与えられた

GISの住宅と共同サービスについては、すでにHabréのLANITグループのブログに詳細な記事がありました。 簡単に言えば、GISの住宅および共同サービスは、ロシアの住宅および共同サービスに関するすべての情報に関する最初の連邦ポータルであり、ほぼすべての地域で開始されています(モスクワ、サンクトペテルブルク、およびセヴァストポリが2019年に参加します)。 過去3か月で、住宅、個人アカウント、支払いの事実など、12 TBを超えるデータがシステムに読み込まれ、全体で24 TBを超えるデータがPostgreSQLに保存されています。
プロジェクトは、アーキテクチャ的にサブシステムに分割されています。 各サブシステムには個別のデータベースがあります。 現在、合計で約60のそのようなデータベースがあり、それらは11の仮想サーバーに配置されています。 一部のサブシステムは他のサブシステムよりも負荷が高く、そのデータベースは3〜6テラバイトの容量を占有できます。
MCC、問題があります
次に、問題についてもう少し説明します。 私は遠くから始めます:アプリケーションコードとデータベース移行コード(移行とは、データベースをあるリビジョンから別のリビジョンに、これに必要なすべてのSQLスクリプトを転送することを意味します)があり、バージョン管理システムに一緒に保存されます。 これはLiquibaseを使用することで可能になります(プロジェクトのLiquibaseの詳細については、LANITのTechGuruDayのMisha Balayanによるレポートに記載されています)。
次に、バージョンのリリースを想像してみましょう。 データが数テラバイト以下で、すべてのテーブルが100ギガバイト以内の場合、データの変更(移行)またはテーブルの構造的な変更は(通常)迅速です。
ここで、すでに数十テラバイトのデータと数テラバイトのテーブルがあり、さらにパーティションが分割されている可能性があることを想像してみましょう。 新しいバージョンでは、これらのテーブルのいずれかに移行する必要があります。さらに悪いことに、一度に移行する必要があります。 同時に、定期的なメンテナンス時間を増やすことはできません。 同時に、テストデータベースで同じ移行を実行する必要があります。テストデータベースでは、鉄が弱くなっています。 同時に、移行にかかる合計時間を事前に把握する必要があります。 これが問題の始まりです。
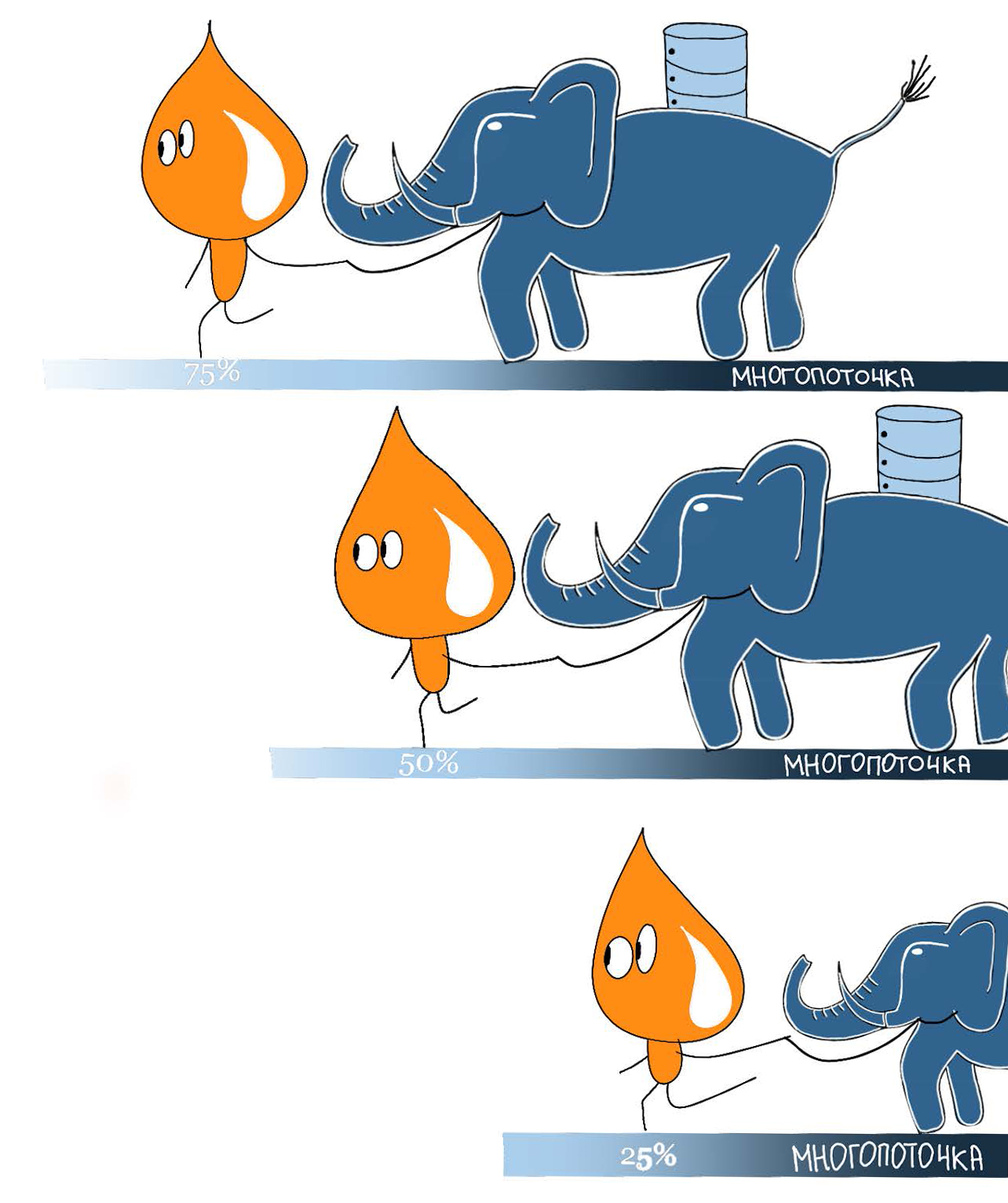
最初に、PostgreSQLの公式ドキュメント(大量移行の前にインデックスとFKを削除する、テーブルを最初から再作成する、コピーを使用する、構成を動的に変更する)のヒントを試しました。 それは効果を与えましたが、私たちはそれをより速く、より便利にしたかったのです(もちろん、ここでの主観的な問題は-それが誰にとって便利かです:–))。 その結果、大量移行の並列実行を実装しました。これにより、多くの場合に速度が向上しました(場合によっては1桁)。 実際にはいくつかのプロセスが並行して実行されていますが、「マルチスレッド」という言葉がチーム内で定着しています。
マルチスレッド

このアプローチの主なアイデアは、大きなテーブルを(たとえば、ntile関数によって)互いに素な範囲に分割し、すべてのデータですぐにではなく、いくつかの範囲で並行してSQLスクリプトを実行することです。 各並列プロセスはそれ自体に対して1つの範囲を取り、それをブロックし、この範囲のデータに対してのみSQLスクリプトの実行を開始します。 スクリプトが完了したら、ブロックされていないまだ処理されていない範囲を再度検索し、操作を繰り返します。 分割する適切なキーを選択することが重要です。 これは、一意の値を持つインデックスフィールドでなければなりません。 そのようなフィールドがない場合は、ctidサービスフィールドを使用できます。
「マルチスレッド」の最初のバージョンは、範囲と次の範囲をとる機能を持つ補助テーブルを使用して実装されました。 必要なSQLスクリプトが匿名関数に置き換えられ、必要なセッション数で起動され、並列実行が提供されました。
コード例
-- UPDATE_INFO_STEPS / -- , / CREATE TABLE UPDATE_INFO_STEPS ( BEGIN_GUID varchar(36), END_GUID varchar(36) NOT NULL, STEP_NO int, STATUS char(1), BEGIN_UPD timestamp, END_UPD timestamp, ROWS_UPDATED int, ROWS_UPDATED_TEXT varchar(30), DISCR varchar(10) ); ALTER TABLE UPDATE_INFO_STEPS ADD PRIMARY KEY(discr, step_no); -- FUNC_UPDATE_INFO_STEPS . -- "" , . CREATE OR REPLACE FUNCTION func_update_info_steps( pStep_no int, pDiscr varchar(10) ) RETURNS text AS $BODY$ DECLARE lResult text; BEGIN SELECT 'SUCCESS' INTO lResult FROM update_info_steps WHERE step_no = pStep_no AND discr = pDiscr AND status = 'N' FOR UPDATE NOWAIT; UPDATE UPDATE_INFO_STEPS SET status = 'A', begin_upd = now() WHERE step_no = pStep_no AND discr = pDiscr AND status = 'N'; return lResult; EXCEPTION WHEN lock_not_available THEN SELECT 'ERROR' INTO lResult; return lResult; END; $BODY$ LANGUAGE PLPGSQL VOLATILE; -- (1 1 ) -- 1. . DO LANGUAGE PLPGSQL $$ DECLARE -- l_count int := 10000; -- l_discr VARCHAR(10) := '<discr>'; BEGIN INSERT INTO UPDATE_INFO_STEPS ( BEGIN_GUID, END_GUID, STEP_NO, STATUS, DISCR ) SELECT min(guid) BEGIN_GUID, max(guid) END_GUID, RES2.STEP STEP_NO, 'N' :: char(1) STATUS, l_discr DISCR FROM ( SELECT guid, floor( (ROWNUM - 1) / l_count ) + 1 AS STEP FROM ( -- SELECT <column> AS GUID, -- row_number() over ( ORDER BY <column> ) AS ROWNUM FROM -- <schema>.<table_name> ORDER BY 1 -- ) RES1 ) RES2 GROUP BY RES2.step; END; $$; -- 2. , UPDATE. DO LANGUAGE PLPGSQL $$ DECLARE cur record; vCount int; vCount_text varchar(30); vCurStatus char(1); vCurUpdDate date; -- l_discr varchar(10) := '<discr>'; l_upd_res varchar(100); BEGIN FOR cur IN ( SELECT * FROM UPDATE_INFO_STEPS WHERE status = 'N' AND DISCR = l_discr ORDER BY step_no ) LOOP vCount := 0; -- ! SELECT result INTO l_upd_res FROM dblink( '<parameters>', 'SELECT FUNC_UPDATE_INFO_STEPS(' || cur.step_no || ',''' || l_discr || ''')' ) AS T (result text); IF l_upd_res = 'SUCCESS' THEN -- . -- , . -- - -- cur.begin_guid - cur.end_guid dblink " ". -- . SELECT dblink( '<parameters>', 'UPDATE FOO set level = 42 WHERE id BETWEEN ''' || cur.begin_guid || ''' AND ''' || cur.end_guid || '''' ) INTO vCount_text; -- . SELECT dblink( '<parameters>', 'update UPDATE_INFO_STEPS SET status = ''P'', end_upd = now(), rows_updated_text = ''' || vCount_text || ''' WHERE step_no = ' || cur.step_no || ' AND discr = ''' || l_discr || '''' ) INTO l_upd_res; END IF; END LOOP; END; $$; -- . SELECT SUM(CASE status WHEN 'P' THEN 1 ELSE 0 END) done, SUM(CASE status WHEN 'A' THEN 1 ELSE 0 END) processing, SUM(CASE status WHEN 'N' THEN 1 ELSE 0 END) LEFT_, round( SUM(CASE status WHEN 'P' THEN 1 ELSE 0 END):: numeric / COUNT(*)* 100 :: numeric, 2 ) done_proc FROM UPDATE_INFO_STEPS WHERE discr = '<discr>';
このアプローチはすぐに機能しましたが、非常に多くの手動アクションが必要でした。 そして、午前3時に展開が行われた場合、DBAはLiquibaseの「マルチスレッド」スクリプトの実行の瞬間(実際には1つのプロセスで実行された)を捕らえ、それをさらに高速化するためにいくつかのプロセスを手で開始する必要がありました。
「MnGOpostok 2.0」
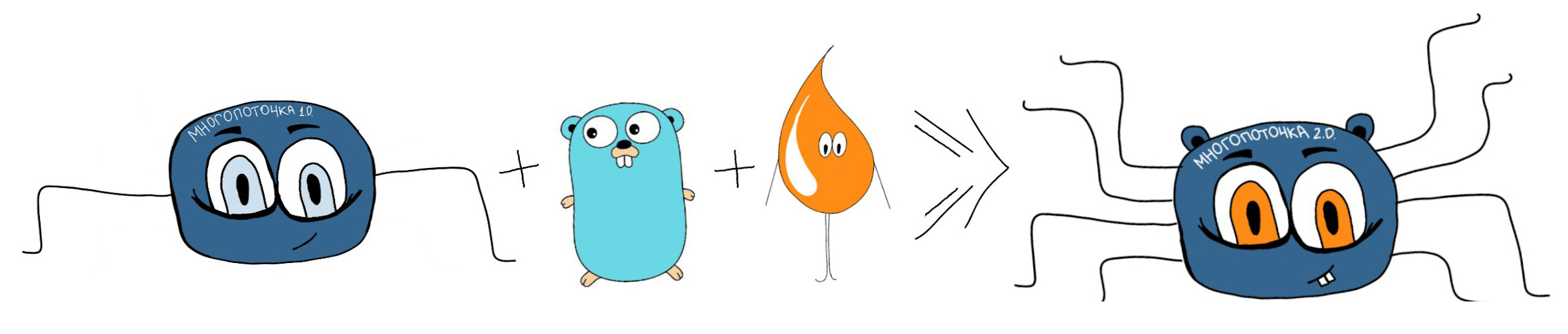
「マルチスレッド」の以前のバージョンは、使用するには不便でした。 そのため、Goでプロセスを自動化するアプリケーションを作成しました(たとえば、Pythonや他の多くの言語でも実行できます)。
まず、可変テーブルのデータを範囲に分割します。 その後、スクリプトに関する情報を補助タスクテーブルに追加します-その名前(一意の識別子、たとえばJiraのタスクの名前)および同時に起動されたプロセスの数。 次に、スクリプトの補助テーブルに、範囲に分割されたSQL移行テキストを追加します。
コード例
-- , -- (pg_parallel_task) -- (pg_parallel_task_statements). CREATE TABLE IF NOT EXISTS public.pg_parallel_task ( name text primary key, threads_count int not null DEFAULT 10, comment text ); COMMENT ON table public.pg_parallel_task IS ' '; COMMENT ON COLUMN public.pg_parallel_task.name IS ' '; COMMENT ON COLUMN public.pg_parallel_task.threads_count IS ' . 10'; COMMENT ON COLUMN public.pg_parallel_task.comment IS ''; CREATE TABLE IF NOT EXISTS public.pg_parallel_task_statements ( statement_id bigserial primary key, task_name text not null references public.pg_parallel_task (name), sql_statement text not null, status text not null check ( status in ( 'new', 'in progress', 'ok', 'error' ) ) DEFAULT 'new', start_time timestamp without time zone, elapsed_sec float(8), rows_affected bigint, err text ); COMMENT ON table public.pg_parallel_task_statements IS ' '; COMMENT ON COLUMN public.pg_parallel_task_statements.sql_statement IS ' '; COMMENT ON COLUMN public.pg_parallel_task_statements.status IS ' . new|in progress|ok|error'; COMMENT ON COLUMN public.pg_parallel_task_statements.start_time IS ' '; COMMENT ON COLUMN public.pg_parallel_task_statements.elapsed_sec IS ' , '; COMMENT ON COLUMN public.pg_parallel_task_statements.rows_affected IS ' , '; COMMENT ON COLUMN public.pg_parallel_task_statements.err IS ' , . NULL, .'; -- INSERT INTO PUBLIC.pg_parallel_task (NAME, threads_count) VALUES ('JIRA-001', 10); INSERT INTO PUBLIC.pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-001' task_name, FORMAT( 'UPDATE FOO SET level = 42 where id >= ''%s'' and id <= ''%s''', MIN(d.id), MAX(d.id) ) sql_statement FROM ( SELECT id, NTILE(10) OVER ( ORDER BY id ) part FROM foo ) d GROUP BY d.part; --
デプロイすると、Goでアプリケーションが呼び出されます。このアプリケーションは、補助テーブルからこのタスクのタスク構成とスクリプトを読み取り、指定された数の並列プロセス(ワーカー)でスクリプトを自動的に実行します。 実行後、制御はLiquibaseに戻されます。
コード
<changeSet id="JIRA-001" author="soldatov"> <executeCommand os="Linux, Mac OS X" executable="./pgpar.sh"> <arg value="testdatabase"/><arg value="JIRA-001"/> </executeCommand> </changeSet>
アプリケーションは、3つの主要な抽象化で構成されています。
- タスク-移行パラメーター、プロセス数、およびすべての範囲をメモリにロードし、マルチスレッドを開始し、進行状況を追跡するためにWebサーバーを起動します。
- statement-実行される操作の1つの範囲を表します。範囲の実行ステータスの変更、範囲の実行時間、範囲内の行数などの記録も行います。
- worker-実行の単一スレッドを表します。
task.doメソッドでは、操作のすべてのステートメントが送信されるチャネルが作成されます。 このチャネルは、指定された数のワーカーを実行します。 ワーカー内で無限ループが発生し、2つのチャネルで多重化されます。ステートメントを受信して実行し、シグナルデバイスとして空のチャネルを使用します。 何を完了する必要があります。 空のチャネルが閉じられるとすぐに、ワーカーはシャットダウンします。これは、ワーカーの1つでエラーが発生すると発生します。 なぜなら Goのチャネルはスレッドで安全な構造なので、1つのチャネルを閉じることで、すべてのワーカーを一度にキャンセルできます。 チャネル内のステートメントが終了すると、ワーカーは単にループを終了し、すべてのワーカーの合計カウンターを減らします。 タスクは常に作業するワーカーの数を知っているため、このカウンターがゼロにリセットされるのを待ってから終了します。
パン
この「マルチスレッド」の実装により、いくつかの興味深い機能が登場しました。
- Liquibaseとの統合(executeCommandタグを使用して呼び出されます)。
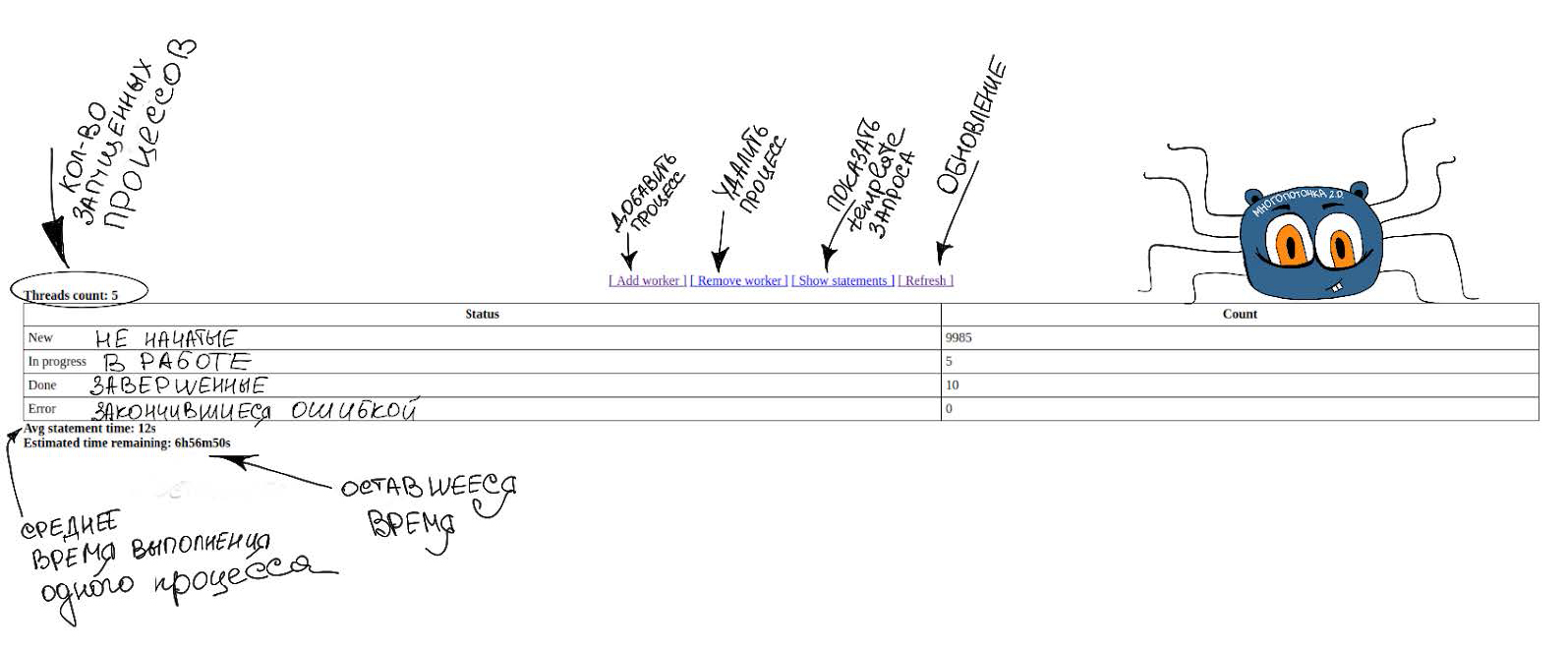
- 「マルチスレッド」を開始すると表示される単純なWebインターフェイス。その実装の進行状況に関するすべての情報が含まれます。
- 進行状況バー(1つの範囲が処理されている数、実行中の並列プロセスの数、およびまだ処理されていない範囲の数がわかっているため、完了時間を計算できます)。
- 並列プロセスの動的な変更(これは手作業で行っていますが、将来は自動化したい)。
- さらに分析できるように、マルチスレッドスクリプトの実行中に情報を記録します。
- 更新などのブロック操作を実行して、ほとんど何もブロックしません(プレートを非常に小さな範囲に分割すると、すべてのスクリプトがほぼ瞬時に実行されます)。
- データベースから直接「マルチスレッド」を呼び出すためのラッパーがあります。
良いものではない
主な欠点は、テキストフィールド、日付、またはUIDがキーとして使用される場合、プレート上で一度フルスキャンを実行して範囲に分割する必要があることです。 連続して増加する密な値を持つフィールドがパーティション化のキーとして選択されている場合、そのような問題はありません(必要なステップを設定するだけで、すべての範囲を事前に指定できます)。
7倍のスピードアップ(pgbenchテーブルでテスト)

最後に、マルチスレッドを使用しない場合と使用する場合の500,000,000行のUPDATE操作の速度を比較する例を示します。 Simple UPDATEの完了には49分かかりましたが、マルチスレッドは7分で完了しました。
コード例
SELECT count(1) FROM pgbench_accounts; count ------- 500000000 (1 row) SELECT pg_size_pretty(pg_total_relation_size('pgbench_accounts')); pg_size_pretty ---------------- 62 Gb (1 row) UPDATE pgbench_accounts SET abalance = 42; -- 49 vacuum full analyze verbose pgbench_accounts; INSERT INTO public.pg_parallel_tASk (name, threads_count) values ('JIRA-002', 25); INSERT INTO public.pg_parallel_tASk_statements (tASk_name, sql_statement) SELECT 'JIRA-002' tASk_name, FORMAT('UPDATE pgbench_accounts SET abalance = 42 WHERE aid >= ''%s'' AND aid <= ''%s'';', MIN(d.aid), MAX(d.aid)) sql_statement FROM (SELECT aid, ntile(25) over (order by aid) part FROM pgbench_accounts) d GROUP BY d.part; -- 10 -- ctid, INSERT INTO public.pg_parallel_tASk_statements (tASk_name, sql_statement) SELECT 'JIRA-002-ctid' tASk_name, FORMAT('UPDATE pgbench_accounts SET abalance = 45 WHERE (ctid::text::point)[0]::text > ''%s'' AND (ctid::text::point)[0]::text <= ''%s'';', (d.min_ctid), (d.max_ctid)) sql_statement FROM ( WITH max_ctid AS ( SELECT MAX((ctid::text::point)[0]::int) FROM pgbench_accounts) SELECT generate_series - (SELECT max / 25 FROM max_ctid) AS min_ctid, generate_series AS max_ctid FROM generate_series((SELECT max / 25 FROM max_ctid), (SELECT max FROM max_ctid), (SELECT max / 25 FROM max_ctid))) d; -- 9 ./pgpar-linux-amd64 jdbc:postgresql://localhost:5432 soldatov password testdatabase JIRA-002 -- 7
PS次の場合に必要ですか?

すべてのツールは特定のタスクに適していますが、ここではマルチスレッド用のツールをいくつか紹介します。
- UPDATEテーブル> 100,000行。
- 並列化できる複雑なロジックを使用した更新(たとえば、関数を呼び出して何かを計算する)。
- ロックなしの更新。 非常に小さな範囲に粉砕し、少数のプロセスを開始することにより、各範囲の即時処理を実現できます。 したがって、ロックもほぼ瞬時に行われます。
- Liquibase(例:VACUUM)でchangeSetsを並行して実行します。
- テーブル内の新しいフィールドのデータの作成と入力。
- 複雑なレポート。
ほぼ非ブロッキングの更新(それぞれ10,000行の50,000範囲)
<changeSet author="soldatov" id="JIRA-002-01"> <sql> <![CDATA[ INSERT INTO public.pg_parallel_task (name, threads_count) VALUES ('JIRA-002', 5); INSERT INTO public.pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-002' task_name, FORMAT( 'UPDATE pgbench_accounts SET abalance = 42 WHERE filler IS NULL AND aid >= ''%s'' AND aid <= ''%s'';', MIN(d.aid), MAX(d.aid) ) sql_statement FROM ( SELECT aid, ntile(10000) over ( order by aid ) part FROM pgbench_accounts WHERE filler IS NULL ) d GROUP BY d.part; ]]> </sql> </changeSet> <changeSet author="soldatov" id="JIRA-002-02"> <executeCommand os="Linux, Mac OS X" executable="./pgpar.sh"> <arg value="pgconfdb"/><arg value="JIRA-002"/> </executeCommand> </changeSet>
Liquibaseの並行変更セット
<changeSet author="soldatov" id="JIRA-003-01"> <sql> <![CDATA[ INSERT INTO pg_parallel_task (name, threads_count) VALUES ('JIRA-003', 2); INSERT INTO pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-003' task_name, 'VACUUM FULL ANALYZE pgbench_accounts;' sql_statement; INSERT INTO pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-003' task_name, 'VACUUM FULL ANALYZE pgbench_branches;' sql_statement; ]]> </sql> </changeSet> <changeSet author="soldatov" id="JIRA-003-02"> <executeCommand os="Linux, Mac OS X" executable="./pgpar.sh"> <arg value="testdatabase"/><arg value="JIRA-003"/> </executeCommand> </changeSet>
データベースから「マルチスレッド」機能を呼び出して、テーブルの新しいフィールドにデータ(各10,000行の50,000の範囲)をほぼノンブロッキングで埋める
-- SQL part ALTER TABLE pgbench_accounts ADD COLUMN account_number text; INSERT INTO public.pg_parallel_task (name, threads_count) VALUES ('JIRA-004', 5); INSERT INTO public.pg_parallel_task_statements (task_name, sql_statement) SELECT 'JIRA-004' task_name, FORMAT('UPDATE pgbench_accounts SET account_number = aid::text || filler WHERE aid >= ''%s'' AND aid <= ''%s'';', MIN(d.aid), MAX(d.aid)) sql_statement FROM (SELECT aid, ntile(50000) over (order by device_version_guid) part FROM pgbench_accounts) d GROUP BY d.part; SELECT * FROM func_run_parallel_task('testdatabase','JIRA-004');
ところで、欠員があります