
Pythonでの完全な機械学習のウォークスルー:パート2
機械学習プロジェクトのすべての部分をまとめるのは難しい場合があります。 このシリーズの記事では、実際のデータを使用した機械学習プロセスの実装のすべての段階を経て、さまざまな手法がどのように組み合わされているかを調べます。
最初の記事では、データのクリーニングと構造化、探索的分析の実施、モデルで使用するための属性セットの収集、および結果を評価するためのベースラインの設定を行いました。 この記事の助けを借りて、Pythonでの実装方法を学習し、いくつかの機械学習モデルを比較し、ハイパーパラメトリックチューニングを実行して最適なモデルを最適化し、テストデータセットで最終モデルのパフォーマンスを評価します。
すべてのプロジェクトコードはGitHubにあり、現在の記事に関連する2番目のメモ帳があります 。 必要に応じてコードを使用および変更できます!
モデルの評価と選択
メモ: ニューヨークの建物のエネルギー情報を使用して 、特定の建物がどのエネルギースタースコアを受け取るかを予測するモデルを作成する、制御回帰タスクに取り組んでいます。 予測の精度とモデルの解釈可能性の両方に関心があります。
現在、 多くの利用可能な機械学習モデルから選択することができ、この豊富さは威圧的です。 もちろん、アルゴリズムを選択する際にナビゲートするのに役立つ比較レビューがネットワーク上にありますが、作業中にいくつか試して、どちらが優れているかを確認することを好みます。 ほとんどの場合、機械学習は理論的な結果ではなく経験的な結果に基づいており、 どのモデルがより正確であるかを事前に理解することはほとんど不可能です。
通常、線形回帰などの単純で解釈可能なモデルから開始し、結果が満足できない場合は、より複雑ですが通常はより正確な方法に進むことをお勧めします。 このグラフ(非常に反科学的)は、いくつかのアルゴリズムの精度と解釈可能性の関係を示しています。

解釈可能性と正確性( ソース )。
さまざまな複雑度の5つのモデルを評価します。
- 線形回帰。
- k最近傍の方法。
- 「ランダムフォレスト。」
- 勾配ブースティング。
- サポートベクターの方法。
これらのモデルの理論的な装置ではなく、それらの実装を検討します。 理論に興味がある場合は、 統計学習の紹介 (無料で利用可能)またはScikit-LearnおよびTensorFlowを使用したハンズオン機械学習をご覧ください 。 両方の本で、理論は完全に説明されており、言及されたメソッドをRおよびPython言語で使用することの有効性がそれぞれ示されています。
欠損値を埋める
データをクリアしたときに、値の半分以上が欠落している列を破棄しましたが、まだ多くの値があります。 機械学習モデルは欠損データを処理できないため、データを入力する必要があります。
最初に、データを検討し、どのように見えるかを思い出します。
import pandas as pd import numpy as np # Read in data into dataframes train_features = pd.read_csv('data/training_features.csv') test_features = pd.read_csv('data/testing_features.csv') train_labels = pd.read_csv('data/training_labels.csv') test_labels = pd.read_csv('data/testing_labels.csv') Training Feature Size: (6622, 64) Testing Feature Size: (2839, 64) Training Labels Size: (6622, 1) Testing Labels Size: (2839, 1)
各
NaN
値は、データ内の欠落したレコードです。 それらはさまざまな方法で入力できます。かなり単純な中央値代入法を使用します。これは、欠損データを対応する列の平均値に置き換えます。
以下のコードでは、中央値戦略でScikit-Learn Imputer
Imputer
を作成します。 次に、トレーニングデータでトレーニングし(
imputer.fit
を使用)、トレーニングセットとテストセットの欠損値を埋めるために適用します(
imputer.transform
を使用)。 つまり、 テストデータにないレコードには、 トレーニングデータからの対応する中央値が入力されます 。
テストデータセットからの情報がトレーニングに入るときにテストデータが漏洩する問題を回避するために、データのモデルをそのままトレーニングしません。
# Create an imputer object with a median filling strategy imputer = Imputer(strategy='median') # Train on the training features imputer.fit(train_features) # Transform both training data and testing data X = imputer.transform(train_features) X_test = imputer.transform(test_features) Missing values in training features: 0 Missing values in testing features: 0
これですべての値が入力され、ギャップはなくなりました。
機能のスケーリング
スケーリングは、特性の範囲を変更する一般的なプロセスです。 記号は異なる単位で測定されるため、これは必要な手順です。つまり、それらは異なる範囲をカバーします。 これは、測定値間の距離を考慮に入れるサポートベクトル法やk最近傍法などのアルゴリズムの結果を大きく歪めます。 また、スケーリングによりこれを回避できます。 また、 線形回帰や「ランダムフォレスト」などの方法では機能のスケーリングは必要ありませんが、いくつかのアルゴリズムを比較する際にこのステップを無視しない方がよいでしょう。
各属性を使用して0〜1の範囲にスケーリングします。属性のすべての値を取得し、最小値を選択して、最大値と最小値の差(範囲)で除算します。 このスケーリング方法はしばしば正規化と呼ばれ、他の主な方法は標準化です。
このプロセスは手動で簡単に実装できるため、Scikit-Learnの
MinMaxScaler
オブジェクトを使用します。 このメソッドのコードは、欠損値を埋めるためのコードと同じです。貼り付けの代わりにスケーリングのみが使用されます。 トレーニングセットでのみモデルを学習し、すべてのデータを変換することを思い出してください。
# Create the scaler object with a range of 0-1 scaler = MinMaxScaler(feature_range=(0, 1)) # Fit on the training data scaler.fit(X) # Transform both the training and testing data X = scaler.transform(X) X_test = scaler.transform(X_test)
現在、各属性の最小値は0、最大値は1です。欠損値の入力と属性のスケーリング-これら2つの段階は、ほとんどすべての機械学習プロセスで必要です。
Scikit-Learnで機械学習モデルを実装します
すべての準備作業の後、モデルの作成、トレーニング、実行のプロセスは比較的簡単です。 PythonのScikit-Learnライブラリを使用します。Scikit-Learnライブラリは、文書化されており、モデルを構築するための精巧な構文を備えています。 Scikit-Learnでモデルを作成する方法を学習することにより、あらゆる種類のアルゴリズムをすばやく実装できます。
勾配ブースティングを使用した作成、トレーニング(
.fit
)、およびテスト(
.predict
)のプロセスを説明します。
from sklearn.ensemble import GradientBoostingRegressor # Create the model gradient_boosted = GradientBoostingRegressor() # Fit the model on the training data gradient_boosted.fit(X, y) # Make predictions on the test data predictions = gradient_boosted.predict(X_test) # Evaluate the model mae = np.mean(abs(predictions - y_test)) print('Gradient Boosted Performance on the test set: MAE = %0.4f' % mae) Gradient Boosted Performance on the test set: MAE = 10.0132
作成、トレーニング、テスト用の1行のコード。 他のモデルを構築するには、同じ構文を使用して、アルゴリズムの名前のみを変更します。

モデルを客観的に評価するために、目標の中央値を使用してベースラインを計算し、24.5を得ました。 また、結果ははるかに優れていたため、機械学習を使用して問題を解決できます。
この場合、 勾配ブースティング (MAE = 10.013)は、「ランダムフォレスト」(10.014 MAE)よりもわずかに優れていることが判明しました。 これらの結果は完全に正直であるとは見なせませんが、ハイパーパラメーターではほとんどの場合デフォルト値を使用するためです。 モデルの有効性は、これらの設定、 特にサポートベクトル法に強く依存します。 それでも、これらの結果に基づいて、勾配ブースティングを選択し、最適化を開始します。
ハイパーパラメトリックモデルの最適化
モデルを選択した後、ハイパーパラメータを調整することで、手元のタスク用にモデルを最適化できます。
しかし、まず最初に、 ハイパーパラメーターとは何か、通常のパラメーターとどのように違うのかを理解しましょう。
- モデルのハイパーパラメーターは、トレーニングの開始前に設定したアルゴリズムの設定と考えることができます。 たとえば、ハイパーパラメーターは、「ランダムフォレスト」のツリー数、またはk最近傍法の近傍数です。
- モデルパラメーター-彼女がトレーニング中に学習すること。たとえば、線形回帰の重み。
ハイパーパラメーターを制御することにより、モデルの結果に影響を与え、 教育不足と再訓練のバランスを変更します。 学習中とは、モデルが複雑でなく(自由度が少なすぎる)、サインと目標の対応を研究できない状況です。 訓練不足のモデルには高いバイアスがあり、モデルを複雑にすることで修正できます。
再トレーニングは、モデルが基本的にトレーニングデータを記憶している状況です。 再トレーニングされたモデルには高い分散があり、正規化によりモデルの複雑さを制限することで調整できます。 十分に訓練されていないモデルと再訓練されたモデルの両方は、テストデータを適切に一般化できません。
適切なハイパーパラメータを選択することの難しさは、各タスクに固有の最適なセットがあることです。 したがって、最適な設定を選択する唯一の方法は、新しいデータセットでさまざまな組み合わせを試すことです。 幸いなことに、Scikit-Learnには、ハイパーパラメーターを効率的に評価するための多くの方法があります。 さらに、 TPOTのようなプロジェクトは、 遺伝的プログラミングなどのアプローチを使用してハイパーパラメーターの検索を最適化しようとしています 。 この記事では、Scikit-Learnの使用に限定します。
クロスチェックランダム検索
ランダム相互検証ルックアップと呼ばれるハイパーパラメーター調整メソッドを実装しましょう。
- ランダム検索 -ハイパーパラメーターを選択する手法。 グリッドを定義してから、そこからさまざまな組み合わせをランダムに選択します。これは、各組み合わせを連続して試行するグリッド検索とは対照的です。 ちなみに、 ランダム検索はグリッド検索とほぼ同じように機能しますが、はるかに高速です。
- クロスチェックは、ハイパーパラメーターの選択された組み合わせを評価する方法です。 データをトレーニングセットとテストセットに分割してトレーニングに使用できるデータ量を削減する代わりに、kブロックのクロス検証(Kフォールドクロス検証)を使用します。 これを行うには、トレーニングデータをkブロックに分割し、反復プロセスを実行します。このプロセスでは、最初にk-1ブロックでモデルをトレーニングし、次にk番目のブロックで学習したときの結果を比較します。 プロセスをk回繰り返し、最終的に各反復の平均エラー値を取得します。 これが最終評価になります。
以下は、k = 5でのkブロックの交差検証の図解です。

相互検証ランダム検索プロセス全体は次のようになります。
- ハイパーパラメーターのグリッドを設定します。
- ハイパーパラメーターの組み合わせをランダムに選択します。
- この組み合わせを使用してモデルを作成します。
- kブロックの交差検証を使用して、モデルの結果を評価します。
- 最適な結果が得られるハイパーパラメーターを決定します。
もちろん、これはすべて手動ではなく、Scikit-Learn!の
RandomizedSearchCV
して行われます。
小さな余談: 勾配ブースティング法
勾配ブーストベースの回帰モデルを使用します。 これは集合的な方法です。つまり、モデルは多数の「弱学習器」で構成されています。この場合、個々の決定木からのものです。 生徒が「ランダムフォレスト」などの並列アルゴリズムで学習し、予測結果が投票によって選択された場合、勾配ブースティングなどのブースティングアルゴリズムでは、生徒は順番に訓練され、それぞれが前任者のミスに「集中」します。
近年、ブースティングアルゴリズムが一般的になり、多くの場合、機械学習のコンテストで優勝しています。 勾配ブースティングは、勾配降下を使用して関数のコストを最小化する実装の1つです。 Scikit-Learnでの勾配ブースティングの実装は、 XGBoostなどの他のライブラリほど効果的ではないと見なされますが、小さなデータセットでうまく機能し、かなり正確な予測を提供します。
ハイパーパラメトリック設定に戻る
勾配ブースティングを使用した回帰では、設定が必要なハイパーパラメーターが多数あります。詳細については、Scikit-Learnのドキュメントを参照してください。 最適化を行います:
-
loss
:損失関数の最小化。 -
n_estimators
:使用される弱い決定木の数(決定木); -
max_depth
:各決定木の最大深さ; -
min_samples_leaf
:デシジョンツリーの「リーフ」ノードにあるサンプルの最小数。 -
min_samples_split
:決定木ノードを分割するために必要な例の最小数。 -
max_features
:ノードの分離に使用される機能の最大数。
すべてがどのように機能するかを本当に理解している人がいるかどうかはわかりません。最適な組み合わせを見つける唯一の方法は、さまざまなオプションを試すことです。
このコードでは、ハイパーパラメーターのグリッドを作成してから、
RandomizedSearchCV
オブジェクトを作成し、25個の異なるハイパーパラメーターの組み合わせに対して4ブロックの交差検証を使用して検索します。
# Loss function to be optimized loss = ['ls', 'lad', 'huber'] # Number of trees used in the boosting process n_estimators = [100, 500, 900, 1100, 1500] # Maximum depth of each tree max_depth = [2, 3, 5, 10, 15] # Minimum number of samples per leaf min_samples_leaf = [1, 2, 4, 6, 8] # Minimum number of samples to split a node min_samples_split = [2, 4, 6, 10] # Maximum number of features to consider for making splits max_features = ['auto', 'sqrt', 'log2', None] # Define the grid of hyperparameters to search hyperparameter_grid = {'loss': loss, 'n_estimators': n_estimators, 'max_depth': max_depth, 'min_samples_leaf': min_samples_leaf, 'min_samples_split': min_samples_split, 'max_features': max_features} # Create the model to use for hyperparameter tuning model = GradientBoostingRegressor(random_state = 42) # Set up the random search with 4-fold cross validation random_cv = RandomizedSearchCV(estimator=model, param_distributions=hyperparameter_grid, cv=4, n_iter=25, scoring = 'neg_mean_absolute_error', n_jobs = -1, verbose = 1, return_train_score = True, random_state=42) # Fit on the training data random_cv.fit(X, y) After performing the search, we can inspect the RandomizedSearchCV object to find the best model: # Find the best combination of settings random_cv.best_estimator_ GradientBoostingRegressor(loss='lad', max_depth=5, max_features=None, min_samples_leaf=6, min_samples_split=6, n_estimators=500)
これらの最適値に近いグリッドのパラメーターを選択することにより、これらの結果をグリッド検索に使用できます。 ただし、さらにチューニングしてもモデルが大幅に改善されることはほとんどありません。 一般的なルールがあります:有能なフィーチャの構築は、最も高価なハイパーパラメトリックセットアップよりもモデルの精度にはるかに大きな影響を与えます。 これは、 機械学習に関連して収益性を低下させる法則です 。属性の設計は最高の利益をもたらし、ハイパーパラメトリックチューニングはわずかな利点しかもたらしません。
他のハイパーパラメーターの値を保持しながら推定器(決定木)の数を変更するには、この設定の役割を示す1つの実験を実行できます。 実装はここにありますが、結果は次のとおりです。
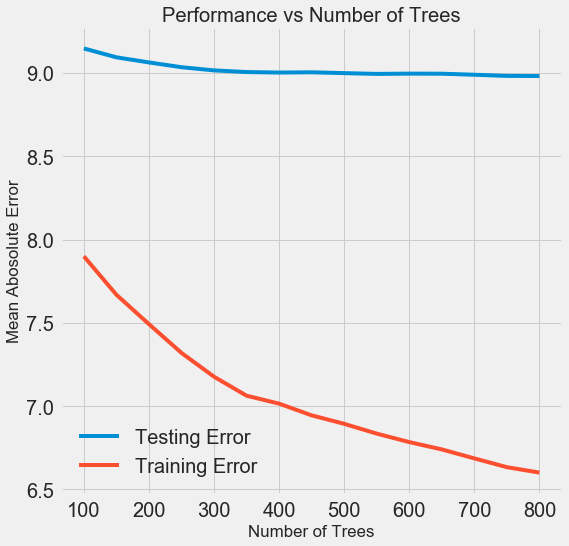
モデルで使用されるツリーの数が増えると、トレーニングおよびテスト中のエラーのレベルが低下します。 しかし、学習エラーははるかに速く減少し、その結果、モデルは再トレーニングされます。トレーニングデータでは優れた結果を示しますが、テストデータでは悪化します。
テストデータでは、精度は常に低下します(結局、モデルはトレーニングデータセットの正しい答えを確認します)が、大幅な低下は再トレーニングを示します 。 この問題は、トレーニングデータの量を増やすか、 ハイパーパラメーターを使用してモデルの複雑さを軽減することで解決できます。 ここでは、ハイパーパラメーターについては触れませんが、再トレーニングの問題に常に注意することをお勧めします。
最終モデルでは、800人の評価者が必要になります。これは、相互検証で最も低いレベルのエラーを与えるためです。 次に、モデルをテストしてください!
テストデータを使用した評価
責任者として、トレーニング中にモデルがテストデータにアクセスできないようにしました。 したがって、 テストデータを実際のタスクに使用する場合のモデル品質指標として使用する場合、精度を使用できます 。
モデルテストデータをフィードし、エラーを計算します。 以下は、デフォルトの勾配ブースティングアルゴリズムとカスタマイズされたモデルの結果の比較です。
# Make predictions on the test set using default and final model default_pred = default_model.predict(X_test) final_pred = final_model.predict(X_test) Default model performance on the test set: MAE = 10.0118. Final model performance on the test set: MAE = 9.0446.
ハイパーパラメトリックチューニングにより、モデルの精度が約10%向上しました。 状況によっては、これは非常に大きな改善となる可能性がありますが、多くの時間がかかります。
Jupyter Notebooksのmagic
%timeit
を使用して、両方のモデルのトレーニング時間を比較できます。 まず、モデルのデフォルト期間を測定します。
%%timeit -n 1 -r 5 default_model.fit(X, y) 1.09 s ± 153 ms per loop (mean ± std. dev. of 5 runs, 1 loop each)
勉強する1秒は非常にまともです。 しかし、調整されたモデルはそれほど高速ではありません。
%%timeit -n 1 -r 5 final_model.fit(X, y) 12.1 s ± 1.33 s per loop (mean ± std. dev. of 5 runs, 1 loop each)
この状況は、機械学習の基本的な側面を示しています。 すべてが妥協です。 精度と解釈可能性のバランス、 変位と分散のバランス、精度と動作時間のバランスなどを常に選択する必要があります。 適切な組み合わせは、特定のタスクによって完全に決定されます。 私たちの場合、相対的な用語での作業期間の12倍の増加は大きいですが、絶対的な用語では重要ではありません。
最終的な予測結果が得られたので、それらを分析して、顕著な偏差があるかどうかを調べましょう。 左側は予測値と実数値の密度のグラフ、右側はエラーのヒストグラムです。
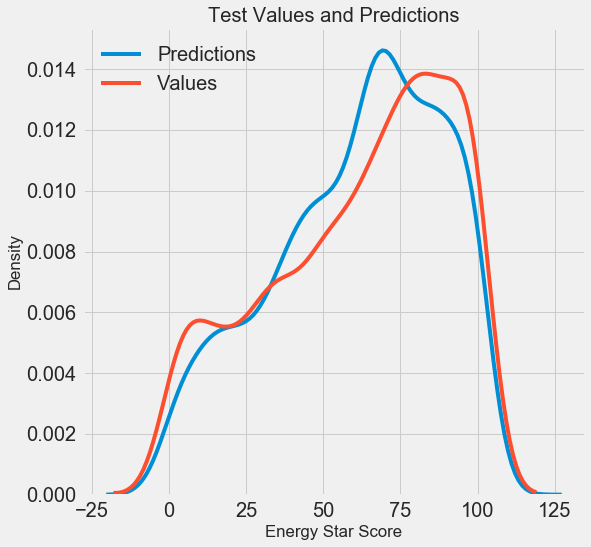

モデルの予測は実際の値の分布をよく繰り返しますが、トレーニングデータでは、密度ピークは実際の密度ピーク(約100)よりも中央値(66)の近くに位置しています。 モデルの予測が実際のデータと大きく異なる場合、いくつかの大きな負の値がありますが、エラーはほぼ正規分布になります。 次の記事では、結果の解釈をさらに詳しく調べます。
おわりに
この記事では、機械学習の問題を解決するいくつかの段階を検討しました。
- 欠損値の入力とスケーリング機能。
- いくつかのモデルの結果の評価と比較。
- ランダムグリッド検索と相互検証を使用したハイパーパラメトリックチューニング。
- テストデータを使用した最適なモデルの評価。
結果は、利用可能な統計に基づいて機械学習を使用してEnergy Starスコアを予測できることを示しています。 勾配ブースティングを使用すると、テストデータで9.1のエラーが達成されました。 ハイパーパラメトリックチューニングは結果を大幅に改善できますが、大幅な速度低下を犠牲にします。 これは、機械学習で考慮すべき多くのトレードオフの1つです。
次の記事では、モデルの仕組みを理解しようとします。 また、エネルギースタースコアに影響を与える主な要因についても説明します。 モデルが正確であることがわかっている場合は、モデルがこのように予測する理由と、これが問題自体について教えてくれることを理解しようとします。