こんにちは、私の名前はVera Sivakovaです。 私はYandex.Kassiの主要パートナーと仕事をしています。大規模な店舗やサービスを結び、プロジェクトを立ち上げ、世界中の会議に参加しています。 一般に、私はすべてが順調だったと言います。
Yandex.Moneyのすべての従業員は、年に一度職業を変えることができます。部門を選択して、数日間そこで働きます。 したがって、一ヶ月前、私はサプサンに座ってサンクトペテルブルクに到着しました。 監視部門がそこで働いており、キャッシャーに接続されている90,000のサイトがすべて良好であることを監視しており、私たちは力を合わせることにしました。

狂わないようにするには? まったく同じではありません (ソース:reddit.com)
これは、監視がどのように機能するかについての物語であり、数日のうちに別の部門で学んだことです。
毎秒、約600のトランザクションがサービスを通過し、これらすべてをリアルタイムで監視する必要がありますが、何か正確な時間に何かが発生した場合にアラームを鳴らすのはいつですか? ほぼすべてを体系的に確認する必要があります。
技術的な観点からシステムを分析することをお勧めします。ビジネスの指標(支払い回数、売り上げなどのパラメーター)を忘れないでください。
小規模なシステムでは、メイン(ほとんどの場合唯一)の管理者の鋭い外観で十分です。 しかし、多くのプロセスがある場合、従業員はすべてを手動で監視することはできないため、最大限の自動化が最善の戦略になります。 監視は継続的な改善、分析、および有能なメトリックとトリガーを選択する機能であるため、専門知識とチームの努力なしでは何も機能しません。 指定された条件から逸脱した場合に機能し、異常を報告します。
監視の3つのレベルを区別します。各レベルには、システムのレベル、ビジネスロジックのレベル、カウンターパーティのレベルという重要な指標があります。
システムレベル
ここで最も重要なことは、インフラストラクチャの24時間監視です。 Zabbixを使用してリアルタイムでデータを収集するツールのうち、サーバーとデータセンターの運用、ネットワークの品質、コンポーネントとデータソースの可用性を通知します。
ITインフラストラクチャの監視は非常に責任のある仕事です。このレベルでの障害にはシステムの動作不能と必死の対策が伴うためです。 したがって、「フラッシュ」問題に対応するだけでなく、傾向と履歴データを分析することも重要です。これにより、潜在的な障害点をタイムリーに警告し、スケーリングの必要性を予測できます。 このルールは、ビジネスを含むすべてのインジケーターと監視レベルで機能します。
重要なポイントについては、トリガーしきい値を以下で選択する必要があります。 たとえば、あるルーターからの応答時間が増加した場合、トラフィックを別のルーターに転送し、最初のルーターの理由を排除します。 これにより警告トリガーがトリガーされ、潜在的な問題の通知を事前に受け取ることができます。これにより、応答のための時間を確保し、変更を予測して災害を回避することができます。
ビジネスロジックレベル
各チームは、追跡する必要のあるプロセス、優先順位、および個人のメトリックを定義します。 たとえば、キャッシャーチームには、カード、電子財布、オンラインバンクや端末、モバイルコマース、レジスター送信など、利用可能な各方法による支払いなど、多数のビジネスプロセスがあります。 ビジネスロジックの作業に関するデータを収集および表示するための主要なツールとして、Grafanaと組み合わせてGraphiteを使用します。
このレベルでは、体系的なアプローチを堅持し、バイナリで情報価値のない「機能する/機能しない」から逃れるようにすることが重要です。
たとえば、メトリック「成功したカード支払いの数」があります。 点滅し始めたら、ワークフローが減少していることを意味します。 この場合、正確な理由を理解し、このプロセスに関係するすべてのコンポーネントを考慮する必要があります。 取引数が減少した場合、買収銀行側に困難があるという事実をすぐに考えることができます。 しかし、グラフは、銀行が利用可能であれば、すべてがうまくいくことを示しています。 その後、さらに調査する必要があり、最終的には、たとえば、すべての質問がレイアウト内にあることがわかります。何らかの理由で、「Pay」ボタンが消えたり、非アクティブになりました。
取引先レベル
ここでは、銀行や商人の買収など、特定の取引相手について話しています。
取得者用に個別のスケジュールとトリガーを選択しました。これらの可用性は常に追跡する必要があります。 私たちにとって、支払いサービスとして、安定性は非常に重要です。したがって、銀行の1つに障害が発生した場合、直ちにフローを準備金に転送します。

1つの銀行が故障したが、別の銀行は自動的に接続された
エラーが開始された場合、タイムリーに適切にワークフローをリダイレクトすることを学びました。
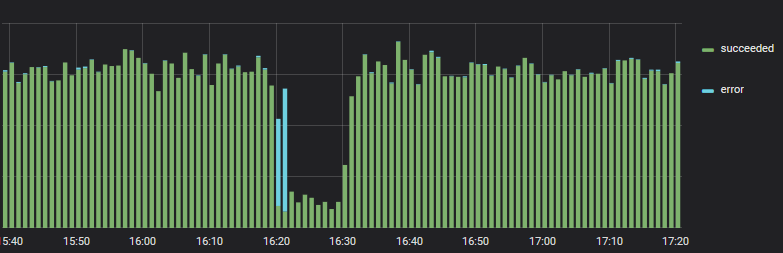
銀行の1つが支払いエラーの増加を記録しました
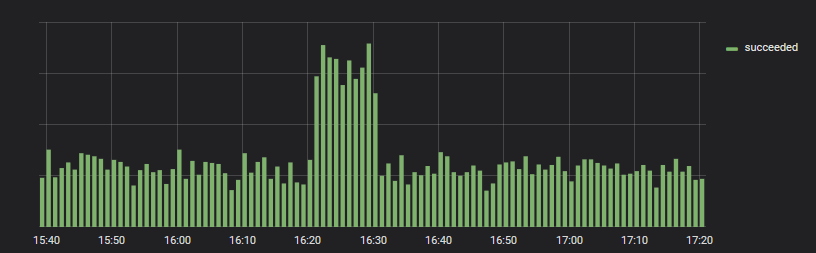
翻訳済み-そしてすべてが順調です。 Y軸の値は釣り合っていない
取得者は、既に説明したレベル(システムとビジネスロジック)でさまざまな理由で失敗する可能性があります。 誰も予期しない問題の影響を受けず、100%の可用性を保証できません。 また、問題の進行状況を綿密に監視する必要がある場合は、計画されている技術的な作業とリリースについても覚えておく必要があります。 単純なことはビジネスの支払いを停止することを意味するため、冗長性と自動切り替えの問題は重要です。
ダウンタイムのリスクを最小限に抑え、SRカードの支払いを最適化するために、複数の銀行と一度に連携しています。 SR(成功率)またはコンバージョンは、トランザクションの総数に対する成功した支払いの数の比率として計算されるビジネスメトリックです。 さまざまな会社が独自の方法でコンバージョンを測定します。たとえば、誰かが支払いページから測定を開始し、他の会社は「支払い」ボタンをクリックした後に測定を開始します。 しかし、一般に、SRは多くの異なる要因(MCC、支払いに3D-Secureが存在するかどうか、支払人の地域、定期的な支払いかどうか)の影響を受けます。 「病院平均」SRは、決定することは不可能であり、知る必要はありません。それぞれの場合、最適化する必要がある独自の価値になります。
さまざまなエラーは、2つの大きなグループに分類できます。
- 防止できるエラー -たとえば、この国からの支払いは禁止されています。 これが不正な攻撃ではないと確信し、世界中にユーザーがいる場合は、この場合、発行者のカードからの支払いの可能性を関連付ける必要があります。 ちなみに、これはYandex Cashierの個人アカウントで行うことができます。
- 影響を受けないエラー -たとえば、カードがロックされています。 ここでは、新しいトランザクションの一部として別のカードで再発行または支払いを繰り返す試みのみが役立ちます。
多くは、レートで支払いプロバイダーを選択します。 実際、考慮すべき値はレートだけではありません。 成功した支払い(SR)の割合も確認する必要があります。これは、誰も100%のコンバージョンを達成できず、この値は銀行によって大きく異なるためです。 また、ユーザーシナリオが一般的にどのように見えるかを考慮する必要があります。支払い前に何ステップを経る必要があるか、インターフェースが明確であるかどうかなどです。
変換が利益に与える影響
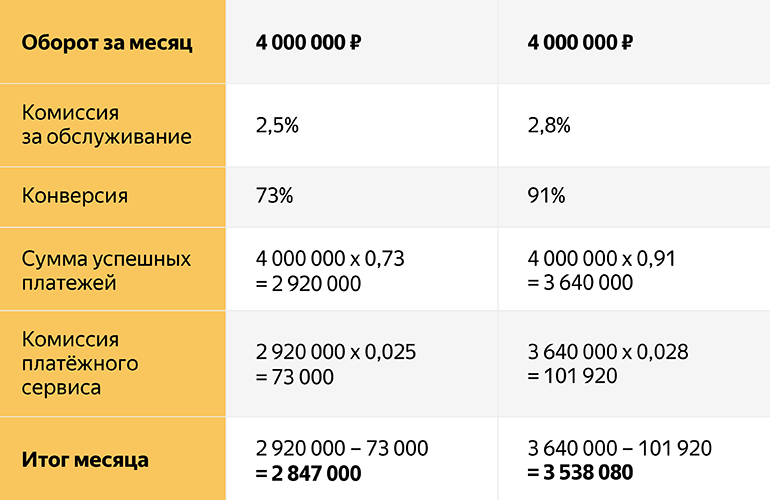
2番目のケースでは、サービスの手数料は高くなりますが、予約と有能なゲートウェイ構成が使用されるため、変換も高くなります。
例からわかるように、ビジネスにとってより良いソリューションは、より良いサービスを利用することであり、取得の質の違いにより手数料が高くなるという事実にもかかわらず、最終的には月あたり3 538 080-2 847 000 = 691 080ルーブルの差があります! そして、これは年間800万であり、これはビジネスにとって大きなお金です。
変換、回転率、レートは任意ですが、この例は、サービスの主なものがその安定性と品質であることを示しています。 そして、これはすでにコンバージョンの増加を伴い、結果として、商人の売上高が増加します。
マーチャントの接続方法
前述のように、イベントで自動的に発生するメトリックとトリガーで可能な限りすべてをカバーしようとします。 いずれかの商人を監視する例で、すべてがどのように起こるかを見てみましょう。
キャッシャーに接続した後、必要に応じて商人が監視されます。 Grafanaでグラフを作成し、指定された「正常な」値から逸脱した場合に自動アラートがトリガーされるメトリックを設定します。
Moiraを使用して、監視グループのチャットに通知を送信し、詳細をすばやく確認します。 通知には、インシデントへのスケジュールと詳細へのリンクが含まれています。

ボットからのメッセージの絶対に実際の例
グラフを分析した後、監視チームの専門家はほとんどの場合、Kibanaを使用してログを表示します。 この場合、状況は散発的である可能性があり、ログでは明らかにエラーが表示されるか、失敗の原因を分析するためにアナリストの追加参加が必要になります。
将来的には、サーバーへのアクセス不能やプロトコル以外の応答など、サイドのエラーに関する販売者への自動通知を設定したいと考えています。 これにより、障害に迅速に対応し、原因に対処するためのカウンターパーティ情報を提供できます。
技術面に加えて、売上高、収入、流出などのビジネス指標も注意深く監視しますが、これは次の記事のトピックのようです。
最も重要なこと
私の「不服従の日」(これは私たちが一時的に別の部門に移行することです)が終わり、モスクワに戻りました。 監視部門で2日間、多くのことを学び、現在の知識を合理化しました。
- 監視タスクは、すべてのレベルでシステムの状態に関する関連情報を提供することです。
- 有能な指標とトリガーを選択-90%成功;
- 支払いサービスでは、コンバージョンが入札に当たります。
- この手法に従って、ビジネスメトリックについて覚えておく必要があります。
- プロセスの体系的なビューと関係を分析する能力が必要です。
そしてまだ-ありがたい。 みんな監視してくれてありがとう!
それだけです 質問をし、私たちのブログを購読し、訪問してください。