
輸送のさまざまな段階で貨物を写真固定するタスクは、運送会社にとって典型的なものです。 会社の従業員が貨物を撮影し、画像をERPシステムにアップロードし、そこから電子アーカイブ(EA)に入ります。 各写真には、部門の送信者、受信者、コード、フライトインデックスなどのメタ情報が付随しています。 電子アーカイブの主なタスクは、過去3年間のメタ情報による写真の柔軟で便利な、そして最も重要な迅速な検索を整理することです。
よくあることですが、Alfresco Community Edition 4.2.xに基づく柔軟なECMシステムであるボックスソリューションを提供し、迅速に実装し、1つのブランチで成功したテストに合格したサプライヤが見つかりました。 そして、彼らはMS SQL ServerをCommunity Editionにねじ込みさえしました。 ERPとのやり取りのプロトコルについては、私たちのケースでは1Cであり、誰もそれについては考えていませんでした。顧客は、サーバー上のフォルダーにファイルをアップロードするための最も便利な方法を望み、古き良きFTPの使用を開始しました。
ヒューストン、問題があります...
最も興味深いことは、120のブランチでレプリケーションを開始したときに始まりました。 Luceneインデックスが無効なため、システムが定期的にクラッシュしました。 このような状況が発生した場合、インデックスを手動で再構築する必要があり、その結果、システムに1日アクセスできなくなりました。 連邦レベルの物流会社にとって、これはかなり重要な時期です。 再構築中、ファイルはボールに残り、「ランナウェイ」デルタのロードが失敗するたびに難しくなりました。 1日に取得できるファイルの最大数は、40〜60千でした。 また、Webインターフェースの検索速度も高速ではありませんでした。ダウンロード可能なユーザーの最大数は20人でした。 スケーラビリティに言及する価値はまったくありません。システムは現在のボリュームに対応できませんでした。 プラットフォームの正しい選択について疑問が生じました。 そしてこの段階で、この顧客との協力が始まりました。
システムのドキュメントはありませんでしたが、リバースエンジニアリングをキャンセルした人はいませんでした。 コードを整理し、エラーと多くの松葉杖を見つけました。これにより、システムが単に高負荷の準備ができていないことが明らかになりました:ファイルは最初にサーバーに保存され、その後、自己記述型のシェダラーがターゲットフォルダーを見て、ファイルをメモリにロードしてから処理しました。 もちろん、Alfrescoメカニズムのチューニングも行いませんでした。 たとえば、ファイルをダウンロードするときに、異なるトランザクションのドキュメントでアクションを投稿することができました。 しかし、残念ながら、誰もトランザクション管理に関与していませんでした。
そして、ここで致命的なミスを犯しました-既存のシステムを完成させ始めました。
120のブランチすべてで管理を開始し、数か月間、ユーザーが作業するシステムを調整しました。 Luceneの最適化、1つのファイルのサイズの変更、インデックスマージを開始するためのパラメーターの変更、Javaマシンのパラメーターの変更などを試みました。
この間、ボリュームは数回増加して1日あたり10万ドキュメントになり、インデックスのサイズは100 GBのクリティカルマークまで増加しました。その後、以前に支援したインデックスの標準的な再構築でさえ、正常に完了するとは限りませんでした-プロセスは合併段階でハングしました。 そして、私たちは気づきました-あなたはそのように生きることはできません! ソリューションを完全に書き直すことにしました。 古い悪い人や他の人の決断をあきらめ、経験の高さから彼らの善を書くのは誰が好きですか? しかし、新しいソリューションを開発してからデータ移行を行っている間に、既存のソリューションの作業をサポートする必要があるという事実により、タスクは複雑になりました。 タスクは現実的に思え、楽観的でした。
トップビュー:ソリューションアーキテクチャ
すべてのコードはJavaで書き直されました(バックエンドコードの一部はAlfrescoの組み込みJavaScriptで書かれました)。 また、メインのDBMSをMS SQLからPostgresqlに変更することも決定されました(実際、これは、自由に分散されたリレーショナルデータベースについて話すときに最初に思い浮かぶことです)。 ソリューションのアーキテクチャは完全にやり直されました。 Alfresco Shareインターフェースの使用を完全に放棄し、データを取得するために開発したWebサービスにアクセスする便利なカスタムWebインターフェースを開発しました。 AlfrescoはREST APIとして機能するようになりました。 Postgresql組み込みツールによるメインデータベースのレプリケーションが追加され、メインデータベースをロードせずにレプリケーションからレポートを作成できました。 検索とデータのロードは、2台のサーバーで間隔を空けられます。 1つではなく2つのAlfrescoのコピーが展開されました。1つはデータの検索と表示を行い、もう1つはダウンロードを行います。
Alfrescoの両方のコピーは同じデータベースを使用します。 ロードと表示の分離により、長時間のロード操作はデータの表示に影響を与えず、表示とロードは互いに独立して機能します。 これにより、最終的にシステムのパフォーマンスが向上しました。 システムのスループットが向上し、1日あたり最大20万枚の写真をアップロードできるようになり、同時ユーザーの数は70〜80に増えました。
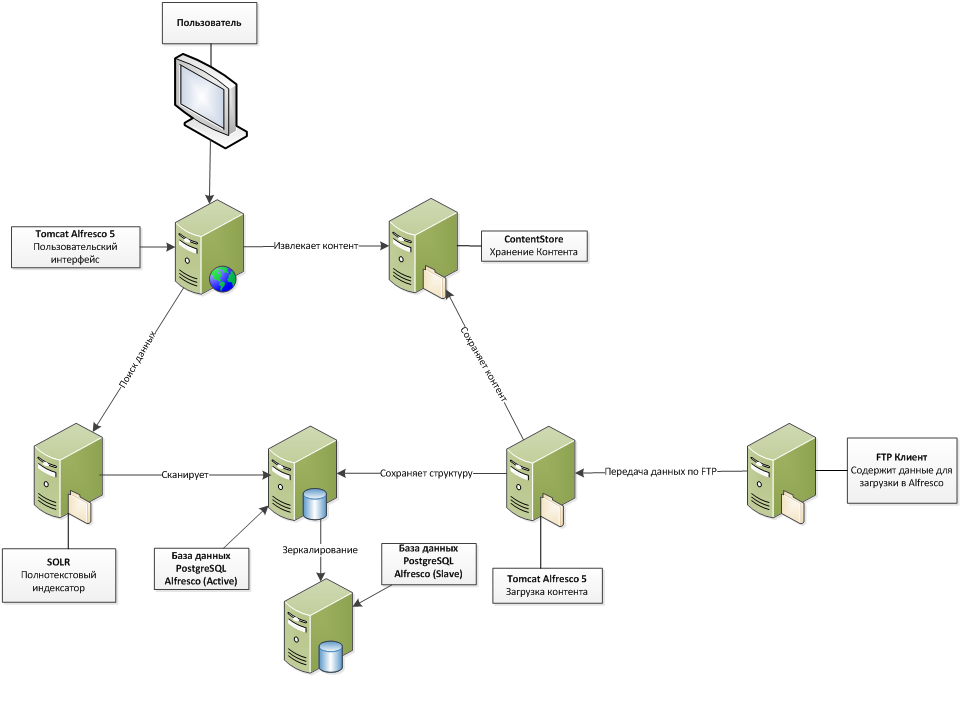
図1.ソリューションのアーキテクチャ
読み込みを高速化
システムパフォーマンスを最適化するために、次のことを行います。
- 再設計されたFTPファイルアップロードメカニズム。
- XMLファイルの処理を並列化しました。
- Alfresco 5に組み込まれた新しい検索エンジンを使用しました。
FTP
FTPファイルのアップロードメカニズムが再設計されました。 仮想FTPサーバーは、Apache FTPServerを介して実装されました。 通常のMavenプロジェクトがあるため、任意のライブラリを接続できます。 現在、ファイルはサーバーに保存されませんが、宛先フォルダーに応じて、受信するとすぐに処理され、ドキュメントのタイプが決定されます。 これにより、パフォーマンスが大幅に向上しました。
お客様がFTP経由でシステムと対話することが重要だったため、CMISは使用されなかったとすぐに言わなければなりません。
XML処理
また、xmlファイルの小さなブロックの処理を並列化し、トランザクションの開始と終了を手動で決定しました。デフォルトでは、ノードを持つすべてのアクション(Alfrescoのいわゆる全オブジェクト)は1つのトランザクションで実行されます。
新しい検索エンジン
Alfresco 5に切り替えると、より信頼性の高い検索エンジンが提供されました。 データ構造には一貫性のあるクエリが必要です。つまり、ロードするとき、1秒前にロードされたオブジェクトが必要になる場合があります。 SOLRは、インデックスの再構築に時間がかかるため、このようなクエリをサポートしていません。 Alfresco 4では、これらのリクエストはLuceneを介してサポートされていましたが、前述のように、独自の問題があります。 Alfresco 5では、そのようなクエリはデータベースで直接実行されます(クエリはHQLクエリに変換され、指定された方言に応じてSQLに変換されます)。 この革新により、システムのダウンロード速度と耐障害性が大幅に向上しました。
ロボット注入:バーコード認識
バーコード認識システムを導入するタスクがありました。 写真はすぐに処理されて保存されるため、ダウンロードサーバーにZbarライブラリをインストールするだけでタスクは解決しました。 実行中のZbarプロセスのプールが実装され、プールサイズはサーバー上のコアの数に等しくなります(スレッドの数は個別に調整されます)。 写真をアップロードすると、写真は最初にZbarを「実行」し、それに応じて認識されたバーコード(文字列として)を取得します。システムにドキュメントが読み込まれ、そのメタデータにこのバーコードが含まれている場合、そのようなドキュメントは写真に添付されます。後でドキュメントを検索するときにウェブインターフェースで写真を表示できます。
飛行の制御:計器
Alfresco 5に移植し、ソースコードを書き直した後、システムを適切に保守および開発し、新しい機能を追加することが可能になりました。 負荷を最適化した後の最初のことは、監視システムの問題を解決することでした。 ヒープサイズ、ディスクアクティビティ、およびその他の標準的なインジケータは、JMXツールを使用してZabbixを通じて監視されました。 アプリケーションメトリックの監視に関する質問がありました:ダウンロード速度、Alfresco REST API応答速度、アクティブユーザー数など。 この問題を解決するために、ユーザー数を収集し、アクティブなチケットを持つJMX Beanが作成されました。

Webインターフェースの読み込みと応答を監視するために、zabbixによって呼び出される2つのWebサービスが作成されました。
数を返す(ダウンロードしたファイルまたはREST APIのヒット数)

図2.ダウンロードされたファイルの数
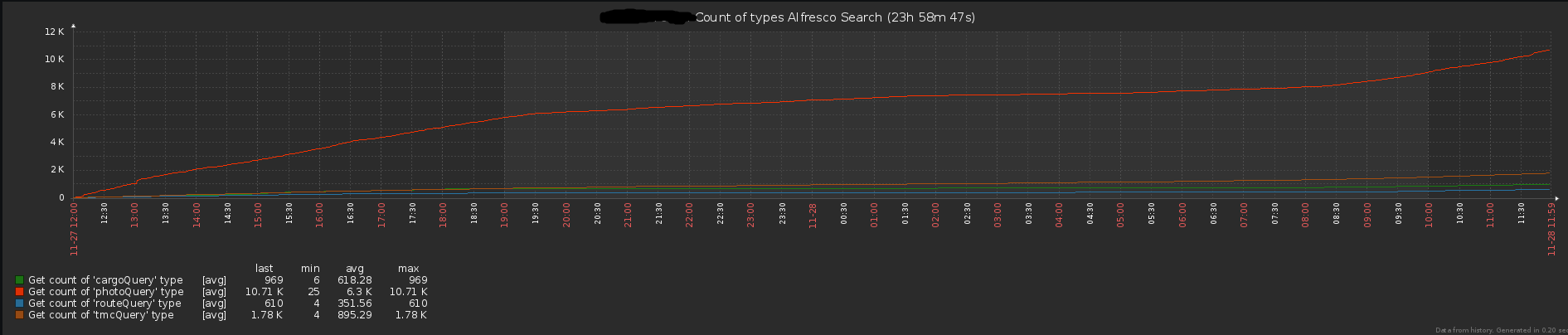
図3. REST APIのリクエスト数
平均時間(ミリ秒)を返します
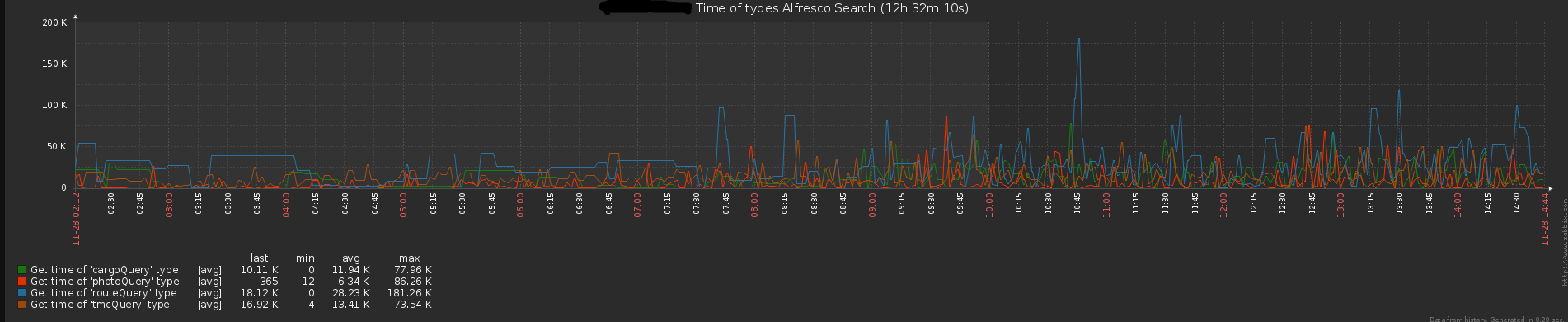
図4. REST APIの応答時間
図5.ファイルのアップロード時間
要求されたオブジェクトのタイプは、getパラメーターとして渡されます。
スペースオデッセイは続く
システムの独自の最適化と改良、およびAlfresco 5への移行により、300,000枚が認識システムを通過するため、ダウンロードスループットを1日あたり最大400,000枚まで増やすことができました。 また、現時点でのアクティブユーザーの平均数は120人に増えています。これは、基本サイズが約700GBで、コンテンツの合計サイズが19TBであるという条件ですべてです。 私たちのシステムには9,000万を超えるドキュメントがあります!
Alfresco Community Editionは、電子アーカイブのプラットフォームとして使用できます。 彼女の肩には、大規模で大規模な宇宙遠征があります。 しかし、遠征の成功は、打ち上げ前の準備作業の品質と、護衛中の乗組員の調整作業に依存することに注意することが重要です。
そして、私たちの飛行は続きますが、速度は異なります!
将来、Webインターフェイスをさらに最適化する予定です。オブジェクトのいわゆる遅延読み込みを行うことで、検索操作を高速化し、ユーザーエクスペリエンスの観点から画面フォームを最適化します。 (ユーザーエクスペリエンス)また、ドキュメントライフサイクル管理を実装し、特に低速のメディアにドキュメントをアーカイブする予定です。