
このライブラリは、テキスト要求への応答を返すアルゴリズムとTelegramメッセンジャーAPIの間のインターフェースの構築専用です。 機械学習アルゴリズムの柔軟な適用のために設計されています。 ちなみに、私よりも知識が豊富な専門家は、応答機能への単一のエントリポイントを使用して、さまざまな通信チャネル(インスタントメッセンジャー、Webウィジェットなど)のインターフェースを統合する成功したオプションを提供できます。コメントでそれを議論できてうれしいです。 個人的には、やがて、Flaskで独自に作成されたモジュールを使用し、http-requestsを介してアルゴリズムにアクセスする必要がありました。 各ユーザーインターフェース(Telegram、Facebookなど)と対話するには、通信に関与する別のプログラムを作成し、要求をFlask APIで理解できるように記述された統一形式に変換し、最後に、受信した応答をユーザーインターフェースで理解できる形式に変換し直す必要がありました。 この設計はやや厄介に見えるので、繰り返しますが、このトピックの経験豊富な同僚とコメントでこの問題を議論することを嬉しく思います。
ライブラリの
main_loop_webhooks()
時に外部から呼び出されるメイン関数
main_loop_webhooks()
は、メタモデルを生成する関数[1]、モデルの適用結果に基づいて応答を生成する関数、設定の更新(特定の商品の天気予報や価格の定期的な更新など
main_loop_webhooks()
を受け取ります、特定の形式のリソースのリスト(現在、Telegramに返信を送信し、ボットが機能し、クラッシュしていないことを外部スクリプトに定期的に警告するために使用されます)。
メタモデルの生成と最終的な回答は、メタモデルの設定、検証、テストの利便性を高めると同時に、本質的にメタモデルの出力値をユーザーフレンドリーなものに変換するUX部分の記述とテストの単純さの理由から、2つの異なる関数に分けられますフォーマット。
非表示のテキスト
# Author: Andrei Grinenko <andrey.grinenko@gmail.com> # License: BSD 3 clause import os import json import time import urllib.request import urllib.parse import threading import traceback import datetime def get_safe_response_data(url): try: response = urllib.request.urlopen(url, timeout=1) response_data = json.loads(response.read()) return response_data except KeyboardInterrupt: raise except: time.sleep(3) return {} def clear_updates(token, offset): urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates?offset=' + str(offset + 1)) def write_message(message, chat_id, token): if type(message) == str: http_request = to_request(message, chat_id, token) response = urllib.request.urlopen(http_request) # including keyboard, new format elif type(message) == dict: text = message['text'] reply_markup = message['reply_markup'] http_request = to_request(text, chat_id, token, reply_markup) response = urllib.request.urlopen(http_request) # type(mesage) == list else: for str_message in message: write_message(str_message, chat_id, token) def write_log(**kwargs): file_name = kwargs.get('file_name', './data/log.txt') current_datetime = datetime.datetime.now() kwargs.update({'current_datetime': current_datetime}) with open(file_name, 'a') as output_stream: try: output_stream.write(to_beautified_log_line(**kwargs)) except: print(kwargs) print(traceback.print_exc()) output_stream.write(to_simple_log_line(**kwargs)) def to_request(message, chat_id, token, reply_markup={}): message_ = urllib.parse.quote(message) return ('https://api.telegram.org/bot' + token + '/sendmessage?' + 'chat_id=' + str(chat_id) + '&parse_mode=Markdown' + '&text=' + message_ + '&reply_markup=' + json.dumps(reply_markup)) def to_request_old(message, chat_id, token, reply_markup={}): return to_request(message, chat_id, token, reply_markup) def get_last_message_data(token): try: response = urllib.request.urlopen('https://api.telegram.org/bot' + token + '/getupdates') text_response = response.read().decode('utf-8') json_response = json.loads(text_response) return json_response except KeyboardInterrupt: raise except: traceback.print_exc() time.sleep(3) return None def update_data(updates_settings): result = dict() for key in updates_settings['data']: result[key] = updates_settings['data'][key]() return result # Updates cash file with new data just obtained from sources def update_cash_file(new_data, cash_file_name): """ new_data: dict of dicts and values """ if os.path.isfile(cash_file_name): with open(cash_file_name) as input_stream: cash_file_data = json.loads(input_stream.read()) else: cash_file_data = {} for key in new_data: if type(new_data[key]) == dict: if not key in cash_file_data: cash_file_data[key] = dict() for subkey in new_data[key]: cash_file_data[key][subkey] = new_data[key][subkey] else: cash_file_data[key] = new_data[key] with open(cash_file_name, 'w') as output_stream: output_stream.write(json.dumps(cash_file_data)) def to_simple_log_line(**kwargs): channel = kwargs.get('channel', None) chat_id = kwargs.get('chat_id', None) message_text = kwargs['message_text'] username = kwargs.get('username', None) first_name = kwargs.get('first_name', None) last_name = kwargs.get('last_name', None) response = kwargs['response'] current_datetime = kwargs.get('current_datetime', None) datetime_output = (str(current_datetime.year) + '-' + str(current_datetime.month) + '-' + str(current_datetime.day) + '/' + str(current_datetime.hour) + ':' + str(current_datetime.minute)) output_data = {'datetime':datetime_output, 'channel':channel, 'chat_id':chat_id, 'message_text':message_text, 'username':username, 'first_name':first_name, 'last_name':last_name, 'response':response} return str(output_data) + '\n' def to_beautified_log_line(**kwargs): channel = kwargs.get('channel', None) chat_id = kwargs.get('chat_id', None) message_text = kwargs['message_text'] username = kwargs.get('username', None) first_name = kwargs.get('first_name', None) last_name = kwargs.get('last_name', None) response = kwargs['response'] current_datetime = kwargs.get('current_datetime', datetime.datetime(2000, 1, 1, 0, 0)) datetime_output = (str(current_datetime.year) + '-' + str(current_datetime.month) + '-' + str(current_datetime.day) + '/' + str(current_datetime.hour) + ':' + str(current_datetime.minute))# .encode('utf-8') username_data = str(username)# .encode('utf-8') first_name_data = str(first_name)# .encode('utf-8') last_name_data = str(last_name)# .encode('utf-8') response_data = str(response)# .encode('utf-8') output_data = {'datetime':datetime_output, 'channel':str(channel), # .encode('utf-8'), 'chat_id':str(chat_id), 'message_text':message_text, # .encode('utf-8'), 'username':username_data, 'first_name':first_name_data, 'last_name':last_name_data, 'response':response_data} return json.dumps(output_data, ensure_ascii=False) + '\n' def message_to_input(message_data): input_data = dict() try: input_data['message_text'] = message_data['result'][-1]['message']['text'] except: input_data['message_text'] = None try: input_data['update_id'] = message_data['result'][-1]['update_id'] except: input_data['update_id'] = None try: input_data['chat_id'] = message_data['result'][-1]['message']['chat']['id'] except: input_data['chat_id'] = None try: input_data['username'] = message_data['result'][-1]['message']['chat']['username'] except: input_data['username'] = None try: input_data['first_name'] = message_data['result'][-1]['message']['chat']['first_name'] except: input_data['first_name'] = None try: input_data['last_name'] = message_data['result'][-1]['message']['chat']['last_name'] except: input_data['last_name'] = None return input_data def is_update_time(new_datetime, last_update_datetime, updates_settings): if updates_settings['frequency'] == None: return False else: return new_datetime - last_update_datetime > updates_settings['frequency'] def update_data_thread_function(updates_settings, cash_file_name): global updating_data last_update_datetime = datetime.datetime.now() - datetime.timedelta(weeks=10) while True: new_datetime = datetime.datetime.now() if is_update_time(new_datetime, last_update_datetime, updates_settings): print('Updating data at datetime: {}', new_datetime) last_update_datetime = datetime.datetime.now() try: new_data = update_data(updates_settings) if cash_file_name: update_cash_file(new_data, cash_file_name) updating_data = json.load(open(cash_file_name)) else: updating_data = new_data except: traceback.print_exc() time.sleep(3) continue time.sleep(10) def main_loop_webhooks(generate_model_func, generate_response_func, updates_settings={'frequency':None, 'data':{}}, **kwargs): """ updates_settings format: {frequency: datetime.timedelta, data: {first_field: first_function, second_field: second_function, ...}} kwargs: cash_file_name: str, cash file name for cashing updates data, None for no file name """ cash_file_name = kwargs.get('cash_file_name', None) log_file_name = kwargs.get('log_file_name', None) list_of_sources = kwargs['list_of_sources'] # .get('list_of_sources', []) model = generate_model_func() print('Model trained') global updating_data if os.path.isfile(cash_file_name): updating_data = json.load(open(cash_file_name)) else: updating_data = {} update_data_thread = threading.Thread(target=update_data_thread_function, args=(updates_settings, cash_file_name)) update_data_thread.start() current_update_id = 0 activity_status = None last_ping_time = datetime.datetime.now() while True: for source in list_of_sources: current_datetime = datetime.datetime.now() if source['node'] == 'https://api.telegram.org/' and activity_status != 'waiting': try: message_data = get_last_message_data(source['id']['token']) except KeyboardInterrupt: raise except: traceback.print_exc() time.sleep(3) continue input_data = message_to_input(message_data) try: if input_data['update_id'] != None: clear_updates(source['id']['token'], input_data['update_id']) except: traceback.print_exc() if (input_data['update_id'] != None and input_data['message_text'] != None and (current_update_id == None or input_data['update_id'] > current_update_id)): current_update_id = input_data['update_id'] analizing_data = {'message_text':input_data['message_text'], 'username':input_data['username'], 'first_name':input_data['first_name'], 'last_name':input_data['last_name'], 'recipient':{'channel':'telegram', 'token':source['id']['token'], 'chat_id':input_data['chat_id']}} user_id = {'channel':analizing_data['recipient']['channel'], 'chat_id':analizing_data['recipient']['chat_id']} try: response = generate_response_func(input_data['message_text'], model, user_id, updating_data) except: response = u'Sorry, can\'t reply' traceback.print_exc() write_attempts_number = 5 write_attempts_counter = 0 while write_attempts_counter < write_attempts_number: try: write_message(response, analizing_data['recipient']['chat_id'], analizing_data['recipient']['token']) write_attempts_counter = write_attempts_number # Success! except: if write_attempts_counter == 1: traceback.print_exc() write_attempts_counter += 1 time.sleep(3) write_log(file_name=log_file_name, message_text=analizing_data['message_text'], response=response, channel=analizing_data['recipient']['channel'], chat_id=analizing_data['recipient']['chat_id'], username=analizing_data['username'], first_name=analizing_data['first_name'], last_name=analizing_data['last_name']) else: current_time = datetime.datetime.now() if current_time - last_ping_time > datetime.timedelta(seconds=10): last_ping_time = current_time response_data = get_safe_response_data(source['node'] + 'ping' + source['id']['token'] + '/getupdates') if response_data.get('sysmsg') == 'ping': activity_status = response_data.get('status') analizing_data = {'node':source['node'], 'recipient':source['id'], 'ping':True} http_address = (analizing_data['node'] + 'ping' + analizing_data['recipient']['token'] + '/sendmessage') try: urllib.request.urlopen(http_address, timeout=1) except: pass
ライブラリに含まれる関数について簡単に説明します。
main_loop_webhook(generate_model_func, generate_response_func, updates_settings, **kwargs)
ライブラリを使用してスクリプトから呼び出されるメイン関数。 キャッシュファイルをロードし、パラレルストリームでデータを更新する関数を起動し、ポーリングして、Telegramとボットの状態を監視するサービスに応答を送信します。
get_last_message_data(token)
ボットユーザーから最新のメッセージを取得します。
message_to_input(message_data)
受信したメッセージを処理し、さらに処理するのに便利な形式に変換します。
write_message(message, chat_id, token)
Telegramチャットにメッセージを送信する機能。 歴史的な理由から、メッセージキー引数のタイプは、str(単純な単一メッセージの場合)、list(メッセージスレッドの場合)、またはdict(埋め込みキーボードを含むメッセージの場合)になります。
write_log(**kwargs)
ダイアログのログを記録する機能。
to_request(message, chat_id, token, reply_markup)
この関数は、メッセージ、チャット番号、トークン、および応答マークアップ(通常、組み込みキーボードに関する情報を含む)に基づいて、Telegram APIへの要求を生成します。
update_data(updates_settings)
サードパーティのソースからのデータを更新します
update_cash_file(new_data, cash_file_name)
キャッシュファイルの内容を更新します。 次回プログラムを起動するとき(たとえば、クラッシュ後または新しいバージョンをデプロイするとき)に便利です。データサービスは使用できません。
is_update_time(new_datetime, last_update_datetime, updates_settings)
サードパーティAPIからデータを更新するときかどうかを確認します。
update_data_thread_function(updates_settings, cash_file_name)
並列スレッドで実行され、サードパーティのAPIデータを更新する関数。 一部のAPIは数十秒間リクエストに応答でき、その間メインプログラムは一時停止し、ユーザーリクエストに応答しなかったため、マルチスレッドプログラミングの基本を思い出さなければなりませんでした。
このライブラリは主に機械学習アルゴリズムとの相互作用を目的としていますが、その議論はこの記事の範囲をはるかに超えています。 どのように機能するかを示すために、2つの簡単な関数を作成し、それらをサンプルモデルのジェネレーターと出力インタープリターとして使用します。
ライブラリを使用したサンプルスクリプト。
非表示のテキスト
# Author: Andrei Grinenko <andrey.grinenko@gmail.com> # License: BSD 3 clause import sys import datetime import web3 TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI' REGISTER_TOKEN = '12:abcdef' class HelloWorldMetaModel(object): def __init__(self): pass def predict(self, instance): if instance == '/start': return 'start' elif instance in ['hi', 'hello']: return 'hello' elif instance == 'how are you': return 'how_are_you' else: return 'unknown' def generate_meta_model(): return HelloWorldMetaModel() def generate_response(instance, model, user_id, updating_data): current_datetime = updating_data['datetime'] meaning = model.predict(instance) if meaning == 'start': reply = current_datetime + ': ' + 'I am habr example bot' elif meaning == 'hello': reply = current_datetime + ': ' + 'Hello, human!' elif meaning == 'how_are_you': reply = current_datetime + ': ' + 'I\'m fine, thanks!' else: reply = current_datetime + ': ' + 'Don\'t know yet' # TODO Add datetime return reply def update_datetime(): return str(datetime.datetime.now()) if __name__ == '__main__': web3.main_loop_webhooks( generate_model_func=generate_meta_model, generate_response_func=generate_response, updates_settings={'frequency':datetime.timedelta(seconds=5), 'data':{'datetime':update_datetime}}, list_of_sources=[{'node':'https://api.telegram.org/', 'id':{'token':TOKEN}}, # {'node':'http://123.456.78.90/', # 'id':{'token':REGISTER_TOKEN}} ], cash_file_name='./cash_file.txt', log_file_name='./log.txt')
TOKEN = '123456789:abcdefghijklmnopqrstuvwxyzABCDEFGHI'
Telegramでボットを認証するためのトークン。 特定のボット用にBotFatherによって発行されたものに置き換える必要があります。
REGISTER_TOKEN = '12:abcdef'
ボットが実行されていることをスクリプトに警告するトークン。 この関数が不要な場合は、ランダムな文字列に置き換えることができます。
class HelloWorldMetaModel(object)
着信メッセージを処理するためのロジックを担当するクラスの簡単な代替。 いつか複雑なAIが登場しますが、残念ながらまだありません。 少なくともこの記事にはありません。 そして、機械学習アルゴリズムを迅速に記述し、それを本番環境に導入する方法について読みたい場合は、 ここでそれを行うことができます
generate_meta_model()
モデルを生成する関数。
generate_response(instance, model, user_id, updating_data)
モデルを適用した結果に基づいて回答を形成するロジックを担当する関数。 この単純な例では、答えはHelloWorldMetaModelクラスのpredict()関数で指定されたユーザーメッセージの考えられる意味の1つに一意に対応しています。
update_datetime()
外部の変化するデータを引き付ける関数の例。
作業の例(写真はクリック可能):
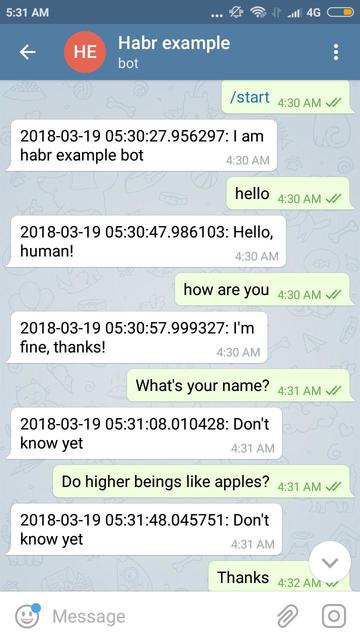
githubのコードはこちらです。
ビットパックのコードはこちらです。
TOKEN定数の値を変更した後、単純に
python3 example.py
を
python3 example.py
するには。
用語集
(トレーニング済み)機械学習モデルは、固定長の数値の配列(数学者の場合はn次元空間の点)を入力として受け取り、クラス識別子(分類問題を解決する場合)または数値(回帰問題を解決する場合)を返す関数です。
[1]メタモデルは、機械学習モデルの概念を一般化したものです。 任意の性質のオブジェクト(たとえば、画像、文字列、ウェブサイトユーザーの説明などをエンコードする配列)を取り、任意の性質のオブジェクト(通常、クラス識別子、番号、辞書、または文字列)を与えるという点で異なります。 抽象化は、通常、前処理、モデルの適用、および後処理を単一のエンティティに含める機械学習パイプラインをカプセル化するのに役立ちます(著者用語)。