過去1年間に取り組んできたすべての製品のソースコードを公開しました。この記事では、それらについて簡単に説明します。
昨年、Hyperpilotはステルスモードで動作していたので、何をしようとしていたのか説明します。 私たちの使命は、インフラストラクチャにインテリジェンスを提供し、効率と生産性を向上させることです。 DevOpsとシステムエンジニアは、手作業を必要とするコンテナインフラストラクチャとプロセスに関連する多くの決定を行う必要性に常に直面しています。 これらのソリューションには、仮想マシン構成(インスタンスタイプ、リージョンなど)、コンテナ構成(リソースリクエスト、コンテナインスタンス数など)からアプリケーションレベルの構成オプション(jvmなど)までのすべてが含まれます。 。 オペレーターと開発者は静的な選択をすることが多く、運用スタッフはこの決定が行われた理由を知りません。 最悪なことに、オペレーターはやりすぎの傾向があり、これはインフラストラクチャの非効率的な使用につながります。 私たちは、オペレータがより良いソリューションのためのツールを見つけ、将来の推奨事項を自動化するのに役立つ3つの製品に取り組みました。 次に、パブリックドメインにある高レベルの製品について説明します。
HyperConfig:スマート構成検索
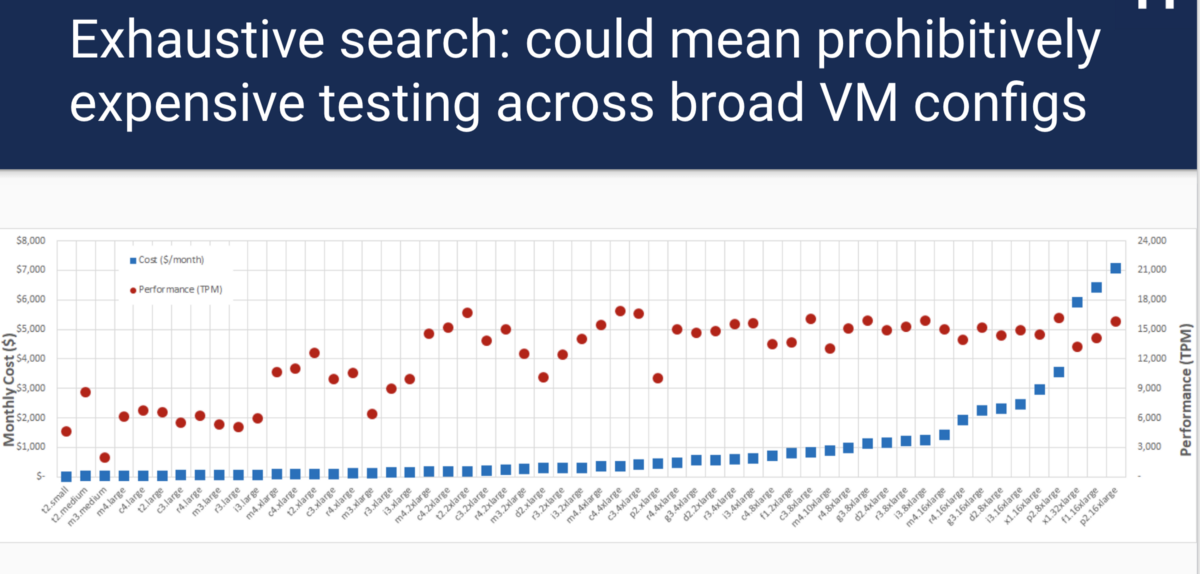
クラウドを使用し、KubernetesまたはMesosを使用してドッカーコンテナをデプロイした場合、最初の問題の1つは、各コンポーネントに最適な構成を見つけ出すことです。 たとえば、どのタイプの仮想マシンインスタンスを使用する必要がありますか? 展開するノードの数 コンテナに割り当てられるプロセッサ時間とメモリはどれくらいですか? これらの問題はすべて、コストとパフォーマンスのトレードオフを意味します。 たとえば、仮想マシンのサイズを考えます。 大規模な仮想マシンのインスタンスを選択すると、コストがかかりますが、パフォーマンスが向上する場合があります。 小さすぎる仮想マシンを選択すると、パフォーマンスとSLAの問題が発生します。 どのソリューションが優れているかを判断することは困難です。MySQLtpccベンチマークテストを実行して、AWSインスタンスの各タイプで実行する場合、パフォーマンスとコスト比の最適な選択は線形で予測可能なパターンに従いません。
さらに、徹底的な検索には多くの時間とお金が必要です。 幸いなことに、これは新しい問題ではなく、多くの研究ソリューションがありますが、負荷テストの一般的な結論をサポートする一般的なオープンソースソリューションはありません。
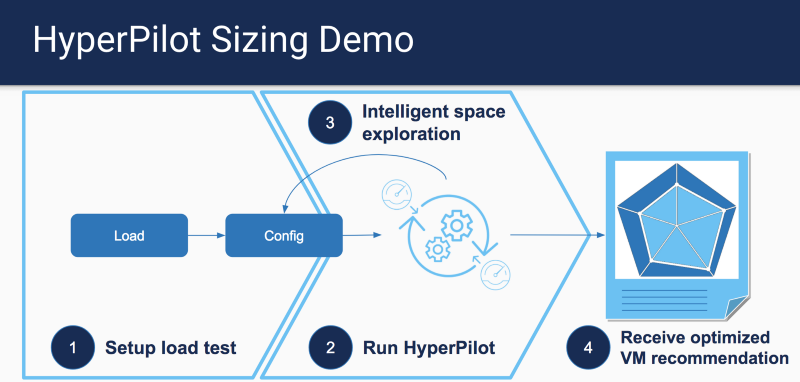
CherryPickの作業に着想を得て、hyperconfigを作成し、負荷テストの全体的な結果に基づいてさまざまな基準に対応するAWSインスタンスタイプのセットを提案しました。
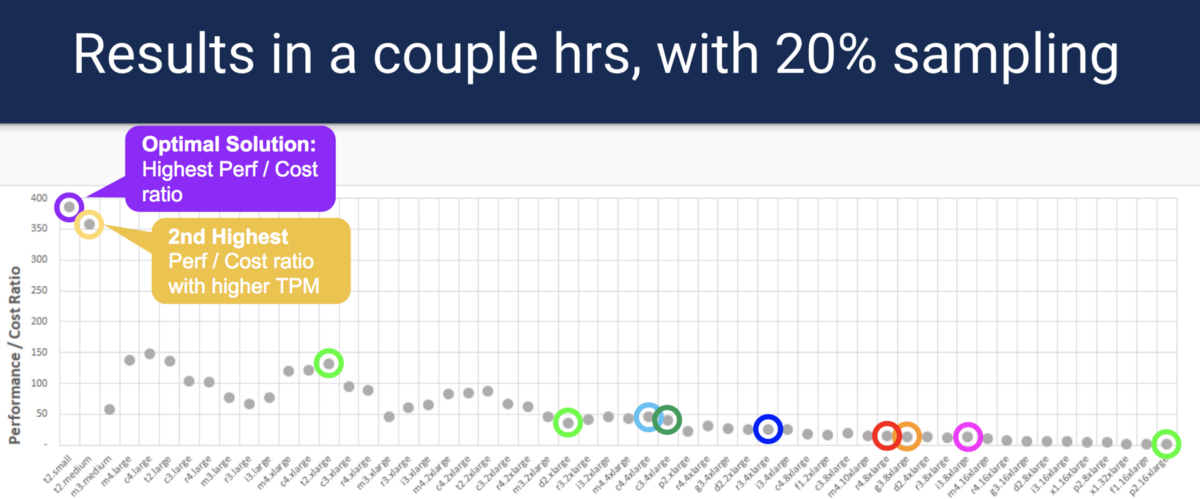
インスタンスの各タイプを徹底的に検索する代わりに、HyperConfigは、ベイズ最適化と呼ばれる既知の最適化方法を使用して、より少ないサンプルポイントで最適なオプションを見つけます。 サンプルを並行して実行できるため、時間とコストが削減されます。 注意:HyperConfigは最適なオプションの場所を保証しませんが、最適なオプションに最も近いオプションを選択します。
デモバージョンの実行方法の詳細とコードの詳細については、 サイジングアナライザーのセクションを参照してください。
HyperPath:リソース問題分析
オペレーターが直面する問題の1つは、Kubernetesクラスターのパフォーマンス低下の原因を見つけることです。 ただし、問題の検索を最も可能性の高い場所に絞り込むと、パフォーマンスの問題の原因を診断して見つけることができるシステムを開発できます。 HyperPathは、CPU /メモリ/ネットワーク/ IOの問題領域の検出に焦点を当てており、コンテナに設定された制限またはノードリソースの不足が原因で問題が発生しているかどうかも判断します。
HyperPathは、アプリケーションのSLOメトリック(たとえば、95パーセンタイル遅延)、およびcpu / mem / net / IOコンテナーパラメーターと同様のノードレベルメトリックを含むリソースメトリックにアクセスできると想定しています。 HyperPathは、このデータを使用して、どのリソースメトリックがしきい値を超えたかを相関させ、最も高い相関メトリックでマスターデータをランク付けしようとします。
デモでは、アプリケーションの遅延中にSLOしきい値を超えたプロセッサおよびその他のリソースのボトルネックを検出できることがわかります。
詳細とソースコードについては、 診断アナライザーのセクションを参照してください。
ベストエフォートコントローラー
すべてのオペレーターが、アプリケーションに必要なリソースの量を意図的に誇張していることはよく知られています。 この動作の最も重要な理由の1つは、突然発生する可能性のあるサージを考慮することです。 これにより、ピーク負荷がまれにしか発生しないため、クラスターリソースの使用率が低くなります。 最小負荷のリソースを割り当てて、クラウドと自動スケーリングに依存することはできません。クラスターのスケーリングプロセスにはピーク負荷の間に1分かかることがあるためです。 余剰リソースをどのように使用しますか? 1つの方法は、ベストエフォート(BE)ワークロードを実行することです。 バースト時にワークロードを制御し、利用可能なリソースの量を増減できるようにする必要があります。
クリストス・コジラキスとデビッド・ローのヘラクレスに関する研究は、資源効率の改善の問題を解決することを目的としていました。 Heraclesの機能の詳細については、ソースドキュメントを参照してください。 非常に高いレベルで、Heraclesは各ノードにコントローラーを作成し、これらのコントローラーのそれぞれには、リソース使用率をモニターする各リソース(プロセッサー、メモリー、ネットワーク、IO、キャッシングなど)の補助コントローラーがあります。 次に、メインアプリケーションのSLOメトリックを入力として使用して、各ワークロードのリソースをいつどのようにスケーリングするかを決定します。 アプリケーションメトリックが大幅に増加すると、BEジョブにさらに多くのリソースを割り当て始めることができ、逆もまた同様です。負荷が低下したときに削減します。
Hyperpilotでは、Heraclesアルゴリズムを開発し、Kubernetesで動作するようにしました。 次のビデオでは、マイクロサービスの横にあるBestEffort QoS品質クラスを使用してSparkを起動したときのコントローラーの動作を確認できます。
BEコントローラーなしでマイクロサービスの隣でSparkを起動すると、Spark Jobからの干渉により遅延が増加します。 Sparkを動作するようにBestEffortを設定しても、干渉の問題が除外されないことに注意してください。 BEコントローラをオンにすると、SLOしきい値内で制御される遅延が観察され、BEジョブは完了せずに進行できます。
コードベースの詳細については、 こちらをご覧ください 。
これらのプロジェクトが、kubernetesとアプリケーションからのリソース使用率データの使用がコストとパフォーマンスにどのように影響するかを示すことを期待しています。
オリジナル: Hyperpilotは、製品の100%をオープンソース化しました 。