythonのコード:
import shap shap_test = shap.TreeExplainer(best_model).shap_values(df) shap.summary_plot(shap_test, df, max_display=25, auto_size_plot=True)
結果の重要度グラフ:
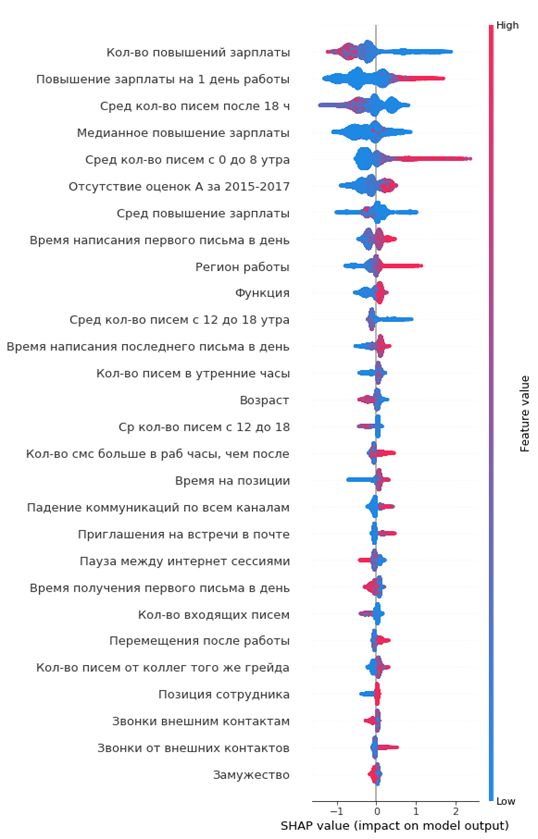
読み方:
- 中央の垂直線の左側の値は負のクラス(0)、右側の値は正(1)です。
- グラフ上の線が太いほど、そのような観測点が多くなります
- グラフ上のポイントが赤くなるほど、その中の特徴が高くなります
グラフから、興味深い結論を導き出し、その妥当性を確認できます。
- 従業員の昇給が少ないほど、離職の可能性が高くなります
- 流出が多いオフィスの地域があります
- 従業員が若いほど、離職の可能性が高くなります
- ...
すぐに出社する従業員の肖像画を作成できます。彼女は昇給を受けていませんでした、彼は十分に若く、独身で、1つのポジションで長い間、グレードアップがありませんでした、年次の高い評価がありませんでした、彼は同僚とほとんどコミュニケーションを取りませんでした。
シンプルで便利!
特定の従業員の予測を説明できます。

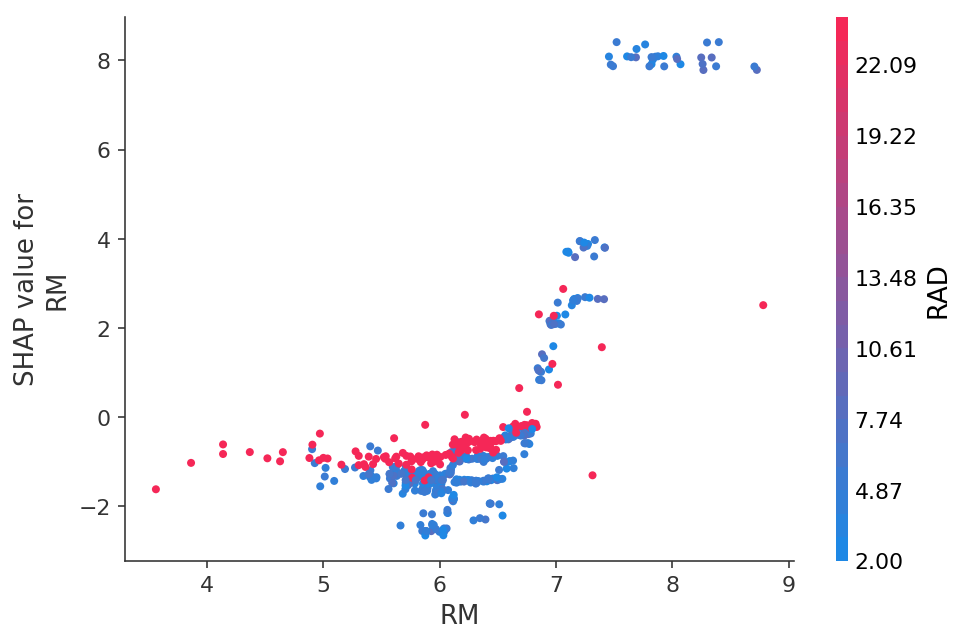
または、2Dグラフの形式で特定の機能に対する予測の依存性を確認します。
ニューラルネットワークの予測を写真で視覚化することもできます。

おわりに
私自身は約6か月前にSHAP値について学びましたが、これは機能の重要性を評価する他の方法を完全に置き換えました。
主な利点:
- 便利な視覚化と解釈
- 機能の重要性の正直な計算
- データの特定のサブサンプルの機能を評価する機能(たとえば、顧客がサンプル内の他の顧客とどのように異なるか)は、pandasのデータセットの単純なフィルターと、文字列で数行のコードでのその分析によって行われます