ソーシャルネットワークの中で、Twitterは、ユーザーが最も必要不可欠なものをすべて入れなければならないメッセージの長さに厳しい制限があるため、テキストデータの抽出に他よりも適しています。
この単語クラウドがどのテクノロジーをフレーム化するか推測することをお勧めします
Twitter APIを使用すると、さまざまな情報を抽出して分析できます。 プログラミング言語Rでこれを行う方法に関する記事。
コードの作成にそれほど時間はかかりません。TwitterAPIの変更と強化により困難が生じる可能性があります。明らかに、2016年の米国の選挙に対する「ロシアのハッカー」の影響の調査後、 米国議会で引きずり出された後、同社はセキュリティ問題を真剣に懸念していました 。
アクセスAPI
なぜ誰かがTwitterから産業データを取得する必要があるのですか? たとえば、スポーツイベントの結果に関するより正確な予測を行うのに役立ちます。 しかし、他のユーザーシナリオもあると確信しています。
開始するには、電話番号のあるTwitterアカウントが必要であることは明らかです。 これはアプリケーションを作成するために必要です。APIへのアクセスを提供するのはこのステップです。
開発者のページに移動し、[ アプリの作成 ]ボタンをクリックします。 次は、アプリケーションに関する情報を入力する必要があるページです。 現在、ページは次のフィールドで構成されています。
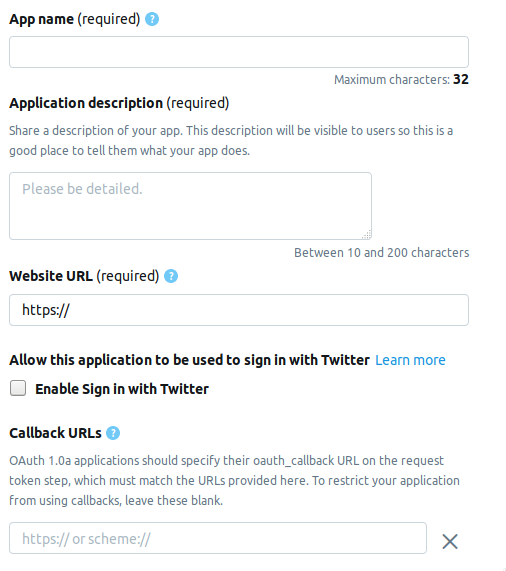
- AppName-アプリケーション名(必須)。
- アプリケーションの説明 -アプリケーションの説明(必須)。
- WebサイトのURL-アプリケーションのWebサイトのページ(必須)。URLのように見えるものなら何でも入力できます。
- Twitterでサインインを有効にする (チェックボックス) -Twitterのアプリケーションのページからログインします。スキップできます。
- コールバックURL-認証中のアプリケーションのコールバック (必須)および必要な場合は、
http://127.0.0.1:1410
ままにしてください。
オプションのフィールドは次のとおりです。利用規約のページのアドレス、組織の名前など。
開発者アカウントを作成するとき、3つの可能なオプションのいずれかを選択する必要があります。
- 標準 -基本バージョン。深さ≤7日までのレコードを無料で検索できます。
- プレミアム -より高度なオプションで、2006年から30日以内の深さまでレコードを検索できます。無料ですが、アプリケーションを検討した後すぐには提供されません。
- エンタープライズ -ビジネスクラス、有料の信頼できる関税。
Premiumを選択しましたが、承認までに約1週間かかりました。 連中にそれを渡してくれるかどうかを全員に伝えることはできませんが、試してみる価値はあります。 スタンダードはどこにも行かないでしょう。
Twitter接続
アプリケーションを作成すると、次の要素を含むセットが[ キーとトークン ]タブに表示されます。 以下は、Rの名前と対応する変数です。
コンシューマーAPIキー
- APIキー
api_key
- API秘密鍵
api_secret
アクセストークンとアクセストークンシークレット
- アクセストークン
access_token
- アクセストークンシークレット
access_token_secret
必要なパッケージをインストールします。
install.packages("rtweet") install.packages("tm") install.packages("wordcloud")
このコードは次のようになります。
library("rtweet") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret)
認証後、Rは後で使用するためにOAuth
コードをディスクに保存するように求めます。
[1] "Using direct authentication" Use a local file to cache OAuth access credentials between R sessions? 1: Yes 2: No
どちらのオプションも受け入れられます。1番目を選択しました。
結果の検索とフィルター
tweets <- search_tweets("hadoop", include_rts=FALSE, n=600)
include_rts
キーを使用すると、リツイートを検索に含めるか除外するかを制御できます。 出力では、各レコードの詳細と詳細がある多くのフィールドを持つテーブルを取得します。 これが最初の20です。
> head(names(tweets), n=20) [1] "user_id" "status_id" "created_at" [4] "screen_name" "text" "source" [7] "display_text_width" "reply_to_status_id" "reply_to_user_id" [10] "reply_to_screen_name" "is_quote" "is_retweet" [13] "favorite_count" "retweet_count" "hashtags" [16] "symbols" "urls_url" "urls_t.co" [19] "urls_expanded_url" "media_url"
より複雑な検索文字列を作成できます。
search_string <- paste0(c("data mining","#bigdata"),collapse = "+") search_tweets(search_string, include_rts=FALSE, n=100)
検索結果はテキストファイルに保存できます。
write.table(tweets$text, file="datamine.txt")
テキストの本文にマージし、サービスワード、句読点からフィルタリングし、すべてを小文字に変換します。
別の検索機能がありますsearchTwitter
、これにはtwitteR
ライブラリーが必要です。 ある意味ではsearch_tweets
より便利ですが、ある意味では劣っています。
プラス -時間によるフィルターの存在。
tweets <- searchTwitter("hadoop", since="2017-09-01", n=500) text = sapply(tweets, function(x) x$getText())
マイナス -出力はテーブルではなく、 status
タイプのオブジェクトです。 この例で使用するには、出力からテキストフィールドを抽出する必要があります。 これにより、2行目に表示されます。
corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "hadoop", stopwords("english")), removeNumbers = TRUE, tolower = TRUE))
2行目の絵文字を小文字に変換するにtm_map
、 tm_map
関数tm_map
必要です。そうしないと、 tolower
を使用した小文字への変換が失敗します。
単語雲の構築
単語の雲は、私が知る限り、 Flickrの写真ホスティングで最初に登場し、それ以来人気を博しています。 このタスクには、 wordcloud
ライブラリが必要です。
m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
search_string
関数を使用すると、言語をパラメーターとして設定できます。
search_tweets(search_string, include_rts=FALSE, n=100, lang="ru")
ただし、RのNLPパッケージはロシア語化が不十分であるため、特にサービスやストップワードのリストがないため、ロシア語で検索して単語クラウドを構築することに成功しませんでした。 コメントでより良い解決策を見つけていただければ幸いです。
まあ、実際に...
library("rtweet") library("tm") library("wordcloud") api_key <- "" api_secret <- "" access_token <- "" access_token_secret <- "" appname="" setup_twitter_oauth ( api_key, api_secret, access_token, access_token_secret) oauth_callback <- "http://127.0.0.1:1410" setup_twitter_oauth (api_key, api_secret, access_token, access_token_secret) appname="my_app" twitter_token <- create_token(app = appname, consumer_key = api_key, consumer_secret = api_secret) tweets <- search_tweets("devops", include_rts=FALSE, n=600) corpus <- Corpus(VectorSource(tweets$text)) clearCorpus <- tm_map(corpus, function(x) iconv(enc2utf8(x), sub = "byte")) tdm <- TermDocumentMatrix(clearCorpus, control = list(removePunctuation = TRUE, stopwords = c("com", "https", "drupal", stopwords("english")), removeNumbers = TRUE, tolower = TRUE)) m <- as.matrix(tdm) word_freqs <- sort(rowSums(m), decreasing=TRUE) dm <- data.frame(word=names(word_freqs), freq=word_freqs) wordcloud(dm$word, dm$freq, scale=c(3, .5), random.order=FALSE, colors=brewer.pal(8, "Dark2"))
使用済みの材料。
短いリンク:
- Twitterデータの収集:はじめに
- Rを使用して人気のセンチメントをマイニングおよび分析する
- Twitter APIを使用してデータを収集する
- Rを使用したTwitterデータの探索
- tmパッケージの概要、Rでのテキストマイニング
元のリンク:
https://stats.seandolinar.com/collecting-twitter-data-getting-started/
https://opensourceforu.com/2018/07/using-r-to-mine-and-analyse-popular-sentiments/
http://dkhramov.dp.ua/images/edu/Stu.WebMining/ch17_twitter.pdf
http://opensourceforu.com/2018/02/explore-twitter-data-using-r/
https://cran.r-project.org/web/packages/tm/vignettes/tm.pdf
PSヒント、KDPVのクラウドキーワードはプログラムで使用されていません。 以前の記事に関連しています 。