-私はトロント大学のいくつかのグループのメンバーです。 それらの1つは、コンピューターシステムとネットワークグループです。 私自身のグループ、EcoSystem Groupもあります。 グループの名前が示すように、私は機械学習の専門家ではありません。 しかし、ニューラルネットワークは現在非常に人気があり、コンピューターアーキテクチャとネットワーク、コンピューターシステムを扱う人々は、これらのアプリケーションを継続的に扱う必要があります。 したがって、私はこの1年半から2年間、このトピックで忙しくしています。
メモリ、プロセッサキャッシュで適切に圧縮する方法を説明します。 それがカーネギーメロンでのアメリカの博士論文のテーマでした。 これは、ニューラルネットワークなどの他のアプリケーションに同様のメカニズムを適用したいときに遭遇した問題を理解するのに役立ちます。
コンピューターアーキテクチャの主な問題の1つは、優れたエネルギー効率パラメーターを備えた高性能システム(グラフィックカード、コプロセッサー、電話、ラップトップ)を取得することです。
現時点では、メモリに制限しない限り、かなり高いパフォーマンスを簡単に得ることができます。 必要に応じて、エキソフロップコンピューターを入手できます。 問題は、これにどのくらいの電気を費やす必要があるかです。 したがって、主な問題の1つは、使用可能なリソースで良好なパフォーマンス結果を得ることと同時に、エネルギー効率のバランスを崩さないことです。
エネルギー効率化への道の主な問題の1つは、クラウドコンピューティングやさまざまなモバイルデバイスで使用される多くの重要なアプリケーションに、転送とストレージの両方の重大なデータコストがあることです。 これらは、最新のデータベース、グラフィックカード、そしてもちろん機械学習です。 これには、カーネルからネットワークリソースまで、スタックのすべてのレベルの非常に深刻なリソースが必要です。
さまざまな最適化を実行する必要がある場合に発生する重要な問題の1つを次に示します。実際には、あるタイプのリソースを別のタイプに置き換えることができます。 これまで、コンピューターアーキテクチャでは、加算、乗算、算術演算などのコンピューティングリソース自体が非常に高価でした。 ただし、この状況は近年変化しており、これは、プロセッサコアの開発がメモリへのアクセス速度よりもはるかに速く進んだためです。

その結果、エネルギーに関する加算の1つの算術演算では、約1ピコジュールのコストがかかります。 この場合、浮動小数点を使用する1つの操作である浮動小数点には、約20ピコジュールのコストがかかります。 メモリから4または8バイトを読み取りたい場合、少なくとも2桁以上のエネルギーを消費します。 そして、これは重大な問題です。 メモリを操作しようとすると、かなり費用がかかります。 また、どのデバイスについて話しているかは関係ありません。 状況は、携帯電話でも、大規模なクラスターやスーパーコンピューターでも同じです。
これから、現在の携帯電話でさえエネルギー資源に十分に使用できない非常に多くの資源が続くことになります。 最新の携帯電話を使用する場合、AndroidでもiPhoneでも、ピーク時のメモリとコア間の利用可能な帯域幅は約50%しか使用できません。 これを行わないと、電話が過熱するか、誰も過熱させません。メモリとコア間の通信中にバス周波数が低下し、パフォーマンスも低下します。
トリッキーな最適化が適用されない限り、多くのリソースは現在使用できません。
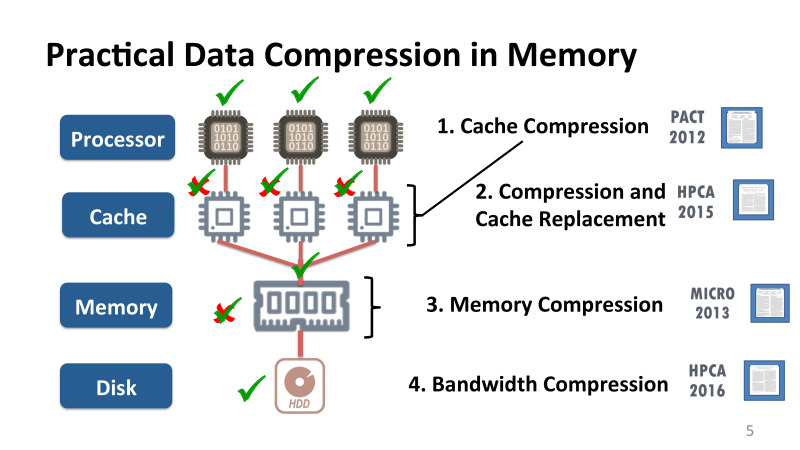
さまざまなレベルでさまざまなリソースの不足に対処する1つの方法は、データを圧縮することです。 これは新しい最適化ではなく、ネットワークとドライブの両方に正常に適用されており、さまざまなユーティリティを使用しています。 Linuxでは、多くがgzipまたはBZip2ユーティリティを使用したとしましょう。 これらのユーティリティはすべて、このレベルで非常にうまく適用されています。 通常、アルゴリズムはハフマンエンコーディングまたはLempel-Zivに基づいて適用されます。
これらのアルゴリズムはすべて、通常、大量の語彙を必要とします。問題は、アルゴリズムが非常に一貫性があり、現代のアーキテクチャにあまり適合せず、非常に並行していることです。 既存のハードウェアを見ると、少なくとも5年前の最初の作業の一部までは、メモリ、キャッシュ、またはプロセッサレベルでの圧縮は実際には使用されていませんでした。
これが起こった理由と、圧縮がさまざまなレベルで利用できるようにするために何ができるか、つまり、キャッシュで直接圧縮する方法について説明します。 キャッシュ圧縮-圧縮がハードウェアで直接行われることを意味します。つまり、プロセッサキャッシュ自体のロジックの一部が変更されます。 このボーナスのボーナスについて簡単に説明します。 メモリ内の圧縮、どのような問題があるかについて説明します。 これはまったく同じことのようですが、メモリに効果的に圧縮を実装することは完全に異なり、キャッシュとは異なります。 NVidiaとの連携について説明します。NVidiaでは、最新のGPU向けの実際のハードウェアで帯域幅圧縮を行い、最適化は最新世代のGPUカードであるVoltで行われました。 そして、圧縮データをまったく解凍せずに直接実行する場合の完全に根本的な最適化について説明します。
キャッシュの圧縮に関するいくつかの言葉。 これは2012年のPACT会議での記事であり、その作業はIntelと共同で行われました。 2 MBまたは4 MBのプロセッサキャッシュを4 MBまたは8 MBに変更する場合、主な問題が何であるかを明確にするため。 あなたはL圧縮をしましたが、問題は何ですか?
大まかに言うと、メモリアクセス操作がある場合、x86アーキテクチャについて話している場合、メモリにロードまたはストアし、レジスタにデータがない場合は、1次キャッシュに移動します。 通常、これらは最新のプロセッサでは3または4クロックサイクルです。 データがある場合は、CPUに戻ります。 存在しない場合、メモリリクエストは階層をさらに進み、L2キャッシュに到達します。
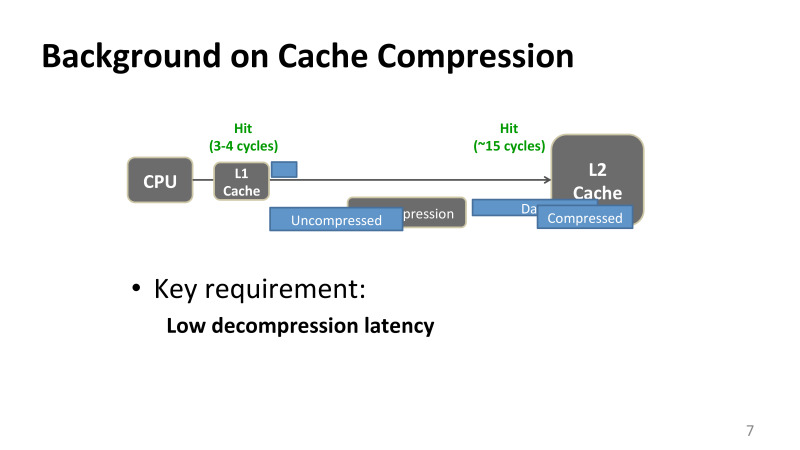
ほとんどのIntelプロセッサのL2キャッシュには、キャッシュのサイズに応じて15〜20クロックサイクルがあります。 そして、メモリに行かなかった場合、データは通常、L2キャッシュで見つかった場合に戻ります。 データはすぐにプロセッサに送られ、L1キャッシュに保存されます。突然このデータを再利用し続けてプロセッサに近づくと、データは保存されます。
問題は、データが圧縮されている場合、圧縮プロセスを最適化する方法は問題ではなく、解凍は常にクリティカルスタートパス上にあるということです。 2次キャッシュへの以前のアクセスに15サイクルかかった場合、圧縮解除に関連する遅延はリクエストの遅延に追加されます。 また、この制限は、メモリ内と、ニューラルネットワークのトレーニングなどの実際のアプリケーションに適用する場合の両方で、ほとんどすべての圧縮アプリケーションに当てはまります。解凍は常にクリティカルパス上にあり、その遅延、実行にかかる時間は非常に重要です。
これは私たちにとって何を意味するのでしょうか? キャッシュレイテンシが15サイクルのレベルであることを理解している場合は、解凍を非常に最適化する必要があります。 わずか数プロセッササイクルで十分です。 それがどれほど小さいかを理解するために、1つのプラス記号は約2つの措置を取ります。 つまり、非常に複雑なことはできません。
これが主な理由で、Intelはある時点でキャッシュ圧縮の開発を停止しました。 彼らはそこで働いたグループ全体を持っていて、2005-2006年に彼らは約5サイクルを解凍するアルゴリズムを開発しました。 この遅延は約30%増加しましたが、キャッシュはほぼ2倍になりました。 ただし、設計者はほとんどのアプリケーションを見て、高価すぎると言いました。
私が2011年にこのトピックに取り組み始めたとき、彼らはあなたが1-2ステップで何かをすることができれば、これを試すために実際のハードウェアで行うことができると言いました。
さまざまなアルゴリズムを試しましたが、すでに文献で利用可能なアルゴリズムを使用できなかった理由の1つは、それらがすべてソフトウェアで作成されていたことです。 ソフトウェアには他の制限があり、人々はさまざまな辞書などを使用します。 これらの手法を実際のハードウェアで作成しようとすると、動作が非常に遅くなります。 IBMは、Lempel-Zivアルゴリズムをgzipと完全に同じにし、完全にハードウェアにしました。解凍には64サイクルかかりました。 キャッシュではこれを使用せず、メモリ内でのみ使用することは明らかです。
私は戦略を変えようとしました。 ソフトウェアアルゴリズムを最適化しようとする代わりに、キャッシュに保存されている実際のデータを確認し、このデータに適したアルゴリズムを作成することにしました。

逆説的に、20%から30%まで多くのゼロがあることがわかりました。 Intelのアプリケーションの大きなパッケージを使用する場合、計算に使用する200の異なるアプリケーションがあります-多くのゼロ。 これは初期化であり、多数のゼロを持つ行列であり、これらはヌルポインターです。 これには多くの理由があります。
多くの場合、値が重複しています。 キャッシュ内の小さなメモリ領域で非常に小さな値を繰り返すことができます。 これは、たとえば、グラフィックスを使用している場合、ピクセルの束があり、同じ色の画像の一部がある場合、行のすべてのピクセルは同じになります。 また、ナロー値は、2バイト、4バイト、および8バイトに格納されるシングルバイトおよびダブルバイトの値です。 なぜこれが起こっているのですか?これは誰の間違いですか? そのような冗長性はどこから来るのでしょうか?
冗長性は、コードのプログラミング方法に関連しています。 C ++など、ある種の言語を使用します。 たとえば、配列全体などのオブジェクトにメモリを割り当てたい場合、配列内のいくつかのイベントに関する統計情報を保存するとします。これらのイベントは非常に頻繁に発生する可能性があります。 たとえば、特定の命令を使用したメモリアクセス。 ほとんどの命令はアクセスされませんが、起動中に何十億回もアクセスされる命令もあります。
プログラマは、最悪の場合、整数値が大きな値をとることがあるため、8バイトの数値の配列を割り当てる必要があります。 ただし、これは冗長です。 これらの値の多くは実際には必要ではなく、不完全なゼロがたくさんありますが、先行ゼロの一部が先にあります。
さらに、さまざまなタイプの冗長性を持つ他の多くの値があります。 たとえば、ポインター。 一度コードをデバッグしてポインターを見た人は、それらが非常に大きく変化していることに気付くでしょう。 ただし、ほぼ同じメモリ領域を持つポインターがある場合、ほとんどのビットは同じになります。 このタイプの冗長性も明らかです。
私は多くの種類の冗長性を見ました。 最初の質問は、いくつあるかということです。
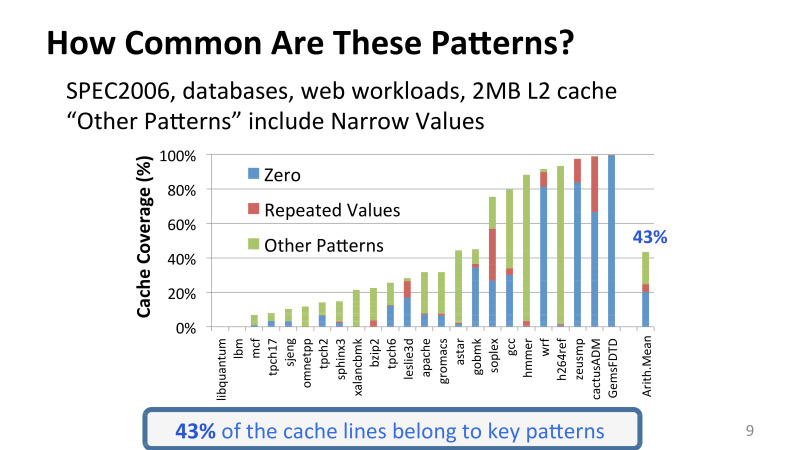
これは、2次キャッシュから定期的にデータを取得し、このキャッシュのスナップショットを保存して、ゼロがいくつあるかを調べて、値が繰り返される実験です。 X軸では、コンピューターアーキテクチャで積極的に使用されているSPEC2006パッケージのさまざまなアプリケーションと、Intelの他のさまざまなアプリケーションの両方が、データベースとApachiサーバーなどのさまざまなWebワークフローの両方です。 そして、これは2メガバイトのL2キャッシュであるという仮定です。
異なるアプリケーションの冗長性には大きなばらつきがあることに気づくかもしれませんが、これらの非常に単純なパターンでさえ非常に一般的です。 すべてのキャッシュラインの43%、キャッシュに格納されているすべてのデータをカバーするのはそれらだけです。
これらのパターンと他のパターンをカバーし、優れた圧縮パフォーマンスを提供する十分にシンプルなものを考え出すことができます。
しかし、問題はこれらのパターンを何が関連させるのか? これらのパターンのそれぞれに特に機能する何らかの種類の圧縮アルゴリズムを作成する必要がありますか、それとも共通点がありますか?
観察の考え方は一般的でした。 これらの値はすべて、大きい場合も小さい場合もありますが、両者の違いはほとんどありません。 大まかに言って、特定の各キャッシュラインの値のダイナミックレンジは非常に小さいです。 また、キャッシュに格納されている値を想像できます。たとえば、32バイトのキャッシュラインは、Base + Delta Encodingを使用して簡単に表すことができます。
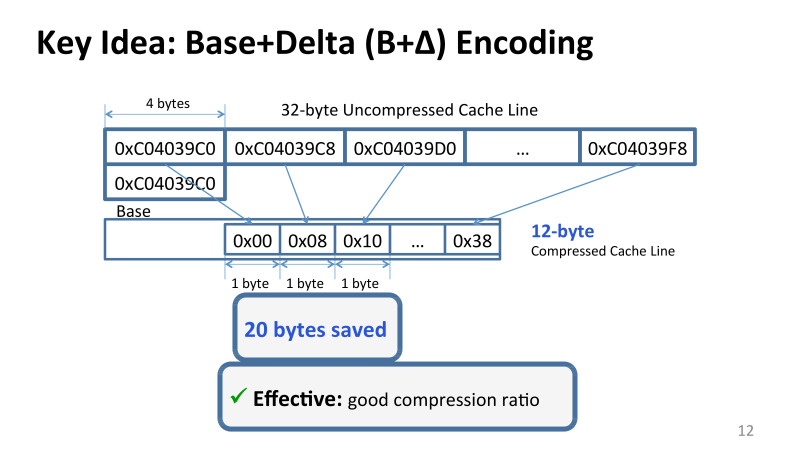
たとえば、最初の値をベースとし、他のすべてをこのベースからのオフセットとして提示します。 また、ほとんどの場合、互いの値はそれほど変わらないため、デルタは1バイトに配置され、32または64バイトではなく、12バイトだけで十分であり、約20バイトのスペースを節約できます。
これを実際のハードウェアに実装する方法の詳細については説明しません。 実際のプロトタイプを作成し、Verilogでプロトタイプを作成し、最新のFPGAでプロトタイプを作成し、実装についてIntelと話しました。 このアイデアに基づいてアルゴリズムを作成することができます。これは、解凍に1つまたは2つのクロックサイクルのみを必要とします。 このアルゴリズムは適用可能であり、良好な圧縮を提供します...
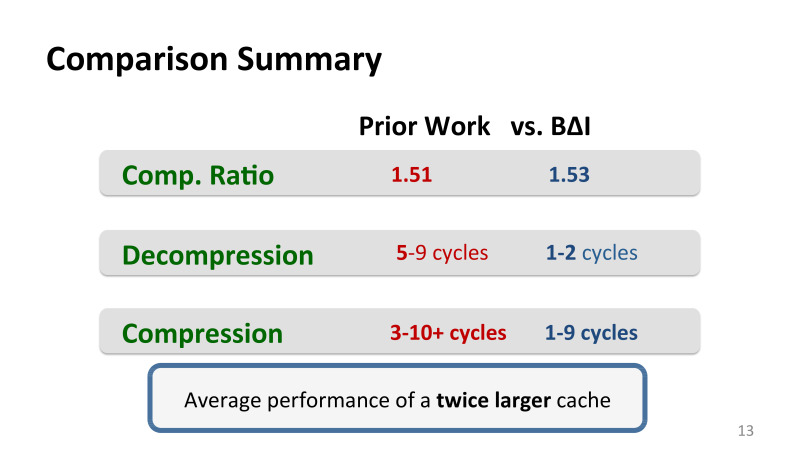
キャッシュで使用された最高の以前の作品は、追加スペースの約50%を提供しました。 これは純粋な圧縮ではありません-はるかに多くを与えることができます-これは効果的な圧縮の本当のボーナスです。つまり、ユーザーにとってキャッシュがどれだけ見えるかです。 断片化など、あらゆる種類の問題に対処する必要があります。
インテルが持っていた最高の以前のメカニズムのレベルで圧縮が行われていますが、スライドの途中での主な利点は圧縮解除です。 以前のアルゴリズムでは、最高の圧縮解除は5〜9サイクルでした。 圧縮は非常に効果的ですが、1〜2サイクルで実行できました。
この種のアルゴリズムは、実際のハードウェアで実行し、メモリなどのキャッシュで使用できます。
このような最適化をキャッシュに適用すると、キャッシュはユーザーにとってほぼ2倍の効果があるように見えることが多くなります。 これはどういう意味ですか? 最新のプロセッサを写真で見ると、コア自体はほとんどありません。 プロセッサキャッシュはそこの大部分を占めています。IBMとIntelの両方にとって40〜50%は簡単です。 実際、Intelは単にキャッシュを取得して2倍にすることはできません。単にキャッシュを追加する余地はありません。 そして、カーネル自体の数パーセントのコストしかかからないこのような最適化は、もちろん非常に興味深いものです。
2番目の作業ではさまざまな最適化を行いましたが、今日は説明しませんが、キャッシュラインのサイズを変更できるようになりました。 これらの問題はすべて正常に解決されました。
Intelでも行われた3番目の作業、メモリの圧縮方法についてお話したいと思います。
そこでの問題は何ですか?
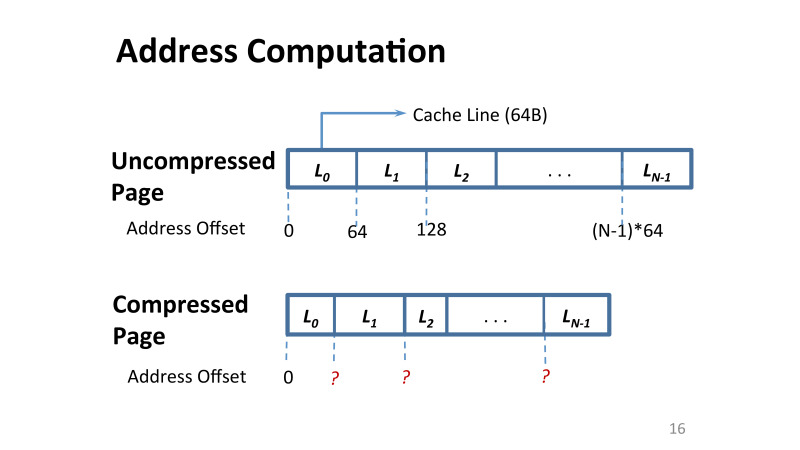
主な問題は、LinuxまたはWindowsに4 KBのメモリページがある場合、それを圧縮するために次の問題を解決する必要があることです。このページのデータアドレスがどのように変化するかという問題を解決する必要があります。 最初は4 KBで、その中の各キャッシュラインも64バイトです。 また、このメモリページ内のキャッシュラインのオフセットを見つけるのは簡単です。64を取り、必要なオフセットを掛けます。
ただし、圧縮を適用すると、各行のサイズが異なる可能性があります。 キャッシュのメモリからページを読み込む必要がある場合、これらのオフセットはありません。
どこかに保存できると言えます。 そして、それらをどこに保存しますか? 再びメモリまたはキャッシュに保存します。 ただし、各メモリのすべてのオフセットを保存する場合、キャッシュはありません。すべてのメモリを処理するには、数百MBのリソースが必要です。 このデータをチップに保存することはできませんが、すべてのメモリアクセスには複数のメモリアクセスがあるため、メモリに保存することは望ましくありません。 最初にメタデータを取得し、次に実際のデータを取得します。
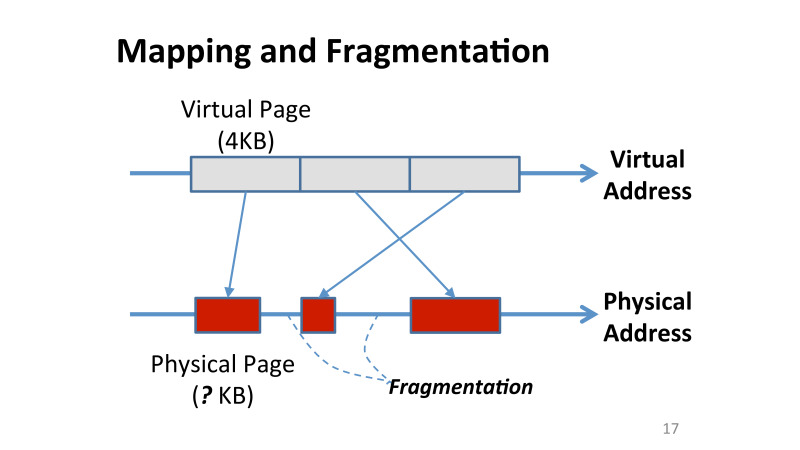
OSでの作業中に誰もが遭遇した2番目の問題は、データの断片化でした。 ここでは、各ページのメモリ内の場所も異なるため、非常に困難になります。 さらに、仮想アドレス空間では、すべてのページが4 KBのままですが、圧縮後、それらはすべて完全に異なるサイズを占有します。 そして、これは問題です。この空の場所をどのように使用できるのでしょうか。 OSは、ページを小さくすることを許可したことを認識していません。断片化されたこれらの断片は表示されません。 そのように、何も変更しない限り、圧縮ボーナスは得られません。
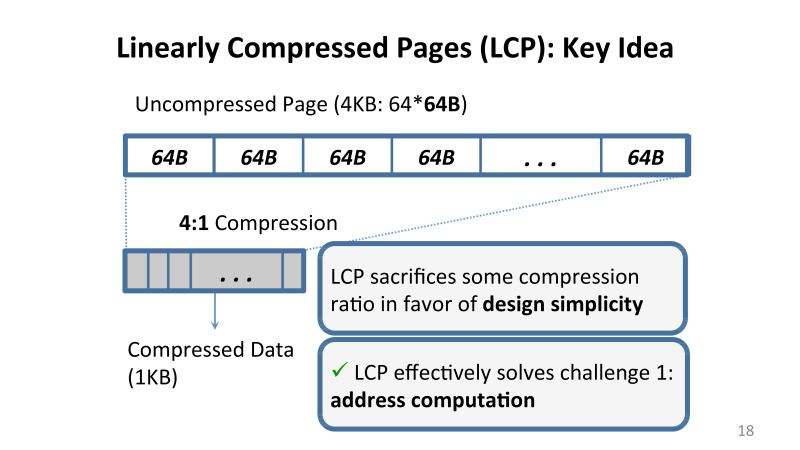
この問題を解決するために何を提案しましたか? 線形係数を使用した圧縮。 記事で詳しく説明されている一連の制限を課しましたが、ポイントは、メモリに圧縮を適用する場合、このページの各キャッシュラインが特定の係数で圧縮されることを保証するアルゴリズムを使用することです4対1、3対1、またはまったく圧縮しません。
追加の制限を課すため、データ圧縮の面で何かを失う可能性がありますが、主なボーナスは、設計が非常に単純であり、実装できることです。これは、たとえばLinuxで成功しました。
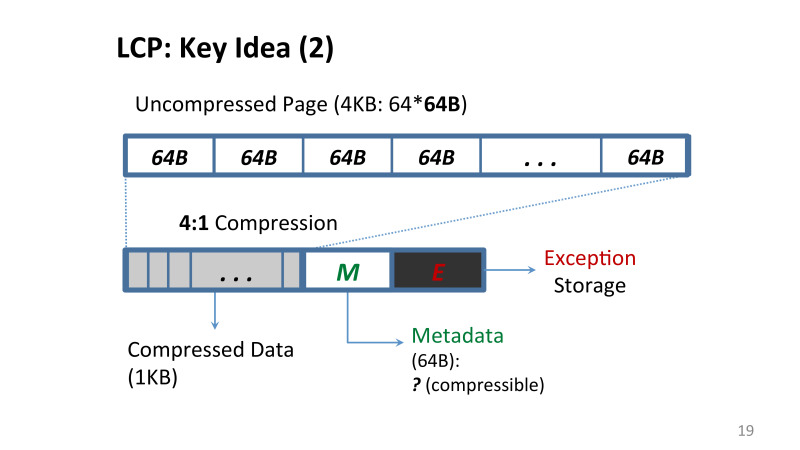
私たちが提案した手法である線形圧縮ページ(LCP)は、すべてのデータのアドレスが非常に単純であるという主な問題に対処します。 同じページに格納される小さなメタデータブロックがあり、圧縮された形式で格納される元のデータ、またはいわゆる例外ストレージと呼ばれるキャッシュラインが格納されますが、この方法では圧縮できません。
これらのアイデアに基づいて、我々は優れたデータ圧縮を得ることができました。最も重要なことは、主にIBMが行った最高の以前の作品と比較したことです。
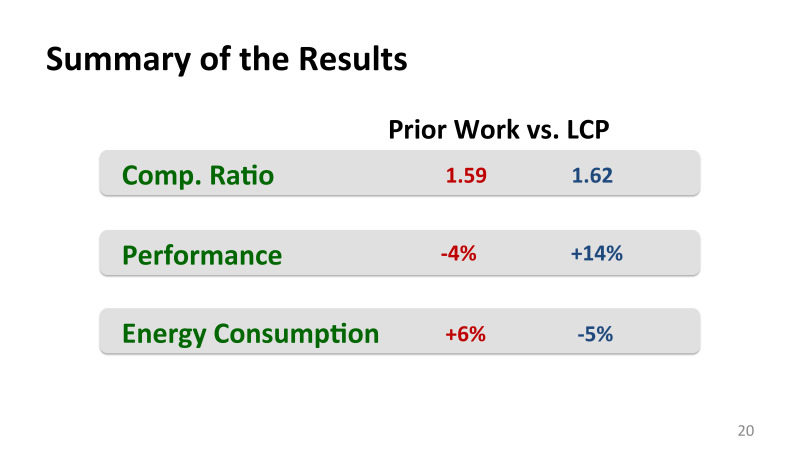
私たちの圧縮は、それらの圧縮よりもはるかに優れていませんでしたが、最も重要なことは、余分なパフォーマンスを支払うことなく、より多くのメモリを取得しました。大まかに言えば、メモリは増えましたが、このため、パフォーマンスはわずかながら低下しましたが、低下していました。そして、エネルギー効率の損失。そして、すべてをプラスにして、パフォーマンスを向上させ、エネルギーコストを削減しました。
実際のハードウェアでの最後の作業について簡単に説明します。これがNvidiaとの仕事です。問題は、通信チャネルを介してメモリからチップにデータを転送する際のエネルギー効率です。グラフィックメモリカードでは、メモリ自体ははるかに小さくなりますが、このメモリのスループットははるかに大きく、ほとんどのグラフィックカードで5〜6倍になります。多くのグラフィックアプリケーションでは、大量のデータを効率的に処理するためにこの帯域幅を必要とするためです。
, Nvidia, 2014 , , , . , : , DVFS, , , , , , , .
— , , . , , . . , - , , , . Nvidia , .
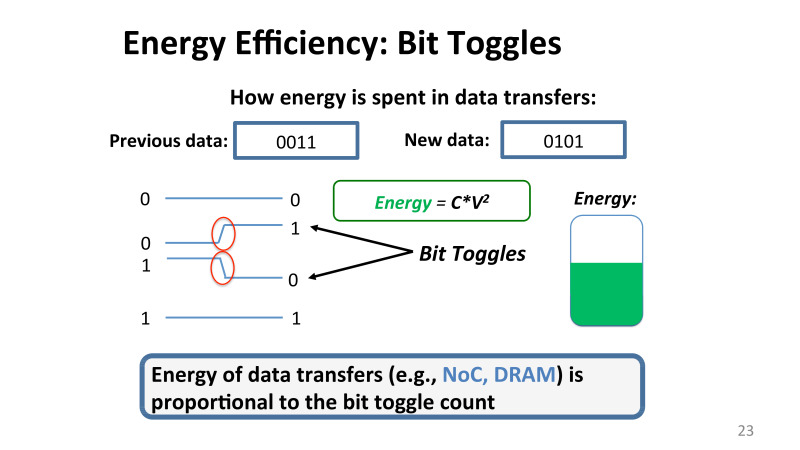
, , . . , , , 0011. . 0101. , 0 0, , bit toggle, , , , , , 0 1 1 0. , . , . , .
— , . , , networks of chip DRM , , .
? ?
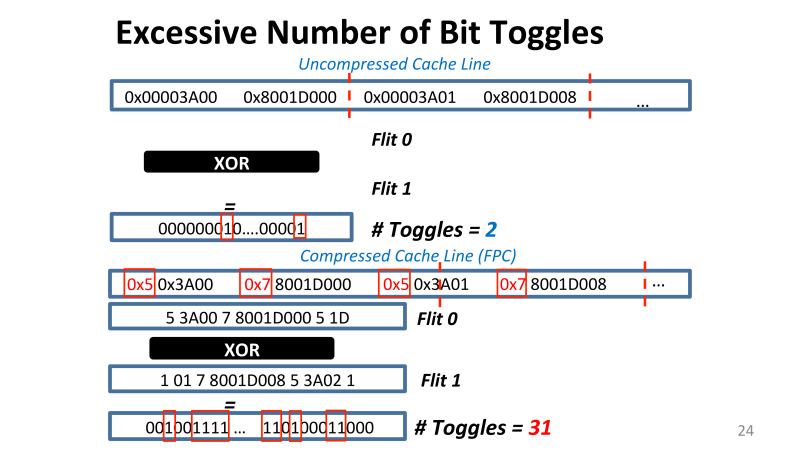
Nvidia, . , 32 16 , . ? , . , , XOR, 16 8 , , .
- , , frequent pattern compression, Intel, , . 15, 16 . , , , alignment. , . , . , Nvidia . , , , , . , 2%, 40%. , .
, . , , , , , , , , , , .

. , , , . , , , - , — , . , , . , , , , , .
, , , Microsoft Research , machine learning.
, , , , . DNNs. . , DNNs — , - Ajura, , , , . , 10%. , , , : TensorFlow, CNTK, MXNet. , , .
DNNs , , , GPU.
DNNs . , , , , . . , , , , . , .
, . , , inference.
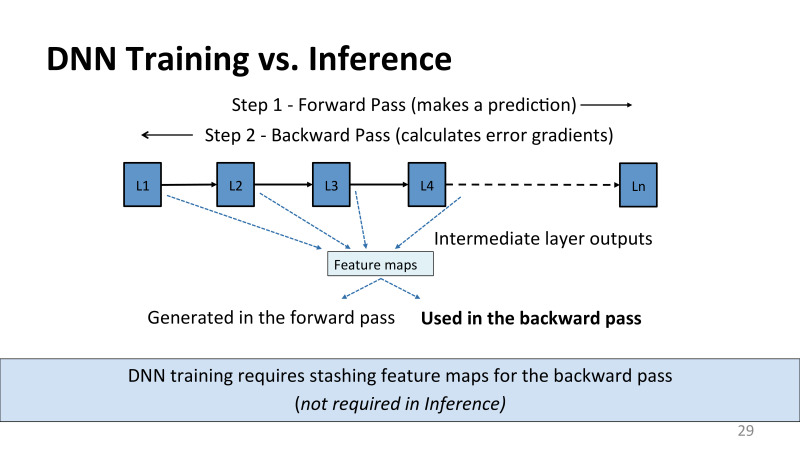
, Google TPU , , , inferent , , Microsoft.
? ? Google, , TPU inference. , . , inference, . forward pass. , - , inference . — . , . backward pass, , , .
, , . , . , , feature maps activations. inference , . back propagation, , , , . , L2, , forward pass , , , , .
, , 100, 200 , , ResNet, image classification. - . — , , ResNet 101 , , , - mini batch , , 64 , , , 16 . , P100 Pascal Volt100, 16 . , .
, Facebook, . , , , . , .
, . GPU, . , .
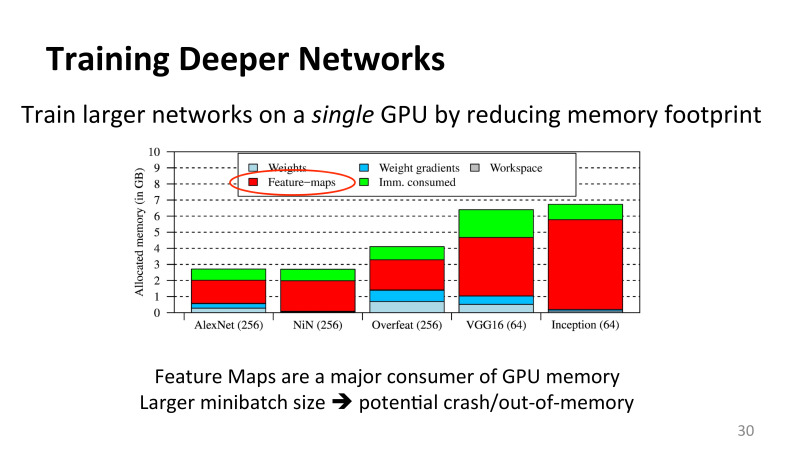
, , , , , . X AlexNet, DNN , : Overfeat, VGG16, Inception ( Google version 3, , Google). mini batch. , , . , , ImageNet, 220 220 3, 1000 : , , .
? AlexNet , 2011 , . , , feature maps, .
? , , mini batch, , , inputs. ? GPU . GPU 8000 threads, , , GPU . , ? , CPU ISAC.
, . , . , , , , , , , DNN inference, , ISCA, MICRO, 2015 15 , deep neural networks, inference, .
-, inference, , forward pass, , , .
, , . , inference, - , , 32- floating point, , 16 , 8 4. , , - stochastic gradient descend, . , . GPU, ISAC, - TPU - FPGA . GPU .
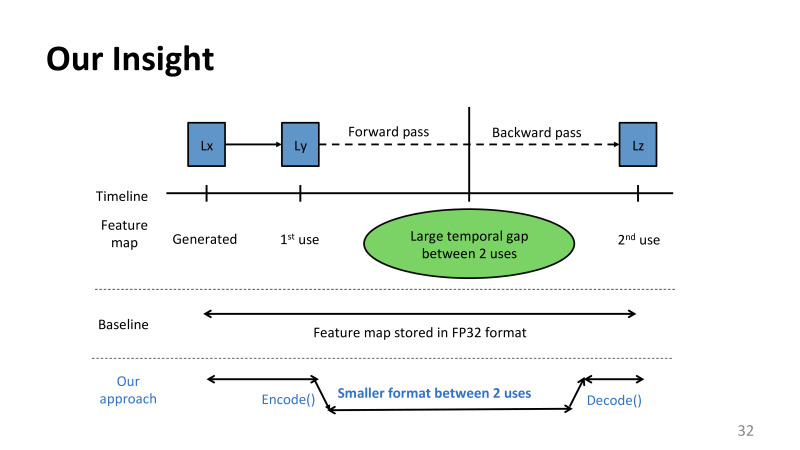
, . , , , , , , , , , , , LX, . , , . . : .
, . - , . , . . . , . , . , . .
, , ? , . , , . , , , . , . - , .
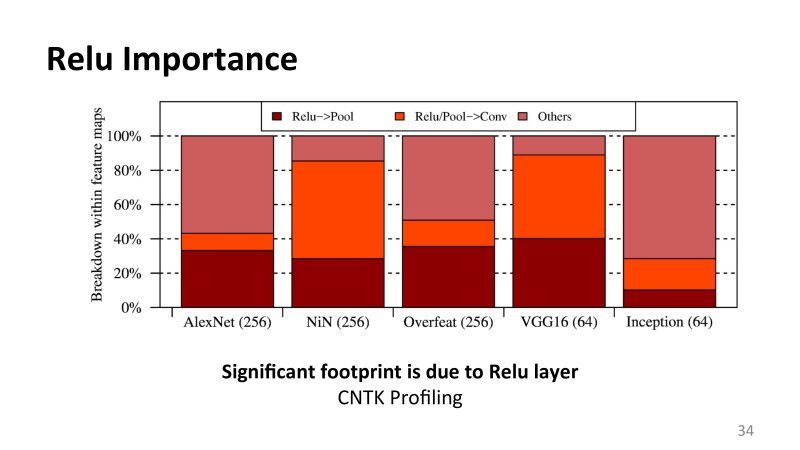
, , : feature maps . , , , , . , , , Relu , rectified linear function pulling layer, , , .
, , . , . , , , Relu, pulling layer. layers, .
, Relu , , - — . — .
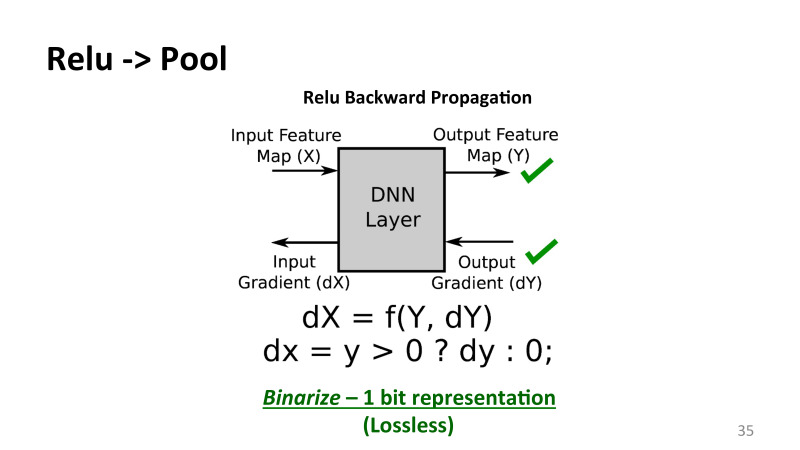
, Relu, . , . Relu — , , , 0, . — , , .
, , , by modal. . , , . , , . - , 32 , , , 31 . , , .
32 , . . , . , pulling layer — 2 2, , 2 2 3 3. , , , . TensorFlow, CNTK, , , . , , machine learning, , . . , , , - , , .
- , , , , . Relu 32 , pulling layer 8 . , , TensorFlow, . - . .
, 32 1 . , , . , . 32-, , . .
, lossless, .
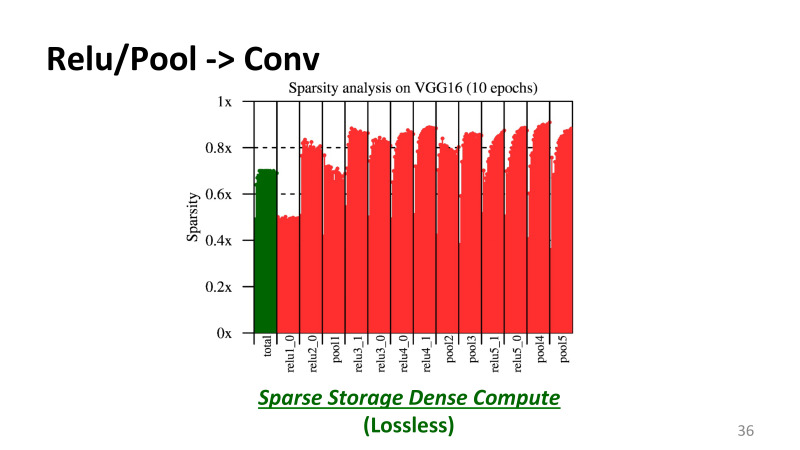
, Relu . . , , VGG16, 10 , , — , . 1 100% , 0,6 — 60% . , .
, , Relu_1, Relu_2 , . , , 60%, 70%. , , , . , .
これはどういう意味ですか? , . , , GPU. CUDA , . , - CUDA . , NVidia , 99%. . , 50% 80% . , GPU . , , , CUDNN , Nvidia . , CUDA , .
, , , Lossy Encoding, . , IBM . , L1 - . 32 , 8 16, - , .
, 32- 16- , , , , , , AlexNet, 32 16 - , , , , validation. , , . , , , . , , , .
. , , , . , , . — . forward pass . , , backward pass, . backward pass, .
?
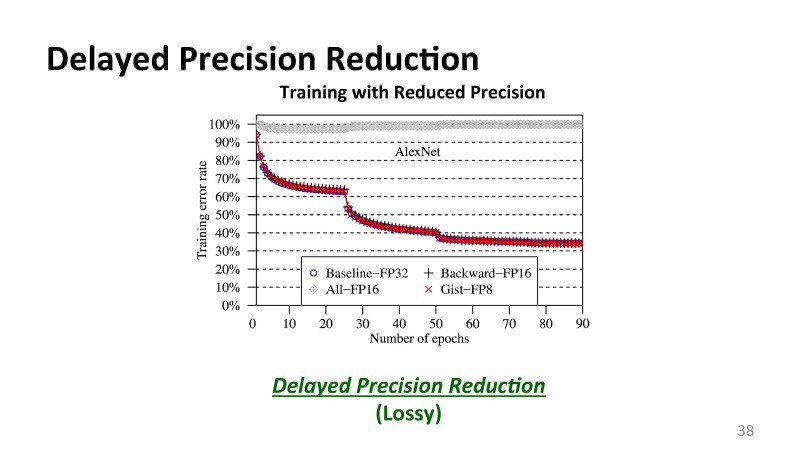
, . — AlexNet FP32, 32 . , IBM , All-FP16, 16 , . - 16 , , 16 , , , - .
, , , , 16 , 8 . , .
, , . , , .
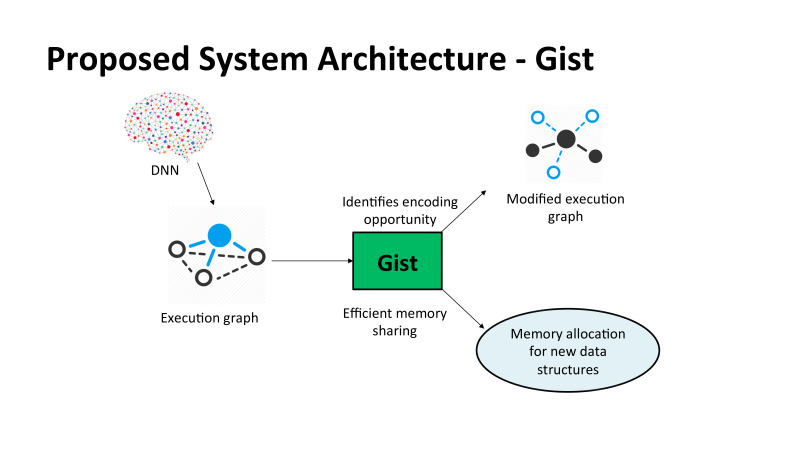
, Gist, «». DNN, execution graph, , , , CNTK , Microsoft. CUDA . execution graph, , TensorFlow, MXNet, . GPU , , . , , .
, , , cuDNN, , . . . , TensorFlow. GIST .
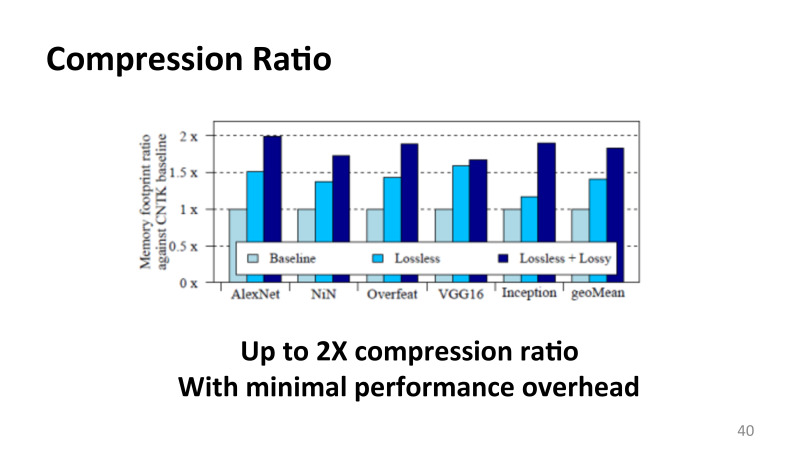
, , ? . , , , , , , 90-100 , . . , , . 6% 8%, , , , . , , Microsoft.
, . , , Microsoft, PhD , , DNN Training, , , , , . . Microsoft , LSTM , speech , , . - -, .
. , , . image classification, AlexNet, ResNet , . Image classification — , , , Facebook. , machine learning .
, , , . , . , MXNet, Amazon, , , TensorFlow. ResNet 50, , «» , 40% , TensorFlow . , MXNet , TensorFlow? . . LSTM, MXNet , TensorFlow, - , Amazon Google, TensorFlow 2,5 . , . .
, . , . , , , , machine learning, .
, , Image Classification, , . object detection, , , Faster RCNNs, 16-17- Google MIT, . : LSTM, , , . nmt — Google, open source. sockeye Amazon. .
Transformer, Attention layers. 2013-, , , , , Attention layers. Google , GPU, , .
speech recognition, LSTM. adversarial networks, reinforcement learning, Google AlphaGo . supervise, n-supervise learning. image classification. , . 16-17- , .
, . TensorFlow, CNTK, MXNet. , , , . TensorFlow , - CNTK MXNet. , , , . , , .
. GPU. , CPU . , , GPU, FPGA, ISAC Google. , TensorFlow, .
: , , , , -. .
, , , , . , , , CNTK. . , . TensorFlow , , 2000 , , , , . . , CNTK, MXNet. TensorFlow , . , Google … , , , , , .
, .
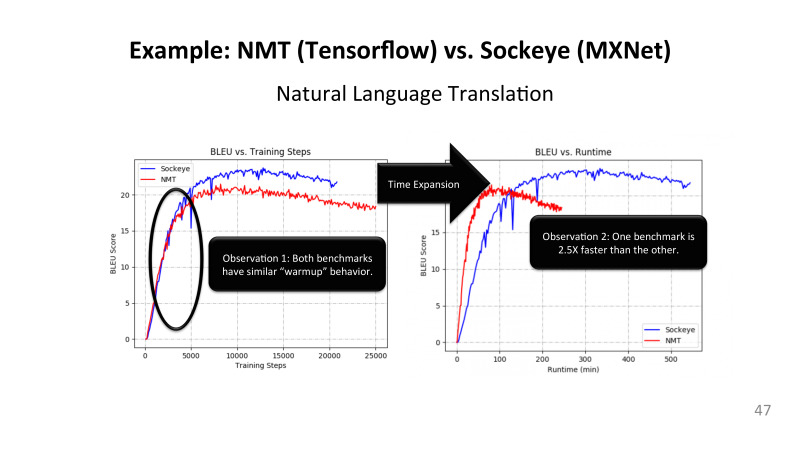
, TensorFlow MXNet . , NMT Google, Sockeye. , - , LSTM , batch, , .
, , , -, Y blue score. , , . , . .
? , , , blue score 20 . , , . SGD. , , - , .
- , learning rate , -, . . , , , , , , . , TensorFlow LSTM . CUDNN, MXNet LSTM. , .
, , TensorFlow, MXNet. , GPU, LSTM , 30% GPU . 70% . , , . TensorFlow 10-15%, . , MXNet. .
LSTM, , Nvidia CUDNN , LSTM . , . -, E , , CUDNN 2,5 LSTM. , «» P100 CUDNN 8 , «» 100 CUDNN 9 . . , . .
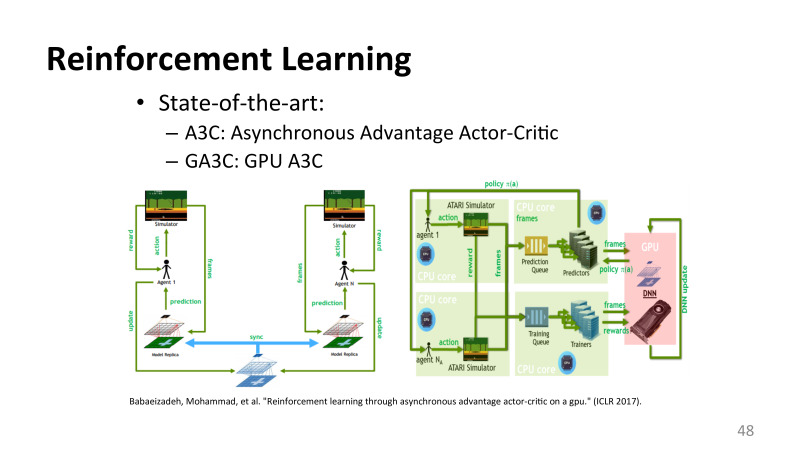
reinforcement learning, . , NIPS ICLR, . , machine learning MATLAB . , , . , , , . . Google, , .
, - , . .
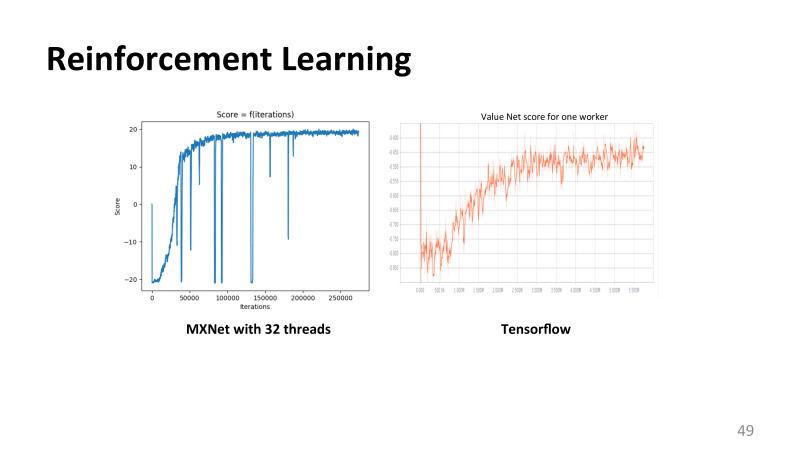
reinforcement learning, MXNet TensorFlow, , .
, . , , , , , , . , , .
, , : , . これはどういう意味ですか? , , . , - , , . , . , Google , 5-7%.
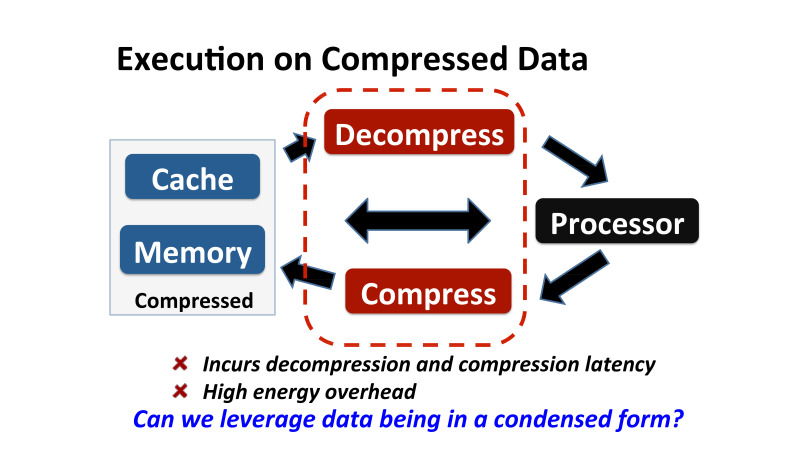
cloud tax 20–25%, , , . , Google Cloud, 25% — , .
— . , - , ? , , , .
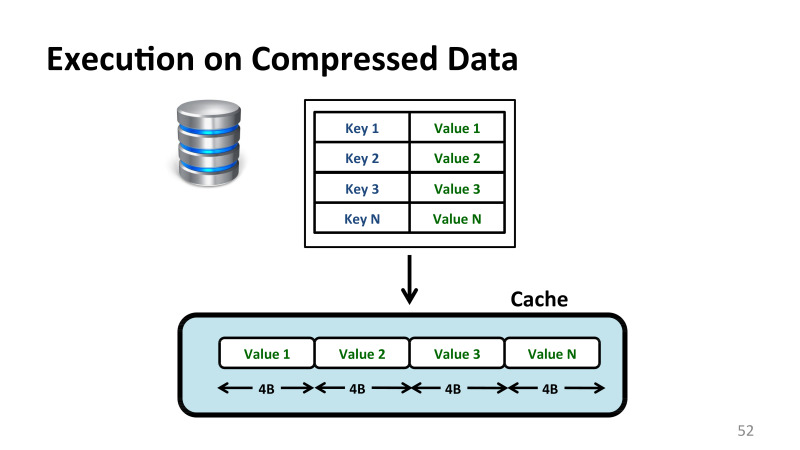
, . . , -, - . - , - . . , , , . , where value = 10, value . , .
, 4 .
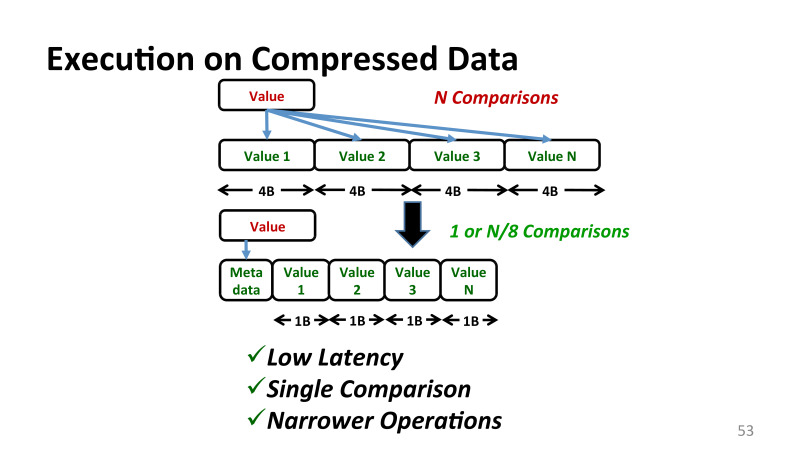
, , , Base+Delta Encoding, - . , 1 , . .
, -. , , ? - , , . , , - , n . , , , . , Base+Delta Encoding . , , Base+Delta Encoding.
これはどういう意味ですか? , , . .
, , , , , , .
, 1 — , . , , — . , . . , CND- Intel . , 1 , . 4 8 .
, . . , , . , . .