StatsDや他の時系列システムの人気を背景に、「 すべてを監視する 」というアイデアが浮上しました:予期しない状況の場合には、すべてを理解できるようにする必要な既に組み立てられたメトリックを見つけることができるため、システムでより多くの異なるものが測定されるほど良いです。
監視できるすべてのことをしましょう、それはクールです!
しかし、元々何らかの制限付きで作られたファッショナブルなテクノロジーでよくあることですが、使用開始時には、人々はこれらの制限について本当に考えていませんが、言うように、必要に応じて行います。
そして、このすべてに多くの問題があり、実際、パベル・トルハノフ( tru_pablo )が私たちに教えてくれます。
私たちが開発しているソフトウェア製品、モバイルゲーム、または銀行のソフトウェアに関係なく、システムはグリッチ、中断なし、ユーザーが満足することなく、着信イベントを迅速に処理することを望んでいます。
これを行うには、プロセスが正常に実行されていることを常に監視する必要があります。 Okmeterは、数千人のエンジニアがモニタリングサービスで同じことを繰り返し行わないように設計されたサービスを提供しています。
会社のディレクターであるPavel Trukhanov ( @tru_pablo )が、監視、測定基準、数学について多くのことを読んで、考えてから、多くのことを読んで考えなければならないことは驚くことではありません。 このトピックは彼にとって苦痛になり、彼は発言することにしました。 この記事は、RIT ++ 2017での彼のレポートの転写です
キューイングシステム
私たちは、独立したリクエストが来るキューイングシステム(QS)について話している。 QSには以下が含まれます。
- それらにサービスを提供するサービス 。
- サービス時間 - サービス時間および応答時間-キュー待機時間を含むタイミング 。
- サービス結果。
Web、つまり、応答時間と応答のhttpステータスが記録されているアクセスログについて話すと、エラーやブレーキがあるかどうかがわかります。 私たちは、システムがグリッチ、何も「失敗」せず、ユーザーが満足することなく、着信イベントを迅速に処理することを望んでいます。 これを行うには、プロセスが期待どおりに進行していることを常に監視する必要があります。 さらに、すべてが良いという考えがありますが、現実があり、それらを常に比較しています。
グラフ
プロセスが私たちの期待に合わない場合、「通常の」状況を自問自答したり決定したりする方法については、さらに理解する必要があります。 そのためには、時間を水平スケールでプロットし、必要なパラメーターを垂直スケールでプロットする時系列チャートを使用すると非常に便利です。
このようなグラフは、次のように明確に表示されるため、予期したとおりに問題が発生した場合に最も役立つと考えています。
- 影響 、つまり、すべてがどれほど悪いか。
- 履歴 -インジケーターの典型的な動作はどのようなものか。
- プロセスダイナミクス 、すなわち 状況が悪化しているか悪化しているかを確認できます。
bar 、 scatter (point)、 heatmapなど、グラフが異なることは誰もが知っています。 しかし、私はタイムラインが好きで、私たちの脳はどのセグメントが長いかを冷静に判断できるので、それらをお勧めします=)これは、そのようなグラフが直接使用できる進化的特性です。
そのようなスケジュールを作成する方法は?
時間スケールは水平スケールにプロットされ、垂直スケールは他のパラメーターに使用されます。 つまり 時間ごとに、情報で満たすことができるピクセルの垂直ストリップが1つあります。 モニターのサイズに応じて、たとえば800ピクセルまたは1600ピクセルです。
システムが非常に大きい場合、システムの時間単位である10、100、1000、またはそれ以上で異なる数のイベントが発生する可能性があります。 システム内でどれほど重要でもありません。これが1つのイベントではないことが重要です。 さらに、イベントにはさまざまなタイプ、タイミング、または結果があります。
好きなだけ多くのグラフを作成して、別々のグラフでさまざまな側面を見ることができるという事実にもかかわらず、とにかく、特定のグラフについては、表示する多数のパラメーターを持ついくつかのイベントから1つの数字を作成する必要があります。
1000タイミング-それらをどうするか?
タイミングは分布密度の形で視覚化できます。水平方向に現在のタイミング値がプロットされ、垂直方向にこの値を持つタイミングの数がプロットされます。
分布密度のグラフは 、特定の平均値を持つタイミングがあり、速い、遅いがあることを示しています。
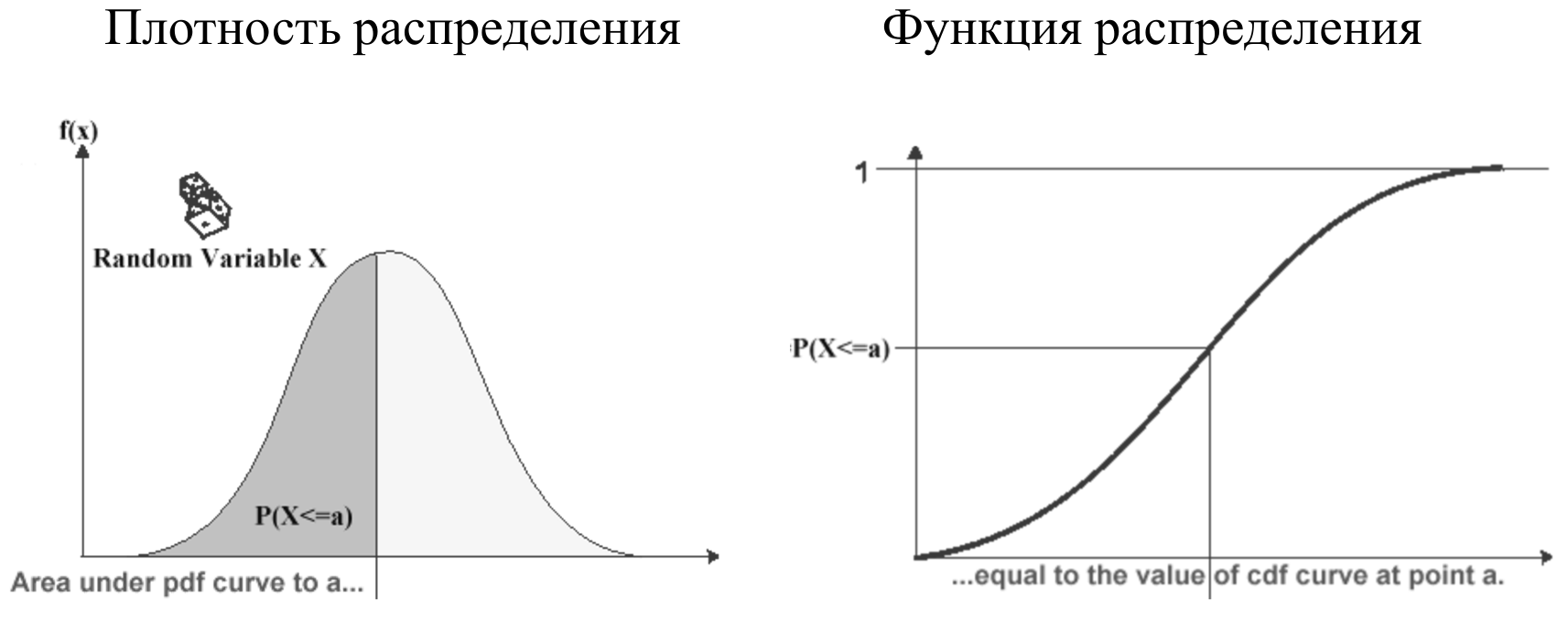
分布密度に加えて、単に分布密度の積分である分布関数を見ると便利です。 値の範囲が0〜1のセグメントによって制限されているため、正規化せずに完全に異なるパラメーターを相互に比較することができます。 しかし、分布密度はより身近で物理的です。
現実には、私たちが話しているシステムでは、分布密度のグラフは誰もが知っている正規分布のガウスの鐘のようには見えません。 少なくとも、 タイミングは負ではありません (サーバーの時間が戻った場合を除き、これはもちろん起こりますが、実際にはまれです)。 したがって、ほとんどの場合、グラフは次の図のようになります。
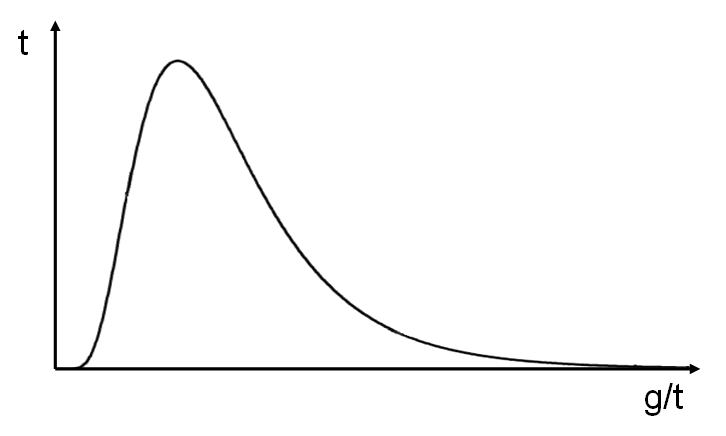
これは特定のモデルであり、近似値です。 対数正規分布と呼ばれ、正規分布関数の指数です。
しかし、現実はもちろん、それでもありません。 すべてのシステムは少し異なって見えます。 たとえば、ある人がMemcachedを自分のphpにねじ込んだ場合、リクエストの半分はMemcachedに送信され 、半分はそうではありませんでした。 したがって、バイモーダル(2頂点)分布が得られます。
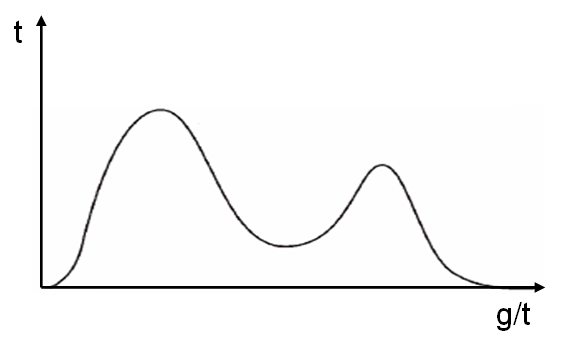
完全に正直に言うと、実際の分布関数は好きなように見えます(下図を参照)。 システムが複雑になるほど、システムは多様になります。 一方、システムが非常に複雑になり、100万件の詳細から外れると、平均で正規分布にロールバックします。
これらの1000のタイミングは、たとえば1分ごとなど、各時間間隔で絶えず計算されることを覚えておくことが重要です。 つまり、間隔ごとに何らかの分布密度があります。

1000タイミング-それらをどうするか?
チャート上で1000ではなく1つの数値を延期するには、測定値から統計情報を取得する必要があります。これは、実際には、1000の数値を1つに絞ります。 つまり、データの損失は重要です。
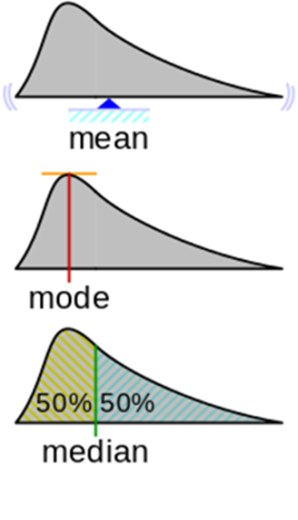
既知の(および一般的な)統計:
- 算術平均は、密度グラフの重心です。
- 密度関数のモードは、最大分布密度です。 X軸に沿った最大値の位置これは疑問を提起します:いくつかのピークがあるときどうするか。
- 中央値 -Xの値。図の領域は半分に分割されます。
中央値に加えて、 パーセンタイルやその他の統計がありますが、 どの統計を採用しても 、1000個の観測値を完全には説明できない1つの数値であることを強調したいと思います。
統計情報を取得し、(最後に)グラフを取得したとします:

この場合、算術平均グラフです。 それから何かがすでに明らかです。 平均値にはわずかな変動があることは明らかですが、桁違いの値のばらつきはありません。
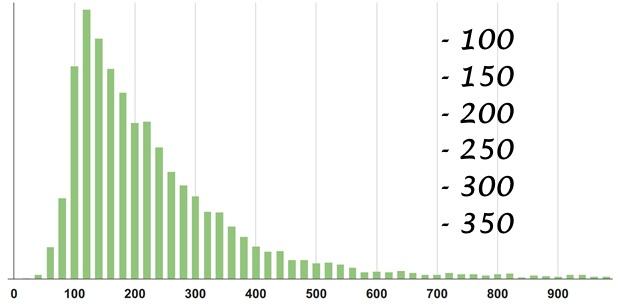
次に例を示します。この分布密度は特定のサービスから取得されます。 統計を推測します-オプションのいずれかを選択してから、露出で黒魔術のセッションを行います。
答え
フィギュアの重心がどこにあるのか想像するのは簡単に思えますが、確かに推測してみてください、あなたがだまされると確信しています! 見てみましょう:
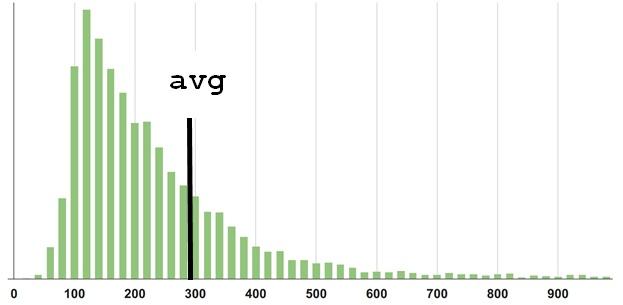
これは推測するのが難しいことではないかもしれませんが、別の例を次に示します。
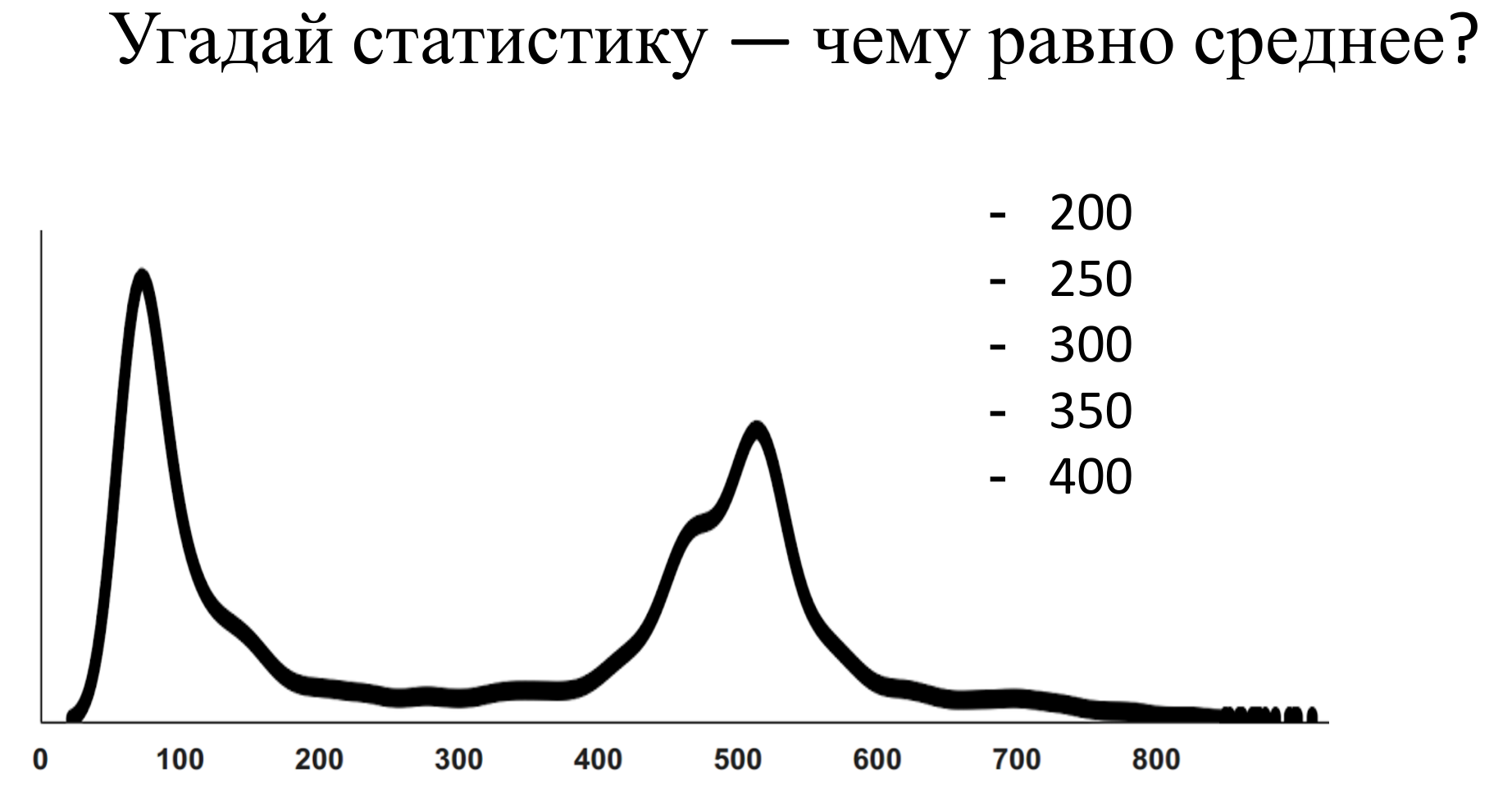
答え
ここで平均は500です。私自身がこの質問に答えたとき、2つの健全なピークは300の領域のどこかでバランスが取れているように思えました。
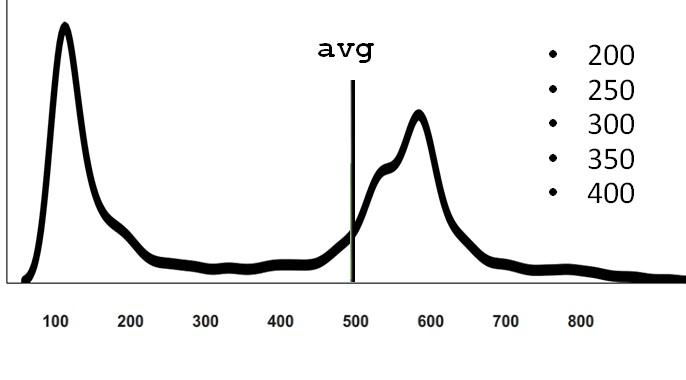
実際、このチャートをキャンセルすると、彼はまた、私たちが見ているスケールでは見えない遠い尾の観測値を持っていることがわかります。
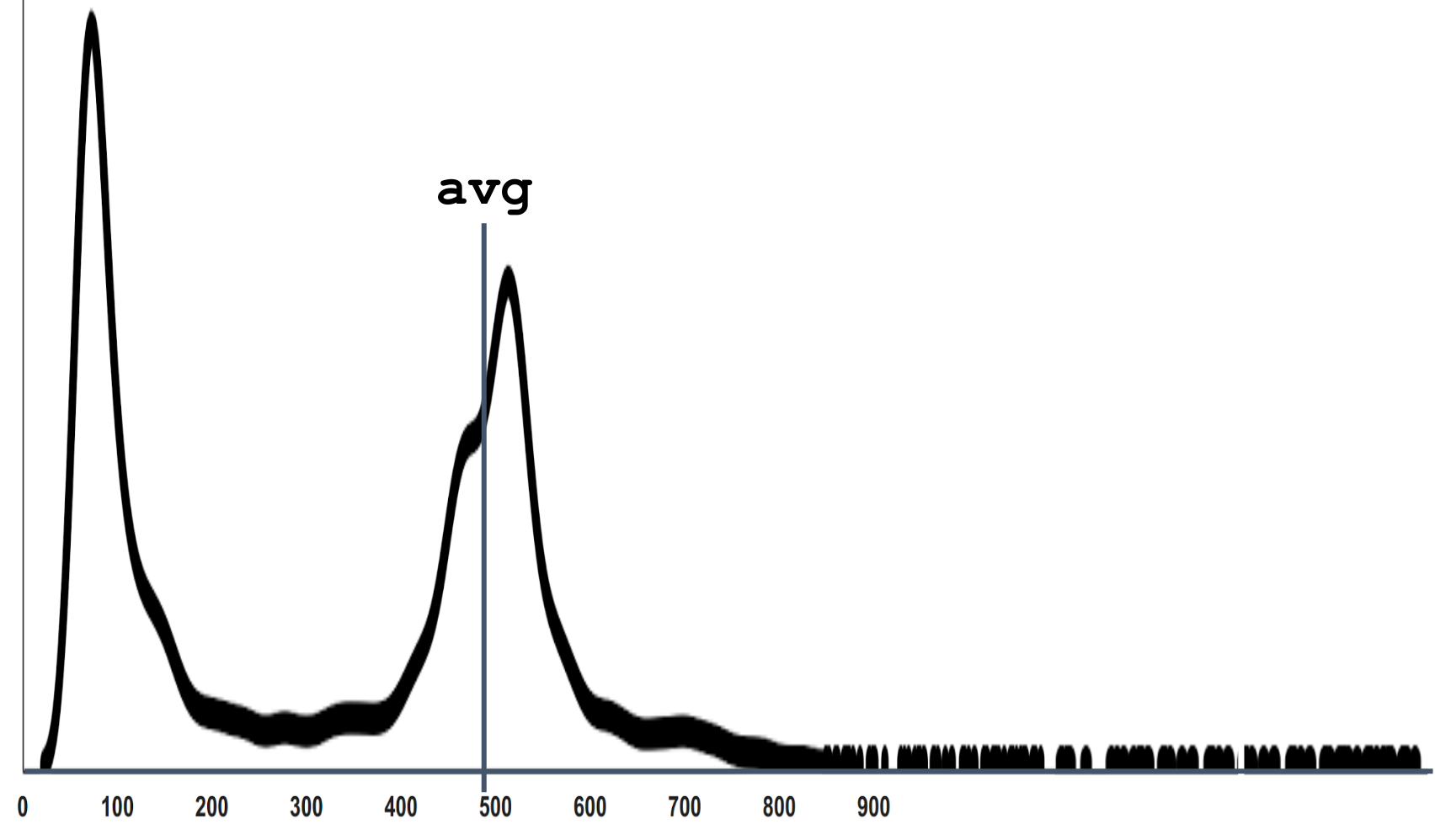
実際、このチャートをキャンセルすると、彼はまた、私たちが見ているスケールでは見えない遠い尾の観測値を持っていることがわかります。
通常、実際の複雑なシステムはこのように動作します。 同時に多くのリクエストが存在する場合があり、特定のリクエストのスターがうまく合わず、処理時間が長い場合に状況が発生するため、常にリソースを奪い合います。 数学的期待の物理的意味が分布密度の重心であることを思い出すと、ファーテールでのわずかな測定値でもてこ比のルールを上回っていることは明らかです。 したがって、平均は「典型的な平均」が感じられる場所にはありません。
私のポイントは、システムやシステムのさまざまな部分でディストリビューションが完全に異なる可能性があるということです。 そして、実際に平均を計算するまで、一連の観測値を収集し、収集した統計に基づいてグラフを作成した後、実際に結果を正しく推測することはほとんどありません。 統計を収集しても、平均を推測するのは簡単ではありません。
算術平均に関する紛争
平均/平均メトリックは、モニタリングに非常に不十分に使用されると考えられています。 パーセンタイルファンは、あらゆる角度から叫びます。「モニタリングであなたの平均を見ました。あなたは悪い人です! パーセンタイルをより良く活用しましょう!」
彼らはこれを一からではなく言っていることに注意すべきであり、これには特定の理由があります:
1.物理的な意味。
平均が重心であるという事実に加えて、物理的な意味は次のように説明できます。特定の数にベットすると、ベットの結果(勝ち負け)が蓄積されます。 1袋のお金にすべてを入れることで獲得した金額は、算術平均に等しい数学的期待の本質です。
しかし、たとえば、ユーザーが製品カードを非常に迅速に開き、購入することを期待するオンラインストアなどのオンラインシステムは、このような期待の概念や発明の目的と比較することはできません。
2.エミッションの堅牢性
パーセンタイルファンの2番目の議論は、「平均は排出に対してロバストではない」ということです。 確かに、ファーテールでは、軸の始点近くにある多数の観測値よりも1つの観測値の方が大きいことがわかりました(この場合、それぞれ大きいタイミングと小さいタイミングがあります)。
しかし、ここで直感的に説明したいのは、実際には監視には堅牢性は必要ないということです! それどころか、 私たちは排出量の非傾向 、つまり、排出量を明確に認識して表示するシステムが必要です。 たとえば、これが一度もなかった場合、平均が特定の境界を超えます。 そして突然、どこからともなく、前例のない遠方の急増が現れました。そして、もちろん、あなたはそれについて知りたいです。 結局のところ、システムはこれまでにないように動作し始めました-これは何かが間違っているという確実な兆候です。 あなたはこれに目をつぶって言いたくありません。 これは爆発的です。私はそれについて知りたくありません。」
エミッションの堅牢性に関する要件/要望はどこから来たのですか? 特定のITシステムを継承した場合など、特定のシステムの調査ではなく、タスクの監視ではなく、そのプロパティの一部を調査する場合、負荷時の動作の基本パターンを強調します。 何らかの制御された環境/環境でこれを行い、動作を測定します。 そして、この挙動を特徴づけようとしている統計が排出に対してロバスト性を備えていればいいと思います。 研究のセットアップやシステムの特徴的な動作とはまったく関係のないイベントの影響を考慮せずに破棄したいからです。 (たとえば、観察を記録し、眠り込んだり、誤って記録した実験助手Vasyaのように)。
それどころか、監視と制御を行う場合は、これらすべての排出量を把握する必要があります。どの排出量が一般的で、どの排出量が一般的でないかです。
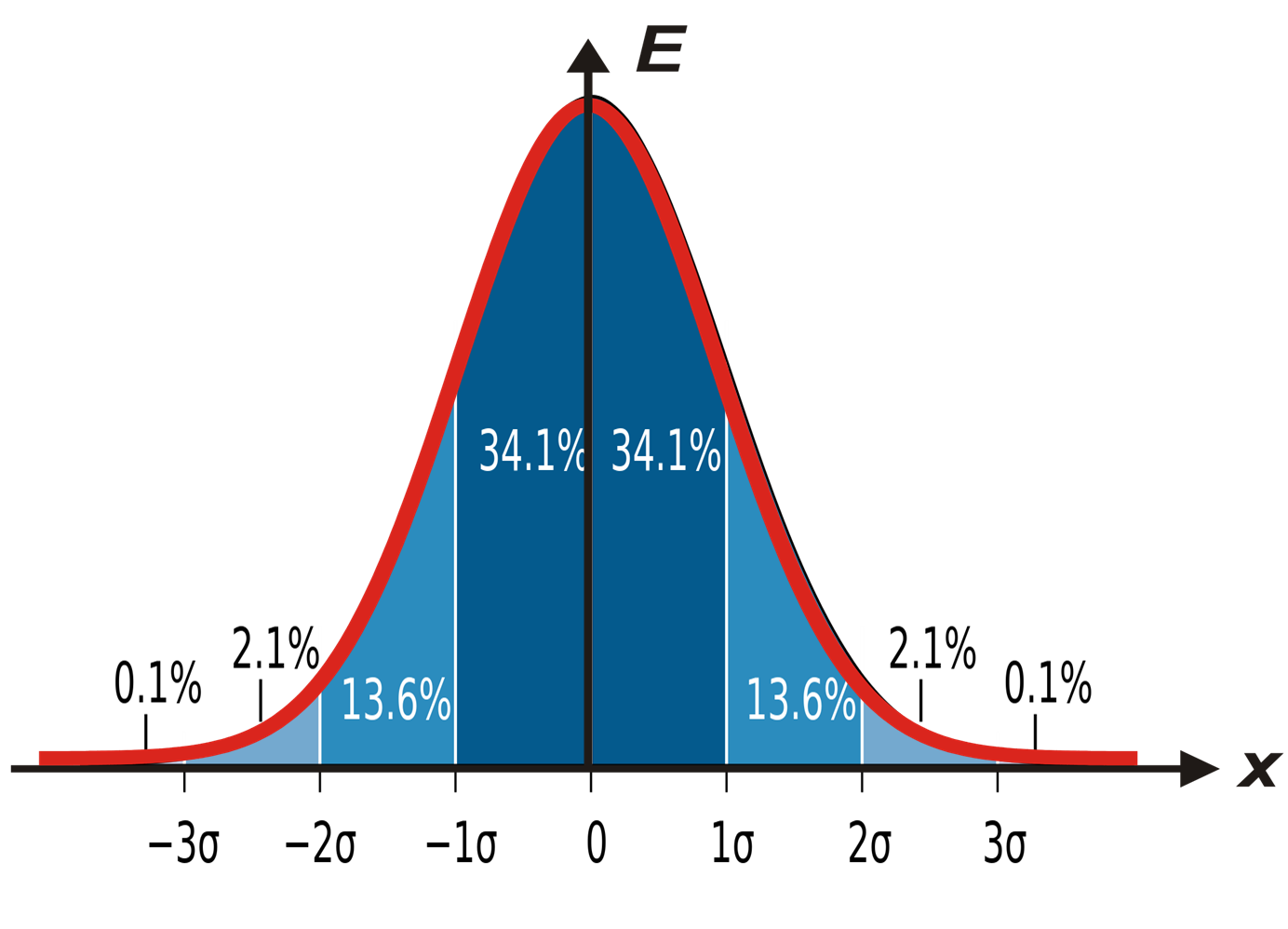
上の写真では、ガウシアナの鐘が「切り分けられ」ています。
多くの人は「 3σ (シグマ)の規則」を知っています。平均から「 3σが後退する」場合、この間隔の外に落ちることを観測する確率は非常に小さくなります。
ここから急ぎの文が続きます。「(任意の、またはお気に入りの)メトリックにチェックをかけ、値が平均から3σ上昇したときに監視し、警告します。」 たとえば、「これらはまれなイベントであるため、これが既に発生している場合は、何かが間違っている可能性が高く、全員を起こして何かをする必要があります。」
図からわかるように、 3σの逸脱は約0.1%の確率を与え、これらは非常にまれなイベントであると思われます。 しかし、実際にはそうではありません! 700回の観測で1回、何かがそこに落ちます。
正規分布であっても、これらの悪名高い3σを超えるイベントは、「まれ」および「異常」の一般的な理解よりも、予想よりも頻繁に発生することを示したいと思います。 そして、これが監視している場合、彼らはあなたにスパムを送りますが、利益はありません。
これら2つのタスクは関連しています:
- まず、私たちのシステムが「通常の」方法でどのように動作するかを理解したいと思います。これは非常に重要です。
- 次に、分布を構築したときに、 しきい値を選択し (分布に焦点を合わせるかどうか)、それらにアラートを設定して監視します。
「ノルム」とは何ですか?
私の意見では、最初の例の値300は、システムの「平均」または典型的な動作を説明していません。 個人的な意味では、中央値(50パーセンタイル)は、この分布の「標準」と呼ぶものに近いものです。
パーセンタイルP90は約550です。また、パーセンタイルが多くなるほど、分布の詳細な説明になります。
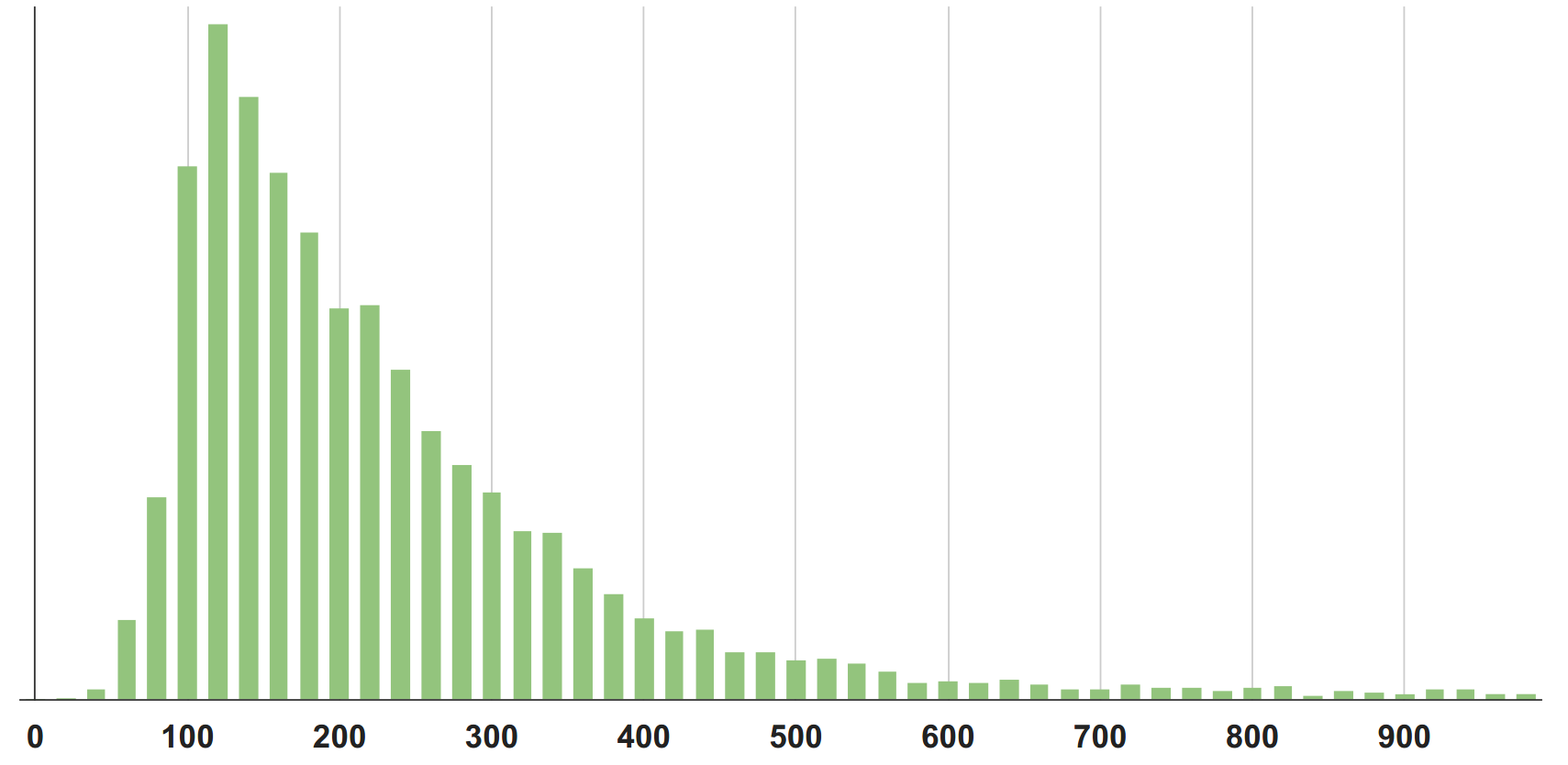
もちろん、分布自体とその密度を構築して目で見ることができますが、制御/監視または最適化タスクでは、異なる分布を比較できるように、限られた数のパラメーターで操作する必要があります 。
別の例、サービス応答時間の別の分布を見てみましょう。 ある意味では、次のようになります。
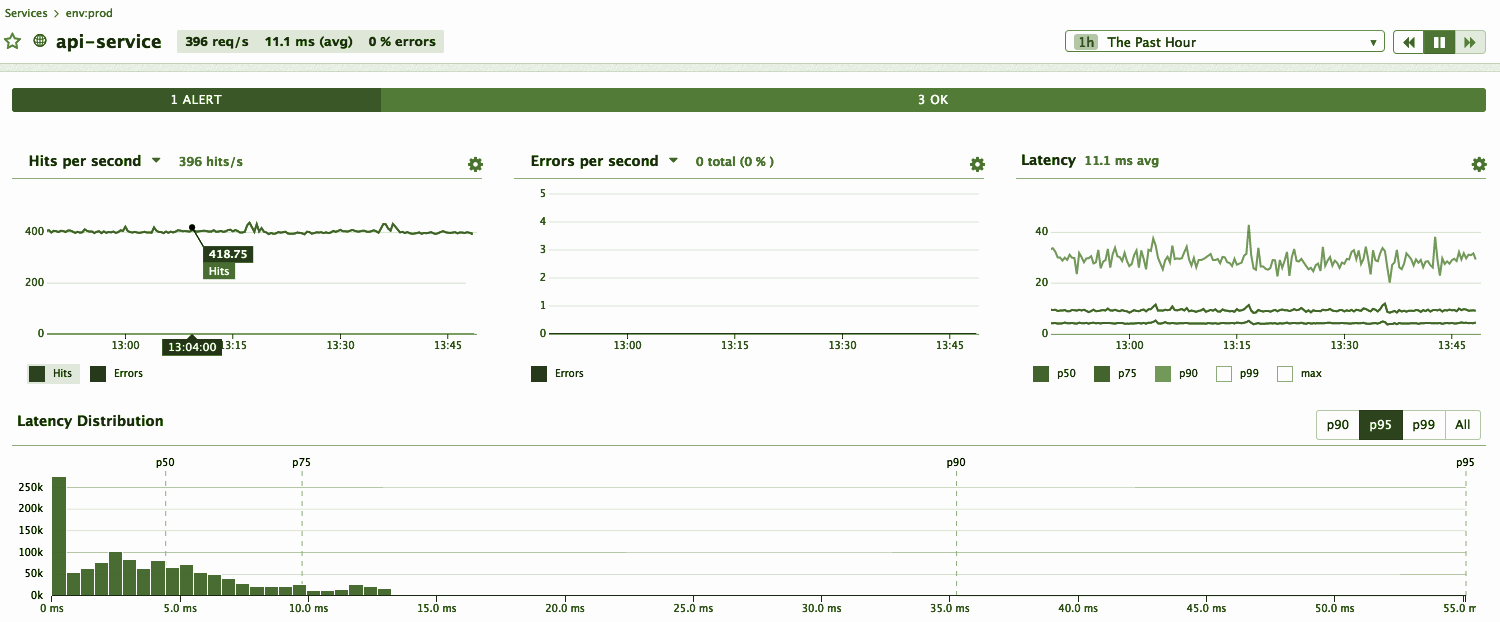

私の期待は、「おい、待って、ここにほとんどすべての観測値があり、最大15ミリ秒、そして95番目の理由はどこにあるのか?」
パラドックス。
さて、95番目はクールなパーセンタイルです。ファンは、中央だけでなく中央値だけでなく、より高いパーセンタイルも見ることが重要であると確信しました。 P95の監視を始めましょう。明らかに以前のすべてをカバーしているからです。
モニタリング
私たちはサービスレベル目標を設定しました-または、ロシア語で、目標。 たとえば、P95 <55 msで、これの監視を開始します。
このSLOが悪いのは、実際には多くのポイントがあります。
微妙な劣化
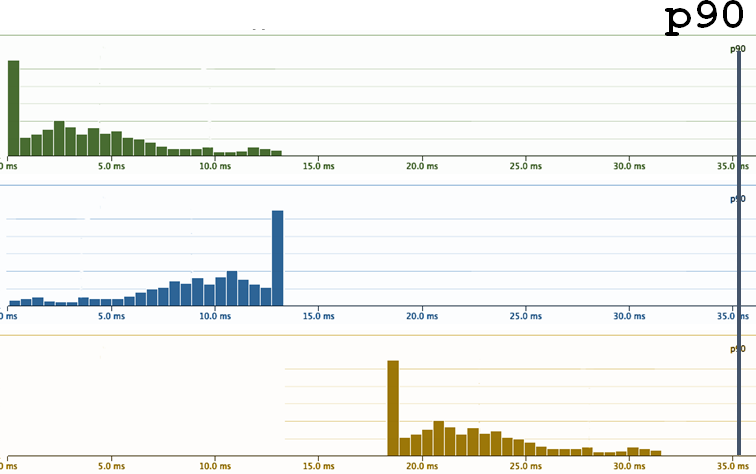
そして、おそらくあなたはそのような変更がシステムで起こったことを知りたいと思うでしょう。 したがって、「Xパーセンタイルのみを見てみましょう」というアプローチは再び機能しません。 ¯\ _(ツ)_ /¯
ソリューションが請う:
-さて、多くのパーセンタイルを追跡しましょう! 1つの9番目では十分ではありません。75番目の条件P75 <15 msを設定しましょう。 そしてさらに!
何が起こるか見てみましょう。
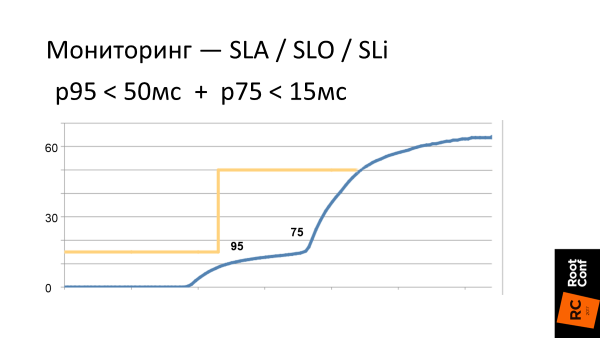
システムの動作に関する現在の要件は、グラフ上の黄色の境界線です。 そして、青い曲線は、システムのレイテンシが実際にどのように見えるかです。 ここで確認する必要があるのは、p95の右側(スケールは非線形)で、レイテンシがすぐに増大し始めることです。 システムをしきい値に固定し、その制御を停止すると、システムはできるだけ早くこれらのしきい値から飛び出そうとします。 つまり、すべてをp95レベルで最適化すると、p96でタイミングが大幅に増加します。
第二の瞬間
私たちは監視会社なので、彼らはいつも私たちに尋ねます:「パーセンタイルを追跡できますか? 95パーセンタイルを描画していますか?」
しぶしぶ答えます:「はい、できます...」。 監視にはパーセンタイルがありますが、ユーザーを誤解させるため、それらを非表示にして表示しないようにしています。
分布密度があると仮定します。
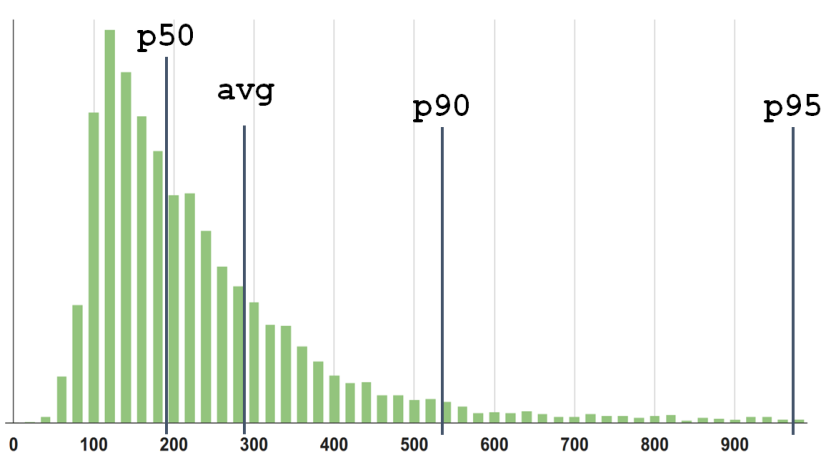
3パーセンタイルと平均が表示されます。 しかし、ここで何が問題なのでしょうか? 95が単なる「95」ではないということではありません。 これは100のうちの95です。 これらの5%はどこにありますか?
右側では、スケジュールはすでに低く、右側には既に非常にまれなイベントがあると感じられます。 そして、それらはありますが、あなたはそれらを見ることができません。
しかし、図では、これらの5%を収集し、列に入れました。 そして、それらはたくさんあります! 5%は20日ごとです。 これはたくさんです! そして、 それらを無視することは間違っていることがすぐに明らかになります 。
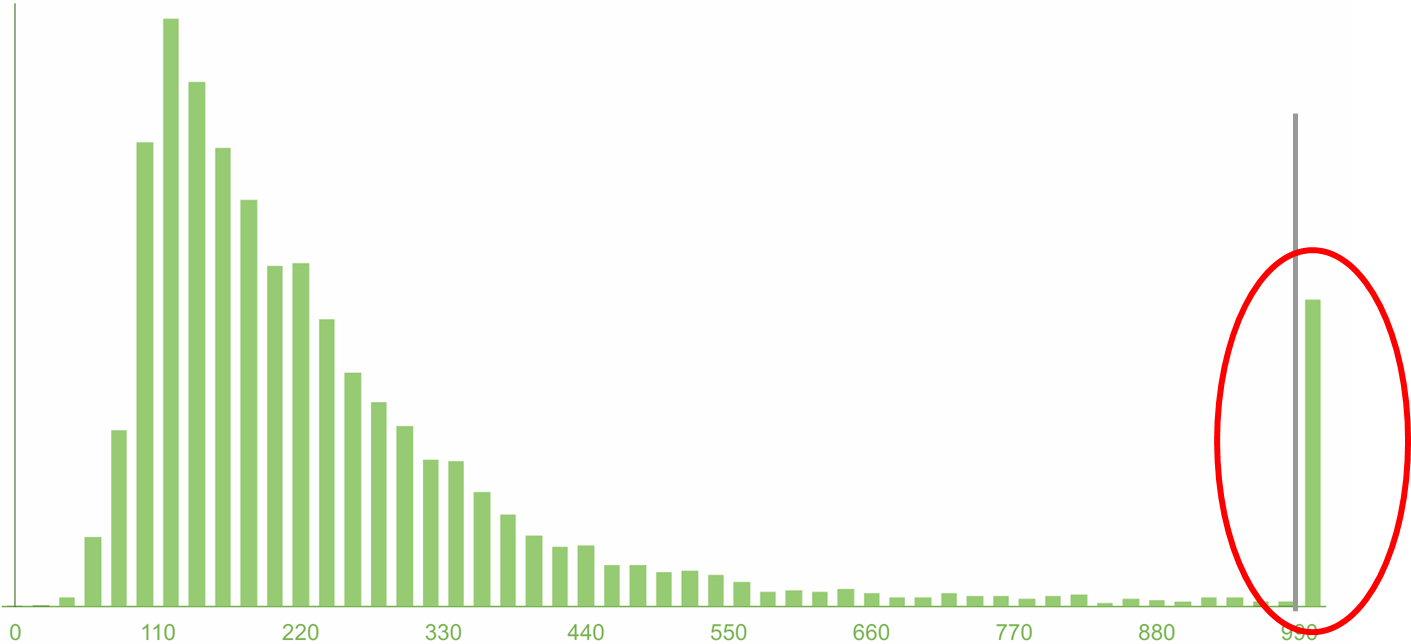
サービスの95パーセンタイルを見ると、それがクール(100ミリ秒程度)である場合、すべてが素晴らしいと思います! 実際、あなたは意識的に5%に目をつぶっただけです。「恐ろしくて不愉快なので、分布のその遠い尾でその恐怖を見ることはありません-見たくない!」これはもちろん無責任です。
ここでも、解決策が請うことは明らかです。「わかりました。95で十分ではありません。99にしましょう。 私たちはクールな男です、9ナイン-99.9%も取りましょう! ''
すでに、実際には、1000分の1は99.9%に該当しないように思われます。これはおそらく最適化に費用がかかるため、このような希少性をスコアリングできます。
え?
しかし、 99.9%はまだ小さいことを納得させようと思います。
これも直観に反する(そして大胆な)声明です。 それを証明する前に、これらの「シニア」パーセンタイルについてお話したいと思います。
パーセンタイルが人生でしばしば測定される方法
現在、 StatsDから始まって、さまざまなディメンションを簡単に取得できるさまざまな最新のユーティリティで終わる多くのツールがあります。
-サービスの動作を測定しましょう!
-さあ!
-監視を続けましょう- あるテーマのリソースでそれがどのように行われるかを読みます-それを置いてください-それがすべてです! チャートがあります!
そして今、私たちはすでに応答のタイムラインを受け取っています。 (最愛の)パーセンタイルを見てみましょう。
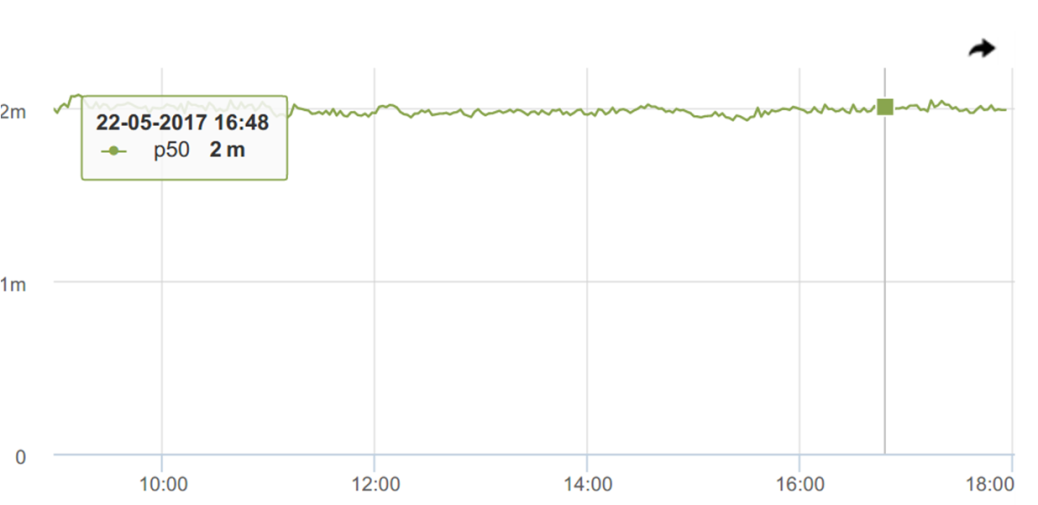
ここに中央値(p50)があります-それはクールです、私は個人的にそれが大好きです! そのような超安定-常に約2ミリ秒。 2.2〜3.5ミリ秒の小さなマージンを持つしきい値でトリガーを切断し、何か問題が発生した場合に通知を受け取るようにします。
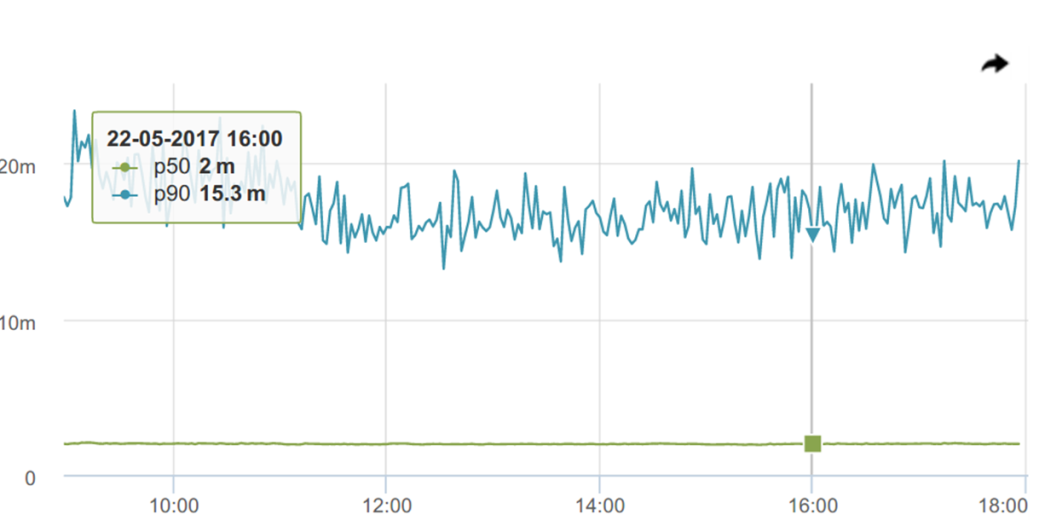
90パーセンタイルを見てみましょう。それほど安定していません
95位-そして、まったく、櫛のように。
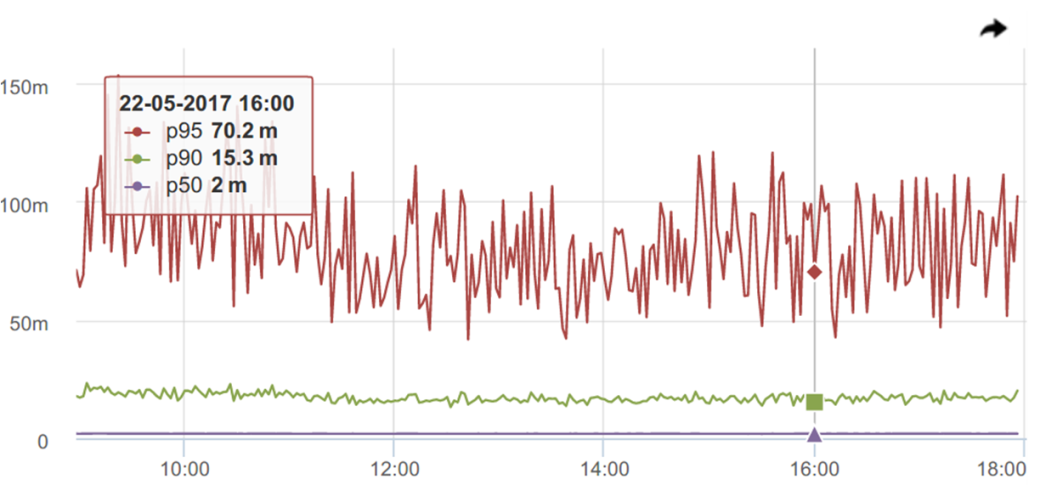
約束された、自慢のエミッションの堅牢性はどこにあるのでしょうか?! これは直観が再び私たちを欺く方法であり、「堅牢」は「安定」を意味することを示唆しています。 現実には、すべてはそうではありません。
パーセンタイルの(カウンター)直感的な感覚についての話を続けて、別のグラフを見てみましょう。
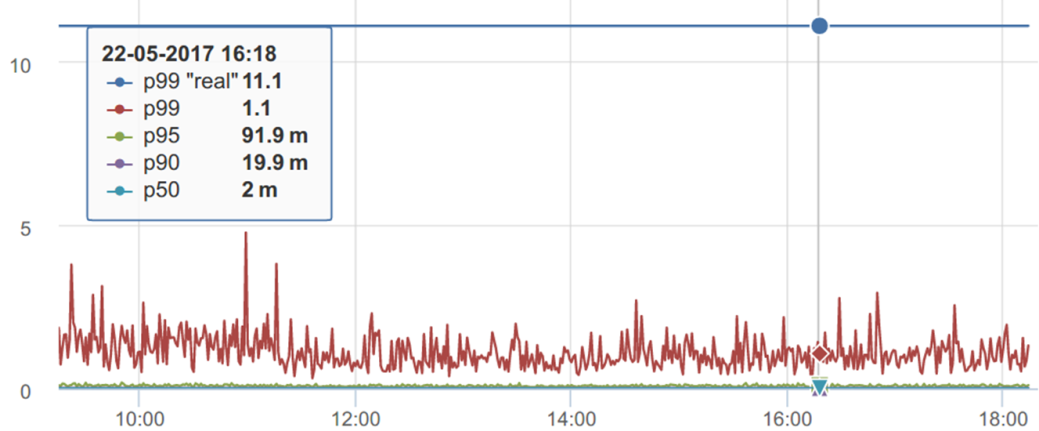
このグラフでは、p99は1秒から2〜3秒の範囲にあるようです。 そして、その本当の価値Noは1.1sの周りのどこかにあるはずです
しかし、この期間に蓄積されたすべてのデータに対してp99を計算すると、p99の「実際の」場所はまったく異なる場所にあることがわかります。その差は10倍です。 どうして?
まず、間隔ごと(この場合は1分ごと)にパーセンタイルを測定します。 1日で、1440分ごとの測定が実行されます。 このグラフを作成し、泳いでいないことがわかった場合、脳はそのグラフの水平方向の傾向を自動的に計算します。 「だから、これはパーセンタイルです-おそらくそれから最大値を取得する必要があります。5s前後のどこかになります」-とにかく、実際にはそこにありません。
この分布を取得して統計をコンパイルしようとすると、計算しているパーセンタイルが時間の経過とともに測定値を追加することから変化を停止する(またはほぼ停止する)場合、予想どおりではなく、2倍高いことがわかります。
頭は特定の水平レベルを計算し、パーセンタイルの動作は異なります。
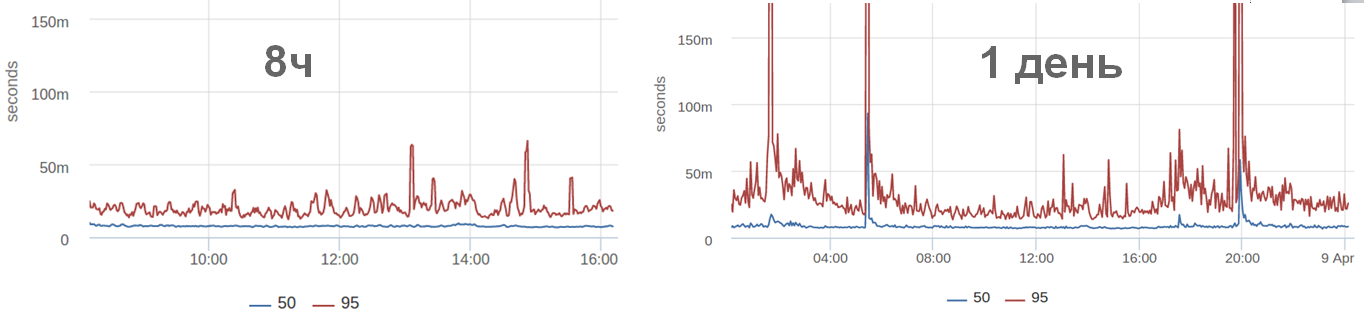
たとえば、8時間のスケジュールを見て、何も特別なことは発生せず、夜間に排出が発生しました。 多くの場合、夜に表示されるリクエストが少なくなります(この特定のケースでは)。 そして、すべてがより速く動作するようです。 また、パーセンタイルの観点から見ると、すべてが必ずしも高速ではなく、好きなように機能します。 本当に速いのですが、たとえばコールドキャッシュが存在する可能性があるため、戻りが遅いためです。
ナインの数に戻りましょう。
私たちは何を忘れていましたか、ユーザーはどうですか?
キューイングシステム、リクエスト、サービス、パーセンタイルについて議論している間、実際のユーザーを失いました。 ユーザーはリクエストではなく、人です。 彼らはサイト(またはモバイルアプリケーション)でローミングし、中間ステップ(多くの場合1を超える)を介してそこで何かを実行したいと考えています。
- セッションは長時間続きます。
- サービスの応答性の一般的な印象。
- 1つの悪い応答時間は非常に影響力があります。
- 重要なAjaxおよびその他のリソース。
セッションの各ユーザーには、独自の表示深度があります。 しかし:
- 1ページがp99よりも良い確率は99%です。
- Nページがp99より悪くない確率は(0.99N)* 100%です。
- p99より悪いものにつまずいたユーザーの数は(1-(0.99N))* 100%です。
- p99およびN = 10の場合、10%です。
- p99.9およびN = 20の場合、2%です
99パーセンタイルを監視した場合、スコア付けしたユーザーの1%しか残っていないと考えています。 しかし、再び、すべてがそうではなく、これは10%にもなります!
そして、すでにデータベース、またはある種のWebサービス、またはアプリケーションサーバーに直接送られている個々のサブクエリのレイテンシについて話すと、この比率はさらに大きくなります。
したがって、多くの場合、99.9%では十分な「高」パーセンタイルではないため、これをガイドする必要があります。
おわりに
統計学者ならだれでも「統計の直観を信用しないでください!」と言うでしょう。
私はあなたに言います: 「監視において直感を信じないでください!」

連絡先
HabrahabrのPavel Trukhanov- @ tru_pablo
会社のブログとokmeter.ioサービス自体 。
質疑応答
「ほぼ同じ問題があります。」 質問-監視のしきい値を選択する方法は? グラフの95パーセンタイル、99パーセンタイルを見ると、そこにピークがあります。 プロダクトオーナーが「ほぼ常に応答時間をどれだけ約束できるか」と尋ねたとしましょう。 そして99番目はどうですか?”-“ 40秒”-“なに?!”
それと一緒に暮らすことはまったく不可能です。 つまり、40秒置いた場合、これは監視ではなく、ゴミです。 300ミリ秒を入力すると、1時間あたり100アラートを受け取ります。
問題はどのように生きるか?
まず、 プロダクトオーナーは、パーセンタイルが何であるかを理解していることを応援します。なぜなら、私のプロダクトオーナーは、 「そのようなパーセンタイル、そのような、そのような時間」、1つの数字が理解できる、2数字はすでに終わっています!
質問に戻ります。 答えは正直で非常に簡単です-あなたはこれにそれほど時間を費やす必要はありませんでした。 自分で穴を掘ったので、 プロダクトオーナーがパーセンタイルグラフを見る(またはこの質問をする)機会があります。 あなたはそれに陥り、あなたがそれに陥ってはならない方法を私に尋ねます。 自分のために穴を掘らないでください-あなたはそれに陥ることはありません。
パーセンタイルに従う必要はありません-これは間違っています。 Okmeterでは、パーセンタイル動作ではなく、必要と思われるもののしきい値を選択することをお勧めします。 たとえば、サイトがすぐに(またはゆっくりと)開いたときにユーザーの気分を良くするため。
もちろん、サービス自体から開始される100万のパラメーターに依存します。 しかし同時に、業界のリーダーからのガイドラインがあります。 Googleによると、 サーバー時間は400ミリ秒で十分です。 Amazonは、400を超える100ミリ秒の遅延により、 コンバージョン率が9%低下すると説明しています。 しかし、私の意見では、このシステムの所有者であるあなたは、そのような状況ではユーザーがそのような時間にページを表示する必要があると判断しなければなりません。
次に、パーセンタイルを描画しません。 監視のパーセンタイルは悪です!
それらを描くと、あなたは内部的な考慮事項(または外部のGoogle)を使用する代わりに、そのようなしきい値まで機能するはずだと言って、グラフを見始めます:
-見て、50ミリ秒のこのタイプのページが応答しています!
-とても良い! そのようなしきい値を設定しましょう!
いいえ、これをしないでください! サーバーが400ミリ秒を担当することを決定します。 それからあなたは引きます-彼はそのようなパーセントで400ミリ秒を担当しました。 さらに悪いことに、まだ耐えることができます。 そして、それは1秒以上です-これはすべて適切ではありません!
その後、それを追跡でき、保証された時間について尋ねられるような問題はありません。
はい、ITシステムは対数正規のように振る舞います。 実際、このテールは通常よりも厚く、対数正規分布よりも遠くにあることがよくわかります(多くの顧客からの統計があります)。
これは典型的な現実の状況です-すべての人ではなく、多くの人にとって。
「朝にコニャックを飲むのをやめましたか?」という質問に答えたら、答える必要はありません。 「保証されたサーバー応答時間はどのくらいですか?」と尋ねられたら、そのような保証された時間はありません。 サーバーがクラッシュし、データセンターが燃え尽き、met石が落ちました。サーバーの応答時間は修復中の2日間です。
答えは箱から出してすぐです。 パーセンタイルの枠組み内で正直に答えることは不可能です。
-問題は、監視に関するものです。 何が起こっているかを理解するためのさまざまな分析があります。 古典的なモデル-50、90、99パーセンタイルなどを構築できます。 質問-どの視覚化ツールをお勧めしますか- オープンソースではなく、オープンソースですか? 時間の傾向の分析、つまり一致、他の何かを見つける方法は?
質問を正しく理解している場合。 事後分析について本当に話している場合、現時点ではグラフィックスは必要ありません。 モニタリングはモニタリング、 死後は死後です。 これらは異なるものです。
もちろん、いつものように、すべてがそこにあり、すべてを表示し、すべてを保存するシステムから銀の弾丸を持ちたいと思います-事後にすべて見ることができます。 しかし、これは非現実的です-それはまったく異なるシステムです。 ニンニクの場合、そのような答え。
-パーセンタイルと平均に加えて、他に興味深い数学的指標とグラフを提供できますか? たとえば、食品会社のサイトでは、サイトからの回答はカウントされません。
彼らは私の耳に私に言う-シグマ。 しかし、私はいつものようにそれについて言うのを忘れていました。
私はすでに誰もが知っている鐘を見せました。 3シグマで0.1になるようにカットできるこれらのアイデアは、システムとは無関係です。 もちろん、標準偏差の考え方は、どの分布にも当てはまります。 - .
, , — , 25- 75- .
— . , . — . . .
— Product Owner' , ? , Amazon . , 100 , , . .
, :
— , - StatsD , - . !
— , — , !
, .
, . , : LD50 ( lethal dose ) — , .
— , . , , . , .
— , , , . : — , — .
, - — , ? ? , — , ?
, okmeter , real-time . .
— , , , — , , .
, . 99,9% , - - , .
, , . - (99,9 99,999), .
, !
2 :
- . , — “ , , , ! ”.
- — — , — 99,9-! — !
— - — . - , , , . ? , , .
— — - , ?
Apdex score , — , 4 , .
, ? ? , , , ?
— , , , , .
, .
— - — 300-400 , . ?
— , . .
それと一緒に暮らすことはまったく不可能です。 つまり、40秒置いた場合、これは監視ではなく、ゴミです。 300ミリ秒を入力すると、1時間あたり100アラートを受け取ります。
問題はどのように生きるか?
まず、 プロダクトオーナーは、パーセンタイルが何であるかを理解していることを応援します。なぜなら、私のプロダクトオーナーは、 「そのようなパーセンタイル、そのような、そのような時間」、1つの数字が理解できる、2数字はすでに終わっています!
質問に戻ります。 答えは正直で非常に簡単です-あなたはこれにそれほど時間を費やす必要はありませんでした。 自分で穴を掘ったので、 プロダクトオーナーがパーセンタイルグラフを見る(またはこの質問をする)機会があります。 あなたはそれに陥り、あなたがそれに陥ってはならない方法を私に尋ねます。 自分のために穴を掘らないでください-あなたはそれに陥ることはありません。
パーセンタイルに従う必要はありません-これは間違っています。 Okmeterでは、パーセンタイル動作ではなく、必要と思われるもののしきい値を選択することをお勧めします。 たとえば、サイトがすぐに(またはゆっくりと)開いたときにユーザーの気分を良くするため。
もちろん、サービス自体から開始される100万のパラメーターに依存します。 しかし同時に、業界のリーダーからのガイドラインがあります。 Googleによると、 サーバー時間は400ミリ秒で十分です。 Amazonは、400を超える100ミリ秒の遅延により、 コンバージョン率が9%低下すると説明しています。 しかし、私の意見では、このシステムの所有者であるあなたは、そのような状況ではユーザーがそのような時間にページを表示する必要があると判断しなければなりません。
次に、パーセンタイルを描画しません。 監視のパーセンタイルは悪です!
それらを描くと、あなたは内部的な考慮事項(または外部のGoogle)を使用する代わりに、そのようなしきい値まで機能するはずだと言って、グラフを見始めます:
-見て、50ミリ秒のこのタイプのページが応答しています!
-とても良い! そのようなしきい値を設定しましょう!
いいえ、これをしないでください! サーバーが400ミリ秒を担当することを決定します。 それからあなたは引きます-彼はそのようなパーセントで400ミリ秒を担当しました。 さらに悪いことに、まだ耐えることができます。 そして、それは1秒以上です-これはすべて適切ではありません!
その後、それを追跡でき、保証された時間について尋ねられるような問題はありません。
はい、ITシステムは対数正規のように振る舞います。 実際、このテールは通常よりも厚く、対数正規分布よりも遠くにあることがよくわかります(多くの顧客からの統計があります)。
これは典型的な現実の状況です-すべての人ではなく、多くの人にとって。
「朝にコニャックを飲むのをやめましたか?」という質問に答えたら、答える必要はありません。 「保証されたサーバー応答時間はどのくらいですか?」と尋ねられたら、そのような保証された時間はありません。 サーバーがクラッシュし、データセンターが燃え尽き、met石が落ちました。サーバーの応答時間は修復中の2日間です。
答えは箱から出してすぐです。 パーセンタイルの枠組み内で正直に答えることは不可能です。
-問題は、監視に関するものです。 何が起こっているかを理解するためのさまざまな分析があります。 古典的なモデル-50、90、99パーセンタイルなどを構築できます。 質問-どの視覚化ツールをお勧めしますか- オープンソースではなく、オープンソースですか? 時間の傾向の分析、つまり一致、他の何かを見つける方法は?
質問を正しく理解している場合。 事後分析について本当に話している場合、現時点ではグラフィックスは必要ありません。 モニタリングはモニタリング、 死後は死後です。 これらは異なるものです。
もちろん、いつものように、すべてがそこにあり、すべてを表示し、すべてを保存するシステムから銀の弾丸を持ちたいと思います-事後にすべて見ることができます。 しかし、これは非現実的です-それはまったく異なるシステムです。 ニンニクの場合、そのような答え。
-パーセンタイルと平均に加えて、他に興味深い数学的指標とグラフを提供できますか? たとえば、食品会社のサイトでは、サイトからの回答はカウントされません。
彼らは私の耳に私に言う-シグマ。 しかし、私はいつものようにそれについて言うのを忘れていました。
私はすでに誰もが知っている鐘を見せました。 3シグマで0.1になるようにカットできるこれらのアイデアは、システムとは無関係です。 もちろん、標準偏差の考え方は、どの分布にも当てはまります。 - .
, , — , 25- 75- .
— . , . — . . .
— Product Owner' , ? , Amazon . , 100 , , . .
, :
— , - StatsD , - . !
— , — , !
, .
, . , : LD50 ( lethal dose ) — , .
— , . , , . , .
— , , , . : — , — .
, - — , ? ? , — , ?
, okmeter , real-time . .
— , , , — , , .
, . 99,9% , - - , .
, , . - (99,9 99,999), .
, !
2 :
- — 99- — 40 . ! , ! ( sarcasm)
- point , — , .
- . , — “ , , , ! ”.
- — — , — 99,9-! — !
— - — . - , , , . ? , , .
— — - , ?
Apdex score , — , 4 , .
, ? ? , , , ?
— , , , , .
, .
— - — 300-400 , . ?
— , . .
監視の問題をDevOpsの他の側面と一緒に議論するために、RIT ++ フェスティバルで別のRootConf会議があります。新旧のスピーカーを歓迎し、あなたのアプリケーションを楽しみにしています。チケットも販売されていますが、これまでのところ盲目的に-プログラムなしで。