今日は、Kerasニューラルネットワークを使用して検索クエリを個別のカテゴリに分類する方法の1つについてお話します。 問い合わせの対象分野は自動車部門でした。
データセットは、3つの検索クエリのサイズとして取得され、14のクラスでマークアップされました: 自動履歴、自動車保険、VU(運転免許証)、苦情、交通警察への登録、MADIへの登録、健康診断への登録、違反と罰則、MADIとAMPPへの控訴、タイトル、登録、登録ステータス、タクシー、避難。
データセット自体(.csvファイル)は次のようになります。
;
;
;
;
;
;
;
;
;
など...
データセットの準備
ニューラルネットワークのモデルを構築する前に、データセットを準備する、つまり、すべてのストップワード、特殊文字を削除する必要があります。 したがって、「オンラインワイン番号でパンチCamry 2.4」などのリクエストのように、番号には意味がありません。それらも削除します。
NLTKパッケージからストップワードを取得します。 また、ストップワードのリストをシンボルで更新します。
結果は次のとおりです。
stop = set(stopwords.words('russian')) stop.update(['.', ',', '"', "'", '?', '!', ':', ';', '(', ')', '[', ']', '{', '}','#','№']) def clean_csv(df): for index,row in df.iterrows(): row[''] = remove_stop_words(row['']).rstrip().lower()
分類の入力時に受信される要求も準備する必要があります。 リクエストを「クリア」する関数を書きましょう
def remove_stop_words(query): str = '' for i in wordpunct_tokenize(query): if i not in stop and not i.isdigit(): str = str + i + ' ' return str
データの形式化
普通の単語を拾い上げてニューラルネットワークに入れるだけでなく、ロシア語でさえ入れることはできません! ネットワークのトレーニングを開始する前に、クエリをシーケンス(シーケンス)の行列に変換します。クラスは、サイズNのベクトルとして表される必要があります(Nはクラスの数)。 データを変換するには、Tokenizerライブラリが必要です。このライブラリは、各単語を個別のインデックスと照合し、クエリ(文)を配列に変換できます
インデックス。 ただし、リクエストの長さは異なる可能性があるため、配列の長さは異なることが判明します。これは、ニューラルネットワークでは受け入れられません。 この問題を解決するには、前述のように、リクエストを等しい長さのシーケンスの2次元配列に変換する必要があります。 出力(クラスベクトル)を使用すると、少し簡単になります。 クラスのベクトルには1または0が含まれます。これは、要求が対応するクラスに属していることを示します。
だから、何が起こったのか見てください:
# CSV df = pd.read_csv('cleaned_dataset.csv',delimiter=';',encoding = "utf-8").astype(str) num_classes = len(df[''].drop_duplicates()) X_raw = df[''].values Y_raw = df[''].values # tokenizer = Tokenizer(num_words=max_words) tokenizer.fit_on_texts(X_raw) x_train = tokenizer.texts_to_matrix(X_raw) # encoder = LabelEncoder() encoder.fit(Y_raw) encoded_Y = encoder.transform(Y_raw) y_train = keras.utils.to_categorical(encoded_Y, num_classes)
モデルの構築とコンパイル
いくつかのレイヤーを追加してモデルを初期化し、コンパイルして、2つ以上のクラス(バイナリではない)があるため、損失関数が「categorical_crossentropy」になることを示します。 次に、モデルをトレーニングしてファイルに保存します。 以下のコードを参照してください。
model = Sequential() model.add(Dense(512, input_shape=(max_words,))) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(num_classes)) model.add(Activation('softmax')) model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1) model.save('classifier.h5')
ちなみに、トレーニング中の精度は97%で、非常に良い結果です。
モデルテスト
ここで、引数をとるコマンドライン用の小さなスクリプト(検索クエリ)を作成し、以前に作成したモデルの意見でクエリが属する可能性が最も高いクラスを出力します。 このセクションのコードの詳細には触れません 。すべてのソースはGITHUBを参照しています 。 仕事に取り掛かりましょう。つまり、コマンドラインでスクリプトを実行し、リクエストの実行を開始します。
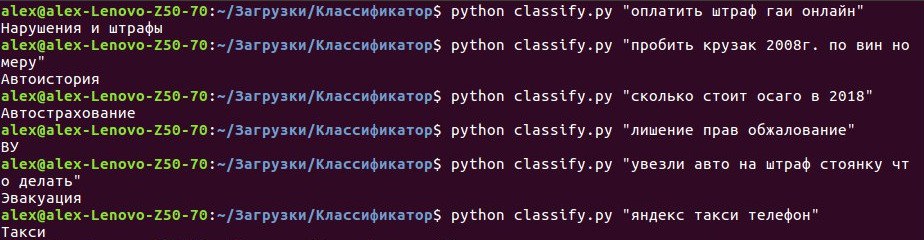
図1-分類子の使用例
結果は非常に明白です-分類子は、入力された要求を正確に認識します。つまり、すべての作業が無駄に行われたわけではありません。
結論と結論
ニューラルネットワークはタスクに完全に対応しており、これは武装した視線なしで見ることができます。 このモデルの実際の応用例は、市民があらゆる種類の声明、苦情などを提出する公共サービスの範囲と考えることができます。 知的分類の助けを借りてこれらすべての「紙」の受け取りを自動化することにより、すべての政府機関の作業を大幅にスピードアップできます。
実用的な応用のためのあなたの提案、および記事に関する意見は、コメントで待っています!