これは、コードの最適化に関する一連の記事の2番目の記事です。 最初から、パフォーマンスを低下させるコードのボトルネックを見つけて分析する方法を学びました。 この例の主な問題は、メモリアクセスが遅いことです。 この記事では、メモリを操作する際のコストを削減し、プログラムの速度を上げる方法を検討します。
コードの最新バージョンは次のとおりです。
void Modifier::Update() { for(Object* obj : mObjects) { Matrix4 mat = obj->GetTransform(); mat = mTransform*mat; obj->SetTransform(mat); } }
メモリアクセスの最適化
メモリに関する仮定が正しい場合、いくつかの方法でプログラムを高速化できます。
- 費用を多数のフレームに分配して、フレーム内のいくつかのオブジェクトを更新します。
- 並行して更新します。
- 圧縮されたマトリックス形式を作成し、メモリ消費量を減らしますが、処理に必要なプロセッサリソースを増やします。
- キャッシュを十分に活用してください。
もちろん、最後のステップから始めます。 プロセッサ開発者は、メモリへのアクセスが遅いプロセスであることを理解しており、機器を設計する際にこの欠点を可能な限り補おうとします。 たとえば、必要と思われるデータは、メモリから事前に取得されます。 プログラムが本当にそれらを要求するとき、待機時間は最小限です。 プログラムがデータにシーケンシャルにアクセスする場合、これは簡単に実装できますが、ランダムアクセスでは完全に不可能です。 したがって、配列内のデータへのアクセスは、リンクされたリストからのアクセスよりもはるかに高速です。 ネットワークには、キャッシュの操作に関する多くの優れたドキュメントがあるため、高性能プログラムの作成に関心がある場合は、必ず学習してください。 開始するのに役立つ資料をいくつか紹介します。
メモリ内のレイアウトを変更する
最適化の最初のステップは、コードではなく、メモリのレイアウト(メモリレイアウト)を変更することです。 メモリを操作する簡単なツールを作成しました。これにより、特定のタイプのすべてのデータが1つのプールで見つかり、このデータが可能な限り順番に使用できるようになります。 そのため、このインスタンス内に行列や他の型を保存する代わりに、オブジェクトを配置するときに、そのような型のプールにあるデータ型へのポインタを保存します。
その結果、Objectクラスのデータストレージは次のように変更されます。
protected: Matrix4 mTransform; Matrix4 mWorldTransform; BoundingSphere mBoundingSphere; BoundingSphere mWorldBoundingSphere; bool m_IsVisible = true; const char* mName; bool mDirty = true; Object* mParent;
これについて:
protected: Matrix4* mTransform = nullptr; Matrix4* mWorldTransform = nullptr; BoundingSphere* mBoundingSphere = nullptr; BoundingSphere* mWorldBoundingSphere = nullptr; const char* mName = nullptr; bool mDirty = true; bool m_IsVisible = true; Object* mParent;
それは私が聞くことです:「しかし今、より多くのメモリが使用されています! ポインターと、それが参照するデータ自体の両方が含まれています。 あなたは正しいです。 もっとメモリが必要です。 多くの場合、最適化は妥協です:パフォーマンスを向上させる代わりに、メモリを増やすか精度を下げます。 この場合、別のポインターが追加され(32ビットアセンブリの場合は4バイト)、Objectからのポインターに従って、変換する必要のある実際の行列を見つける必要があります。 はい、これは追加の作業ですが、探しているマトリックスはObjectインスタンスから読み取るポインターのように順番に配置されるため、回路はメモリからランダムな順序で読み取るよりも高速に動作するはずです。 これは、オブジェクト、ノード、および修飾子が使用するメモリにデータを順番に配置する必要があることを意味します。 実際のシステムでは、このようなタスクを解決するのは難しい場合がありますが、例を検討しているため、立場を強化するためにarbitrary意的な制限を課します。
オブジェクトコンストラクターは次のようになりました。
Object(const char* name) :mName(name), mDirty(true), mParent(NULL) { mTransform = Matrix4::identity(); mWorldTransform = Matrix4::identity(); sNumObjects++; }
そして今、このようになります:
Object(const char* name) :mName(name), mDirty(true), mParent(NULL) { mTransform = gTransformManager.Alloc(); mWorldTransform = gWorldTransformManager.Alloc(); mBoundingSphere = gBSManager.Alloc(); mWorldBoundingSphere = gWorldBSManager.Alloc(); *mTransform = Matrix4::identity(); *mWorldTransform = Matrix4::identity(); mBoundingSphere->Reset(); mWorldBoundingSphere->Reset(); sNumObjects++; }
gManager.Alloc()
呼び出しは、単純なブロックアロケーターの呼び出しです。
Manager<Matrix4> gTransformManager; Manager<Matrix4> gWorldTransformManager; Manager<BoundingSphere> gBSManager; Manager<BoundingSphere> gWorldBSManager; Manager<Node> gNodeManager;
メモリの大きなチャンクを事前に割り当ててから、各Alloc()
呼び出しは次のNバイトを返しますMatrix4
場合は64バイト、 Matrix4
場合は32バイト。 ただし、特定のタイプには大量のメモリが必要です。 実際、これは、メモリに事前に割り当てられた特定タイプのオブジェクトの大きな配列です。 このようなディストリビュータの利点の1つは、特定の順序で配置された特定のタイプのオブジェクトがメモリ内で次々に移動することです。 オブジェクトをアクセスしたい順序で配置すると、ハードウェアはより効率的にプリフェッチして、指定された順序でオブジェクトを処理できます。 幸いなことに、この例では、メモリに配置された順序で行列やその他の構造を調べます。
すべてのオブジェクト、マトリックス、および境界球が回転順に保存されたので、プログラムのプロファイルを変更して、パフォーマンスが変化したかどうかを確認します。 コードへの唯一の変更は、メモリレイアウトの変更と、ポインタを介したデータの使用方法であることに注意してください。 たとえば、 Modifier::Update()
は次のようになります。
void Modifier::Update() { for(Object* obj : mObjects) { Matrix4* mat = obj->GetTransform(); *mat = (*mTransform)*(*mat); obj->SetDirty(true); } }
マトリックスへのポインターを使用するため、 SetTransform
を使用してマトリックス乗算の結果をオブジェクトにコピーする必要がなくなりました。すぐに変換します。
パフォーマンスの変化
変更後、最初にコードが正しくコンパイルおよび実行されていることを確認します。 テストプロファイルの以前の結果は次のとおりです。

しかし、メモリ内のレイアウトを変更した後はどうなりましたか:

つまり、プログラムをフレームあたり17.5ミリ秒から10.15ミリ秒に加速しました! メモリ内のデータのレイアウトのみを変更すると、ほぼ2倍の速度になりました。
この一連の記事の主なものを思い出してください。メモリ内のデータのレイアウトは、プログラムのパフォーマンスにとって重要です。 人々は性急な最適化の危険性について話しますが、私の経験が示唆しているように、データと処理および処理の順序との関係について少し慎重にすれば、生産性が大幅に向上します。 事前にレイアウトを計画できない場合は、レイアウトの再編成と使用に役立つコードを記述しようとすると、最適化が促進されます。 ほとんどの場合、スローダウンするのはコードではなく、データアクセスです。
次のボトルネック
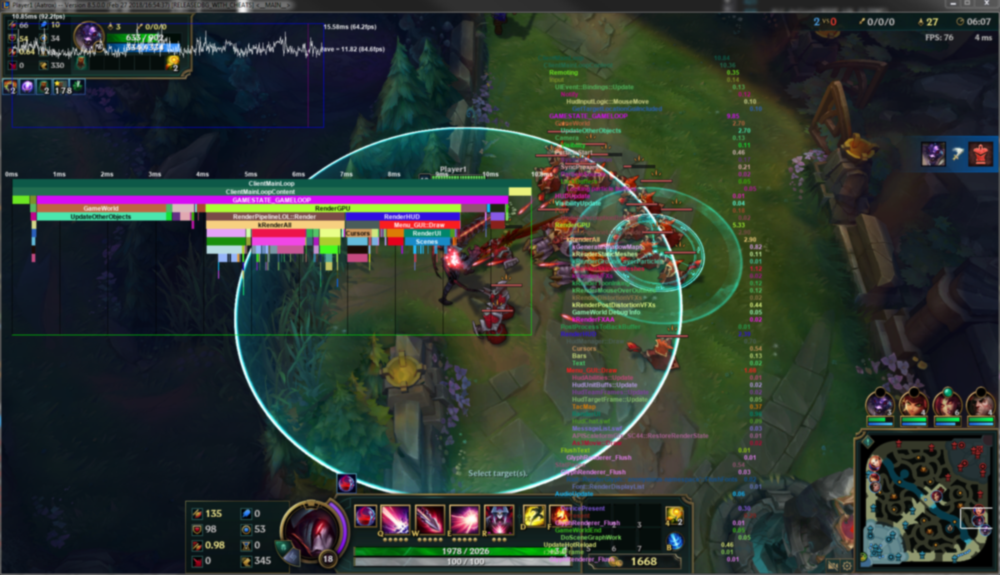
コードは高速ですが、それで十分ですか? もちろん違います。 パフォーマンス特性が変更されたため、プロファイルを再作成し、最適化の次の候補を見つける必要があります。 サンプリングプロファイラーの実行を比較します。 それは:

次のようになりました:

サンプリングプロファイルでは、プログラムが現在より高速であるかどうかはわかりません。 各機能に費やされた相対的な時間のみが表示されます。 これで、行列演算子の乗算関数が最も長く機能します。 これは、他の人と比べて速度が低下したことを意味するのではなく、完了するまでに時間がかかり始めました。 サンプリングを見て、ボトルネックがどこにあるのかを見てみましょう。
まず、 Modifier::Update()
見てください。 マトリックスはスタックにコピーされなくなりました。 これは、ポインターをマトリックスに渡し、64バイトすべてをコピーするわけではないため、お勧めです。

関数の時間の大部分は、行列乗算の呼び出しの設定に費やされ、その結果をobj->mTransform
の場所にコピーしobj->mTransform
(簡略化されたアセンブラーを以下に示します)。

問題が発生します:関数を呼び出すコストを削減する方法は? 答えは簡単です。インラインにする必要があります。 しかし、行列乗算関数をよく見ると、インライン化の準備がすでに整っていることが明らかになります。 それでは問題は何ですか?
関数が十分に小さい場合、コンパイラは多くの場合、自動的にインライン化することを決定します。 ただし、プログラマはこの動作を制御できます。 インライン関数の最大サイズを変更できます。一部のコンパイラでは、インラインの「強制」が可能ですが、これには代価があります。 コードのサイズが大きくなる可能性があり、さまざまな場所からより多くのバイトを実行するとキャッシュがスリップし始めます。
SIMDはありますか?
行列乗算演算子は、SIMDではなく、単一の浮動小数点数を使用します(単一命令複数データ:最新のプロセッサは、4つの浮動小数点数を同時に乗算するなど、データの複数のコピーで単一の命令を実行できる命令を提供します)。 SIMDを使用することをコンピューターに伝えても、無視され、同様のコードが生成されます。

SIMD命令はありません。16バイトにアライメントされたデータが必要であり、4バイトのアライメントしか持っていないためです。 もちろん、アライメントされていないデータをロードしてから、それをSIMDレジスタに転送できます。 ただし、SIMD処理の量が大きすぎない場合、一度に1つの浮動小数点数を使用する場合よりも速度が低下する可能性があります。 幸いなことに、このようなオブジェクト用のメモリマネージャを作成したため、マトリックスに16バイト(またはそれ以上)のアライメントを強制できます。 この例では、16に決めました。また、VectormathライブラリーにSIMD命令のみを生成させました。
プロファイラーの次の実行時に、平均フレーム期間が10.15から約7ミリ秒に減少したことが判明しました。

サンプリングプロファイルを見てみましょう。
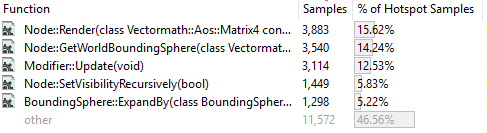
行列乗算演算子が消えました。 SIMD命令を変換すると、関数のサイズが小さくなり(1060バイトから約350)、コンパイラーはインライン化できました。 行列乗算コードはそれを呼び出したすべての関数に含まれていましたが、現在では乗算関数のインスタンスを呼び出しません。 副作用として、コードサイズが大きくなりました(255の代わりに.exeファイルが256 Kbを占有し始めたため、あまり気にしません)が、呼び出された関数を使用するために関数のパラメーターをスタックにコピーする必要がなくなりました。
Modifier::Update()
詳しくModifier::Update()
ましょう。
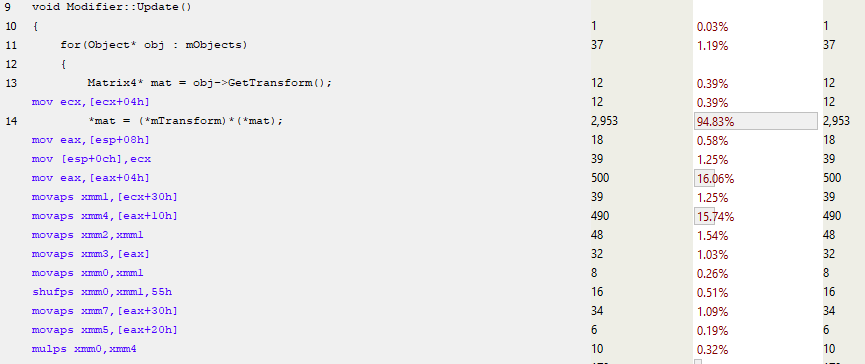
13行目はmTransformへのポインタを取り、その後すぐに、マトリックスSIMDコードはMOVAPS命令(位置合わせされた単精度浮動小数点値の移動)を使用してxmmレジスタに入力します。 そのため、MULPS(Multiply Packed Single-Precision Floating-Point Values)などの命令を使用して一度に4つの浮動小数点数を処理するだけでなく、これらの数値も同時に読み込みます。 その結果、関数内の命令の数が大幅に削減され、パフォーマンスが向上します。 まだブレーキがあり、キャッシュミスに起因する可能性がありますが、主に命令の使用とインライン化の改善により、生産性が向上しました。 コードの初期では、行列の乗算がよく呼ばれていましたが、今ではかなりの量の関数呼び出しがなくなりました。
そのため、フレームの処理時間を17.5から約7ミリ秒に短縮しました。つまり、コードを劣化させることなく2.5倍のパフォーマンスを向上させました。 複雑さを大幅に増加させることなく、より速く動作し始めました。 データをメモリに保存する方法を制限しましたが、高レベルのコードを変更せずに低レベルの変更を行うことができます。
追加の割り当て:仮想機能
2009年のプレゼンテーションでは、ここよりもはるかに進んでいます。コードを壊し、すべてのバーチャルを削除し、コードの柔軟性を低下させましたが、パフォーマンスは2倍になりました。 今はしません。 サンプルをさらに最適化できると確信していますが、読みやすさ、拡張性、移植性、メンテナンスの容易さでこれを支払う必要があります。 代わりに、実装を検証し、仮想機能の影響を検討します。
派生クラスで再定義できる基本クラスの仮想関数が呼び出されます。 たとえば、Objectクラスには、 Render()
の機能を定義するCube()
およびElephant()
オブジェクトを継承および作成できる仮想関数Render()
があります。 これらの新しいオブジェクトはノードの1つに追加できます。元のオブジェクトのポインターを使用してRender()
を呼び出すと、オーバーライドされたRender()
関数が呼び出され、画面に立方体または象が描画されます。
この例の最も簡単なテストは、オブジェクトとノードのSetVisibilityRecursively()
メソッドです。 ノードが完全に錐台の内側または外側にあるカリングフェーズ中に使用されるため、その子は単純に表示または非表示に割り当てることができます。 Objectの場合、内部フラグが設定されるだけです:
virtual void SetVisibilityRecursively(bool visibility) { m_IsVisible = visibility; }
Nodeの場合、すべての子に対してSetVisibilityRecursively()
が呼び出されます。
void Node::SetVisibilityRecursively(bool visibility) { m_IsVisible = visibility; for(Object* obj : mObjects) { mObjects[i]->SetVisibilityRecursively(visibility); } }
これは、サンプリングプロファイルを分析するときにノードバージョンに表示されるものです。
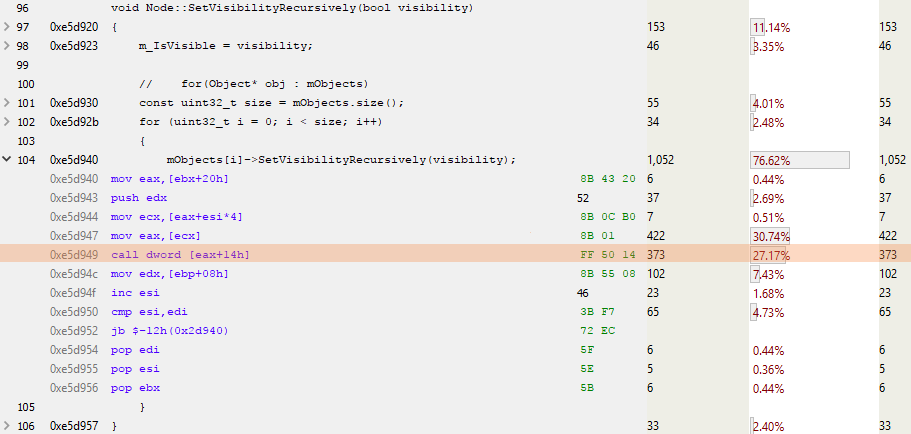
ESIはループのカウンターであり、EAXは次のオブジェクトへのポインターです。 強調表示されている行はCALL DWORD [EAX + 14h]です。ここでは、仮想テーブルの先頭から0×14(10進数の20)バイトにある仮想関数が呼び出されます。 ポインターは4バイトで、すべての合理的な人が0からカウントを開始するため、これはオブジェクトの仮想テーブル内の5番目の仮想関数の呼び出しです。 または、以下に示すように、 SetVisibilityRecursively()
:

仮想関数を呼び出すには、もう少し作業が必要です。 仮想テーブルをロードする必要があります。次に、仮想関数を検索して呼び出し、いくつかのパラメーターと「this」ポインターをそのテーブルに渡します。
事実上欠けているバーチャル
次のコード例では、ノードとオブジェクトで、仮想関数を通常の関数に置き換えました。 これは、それぞれが異なるため、各ノードに2つの配列(ノードとオブジェクト)を保持する必要があることを意味します。 例:
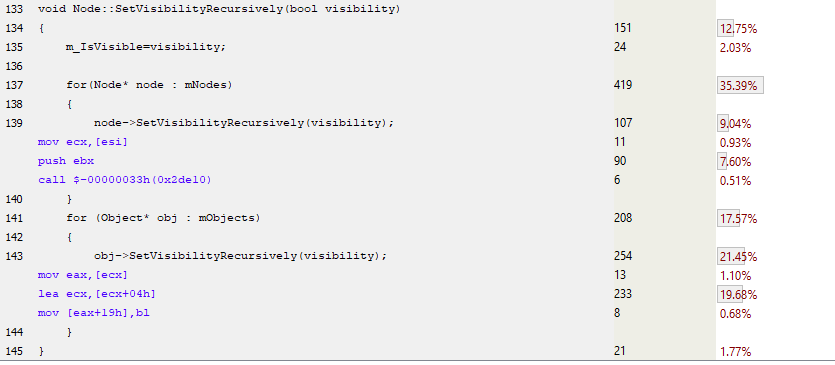
ご覧のとおり、仮想テーブルのダウンロードや仮想関数の逆参照はありません。 最初のケースでは、 Node::SetVisibilityRecursively()
実装の単純な関数呼び出しのみがあり、2番目のケースでは、Object実装では、関数は完全にインラインです。 コンパイラーは、実行時にのみ定義できないため、仮想関数をインライン化できません。 したがって、この非仮想実装はより高速に動作するはずです。 プロファイルして調べてみましょう。

この最適化により、パフォーマンスはほとんど変化しませんでした:6.961から6.963ミリ秒。 これは、コードが0.002ミリ秒遅くなったことを意味しますか? まったくありません。 この違いは、システムのノイズ背景に起因する可能性があります。これは、多くのタスクを同時に実行するOSを実行しているパーソナルコンピューターです(Twitterフィードの更新、メールのチェック、閉じ忘れたページのアニメーションGIFの更新)。 OSが実行可能コードにどのように影響するかを理解するために、貴重なWindows Performance Analyzerツールを使用できます。 このソフトウェアは、コードのパフォーマンスを表示するだけでなく、システム全体を全体的に表示します。 そのため、コードが突然2倍の長さで処理を開始した場合は、他の誰かがこれを犯しているかどうかを確認し、プロセッササイクルを盗みます。 ブルース・ドーソンの優れたブログも読むことができます。
したがって、仮想関数を削除しても、コードのパフォーマンスにはほとんど影響しません。 仮想テーブルでの検索回数の減少とより少ない命令の実行にもかかわらず、プログラムは同じ速度で実行されます。 最も可能性が高いのは、Miracles of Modern Equipmentです-分岐予測と投機的実行は、ハッキングだけでなく、繰り返しコードを取得し、可能な限り迅速に実行する方法を見つけ出すのにも適しています。
ヘンリーペトロスキーを引用するには:
「現代のソフトウェア業界の最も驚くべき成果は、ハードウェア業界の着実で見事な成功の放棄の継続です。」
仮想関数は無料では使用できないことを示しましたが、この場合、コストはごくわずかです。
まとめ
サンプルコードのプロファイルを作成し、ボトルネックを特定し、その影響を軽減しようとしました。 コードを変更するたびに、プロファイルを再プロファイリングして、悪化したか改善したかを把握しました(エラーは有用であり、そこから学習します)。 そして、各段階で、コードの実行方法、メモリへのアクセス方法をよりよく理解します。 このソリューションは、高レベルのコードを最小限に修正し、単一フレームのレンダリング時間を17ミリ秒から7ミリ秒に短縮します。 メモリが遅いため、ハードウェアを操作して高速コードを記述する必要があることがわかりました。
シリーズの第3部では、 League of Legendsで最近発見したパフォーマンスのボトルネックの特定、分析、および最適化について説明します。