みなさん、こんにちは
以前の記事で、新しいインメモリデータベースを作成しました-高速で豊富な機能を備えたReindexerです。
この記事では、Reindexerを使用して、最小限のアプリケーションコードを記述することで、サイトに全文検索を実装する方法を説明します。

一般に、フルテキストサイト検索は重要な機能であり、最近では、あらゆるインターネットサイトに不可欠です。 検索の品質と速度は異なります
ユーザーが興味のある情報や購入を計画している製品をすばやく見つける方法。
約15〜20年前、検索は完全に非対話型で素朴でした-サイトには検索行と「検索」ボタンがありました。 ユーザーは正しくする必要がありました
入力ミスなしで、正確な形式で検索したいものを入力し、「検索」ボタンをクリックします。 次-ページをリロードしてから数秒-そして、ここに結果があります。
多くの場合、ユーザーが見ることを期待していたものではありません。 そして、すべてが新しい方法で繰り返されました。新しいクエリ、「検索」ボタン、待機時間を入力してください。 最新の基準-UXとユーザーの基本原則の露骨なm笑。
過去数十年にわたって、検索エンジンのレベルは平均して大幅に向上しました-タイプミス、さまざまな単語形式の単語をユーザーに許す準備ができており、最も高度なものは、文字変換または間違ったキーボードレイアウトで入力された検索クエリを変換できます(例:「zyltrc」-「Yandex」、誤って英語のレイアウトに入力しました。
また、検索エンジンのインタラクティブ性が高まりました-「サジェスト」を提供することを学びました-検索行に入力する内容をユーザーに提案します。たとえば、ユーザーが「prezi」と入力し始めると、入力時に「president」という単語に自動的に置き換えられます。
対話型検索のさらに高度なバージョンは「入力時に検索」です。ユーザーがクエリを入力すると、検索結果が自動的に表示されます。
多くの可能性がありますが、それらは無料ではありません-検索で修正できるエラーが多いほど、動作が遅くなります。 また、検索が遅い場合、サジェストとインスタント検索を忘れる必要があります。
そのため、開発者はしばしば妥協する必要があります-機能の一部をオフにするか、対話機能をオフにするか、ハードウェアであふれ、サーバーインフラストラクチャに多額の費用を費やします。
だからそれは少し歌詞だった。 練習しましょう-Reindexerを使用して、妥協することなくサイトを検索します。
そして、結果からすぐに始めます-何が起こったか:コメントとメタデータを含むHabr全体を解析し、リインデクサーをロードして、Habr全体でバックエンドと検索フロントエンドを作成しました。
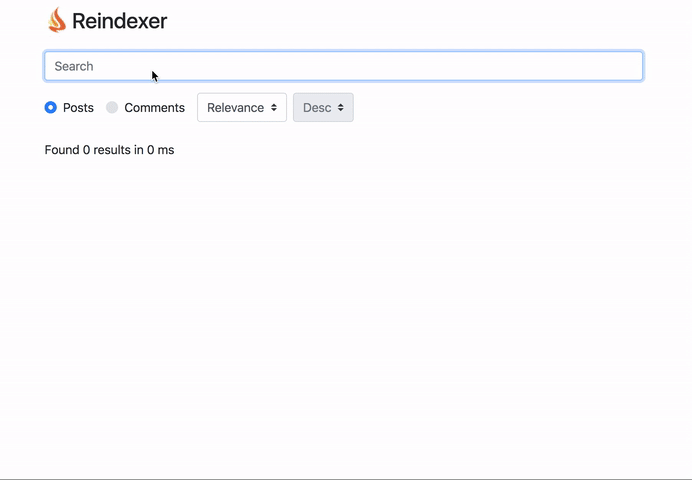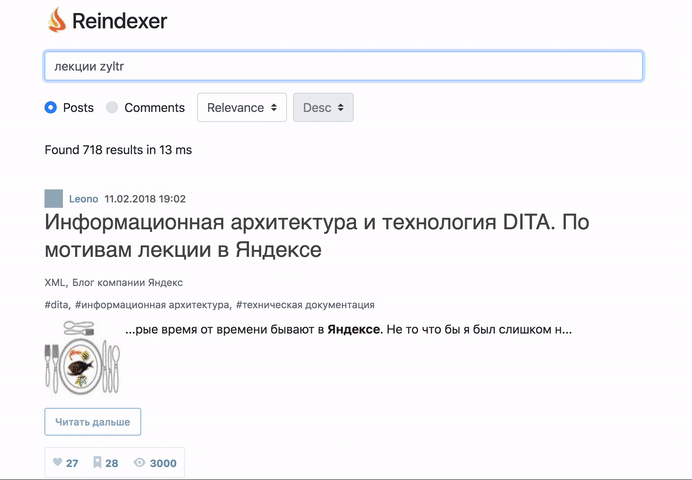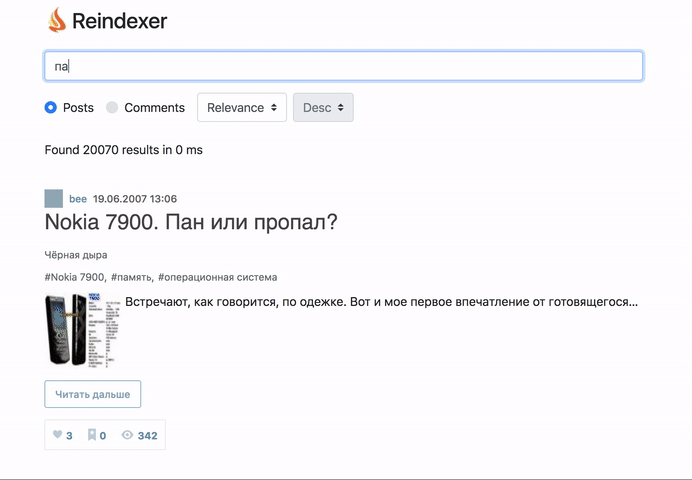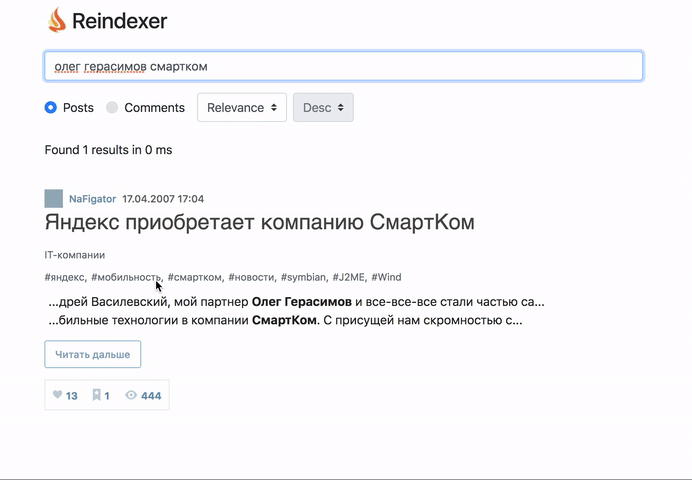
生きていると感じて、何が起こったのかはこちら: http : //habr-demo.reindexer.org/
データ量について言えば、これは約5GBのテキスト、17万件の記事、600万件のコメントです。
検索は、音訳、不正なキーボードレイアウト、タイプミス、単語形式など、すべての機能で動作します。
ただし、免責事項は、1週間、夕方に他のことから自由に「膝の上」で組み立てられたプロジェクトです。 したがって、厳密に判断しないでください。
第1 VPS 4x CORE、12 GB RAMを搭載。 少なくとも、最大1倍のCORE、および10GB RAMを圧縮することは可能ですが、少し予備を残しました-突然のハブロ効果です。
プロジェクト全体の実装<1000行。注目すべき部分は、htmlをデータ構造に配布するhabraページのパーサーです。
さらに記事では、これがどのように実装されているかを説明します。
バックエンド
使用される構造とコンポーネント
バックエンドはgolangアプリケーションです。 fasthttpおよびfasthttprouterは、httpサーバーおよびルーターとして使用されます。 この特定のケースでは、
他のサーバーとルーターのセットを使用しますが、それらにとどまることにしました。
データベースとして、 reindexer が使用され、htmlページの解析に使用されます-素晴らしいgoqueryライブラリ
アプリケーション構造は非常に単純で、4つのモジュールのみで構成されています。
- リポジトリ-データウェアハウスの操作と、その中のデータモデルの説明を担当します。
- HTTP-リクエストの処理を担当
- パーサー-Habrページの解析を担当
- main-コマンドラインインターフェースの処理とコンポーネントの起動/初期化
APIメソッド
- / api / search-投稿とコメントの全文検索
- / api / posts /:id-IDで投稿を取得
- / api / posts-フィルタリングを使用して投稿のリストを取得する
データモデル
データモデルはgolang構造です。 Reindexerを使用する場合、構造体フィールドのタグは、フィールド上に構築されるインデックスを記述します。
インデックスの選択について詳しく説明します。クエリの実行速度と消費されるメモリの両方は、インデックスの選択に依存します。
したがって、検索またはフィルタリングされることになっているフィールドに正しいインデックスを割り当てることが非常に重要です。
ポスト構造:
type HabrPost struct { // ID . `id` 'pk' - Primary Key // , `id`, Reindexer id ID int `reindex:"id,,pk" json:"id"` // . API, , `tree` Time int64 `reindex:"time,tree,dense" json:"time"` // . text , `-` - Text string `reindex:"text,-" json:"text"` // . title , `-` - Title string `reindex:"title,-" json:"title"` // . API , `HASH` User string `reindex:"user" json:"user"` // . HASH , Hubs []string `reindex:"hubs" json:"hubs"` // . HASH , Tags []string `reindex:"tags" json:"tags"` // . . API . // `likes` , // Likes int `reindex:"likes,-,dense" json:"likes,omitempty"` // . `likes` Favorites int `reindex:"favorites,-,dense" json:"favorites,omitempty"` // . `likes` Views int `reindex:"views,-,dense" json:"views"` // , . HasImage bool `json:"has_image,omitempty"` // - Comments []*HabrComment `reindex:"comments,,joined" json:"comments,omitempty"` // . title, text, user // - `search` // `dense` - , _ struct{} `reindex:"title+text+user=search,text,composite;dense"` }
コメント付きの構造は非常に単純なので、ここでは詳しく説明しません。
検索方法の実装
ハンドラー
REST APIレベルでは、ハンドラーは通常のfasthttpハンドラーです。 その主なタスクは、リクエストパラメータの取得、リポジトリ内の検索メソッドの呼び出し、クライアントへの応答の提供です。
func SearchPosts(ctx *fasthttp.RequestCtx) { // text := string(ctx.QueryArgs().Peek("query")) limit, _ := ctx.QueryArgs().GetUint("limit") offset, _ := ctx.QueryArgs().GetUint("offset") sortBy := string(ctx.QueryArgs().Peek("sort_by")) sortDesc, _ := ctx.QueryArgs().GetUint("sort_desc") // items, total, err := repo.SearchPosts(text, offset, limit, sortBy, sortDesc > 0) // resp := PostsResponce{ Items: convertPosts(items), TotalCount: total, } respJSON(ctx, resp) }
検索にアクセスする主なタスクは、 SearchPosts
リポジトリSearchPosts
によって実行されますSearchPosts
クエリ(クエリ)を生成し、応答を受信してから応答を変換します
[]interface{}
をHabrPost
モデルへのポインターの配列にHabrPost
ます。
func (r *Repo) SearchPosts(text string, offset, limit int, sortBy string, sortDesc bool) ([]*HabrPost, int, error) { // Reindexer query := repo.db.Query("posts"). // `search`, DSL Match("search", textToReindexFullTextDSL(r.cfg.PostsFt.Fields, text)). ReqTotal() // : // , 30 30 // <b> </b> // "...", "...<br/>" query.Functions("text = snippet(<b>,</b>,30,30, ...,... <br/>)") // // - // , `query.Sort` if len(sortBy) != 0 { query.Sort(sortBy, sortDesc) } // applyOffsetAndLimit(query, offset, limit) // . query.Exec () it := query.Exec() // , if err := it.Error(); err != nil { return nil, 0, err } // . defer it.Close () // items := make([]*HabrPost, 0, it.Count()) for it.Next() { item := it.Object() items = append(items, item.(*HabrPost)) } return items, it.TotalCount(), nil }
DSLの形成と検索ルール
通常、サイトの検索文字列には、「科学のビッグデータ」や「Rust vs C ++」など、通常の人間の言語でクエリを入力する必要がありますが、検索エンジンは追加の検索パラメータを示す特別なDSL形式でクエリを送信する必要があります
DSLでは、検索が行われるフィールド、関連性が調整されます。たとえば、DSLでは、「見出し」フィールドで見つかった結果が「投稿テキスト」フィールドでの結果よりも関連性があることを指定できます。 また、DSLの検索オプションは、たとえば、単語の正確な出現のみを検索するか、同時に検索するか、タイプミスのある単語を検索するかなどのように構成されます。
Reindexerも例外ではなく、Application DSLのインターフェイスも提供します。 githubで利用可能な DSLドキュメント
textToReindexFullTextDSL
関数は、テキストをDSLに変換します。 関数は次のようにテキストを変換します。
| 入力されたテキスト | DSL | コメント |
|---|---|---|
| ビッグデータ | @*^0.4,user^1.0,title^1.6 **~ +**~
| tilte
フィールドにいることの関連性は1.6であり、 user
フィールドにあることは1.0です。 |
残り-0.4。 すべての単語形式で単語を検索する | ||
| 接頭辞または接尾辞としてだけでなく、タイプミスおよび検索での検索 | ||
接尾辞または接頭辞としてれたすべての単語形式 |
データの取得と読み込み
デバッグの便宜上、Habrからデータを受信/解析し、それらを2つの別々の段階でリインデクサーにロードするプロセスを分割しました。
パーシムハブル
DownloadPost
関数は、Habrページのダウンロードと解析を行います-そのタスクは、Habrから指定されたIDを持つ記事をダウンロードし、受け取ったhtmlページを解析し、記事から最初の画像を読み込んでサムネイルを作成することです。
DownloadPost
関数の結果は、記事のコメントと写真付きの配列[]byte
を含む、すべてのフィールドを持つ完全なHabrPost
構造です。
パーサーの仕組み、 githubを見ることができます
データインポートモードでは、アプリケーションは1〜360,000のIDを持つループでDownloadPost
をいくつかのストリームで呼び出し、結果はjsonファイルとjpgファイルのセットに保存されます。
5つのストリームでダウンロードする場合-Habr全体が約8時間でダウンロードされます。 可能な360,000の記事のうち、残りのIDについては、正しい記事に対する正しい記事は175,000しかありません
このエラーまたはそのエラーが返されます。
解析されたデータの合計量は約5GBです。
Reindexerへのデータの読み込み
Habrのインポートが完了すると、170kのjsonファイルが作成されます。 関数RestoreAllFromFilesは、 Reindexerでファイルのセットをロードする役割を果たします。
この関数は、保存された各JSONをHabrPost構造に変換し、そのposts
とcomments
プレートを読み込みます。 コメントは個別のプレートで強調表示されるため、個々のコメントを検索できます。
別の方法ですべてを1つのテーブルに格納することもできます(これにより、メモリ内のインデックスのサイズが小さくなります)が、個々のコメントを検索することはできません。
この操作はそれほど長くありません。すべてのデータを1つのストリームでReindexerにロードするのに約5〜10分かかります。
全文索引設定
フルテキストインデックスには、さまざまな設定があります。 これらの設定は、DSLからの設定とともに、検索の品質を直接決定します。
次の設定が含まれます。
- 「ストップワード」のリスト:これらはドキュメントでよく使用される単語であり、セマンティックの負荷はありません。
- 索引作成オプション:文字変換サポート/タイプミス/キーボードレイアウトの誤り
- 関連性を計算するための式の係数。 bm25関数、見つかった単語間の距離、クエリからの単語の長さ、完全一致/完全一致ではない記号。
このアプリケーションでは、 Initリポジトリー関数が検索パラメーターの設定を担当します。
Chromeフロントエンドと「エンドレス」スクロールのバグについて
フロントエンドはvue.jsに実装されています-https ://github.com/igtulm/reindex-search-ui
読み込み結果で「無限の」スクロールを行ったとき、Google Chromeで非常に不快なバグが発生しました。後者によると、スクロール中にサーバーから応答をダウンロードするのに3〜4秒かかることがあります。

どうして! ミリ秒単位の再インデクサーを備えた高速バックエンドがあり、ここでは最大4秒です。 彼らは理解し始めました:
サーバーログによると、すべてが問題ありません-回答は数ミリ秒で与えられます。
2018/04/22 16:27:27 GET /api/search?limit=10&query=php&search_type=posts 200 8374 2.410571ms 2018/04/22 16:27:28 GET /api/search?limit=10&offset=10&query=php&search_type=posts 200 9799 2.903561ms 2018/04/22 16:27:34 GET /api/search?limit=10&offset=20&query=php&search_type=posts 200 21390 1.889076ms 2018/04/22 16:27:42 GET /api/search?limit=10&offset=30&query=php&search_type=posts 200 8964 3.640659ms 2018/04/22 16:27:44 GET /api/search?limit=10&offset=40&query=php&search_type=posts 200 9781 2.051581ms
もちろん、サーバーログは究極の真実ではありません。 したがって、tcpdump番目のトラフィックを調べました。 また、tcpdumpは、サーバーがミリ秒の原因であることも確認しました。
SafariとFirefoxで試してみました-彼らはそのような問題はありません。 したがって、問題は明らかにバックエンドの応答時間ではなく、他のどこかにあります。
問題はまだChromeにあるようです。
数時間のグーグルが報われました-StackOverflowに回避策の記事があります
また、記事から魔法の「回避策」を追加すると、Chromeの問題が部分的に修正されました。
mousewheelHandler(event) { if (event.deltaY === 1) { event.preventDefault(); } }
ただし、とにかく、非常に積極的にタッチパッドをスクロールすると、遅延が生じることがあります。
他に何か-結論の代わりに小さなボーナストラック
前の記事の公開以来、多くの新機能がReindexerに登場しました。 最も重要なのは、本格的なサーバー(スタンドアロン)動作モードです。
サーバーモードのgolang API。埋め込みモードのAPIと完全に互換性があります。 1行を置き換えることにより、既存のアプリケーションを埋め込みからスタンドアロンに切り替えることができます。
これは、アプリケーションが埋め込みモードで動作し、ローカルファイルシステム上のデータを/tmp/reindex/testdb
db := reindexer.NewReindex("builtin:///tmp/reindex/testdb")
これは、ネットワークを介したスタンドアロンサーバーでのアプリケーションの動作方法です。
db := reindexer.NewReindex("cproto://127.0.0.1:6534/testdb")
スタンドアロンサーバーは、 dockerhubからインストールするか、ソースから組み立てることができます
それでも、電報の公式Reindexerサポートチャネルを開きました。 質問や提案がある場合-ようこそ!