JPoint 2017からの彼のレポートのトランスクリプトを提供します。一般に、ここではHTTP / 2については説明しません。 もちろん、多くの詳細がなければ管理することはできません。
HTTP / 2(別名RFC 7540)
HTTP 2は、レガシーHTTP 1.1を置き換えるために設計された新しい標準です。 HTTP 2の実装とパフォーマンスの面での以前のバージョンとの違いは何ですか?
HTTP 2の重要な点は、単一のTCP接続があることです。 データストリームはフレームに分割され、これらすべてのフレームはこの接続を介して送信されます。
別のヘッダー圧縮標準であるRFC 7541(HPACK)も提供されます。 これは非常にうまく機能します。1キロバイト程度のサイズのHTTPヘッダーを最大20バイト圧縮できます。 最適化の一部では、これは重要です。
一般に、新しいバージョンには多くの興味深いものがあります-要求の優先順位付け、サーバープッシュ(サーバー自体がクライアントにデータを送信するとき)など。 ただし、この物語の文脈では(パフォーマンスの観点から)、これは重要ではありません。 さらに、多くのものが同じままです。 たとえば、上記のHTTPプロトコルは次のようになります。同じGETメソッドとPOSTメソッド、同じHTTPヘッダーフィールド値、ステータスコード、および「リクエスト->レスポンス->最終レスポンス」の構造があります。 実際、詳しく見てみると、HTTP 2はHTTP 1.1の低レベルのトランスポートサブストレートにすぎず、その欠点が取り除かれています。
HTTP API(別名JEP 110、HttpClient)
JEP 110と呼ばれるHttpClientプロジェクトがあります。これはほとんどJDK 9に含まれています。当初、このクライアントをJDK 9標準の一部にしたかったのですが、API実装レベルでいくつかの論争がありました。 また、JDK 9のリリースまでにHTTP APIを完成させる時間がないので、コミュニティに見せて議論できるようにHTTP APIを作成することにしました。
JDK 9では、新しいインキュベーターモジュール(Incubator Modules aka JEP-11)が導入されています。 これは、コミュニティからのフィードバックを受け取るために、まだ標準化されていない新しいAPIが追加されるサンドボックスですが、インキュベーターの定義により、次のバージョンに標準化されるか、完全に削除されます(「APIのインキュベーション寿命は制限されています: APIは標準化されるか、そうでなければ次のリリースで最終的にされるか、削除されます。 興味のある人は誰でもAPIに慣れ、フィードバックを送信できます。 おそらく次のバージョン-JDK 10-が標準になると、すべてが修正されます。
- モジュール:jdk.incubator.httpclient
- パッケージ:jdk.incubator.http
HttpClientは、インキュベーターの最初のモジュールです。 その後、クライアントに関連する他のものがインキュベーターに表示されます。
APIの例をいくつか紹介します(これはクライアントAPIであり、リクエストを行うことができます)。 主なクラス:
- HttpClient(そのビルダー);
- HttpRequest(そのビルダー);
- HttpResponseは、私たちが構築しているのではなく、ただ戻ってきています。
クエリを作成する簡単な方法を次に示します。
HttpRequest getRequest = HttpRequest .newBuilder(URI.create("https://jpoint.ru/")) .header("X-header", "value") .GET() .build();
HttpRequest postRequest = HttpRequest .newBuilder(URI.create("https://jpoint.ru/")) .POST(fromFile(Paths.get("/abstract.txt"))) .build();
ここで、URLの指定、ヘッダーの設定などを行います。 -リクエストを受け取ります。
どうすればリクエストを送信できますか? クライアントには2種類のAPIがあります。 1つ目は、この呼び出しの場所でブロックするときの同期要求です。
HttpClient client = HttpClient.newHttpClient(); HttpRequest request = ...; HttpResponse response = // synchronous/blocking client.send(request, BodyHandler.asString()); if (response.statusCode() == 200) { String body = response.body(); ... } ...
リクエストはなくなり、答えを受け取り、それを
string
として解釈し(ここのハンドラは異なる場合があります
string
、
byte
、独自のものを書くことができます)、処理しました。
2つ目は非同期APIです。この場所でブロックしたくない場合、非同期要求を送信して実行を続行し、結果のCompletableFutureを使用して必要な処理を実行できます。
HttpClient client = HttpClient.newHttpClient(); HttpRequest request = ...; CompletableFuture> responseFuture = // asynchronous client.sendAsync(request, BodyHandler.asString()); ...
クライアントには、1000個の構成パラメーターを設定でき、さまざまな方法で構成できます。
HttpClient client = HttpClient.newBuilder() .authenticator(someAuthenticator) .sslContext(someSSLContext) .sslParameters(someSSLParameters) .proxy(someProxySelector) .executor(someExecutorService) .followRedirects(HttpClient.Redirect.ALWAYS) .cookieManager(someCookieManager) .version(HttpClient.Version.HTTP_2)</b> .build();
ここでの主なトリックは、クライアントAPIがユニバーサルであることです。 詳細を区別することなく、古いHTTP 1.1とHTTP 2の両方で動作します。 クライアントの場合、標準のHTTP 2でデフォルトの操作を指定できます。個々のリクエストごとに同じパラメーターを指定できます。
問題の声明
そのため、Javaライブラリがあります。これは、標準のJDKクラスに基づいており、最適化する必要がある(何らかのパフォーマンス作業を行うために)別のモジュールです。 正式には、パフォーマンスのタスクは次のとおりです。許容できるエンジニアの時間内に合理的なクライアントの生産性を取得する必要があります。
アプローチを選択します
この作業はどこから始められますか?
- 座ってHTTP 2仕様を読むことができます。これは便利です。
- クライアント自体の調査を開始し、見つかったたわごとを書き換えることができます。
- このクライアントを見て、全体を書き直すことができます。
- ベンチマークできます。
ベンチマークから始めましょう。 突然、すべてがそこまで良くなりました。仕様を読む必要はありません。
ベンチマーク
彼らはベンチマークを書いた。 比較のために競合他社があればいいです。 Jetty Clientをライバルとして採用しました。 サーバーをJavaにしたかったからといって、Jettyサーバーを横にねじ込みました。 さまざまなサイズのGETおよびPOSTリクエストを作成しました。

当然、問題が発生します-スループット、遅延(最小、平均)を測定します。 議論の中で、これはサーバーではなくクライアントであると判断しました。 つまり、このコンテキストで最小レイテンシ、gcポーズ、その他すべてを考慮することは重要ではありません。 したがって、特にこの作業のために、システム全体のスループットの測定に限定することにしました。 私たちの仕事はそれを増やすことです。
システムの全体的なスループットは、平均レイテンシの逆数です。 つまり、平均レイテンシに取り組みましたが、同時に個々のリクエストに煩わされませんでした。 クライアントがサーバーと同じ要件を持たないという理由だけで。
変更1. TCP構成
1バイトでGETを開始します。 鉄が書かれています。 取得するもの:

HTTPClientについても同じベンチマークを取り、他のオペレーティングシステムとハードウェア(これらは多かれ少なかれサーバーマシンです)で実行します。 私は得る:

Win64では、すべてがより良く見えます。 しかし、MacOSでも、事態はLinuxほど悪くはありません。
問題はここにあります:
SocketChannel chan; ... try { chan = SocketChannel.open(); int bufsize = client.getReceiveBufferSize(); chan.setOption(StandardSocketOptions.SO_RCVBUF, bufsize); } catch (IOException e) { throw new InternalError(e); }
これは、サーバーに接続するためにSocketChannelを開いています。 問題は、1行がないことです(以下のコードで強調しました)。
SocketChannel chan; ... try { chan = SocketChannel.open(); int bufsize = client.getReceiveBufferSize(); chan.setOption(StandardSocketOptions.SO_RCVBUF, bufsize); chan.setOption(StandardSocketOptions.TCP_NODELAY, true); <-- !!! } catch (IOException e) { throw new InternalError(e); }
TCP_NODELAY
は、前世紀の「ハロー」です。 さまざまなTCPスタックアルゴリズムがあります。 このコンテキストには、Nagleのアルゴリズムと遅延ACKの2つがあります。 特定の条件下では、フレアが発生し、データ転送が急激に遅くなる可能性があります。 これはTCPスタックの既知の問題であり、デフォルトでNagleのアルゴリズムをオフにする
TCP_NODELAY
有効にします。 ただし、エキスパート(および実際のTCPエキスパートがこのコードを書いた)でさえ、このコマンドラインを入力せずに、単にそれを忘れてしまうことがあります。
原則として、これらの2つのアルゴリズムがどのように競合するのか、なぜこのような問題が発生するのかについて、インターネット上で多くの説明があります。 気に入った記事へのリンクを提供します。NagleのアルゴリズムとDelayed ACKの相互作用によって引き起こされるTCPパフォーマンスの問題
この問題の詳細な説明は、会話の範囲を超えています。
TCP_NODELAY
含めて1行だけ追加した後、次のパフォーマンス向上が得られました。

パーセンテージはいくらでも数えません。
道徳:これはJavaの問題ではなく、TCPスタックとその構成の問題です。 多くの地域で、有名な学校があります。 よく知られているので、人々はそれらを忘れています。 それらについて知ることをお勧めします。 この分野に慣れていない場合は、存在する主要な浅瀬を簡単にグーグル検索できます。 非常に迅速に問題なくチェックできます。
あなたはあなたの主題領域の有名な横棒のリストを知る必要があります(そして忘れないでください)。
変更2.フロー制御ウィンドウ
最初の変更があり、仕様を読む必要さえありませんでした。 1秒あたり9600の要求が判明しましたが、Jettyが11,000を与えることを思い出してください。次に、任意のプロファイラーを使用してプロファイリングします。
ここに私が得たものがあります:

そして、これはフィルターされたオプションです:

私のベンチマークはCPU時間の93%かかります。
サーバーにリクエストを送信するには37%かかります。 次に、すべての内部詳細、フレームの操作、および19%の終わりに来ます-これはSocketChannelのエントリです。 リクエストのデータとヘッダーは、HTTPにあるはずなので、転送します。 そして、
readBody()
を読み取ります。
次に、サーバーから送られてきたデータを読み取る必要があります。 それでは何ですか?
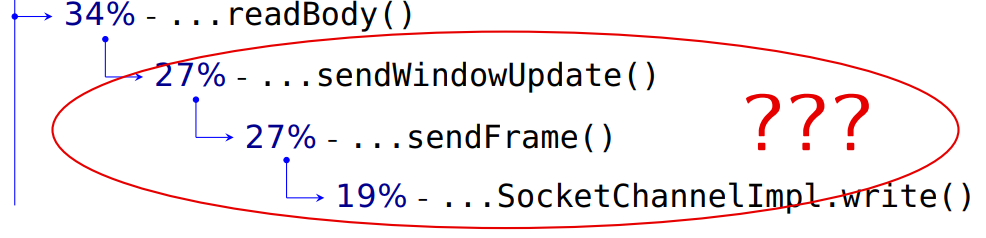
エンジニアがメソッドに正しく名前を付け、それらを信頼する場合、ここでサーバーに何かを送信します。これには、リクエストを送信するのと同じくらい時間がかかります。 サーバー応答を読み取るときに何かを送信するのはなぜですか?
この質問に答えるには、仕様を読む必要がありました。
一般に、パフォーマンスに関する多くの問題は、仕様を知らなくても解決されます。
ArrayList
を
LinkedList
またはその逆に、または
Integer
を
int
などに置き換える必要がある場所。 この意味で、ベンチマークがあれば非常に良いです。 測定-正しい-動作します。 また、仕様に従ってどのように機能するかについては詳しく説明しません。
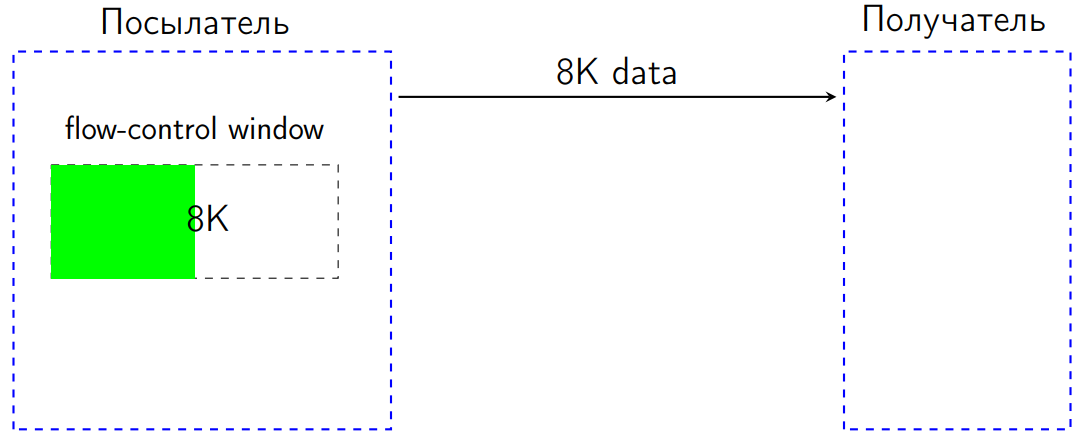
しかし、私たちの場合、問題は仕様で実際に明らかにされました。HTTP2標準には、いわゆるフロー制御があります。 次のように機能します。 2つのピアがあります。1つはデータを送信し、もう1つは受信します。 送信者(送信者)にはウィンドウがあります-特定のバイト数(16 KBと仮定)のサイズのフロー制御ウィンドウ。

8 KBを送信したとします。 フロー制御ウィンドウは、これらの8 KB削減されます。
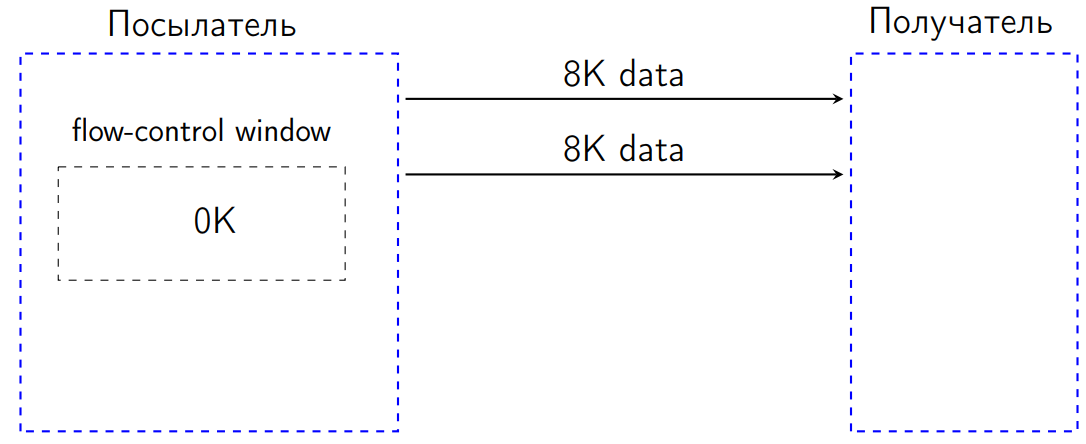
さらに8 KBを送信した後、フロー制御ウィンドウは0 KBになりました。
標準では、この状況では、私たちには何も送信する権利がありません。 データを送信しようとすると、受信者はこの状況をプロトコルエラーとして解釈し、接続を閉じる必要があります。 これは多くの場合、DDOSに対する一種の保護であるため、余分なものは送信されず、メッセンジャーは受信者の帯域幅に合わせて調整されます。
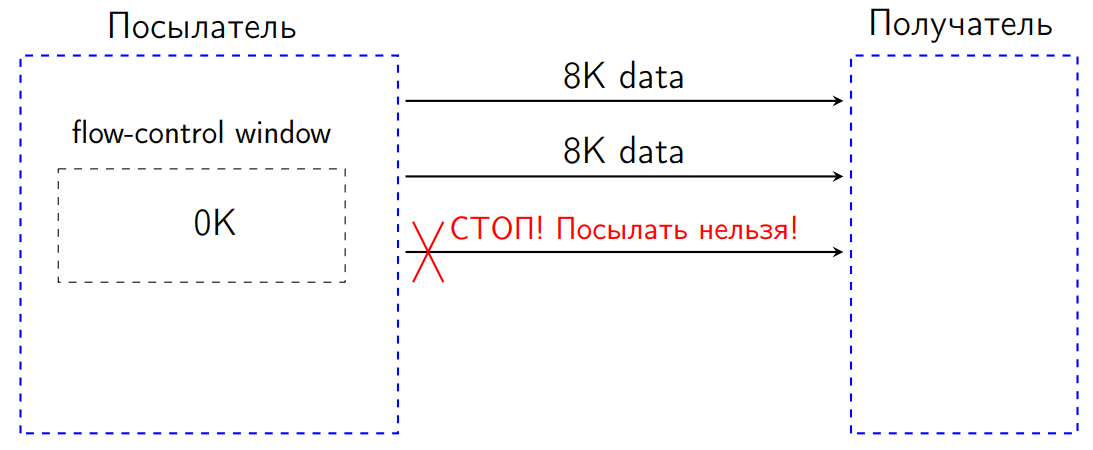
受信者が受信データを処理するとき、フロー制御ウィンドウを増やすバイト数を示すWindowUpdateと呼ばれる特別な専用信号を送信する必要がありました。
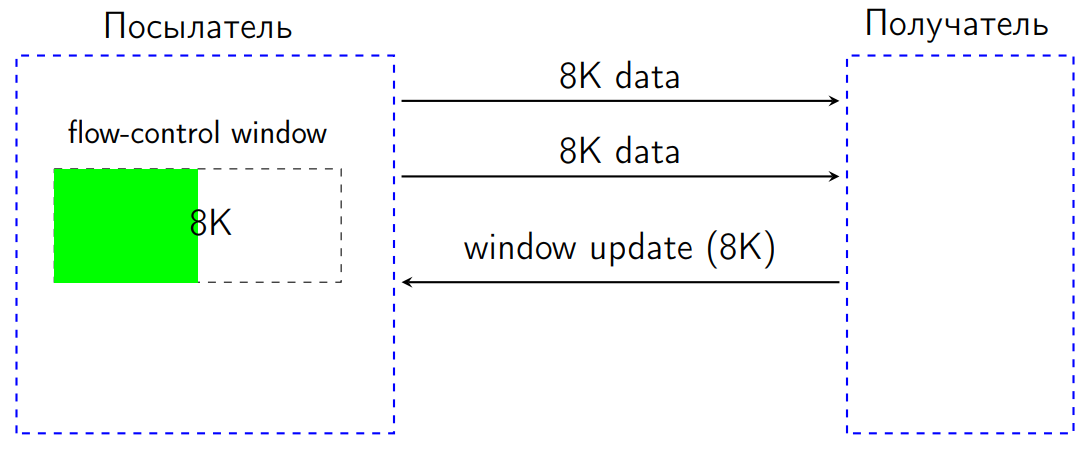
WindowUpdateが送信者に到着すると、そのフロー制御ウィンドウが増加し、データをさらに送信できます。
クライアントで何が起こっていますか?
サーバーからデータを取得しました-これが実際の処理です。
// process incoming data frames ... DataFrame dataFrame; do { DataFrame dataFrame = inputQueue.take(); ... int len = dataFrame.getDataLength(); sendWindowUpdate(0, len); // update connection window sendWindowUpdate(streamid, len); //update stream window } while (!dataFrame.getFlag(END_STREAM)); ...
特定の
dataFrame
-データフレーム。 データ量を調べて処理し、WindowUpdateを返送して、フロー制御ウィンドウを目的の値だけ増やしました。
実際、それぞれの場所で2つのフロー制御ウィンドウが機能します。 このデータストリーム(要求)専用のフロー制御ウィンドウがあり、接続全体に共通のフロー制御ウィンドウもあります。 したがって、2つのWindowUpdateリクエストを送信する必要があります。
この状況を最適化する方法は?
最初のもの。
while
の最後に、最後のデータフレームが送信されたことを示すフラグがあります。 標準では、これはデータがこれ以上来ないことを意味します。 そしてこれを行います:
// process incoming data frames ... DataFrame dataFrame; do { DataFrame dataFrame = inputQueue.take(); … int len = dataFrame.getDataLength(); connectionWindowUpdater.update(len); if (dataFrame.getFlag(END_STREAM)) { break; } streamWindowUpdater.update(len); } while (true); ...
これは小さな最適化です。ストリーム終了フラグをキャッチした場合、このストリームに対してWindowUpdateは送信できなくなります。データを待機しなくなり、サーバーは何も送信しません。
二番目。 WindowUpdateを毎回送信する必要があると言うのは誰ですか? 多数のリクエストを受信したのに、受信したデータを処理してから、受信したすべてのリクエストにWindowUpdateを送信できないのはなぜですか?
特定のフロー制御ウィンドウで動作する
WindowUpdater
は次の
WindowUpdater
です。
final AtomicInteger received; final int threshold; ... void update(int delta) { if (received.addAndGet(delta) > threshold) { synchronized (this) { int tosend = received.get(); if( tosend > threshold) { received.getAndAdd(-tosend); sendWindowUpdate(tosend); } } } }
一定の
threshold
ます。 データを受信しますが、何も送信しません。 この
threshold
前にデータを収集するとすぐに、すべてのWindowUpdateを送信します。
threshold
がフロー制御ウィンドウの半分に近い
threshold
うまく機能する特定のヒューリスティックがあります。 最初にこのウィンドウを64 KBにして、それぞれ8 KBを取得した場合、合計32 KBのデータフレームをいくつか受信するとすぐに、ウィンドウアップデーターをすぐに32 KBに送信します。 通常のバッチ処理。 良好な同期のために、完全に通常の二重チェックも行います。
1バイトのリクエストの場合:
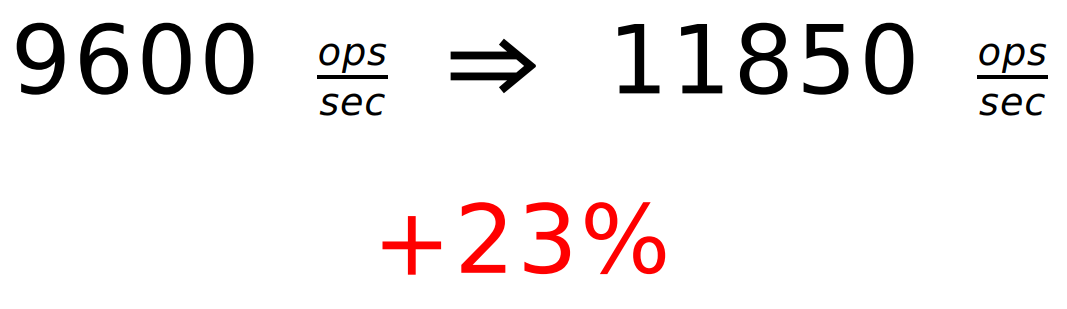
効果は、多くのフレームがあるメガバイトリクエストでも発生します。 しかし、もちろん、彼はそれほど目立ちません。 実際には、さまざまなベンチマーク、さまざまなサイズの要求がありました。 しかし、ここではそれぞれの場合にグラフィックを描画しませんでしたが、簡単な例を取り上げました。 より詳細なデータの絞り込みは少し後で行われます。
+ 23%しか得られませんでしたが、Jettyはすでに追い越しています。
道徳: 仕様を注意深く読んで、ロジックはあなたの友達です。
仕様にはいくつかのニュアンスがあります。 一方では、データフレームを受信したら、WindowUpdateを送信する必要があります。 しかし、仕様を注意深く読んで、次のことがわかります。受信した各バイトにWindowUpdateを送信する必要はありません。 したがって、仕様では、フロー制御ウィンドウのこのようなバッチ更新が許可されています。
変更3.ロック
スケーリング(スケーリング)の方法を学びましょう。
このラップトップは、スケーリングにはあまり適していません。実カーネルと偽のカーネルは2つしかありません。 48個のハードウェアスレッドがあるサーバーマシンを使用して、ベンチマークを実行します。
ここで、水平方向-スレッド数、および垂直方向は合計スループットを示します。
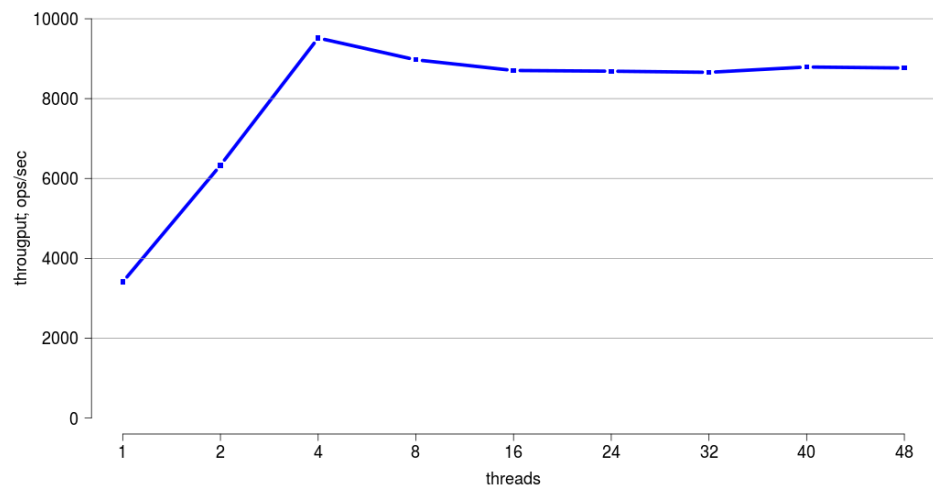
ここでは、最大4つのスレッドが非常にうまくスケーリングされていることがわかります。 しかし、さらに、スケーラビリティは非常に悪くなります。
どうしてこれが必要なのでしょうか? クライアントは1人です。 1つのスレッドからサーバーから必要なデータを取得し、それを忘れます。 しかし、最初に、非同期バージョンのAPIがあります。 私たちは再び彼女に来ます。 おそらくいくつかのスレッドがあります。 第二に、私たちの世界のすべてがマルチコアになり、ライブラリ内の多くのスレッドでうまく動作できることは、誰かがシングルスレッドバージョンのパフォーマンスについて不平を言い始めたときに、マルチスレッドに切り替えることを勧められる場合にのみ有用ですそして利益を得る。 したがって、スケーラビリティが低い加害者を探しましょう。 私は通常このようにします:
#!/bin/bash (java -jar benchmarks.jar BenchHttpGet.get -t 4 -f 0 &> log.log) & JPID=$! sleep 5 while kill -3 $JPID; do : done
スタックトレースをファイルに書き込むだけです。 実際には、プロファイラーを使用せずにロックを操作する場合の90%の場合、これで十分です。 いくつかの複雑なトリックの場合にのみ、ミッションコントロールまたは他の何かを起動し、ロックの分布を監視します。
ログでは、さまざまなスレッドがある状態を確認できます。
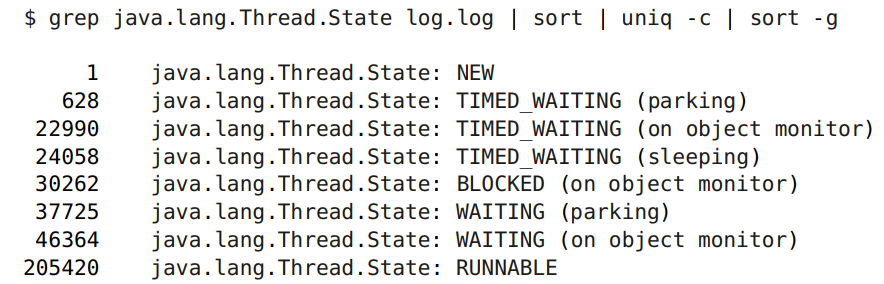
ここでは、イベントが発生するのを待つのではなく、まさにロックに関心があります。 ロックは3万件あり、これは20万件の実行可能ファイルに対してかなりの量です。
しかし、そのようなコマンドラインは単に犯人を表示します(余分なものは必要ありません-コマンドラインだけです)。
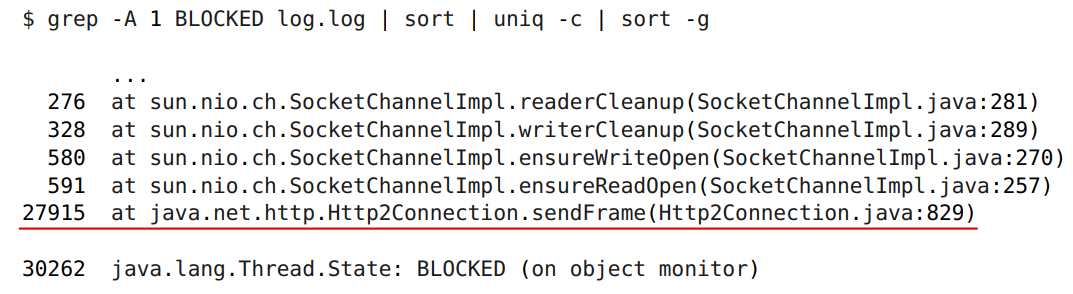
犯人は捕まった。 これは、データフレームをサーバーに送信するライブラリ内のメソッドです。 正しくしましょう。
void sendFrame(Http2Frame frame) { synchronized (sendlock) { try { if (frame instanceof OutgoingHeaders) { OutgoingHeaders oh = (OutgoingHeaders) frame; Stream stream = registerNewStream(oh); List frames = encodeHeaders(oh, stream); writeBuffers(encodeFrames(frames)); } else { writeBuffers(encodeFrame(frame)); } } catch (IOException e) { ... } } }
ここにグローバルモニターがあります。

しかし、このブランチ-

-リクエストの開始の開始。 これにより、最初のヘッダーがサーバーに送信されます(ここでは追加のアクションがいくつか必要です。今から説明します)。
これにより、他のすべてのフレームがサーバーに送信されます。

これはすべてグローバルロック下です!
sendFrame
自体は、平均で55%の時間がかかります。

ただし、この方法では1%かかります。
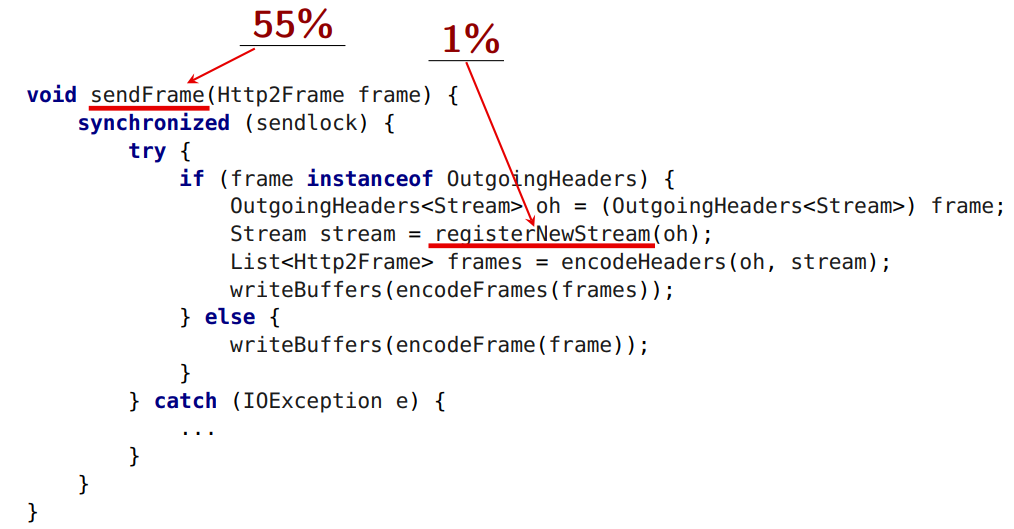
グローバルロックから何を取り出すことができるかを理解してみましょう。
新しいロックストリームの登録は取得できません。 HTTP標準は、ストリームの番号付けに制限を課しています。
registerNewStream
新しいストリームが番号を取得します。 データの転送のために、15、17、19、21の番号でストリームを開始し、21、15を送信した場合、これはプロトコルエラーになります。 番号の昇順で送信する必要があります。 ロックの下からそれらを取り出した場合、それらは私が待つ順番で送信されない場合があります。
ロックの下から除去できない2番目の問題:
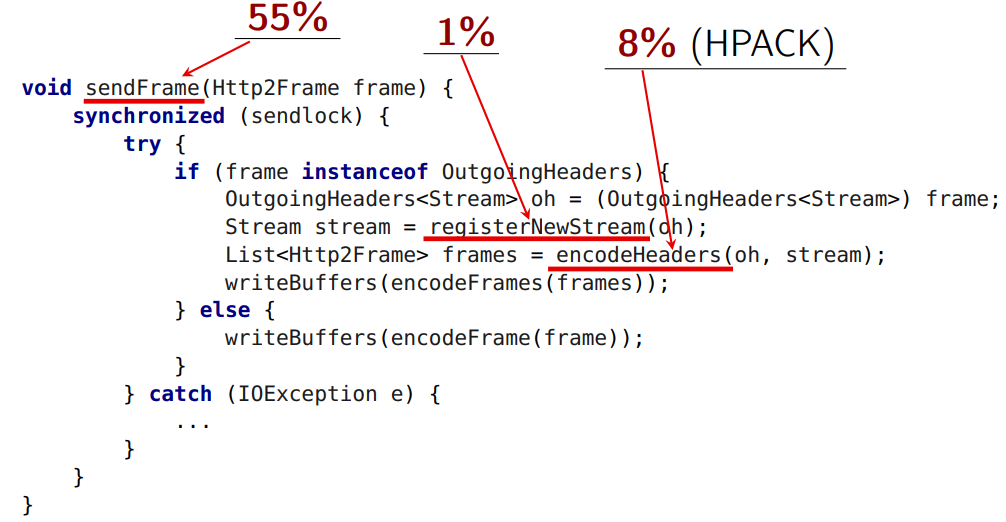
これは、ヘッダーが圧縮される場所です。
通常の形式では、見出しには通常のマップ-key-value(string to string)が添付されます。
encodeHeaders
はヘッダーを圧縮します。 そして、ここでHTTP 2標準の2番目のレーキは、ステートフル圧縮で機能するHPACKアルゴリズムです。 つまり 状態があります(したがって、非常によく圧縮されます)。 2つのリクエストが送信された場合(2つのヘッダー)、最初に1つを圧縮し、次に2つ目を圧縮してから、サーバーは同じ順序でそれらを受信する必要があります。 別の順序で受け取った場合、デコードできません。 この問題がシリアル化ポイントです。 すべてのHTTPリクエストのすべてのエンコーディングは単一のシリアル化ポイントを通過する必要があり、それらは並行して動作できず、その後でもエンコードされたフレームを送信する必要があります。
encodeFrame
メソッドは6%の時間を要し、理論的にはロック状態から削除できます。

encodeFrames
は、仕様で定義されている形式でフレームをバイトバッファーにドロップします(フレームの内部構造を準備する前に)。 6%の時間がかかります。
ソケットへの実際の記録が行われるメソッドを除き、ロックの下から
encodeFrames
を
encodeFrames
妨げるものはありません。

実装にはいくつかの微妙な違いがあります。
encodeFrames
は、フレームを1つではなく、いくつかのバイトバッファーにエンコードできることが
encodeFrames
。 これは、主に効率性によるものです(コピーが多すぎないようにするため)。
writeBuffers
ロックから
writeBuffers
しようとして、2つのフレームの
writeBuffers
が混在している場合、フレームをデコードできません。 つまり ある種の原子性を提供する必要があります。 同時に、
writeBuffers
は
writeBuffers
内で実行され、ソケットへの書き込みには独自のグローバルロックがあります。
最初に頭に浮かぶのは、キューの順番です。 このキューにバイトバッファーを正しい順序で配置し、別のスレッドに読み取らせます。
この場合、
writeBuffers
メソッドは通常、このスレッドを残します。 このロックの下に保持する必要はありません(独自のグローバルロックがあります)。 私たちにとっての主なことは、そこに来るバイトバッファの順序を保証することです。
そこで、最も困難な操作の1つを外部で削除し、追加のスレッドを起動しました。 クリティカルセクションのサイズが60%小さくなりました。
しかし、実装には欠点もあります。
- HTTP 2標準の一部のフレームでは、順序に制限があります。 ただし、他の仕様フレームはより早く送信できます。 他の前に送信できる同じWindowUpdate。 そして、サーバーが立っているので、これをやりたいと思います-それは待っています(フロー制御ウィンドウ= 0を持っています)。 ただし、実装ではこれが許可されていません。
- 2番目の問題は、キューが空の場合、送信ストリームがスリープ状態になり、長時間起動することです。
フレームの順序に関する最初の問題を解決しましょう。
明白なアイデアは
Deque<ByteBuffer[]>
です。
何とも混合できないバイトバッファの切っても切れないスライスがあります。 配列に入れ、配列自体をキューに入れます。 次に、これらの配列を一緒に混在させることができ、固定された順序が必要な場合は、それを提供します。
- ByteBuffer []-バッファのアトミックシーケンス。
- WindowUpdateFrame-キューの一番上に配置し、ブロッキングから完全に削除できます(プロトコルエンコーディングも番号付けもありません)。
- DataFrame-ロックから取り出してキューの最後に置くこともできます。 その結果、ロックはどんどん小さくなっています。
長所:
- より少ないロック。
- Window Updateを早期に送信すると、サーバーはデータを早期に送信できます。
しかし、ここにはもう1つマイナスがありました。 前と同様に、送信ストリームはしばしばスリープ状態になり、長時間起動します。
これをやってみましょう:

少し回ります。 その中に、受信したバイトバッファーの配列を追加します。 その後、ロック外のすべてのスレッド間の競合を手配します。 勝った人は誰でもソケットに書き込みましょう。 そして、残りの作業をしましょう。
flush()
メソッドには、効果をもたらす別の最適化が行われていることに注意してください:大量の小さなデータ(たとえば、3から4バッファーの10配列)と暗号化されたSSL接続がある場合、キューから複数の配列を取得できます、より大きな断片で、それらをSSLEngineに送信します。 この場合、コーディングのコストは大幅に削減されます。
提示された3つの最適化のそれぞれにより、スケーリングの問題を非常にうまく解決できました。 このようなもの(全体的な効果を反映):
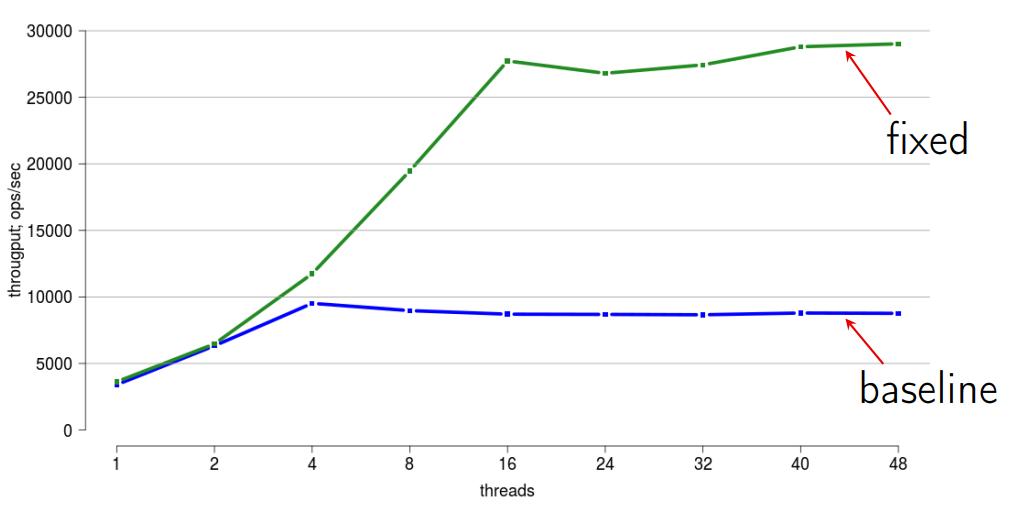
道徳: ロックは悪です!
ロックを解除する必要があることは誰もが知っています。 さらに、並行ライブラリーはますます高度で興味深いものになっています。
変更4.プールかGCか?
HTTP Client, 100% ByteBufferPool. … , — - , — … ByteBuffer , … . , . ( ):
- 20% ;
- ByteBufferPool.getBuffer() 12% .
, — . . : , ByteBuffer , , public API.
? :
- , ! eg Dr. Cliff Click, Brian Goetz, Sergey Kuksenko, Aleksey Shipil¨ev,…
- , — . ! eg Netty (blog.twitter.com/2013/netty-4-at-twitter-reduced-gc-overhead),…
DirectByteBuffer HeapByteBuffer
, — HTTPClient: DirectByteBuffer HeapByteBuffer?
:
- DirectByteBuffer I/O.
sun.nio.* HeapByteBuffer DirectByteBuffer;
- HeapByteBuffer SSL.
SSLEngine byte[] HeapByteBuffer.
, DirectByteBuffer . Write- nio, , HeapByteBuffer DirectByteBuffer-. DirectByteBuffer, .
— SSL-. HTTP 2 plain connection, SSL connection, , SSL - . , OpenJDK, , SSLEngine HeapByteBuffer, byte[] . DirectByteBuffer , .
, HeapByteBuffer :
- PlainConnection — HeapByteBuffer «» 0%-1% — , 0 — 1% — . DirectByteBuffer , ;
- SSLConnection — HeapByteBuffer 2%-3%
つまり HeapByteBuffer — !
, DirectByteBuffer , . , unsafe. HeapByteBuffer — intrinsic ( ). .
HeapByteBuffer 2-3% , DirectByteBuffer, , DirectByteBuffer. .
.
1:
- . , .
- ( ConcurrentLinkedQueue).
- ( ). , . , Jetty ByteBufferPool, - 1 . ByteBufferPool, . , :
- SSL (SSLSession.getPacketBufferSize());
- (MAX_FRAME_SIZE);
- .
1:
- «allocation pressure»
短所:
- . ? , ByteBuffer -, , , . , -. . , ;
- « »;
- ( );
- , :
-
ByteBuffer.slice()
ByteBuffer.wrap()
. ByteBuffer, - , , slice(). slice() . , . , . , - . , 128 , -, 128 , . , . — -. - . , . , .
2: — GC
GC , DirectByteBuffer, HeapByteBuffer.
- , Public API, , - .
- , , GC, —
ByteBuffer.slice()
/wrap()
— .
長所:
- ;
- «public API»;
- « »;
- , ;
- .
:
- -, — «allocation pressure»
- , , . , I/O, , 32 , 16 . 12 . ? . ( ) — 12 16 .
3:
. . .
:
- . , HPACK, — . — GC .
- HTTP- — , - .
- — (GC )
:
- — - — 16 32 ;
- (DataFrame) —
slice()
(GC );
- — .
HTTP 2 . (, ), - , - . , slice, , — GC.
SSL-, .
:
- ( -, , , );
- «public API»;
- « »;
- ;
- ;
- .
— : «allocation pressure».
, , , . . . 32 , 32 . . baseline — ( 100%). allocation rate baseline .

, , . , , , . allocation rate? GC-:

GC- allocation rate .
, ( ) 25% . 27% , 36% . .
10% , , .
: , public API .
- «urban legends»
-
- « - »
小計
, . , .
HttpClient JettyClient . — ; — .
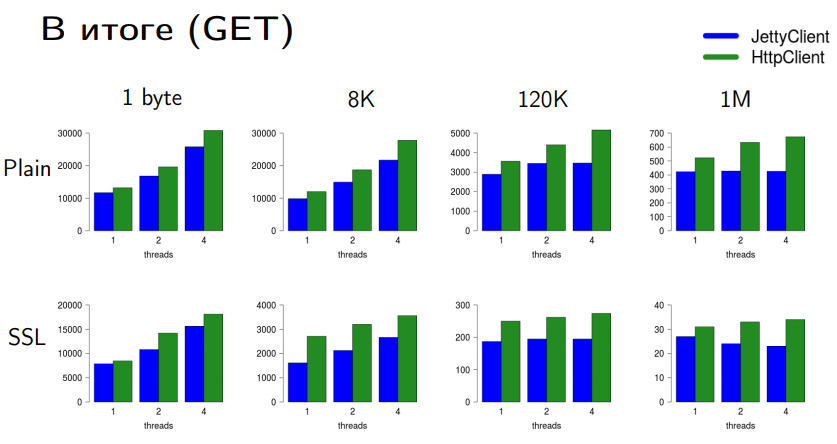
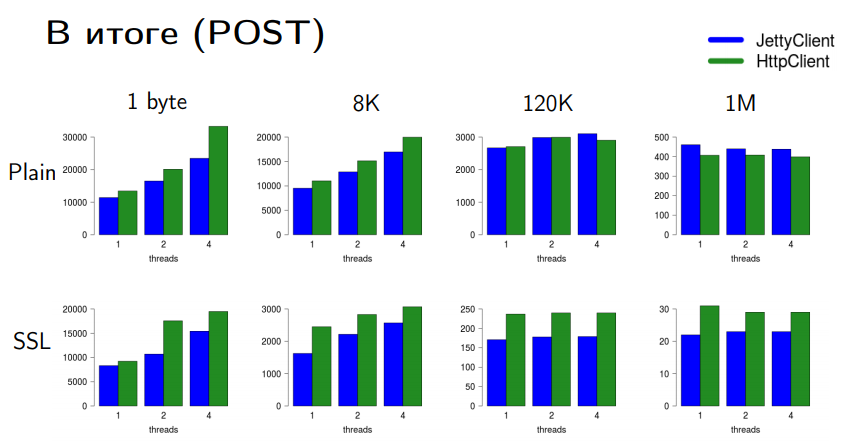
GET- Jetty. . . , , - , Java 9 Java 10 HttpClient .
POST- . PLAIN- Jetty - . SSL- .
post-? : SSL- lock — SocketChannel. . JDK, nio — , . , bottleneck.
SSL ( encryption) . SSLEngine encryption / decryption. . encryption , . SSL-. . , - OpenSSL-.
5. API
.
API?
public <T> HttpResponse<T> send(HttpRequest req, HttpResponse.BodyHandler<T> responseHandler) { ... } public <T> CompletableFuture<HttpResponse<T>> sendAsync(HttpRequest req, HttpResponse.BodyHandler<T> responseHandler) { return CompletableFuture.supplyAsync(() -> send(req, responseHandler), executor); }
executor — (executor ; executor, , , executor).
, API:

, - .
. — , … .

1 — CompletableFuture
, wait condition. API, Async executor, executor .
, . — API, API executor. fixed thread pool ( executor, ).
, executor- . , , - . - , executor- . それだけです 到着しました。
, CompletableFuture. このようなもの:
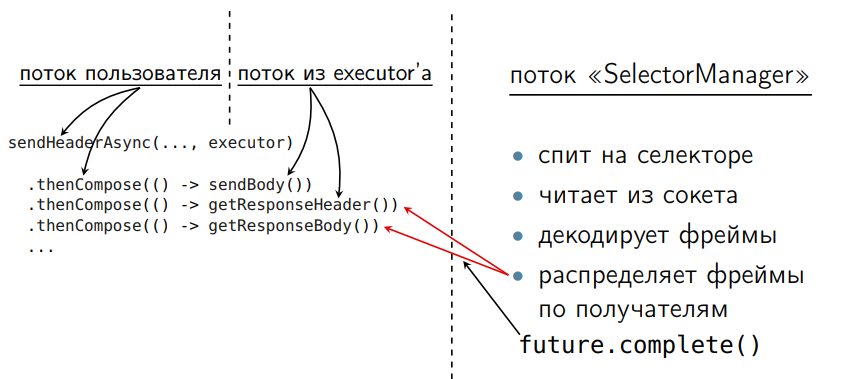
. . thenCompose, future, future. C , thread- SelectorManager. , . , complete.
thenCompose , future, , , ( CompletableFuture), . executor, - , executor-, . CompletableFuture, . . . .
condition wait, CompletableFuture. CompletableFuture , . +40% .
2 —
. , . , CompletableFuture. — thenSomething. «Something» Compose, Combine, Apply — CompletableFuture. CompletableFuture.
foo — , — ?

— .
— .. thenSomething — CompletableFuture , foo . CompletableFuture , complete , .. . .
, . , sendAsync. つまり , sendAsync, CompletableFuture . executor , , .
Java- . : , CompletableFuture :
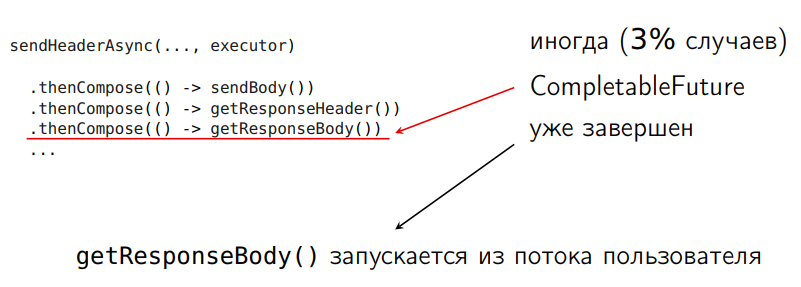
( ), . — 3% . , , , , . , , .. . , executor-.
, , Compose Async. thenCompose
thenComposeAsync()
, , , .
:
- ;
短所:
- executor' executor' (). ,
thenComposeAsync
,thenApplyAsync
Async CompletableFuture executor-, executor- ( Async), fork-join executor. CompletableFuture , ? - — .
:
CompletableFuture<Void> start = new CompletableFuture<>(); start.thenCompose(v -> sendHeader()) .thenCompose(() -> sendBody()) .thenCompose(() -> getResponseHeader()) .thenCompose(() -> getResponseBody()) ...; start.completeAsync( () -> null, executor); // !!! trigger execution
CompletableFuture, , , . CompletableFuture —
completeAsync
— executor. 10% .
3 — complete()
, CompletableFuture:

CompletableFuture SelectorManager CompletableFuture .
future.complete
. , SelectorManager — , . CompletableFuture. . response.complete SelectorManager , SelectorManager, , . - — executor, .
.

completeAsync
.

completeAsync
, .
executor executor . SelectorManager executor - executor. executor- , . .
CompleteAsync
. Async.

. , , — .
長所:
- «SelectorManager»
短所:
- executor' executor' ()
: , CompletableFuture ? CompletableFuture — Async. — , CompletableFuture , executor .

, .
16% .
CompletableFuture 80%.
: .
CompletableFuture ( since 1.8)
6
HTTP Client , Public API. . .
, , executor. HTTP Client executor, ,
CachedThreadPool()
.
,
CachedThreadPool()
. , :

CachedThreadPool()
. . ,
CachedThreadPool()
, . , — , , . , , .
, ( ), , ,
CachedThreadPool()
20 — . 100 out of memory exception. — , .
, , « ». , , .
CachedThreadPool()
12 . 100 800 . , .
CachedThreadPool()
executor . , ,
CachedThreadPool()
executor . — . , .
ThreadPool executor. . ,
CachedThreadPool()
:

— , — bottleneck, , SSLEngine . .
: ThreadPool' .
HTTP 2 Client .
, , Java API. -, . , . JDK — , API.
Norman Maurer , . — , : Writing Highly Performant Network Frameworks on the JVM — A Love-Hate Relationship .
API JDK , API . , JDK, Netty. , , .
Java , , JPoint 2018 :
- Java ( , Devexperts)
- : , ( , JetBrains)
- ( , )
- Java EE 8 finally final! And now EE4J? (David Delabassée, Oracle)