はい、Node.jsでサーバーを作成できますが、バックエンド開発では、.netが議論の余地のないリーダーです。 私の意見では、jsでは、柔軟で簡単にサポートされるバックエンドを書くことは非常に困難ですが、多くの人は私に反対するかもしれません。
このチュートリアルの後、Web開発者とバックアップ開発者が敵エリアで足元を見つけ、より詳細な調査を行う方法を理解しやすくなることを願っています。 行こう!
だから私たちは必要です
1. Visual Studio 2017(.NET Coreクロスプラットフォーム開発のインストール時にチェックマークを付けます)。 サーバーを.netコア2.0に書き込むので、スタジオが正確に必要です> = 2017 2015スタジオでのサポートはバージョン1.1で終了しました
2. Node Package Manager(NPM)がインストールされたNode.js。 プロジェクトのNode.jsは、2つのWeb開発開発ツール(Webpack(クライアントコードのさまざまなクライアントコードのビルドと処理用)およびNPM(jsユーティリティ/コンポーネント/パッケージのインストール用)のみ必要です。
何を書きますか?
メインページに投稿のリストを表示し、コメント付きの別のページに移動して(コメントする機能があります)、所有者を許可し、新しい投稿を書く機会を与える、非常にシンプルなブログの開発に取り組みます。
パート1.バックエンド
バッキングは、クライアントの安らかなAPIのセットになります。msmslベースを使用します。 データベースを操作するには-EntityFramework Core、Code Firstアプローチ。
空のASP.NET Core Webアプリケーションプロジェクトを作成し、将来必要なものをすべて手作業で追加します。
新しいプロジェクトでは、asp.netコアのメイン構成ファイルであるStartupクラス(Startup.csファイル)で、サービスとミドルウェアMVCを接続します(ミドルウェアチェーンとミドルウェアレイヤーを使用したユーザーリクエストの処理の詳細については、 Microsoftのドキュメントを参照してください) 。 asp.netコアでご存知のように、すべての静的コンテンツ(js / css / img)はwwwrootフォルダー(他のフォルダーが指定されていない場合はデフォルト)にある必要があります。このコンテンツをエンドユーザーに提供するには、別のミドルウェアレイヤーを登録する必要があります-呼び出し拡張メソッドUseStaticFiles。 その結果、次のコードでStartupクラスを取得します。
Startup.cs
public class Startup { public void ConfigureServices(IServiceCollection services) { services.AddMvc(); } public void Configure(IApplicationBuilder app, IHostingEnvironment env) { if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); } app.UseStaticFiles(); app.UseMvc(); } }
それでは、ビジネスロジックに取り組みましょう。 ソリューションで2つの新しいクラスライブラリ(.NET Standart)プロジェクトを作成します。
- EntityFramework Coreを介してデータベースを操作するDBRepository
- モデル。アプリケーションの日付クラスになります
そして、Modelsプロジェクトの場合はDBRepositoryに、DBRepositoryプロジェクトとModelsプロジェクトの場合はASP.NET PersonalPortalプロジェクトへの参照を追加します。
このようにして、リポジトリ、アプリケーション、およびモデルを互いに分離します。 また、将来、たとえば、DBRepositoryデータベースを操作するアセンブリを、EF Coreではなく、他のORMまたはado.netを介してデータベースで機能する別のアセンブリに置き換えることができます。 または、たとえば、リポジトリとモデルのアセンブリをWebアプリケーションではなくデスクトップに接続できます。
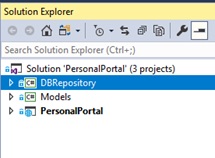
次に、Modelsプロジェクトにクラスを追加します。これは、後でデータベースのテーブルにマッピングされます。クラスダイアグラムでは、これについては詳しく説明しません。
次に、DBRepositoryプロジェクトに移動して、EF Coreと連携するために必要な2つのnugetパッケージ(Microsoft.EntityFrameworkCoreとMS SQL ServerデータベースプロバイダーMicrosoft.EntityFrameworkCore.SqlServer)をインストールします。
EFクラスのベースであるDBContextクラス(データを操作するためのエントリポイント)から継承を作成しましょう。 そして、このコンテキストを作成するファクトリー(インターフェース+実装)。 なぜ工場が必要なのか、後でわかります。
RepositoryContext.cs
public class RepositoryContext : DbContext { public RepositoryContext(DbContextOptions<RepositoryContext> options) : base(options) { } public DbSet<Post> Posts { get; set; } public DbSet<Comment> Comments { get; set; } public DbSet<Tag> Tags { get; set; } public DbSet<User> Users { get; set; } }
RepositoryContextFactory.cs
public class RepositoryContextFactory : IRepositoryContextFactory { public RepositoryContext CreateDbContext(string connectionString) { var optionsBuilder = new DbContextOptionsBuilder<RepositoryContext>(); optionsBuilder.UseSqlServer(connectionString); return new RepositoryContext(optionsBuilder.Options); } }
コードは非常に単純です。工場では、dbcontextをSQL Serverで動作するように設定し、接続文字列をデータベースに渡します(接続文字列なしで...)。 拡張メソッドUseSqlServerは、Microsoft.EntityFrameworkCore.SqlServerパッケージから提供されました。
人気のあるRepositoryパターンを使用して、最終的な消費者クラスを特にデータベースやEntityFrameworkと連携させないようにする中間クラスを作成します。
BaseRepositoryクラス、IBlogRepositoryインターフェイス、およびBlogRepositoryの実装を追加します。
BaseRepository.cs
public abstract class BaseRepository { protected string ConnectionString { get; } protected IRepositoryContextFactory ContextFactory { get; } public BaseRepository(string connectionString, IRepositoryContextFactory contextFactory) { ConnectionString = connectionString; ContextFactory = contextFactory; } }
BaseRepositoryは、その名前が示すとおり、作成したすべての中間クラスの基本クラスになります。 コンストラクターでは、接続文字列とファクトリーを使用してEFコンテキストを作成します。
BlogRepository.cs
public class BlogRepository : BaseRepository, IBlogRepository { public BlogRepository(string connectionString, IRepositoryContextFactory contextFactory) : base(connectionString, contextFactory) { } public async Task<Page<Post>> GetPosts(int index, int pageSize, string tag = null) { var result = new Page<Post>() { CurrentPage = index, PageSize = pageSize }; using (var context = ContextFactory.CreateDbContext(ConnectionString)) // 1 { var query = context.Posts.AsQueryable(); if (!string.IsNullOrWhiteSpace(tag)) { query = query.Where(p => p.Tags.Any(t => t.TagName == tag)); } result.TotalPages = await query.CountAsync(); query = query.Include(p => p.Tags).Include(p => p.Comments).OrderByDescending(p => p.CreatedDate).Skip(index * pageSize).Take(pageSize); // 2 result.Records = await query.ToListAsync(); //3 } return result; } }
BlogRepositoryクラスでは、遅滞なく、ページネーション付きの投稿のリストを取得するメソッドをすでに実装しています。
1行目で、データベースを操作するためのコンテキストを最終的に作成します。 2行目では、EFがsqlスクリプトに変換するLINQメソッドを使用して、必要なページをタグとともに取得する要求を作成します(Includeメソッドを使用)。 LINQメソッドは遅延によって実行されるため、データベース自体への呼び出しは3行目(およびCountAsync)でToListAsyncメソッドを呼び出した後にのみ行われることに注意してください。 データを受信した後、データベースを操作するコンテキストを閉じる必要があります(この場合のように、使用中に作成をラップします)。
Webアプリケーションを使用してプロジェクトに戻り、構成ファイルを追加しましょう。 作成されたファイルには、接続文字列を含むフィールドが既に含まれています。編集するだけで、現在のデータベースとサーバーを指定できます。
Startupクラスで、リポジトリおよびファクトリクラスの実装を登録します。 .NET Core IoCでは、コンテナーはそのまま使用できるため、使用しましょう。 構成ファイルにアクセスするためのStartupコンストラクター(IConfiguration構成)を追加すると、構成インスタンスはWebHostBuilderによって既に挿入されます。 次に、構成ファイルからConnectionStringを取得します。
Startup.cs
public Startup(IConfiguration configuration) { Configuration = configuration; } public IConfiguration Configuration { get; } public void ConfigureServices(IServiceCollection services) { services.AddMvc(); services.AddScoped<IRepositoryContextFactory, RepositoryContextFactory>(); // 1 services.AddScoped<IBlogRepository>(provider => new BlogRepository(Configuration.GetConnectionString("DefaultConnection"), provider.GetService<IRepositoryContextFactory>())); // 2 } public void Configure(IApplicationBuilder app, IHostingEnvironment env) { if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); } app.UseStaticFiles(); app.UseMvc(); }
1行目と2行目で、AddScopeメソッドを使用して実装を登録します。
一般に、実装を登録するには、AddScope、AddTransient、AddSingletonの3つのメソッドがあります。これらのメソッドは、登録されたインスタンスのライフタイムのみが異なります。
AddScope-クライアントからサーバーへのリクエストごとにインスタンスが1回作成されます。
AddTransient-依存関係を解決するたびに、新しいインスタンスが作成されます
AddSingleton-インスタンスは単一のインスタンスで作成され、リクエスト間で変更されません。
詳細はドキュメントをご覧ください。
ここで、APIメソッドを使用してコントローラーを作成すると、すでに手で何かを感じることができます。
コントローラー/ BlogController.cs
[Route("api/[controller]")] public class BlogController : Controller { IBlogRepository _blogRepository; public BlogController(IBlogRepository blogRepository) { _blogRepository = blogRepository; } [Route("page")] [HttpGet] public async Task<Page<Post>> GetPosts(int pageIndex, string tag) { return await _blogRepository.GetPosts(pageIndex, 10, tag); } }
IBlogRepository依存関係は、IoCコンテナーによって自動的に解決されます。
F5キーを押して、ブラウザーのURLのアドレスバーをapiメソッド-localhost:64422 / api / blog / pageにたたき込み、接続文字列を正しく変更しない限り、次の実行を取得します。
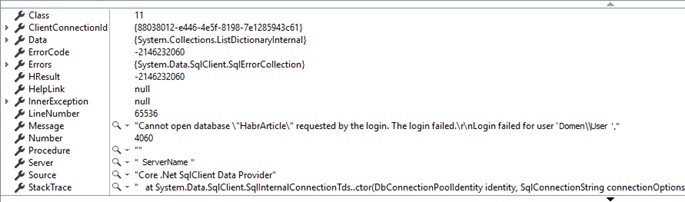
実際のところ、私たちの拠点はまだ存在しておらず、当然、EFは存在しない拠点を開くことはできません。 データベースがない場合は、EFがデータベースを作成する必要があることを何らかの方法で通知する必要があります。
データベースにアクセスする前に、単にcontext.Database.EnsureCreatedメソッドを呼び出すことができますが、多くの場合、移行メカニズムを使用します。 データスキームを変更した場合、既存のデータを失わずにデータベースに慎重に適用できます。 やってみましょう。
移行ユーティリティを機能させるには、DBContextクラス(この場合はRepositoryContextクラス)の子孫が外部からアクセス可能である必要があり、起動時の移行ユーティリティは「引き出し」て必要に応じて使用できます。 これを行うには、次のことを行う必要があります。
RepositoryContextをサービスに登録しますが、リポジトリの中間クラスを作成したためではなく、プロジェクトでコンテキストバインドを取得したくありません。
services.AddDbContext<RepositoryContext>(options => options.UseSqlServer(Configuration.GetConnectionString("DefaultConnection")));
次のインターフェースを実装する
public interface IDesignTimeDbContextFactory<out TContext> where TContext : DbContext { TContext CreateDbContext([NotNullAttribute] string[] args); }
最後のオプションを選択します。
コンテキストを作成するための別のファクトリーを混乱させないでください。これは移行ユーティリティにのみ必要です。
そのため、インターフェイスを実装します。
DesignTimeRepositoryContextFactory.cs
public class DesignTimeRepositoryContextFactory : IDesignTimeDbContextFactory<RepositoryContext> { public RepositoryContext CreateDbContext(string[] args) { var builder = new ConfigurationBuilder() .SetBasePath(Directory.GetCurrentDirectory()) .AddJsonFile("appsettings.json"); var config = builder.Build(); var connectionString = config.GetConnectionString("DefaultConnection"); var repositoryFactory = new RepositoryContextFactory(); return repositoryFactory.CreateDbContext(connectionString); } }
実装は非常に簡単です。設定から接続文字列を取得し、DBContextを作成して返します。
Powershellコンソールを開き、DBRepositoryプロジェクトを選択して、移行を追加します。
Add-Migration InitialCreate -Project DBRepository
これで、移行が作成され、MigrationsフォルダーがDBRepositoryプロジェクトに追加されました。これには、自動生成されたクラスと移行の増分のUpメソッド、減分のDownメソッドを持つ新しいファイルが含まれます。
前のチームでは、プロジェクトでクラスを作成しただけでしたので、移行をベースに適用する必要があります。
Update-Database

コードにデータベースへの自動アプリケーションを作成して、次の移行中に毎回手動でUpdate-Databaseコマンドを呼び出さないようにし、コードを引き続き使用するユーザーがすべての移行を適用してデータベースを作成できるようにします。
Program.csファイルに移動して、次の大事な行を書きましょう。
Program.cs
public static void Main(string[] args) { var host = BuildWebHost(args); var builder = new ConfigurationBuilder() .SetBasePath(Directory.GetCurrentDirectory()) .AddJsonFile("appsettings.json"); //1 var config = builder.Build(); // 1 using (var scope = host.Services.CreateScope()) //2 { var services = scope.ServiceProvider; var factory = services.GetRequiredService<IRepositoryContextFactory>(); factory.CreateDbContext(config.GetConnectionString("DefaultConnection")).Database.Migrate(); // 3 } host.Run(); } public static IWebHost BuildWebHost(string[] args) => WebHost.CreateDefaultBuilder(args) .UseStartup<Startup>() .Build();
1行目で構成を作成し、2行目で新しいスコープを作成してRepositoryContextFactoryのインスタンスを取得します(スコープライフタイムで登録したことを覚えていますか?スコープなしではインスタンスはありません)、3行目でDBContext.Database.Migrate()メソッドデータベースにまだないすべての移行をベースにロールします。 そして、まだベースがないときにこれが最初の呼び出しである場合、それを作成します。 次に、使い捨てスコープ 彼はもう必要ありません。
また、移行メカニズムは、どの移行がデータベースに既に存在し、どの移行がまだ存在していないかをどのように知るのですか? すべてが非常に簡単です。 実行されると、__ EFMigrationsHistoryテーブルが作成され、適用されたすべての移行の名前が記録されます。
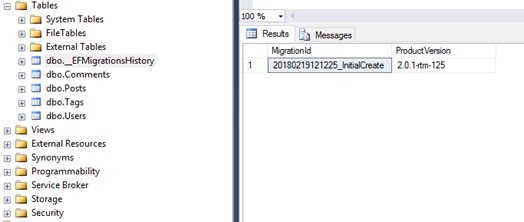
次の移行が類推によって追加されます-モデル日付に変更が加えられ、Add-Migration <migration_name>コマンドが実行され、ユーティリティは新しい変更を以前の移行のスナップショットと比較し、移行の結果で新しいクラスを生成します。
この段階でバックエンドを実際に把握しましたが、フロントに行くことができますが、ジレンマに直面しています-フロントを別のプロジェクトで開発し、後で個別にホストするか、Web APIと同じプロジェクトに残して、もちろん開発を促進します展開。 また、Visual Studioには、Microsoft.AspNetCore.SpaServices nugetパッケージを使用して、Webpackのルーティングやビルドなどの日常的な作業をミドルウェアマジックに変える既製のテンプレートが既にあります。
最初のオプションは確かに柔軟性が高く、Webとバックアップを別々に展開し、異なる環境で開発することができますが、2番目のオプションには存在する権利もあります。この場合、単純さと明快さを上回るため、努力と勇気を出します。 2つ目の簡単な方法を見てみましょう。
クライアントアプリケーション(Views / Home / Index.cshtml)のビューコンテナを作成してみましょう。ビューコンテナは、それを提供してルーティングを記述します。
Startup.cs
... app.UseMvc(routes => { routes.MapRoute( name: "DefaultApi", template: "api/{controller}/{action}"); }); ...
パート2.フロントエンド
ここでは、Visual Studioにasp.netコアと組み合わせてSPAアプリケーションを作成するためのテンプレートがあることを予約する必要がありますが、何かを理解したい場合は自分でやるという原則に沿ってガイドされます。 さらに、私の意見では、そのテンプレートはいくぶん冗長であり、そこから多くを削除する必要があります。
Webプロジェクトを作成します。 コマンドラインを開き、スタジオで作成された.netコアWebアプリケーションがあるフォルダーに移動し、npm initコマンドを実行します。 ユーティリティが要求する多くのパラメーターを入力するか、単にEnterキーを押すと、Web用の「* .csproj」に相当するpackage.jsonファイルが出力されます。
次に、今後の開発に必要な多くのnpmパッケージをダウンロードする必要があります。 npm i <package_name> [--save-dev]コマンドを実行して各パッケージを個別にインストールするか、プロジェクトファイルにすべての依存関係をすぐに書き込んでnpm installを実行できます。 記事の時間とスペースを節約するために、package.jsonにすべての依存関係を指定します。
package.json
{ "name": "personalportal", "version": "1.0.0", "description": "", "main": "index.js", "scripts": { "test": "echo \"Error: no test specified\" && exit 1" }, "author": "", "license": "ISC", "devDependencies": { "babel-core": "^6.26.0", "babel-loader": "^7.1.2", "babel-preset-env": "^1.6.0", "babel-preset-es2015": "^6.24.1", "babel-preset-react": "^6.16.0", "babel-preset-stage-0": "^6.24.1", "aspnet-webpack": "^2.0.3", "css-loader": "^0.28.7", "file-loader": "^1.1.6", "style-loader": "^0.19.1", "webpack": "^3.11.0" }, "dependencies": { "babel-polyfill": "^6.26.0", "isomorphic-fetch": "^2.2.1", "query-string": "^5.0.1", "react": "^16.2.0", "react-dom": "^16.2.0", "react-redux": "^5.0.6", "react-router-dom": "^4.2.2", "redux": "^3.7.2", "redux-thunk": "^2.2.0" } }
このファイルには、標準で生成されたフィールドに加えて、devDependenciesと依存関係の2つのセクションがあります。これは、配置するパッケージのリストです。 1つのセクションと他のセクションの違いは、devDependenciesセクションでは、アプリケーションの構築にのみ必要なパッケージ(さまざまなローダー、プリローダー、コンバーター、パッカー)、および依存関係セクションでは、開発に必要なパッケージを指定することです。コードを書くために使用します。
パッケージについて簡単に説明します。
- Babel- *パッケージが必要です。まず、Reactコンポーネントを記述するときにjs関数の鈍い呼び出しの代わりにjsx構文を使用し(以下、フロントパートを記述するときにjsx構文とは何かを理解します)、次に、目を楽しませ、js構文を使用し、古い(理由のある)ブラウザとの互換性について心配する必要はありません。
- webpackパッケージは、Webアプリケーションのメインであり、非常に強力なビルドツールです。
- Reactで開発するためのReact / react-domパッケージ。
- SPAアプリケーションでのクライアントルーティング用のreact-router-domパッケージ。
- redux / react-redux / redux-thunk-フロントパーツのアーキテクチャを整理するためのパッケージ。
- 同形フェッチ、クエリ文字列は、クエリブラウザ文字列とサーバークエリの操作を簡素化する便利なパッケージです。
npm installコマンドを実行した後、Webアプリケーションを含むディレクトリにnode_modulesフォルダーを作成し、すべての登録済みパッケージとその依存関係がそこにダウンロードされます。 package-lock.jsonファイルも、すべての依存関係の説明とともに作成する必要があります。
Visual Studioはこれらのパッケージを表示し、[依存関係]タブの下に表示するはずです。
次に、Startup.csファイルに移動して、上記のミドルウェアマジックを記述します。 これを行うには、Microsoft.AspNetCore.SpaServicesパッケージをインストールするか、Microsoft.AspNetCore.Allパッケージに既に含まれている必要があります。
Startup.cs
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory) { if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); app.UseWebpackDevMiddleware(); // 1 } app.UseStaticFiles(); app.UseMvc(routes => { routes.MapRoute( name: "DefaultApi", template: "api/{controller}/{action}"); routes.MapSpaFallbackRoute("spa-fallback", new { controller = "Home", action = "Index" }); // 2 }); }
1行目では、webpackサポートを有効にします。クライアントリソースをアセンブルするのに苦労することはなく、毎回手動で起動したり、PostBuildEventsのどこかに登録したり、webpack –watchを実行してコンソールウィンドウを開いたりする必要はありません この行を使用して、ファイル内の変更を追跡し、インクリメンタルビルドを実行するWebpackインスタンスをメモリ内に作成します。
2行目では、クライアントルーティングのサポートを有効にします。 この行が解決する問題を簡単に説明しようと思います。 ご存じのとおり、SPAの哲学は、1つのページが常にブラウザーにロードされ、新しいデータがajaxリクエストとともにロードされるというものです。 また、ブラウザのクエリ文字列で変更されるすべてのルーティングは、実際にはサーバーリソースではなく、これらのリソースへのクライアント側の「リクエストのエミュレーション」です。 ユーザーは引き続き同じページに残ります。 ユーザーが目的のリソースに順番にアクセスしても問題はありませんが、このリソースに直接アクセスすることにした場合、問題が発生します。
たとえば、アプリケーションはwww.mytestsite.comにあります。 ユーザーはwww.mytestsite.com/home/news?id=1のページで興味深いコンテンツを見つけ、友人またはガールフレンドへのリンクをドロップすることにしました。 友人はリンクを受け取り、ブラウザにコピーして404エラーを受け取ります。 ここでの問題は、サーバーに物理的にこのリソースがなく、WebサーバーがこのURLをルーティングする方法を知らないことです。これは、SPAアプリケーションがあり、クライアントルーティングが編成されているためです。
したがって、Startup.csの2行目は、このようなすべてのリクエストのページをコンテナに提供し、クライアントに到着し、アプリケーションは既にクライアントでクライアントをルーティングしています。
次に、webpackがさまざまなプリプロセッサを使用してアプリケーションを構築するためのガイドとなるwebpackの設定ファイル(webpack.config.js)を作成する必要があります。 package.jsonがある同じ場所で作成してみましょう。
webpack.config.js
'use strict'; const webpack = require('webpack'); const path = require('path'); const bundleFolder = "./wwwroot/assets/"; const srcFolder = "./App/" module.exports = { entry: [ srcFolder + "index.jsx" ], devtool: "source-map", output: { filename: "bundle.js", publicPath: 'assets/', path: path.resolve(__dirname, bundleFolder) }, module: { rules: [ { test: /\.jsx$/, exclude: /(node_modules)/, loader: "babel-loader", query: { presets: ["es2015", "stage-0", "react"] } } ] }, plugins: [ ] };
簡単に設定を確認します。 詳細なドキュメントについては、 公式ソースに連絡することをお勧めします 。 残念なことに、Webpack 1.x専用の優れたWebキャストスクリーンキャストもありますが、基本的なものと概念も見ることができます。
したがって、まず、ソースでwebpackエントリポイントを指定する必要があります-エントリフィールドの値、これが最愛の人です。
次に、出力で、webpackが作業の結果(バンドル)を配置する場所を示します。
devtoolでは、デバッグ時に巨大なバンドルを登らないようにソースマップを作成する必要があることを示しますが、ソースへのバインディングがあります。
最後に、モジュールセクションで、接続するローダーを指定します。 今のところ、Babelモジュールとそのプリセットのみを接続します-jsx構文の変換、es2015でES6をサポート、stage-0で新しいjs機能を使用
さて、これでセットアップは完了し、最終的に開発自体を開始する準備が整いました。
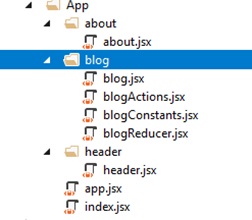
asp.netコアアプリケーションのルートにAppディレクトリを作成し、index.jsxファイルを追加します。 ソリューションエクスプローラーで失っていない画面を以下に示します。
index.jsxでは、次のように記述します。
index.jsx
import React from 'react' //1 import { render } from 'react-dom' //2 import App from './containers/app.jsx' //3 render( <App />, document.getElementById('content') ) //4
これは、クライアントアプリケーションへのエントリポイントになります。 要するに、上位2行ではReactでの開発用にすべてをインポートし、3行目ではAppコンポーネントコンテナーをインポートします。これを以下に記述します。 4行目で、このコンポーネントをid =” content”のDOM要素でレンダリングします。
<App />のようなレコードはJSXであるため、xmlと同様にコンポーネントを操作し、jsファイルにマークアップを記述できます。 対応するbabelプリセットを処理せずに、毎回React.createElementメソッドを呼び出す必要があります。これにより、可読性が著しく低下し、コンポーネントの記述が複雑になります。
render( React.createElement(App, null, null), document.getElementById('content') )
上記のapp.jsxファイルを作成します。
app.jsx
import React from 'react'; import ReactDOM from 'react-dom'; import { BrowserRouter as Router, Route, Switch} from 'react-router-dom'; import Header from './header/header.jsx'; import About from './about/about.jsx'; import Blog from './blog/blog.jsx'; export default class App extends React.Component { render() { return ( <Router> <div> <Header /> <main> <Switch> <Route path="/about" component={About} /> <Route path="/" component={Blog} /> </Switch> </main> </div> </Router> ); } };
何がとても面白い。 最初に、エクスポートのデフォルトクラスAppがReact.Component行を拡張するときに新しいコンポーネントを宣言し、外部からアクセスできるようにエクスポートしました。
次に、クライアントルーティングを整理するために、react-router-domパッケージからコンポーネントのセットをインポートしました。ルーターはルーティングのルートコンポーネントであり、そこに他の全員を埋め込む必要があり、スイッチとルートはルーティング自体の組織です。この場合、ルートパス(www.mytestsite.comなど)にアクセスするときにBlogコンポーネントを表示し、/ aboutパス(www.mytestsite.com/about)にアクセスするときにAboutコンポーネントを表示する必要があります。
Header、About、Blogはカスタムコンポーネントです。すぐに偽物を投げましょう。app.jsxと同じディレクトリに3つのディレクトリを作成し、新しいディレクトリに新しいディレクトリを作成し、クラス名とdivのテキストを変更して次のコードをコピーして貼り付けます
about.jsx
import React from 'react'; export default class About extends React.Component { render() { return ( <div> </div> ); } };
次に、新しく作成されたheader.jsxに移動して、ナビゲーションを実行しましょう。
header.jsx
import React from 'react'; import { Link } from 'react-router-dom'; export default class Header extends React.Component { render() { return ( <header> <menu> <ul> <li> <Link to="/"></Link> </li> <li> <Link to="/about"> </Link> </li> </ul> </menu> </header> ); } };
Linkコンポーネントを除いて、ここでは新しいものはありません。コンポーネントは、サーバーに送信しないリンクを生成しますが、ブラウザのクエリ文字列を変更し、履歴にエントリを追加します。通常、通常のリンクのように動作しますが、ページをリロードしません。
それでは、プロジェクトを実行して、得られるものを見てみましょう。webpackの結果である最終バンドルをコンテナページIndex.cshtmlに接続することを忘れないでください
Index.cshtml
<!DOCTYPE html> <html> <head> <meta name="viewport" content="width=device-width" /> <script type="text/javascript"> constants = { getPage: '@Url.RouteUrl("DefaultApi", new {controller = "Blog", action = "page" })' } </script> <title>Index</title> </head> <body> <div id="content"> </div> <script type="text/javascript" src="@Url.Content("~/assets/bundle.js")"></script> </body> </html>

もちろん、視覚的な美しさはまだ十分ではありませんが、CSS、スタイル、写真、その他のポインティングマラソンはこの記事の範囲に含まれていません。
リンクをクリックして、ページがリロードされないことを確認し、ブラウザーのクエリ文字列がそのURLを変更します。動作しますか?さらに進みましょう。
ここで、クライアントアプリケーションのアーキテクチャを検討し、一般に、ファイル、コンポーネントなどの場所を整理します。もちろん、このトピックで多くのコピーが破損し、多くのホリバーが合格しました。アプローチの1つは、関数(機能)を中心にファイルをグループ化するのが便利なことです。フロントエンドプロジェクトでこのルールを守りましょう。
アーキテクチャに関しては、現在人気のあるReduxを使用します。 webpackをセットアップするとき、すでに必要なすべてのパッケージ(redux、redux-thunk、react-redux)をインストールしました。 Reduxの詳細については、ドキュメントを参照してください。ロシア語への完全な翻訳があります。
それでは、ブログ、つまりフィードの出力を取り上げましょう。
ここで、Reduxのアーキテクチャについて少し説明する必要があります。アーキテクチャ全体は、アクション/レデューサー/ストア/ビューという重要な概念に基づいて構築されています。このアーキテクチャの主なアイデアは、アプリケーションの状態が1つの場所(ストア)に格納され、いわゆる純粋関数(リデューサー)のみがこの状態に影響を与えることができるということです。変更して新しい条件を返します。
次に、ビューは、ユーザーからの任意のアクションで、これらのアクションを処理するいわゆるアクションと呼ばれ(サーバー、ビジネスロジックなどへの要求を実行/受信します)、フラグと一緒に新しいデータがわかるリデューサーによって提供されますこのデータをアプリケーションの状態に適用する方法。
したがって、責任の分離と単方向のデータストリームが得られます。これは、将来の保守やテストでのカバーに便利です。
これまでのところ、これはあまり明確に聞こえないかもしれませんが、メッセージのフィードを受信/表示する例では、アーキテクチャをより詳細に分析します。
ディレクトリapp / blog /でredux-infrastructureファイルを作成します。blogActions.jsx、blogReducer.jsx、blogConstants.jsx(アクションキーの保存用)。
blogActions.jsxにアクセスして、サーバーから投稿のリストを取得するメソッドを作成しましょう。
blogActions.jsx
import { GET_POSTS_SUCCESS, GET_POSTS_ERROR } from './blogConstants.jsx' import "isomorphic-fetch" export function receivePosts(data) { return { type: GET_POSTS_SUCCESS, posts: data } } export function errorReceive(err) { return { type: GET_POSTS_ERROR, error: err } } export function getPosts(pageIndex = 0, tag) { return (dispatch) => { let queryTrailer = '?pageIndex=' + pageIndex; if (tag) { queryTrailer += '&tag=' + tag; } fetch(constants.getPage + queryTrailer) .then((response) => { return response.json() }).then((data) => { dispatch(receivePosts(data)) }).catch((ex) => { dispatch(errorReceive(err)) }); } }
getPostsメソッドを使用してデータを取得し、state.dispath()メソッドを使用して、アクションが発生し、一部のデータが結果になったことをリデューサーに通知します。この例では、アクションはrecievePostsとerrorReceiveです。GET_POSTS_SUCCESS、GET_POSTS_ERROR、これらはリデューサーがアクションを識別するための定数です。
blogConstants.jsx
export const GET_POSTS_SUCCESS = 'GET_POSTS_SUCCESS' export const GET_POSTS_ERROR = 'GET_POSTS_ERROR'
blogReducer.jsxにアクセスして、これらのアクションのアプリケーションの状態を変更するコードを作成しましょう。
blogReducer.jsx
import { GET_POSTS_SUCCESS, GET_POSTS_ERROR } from './blogConstants.jsx' const initialState = { data: { currentPage: 0, totalPages: 0, pageSize: 0, records: [] }, error: '' } export default function blog(state = initialState, action) { switch (action.type) { case GET_POSTS_SUCCESS: return { ...state, data: action.posts, error: '' } case GET_POSTS_ERROR: return { ...state, error: action.error } default: return state; } }
簡単です。reducerメソッドは現在の状態とアクションを入力として受け取ります。スイッチにより、発生したアクションを判別し、状態を変更し、その新しいコピーを返します。ご想像のとおり、initialStateがデフォルトの状態です。
わかりました、今私達はそれをすべて一緒に置き、それを働かせる必要があります。
blog.jsxファイルに移動し、マークアップを入れてreduxインフラストラクチャに接続しましょう。
blog.jsx
import React from 'react'; import ReactDOM from 'react-dom'; import { connect } from 'react-redux'; import { getPosts } from './blogActions.jsx' class Blog extends React.Component { componentDidMount() { this.props.getPosts(0); } render() { let posts = this.props.posts.records.map(item => { return ( <div key={item.postId} className="post"> <div className="header">{item.header}</div> <div className="content">{item.body}</div> <hr /> </div> ); }); return ( <div id="blog"> {posts} </div> ); } }; let mapProps = (state) => { return { posts: state.data, error: state.error } } let mapDispatch = (dispatch) => { return { getPosts: (index, tags) => dispatch(getPosts(index, tags)) } } export default connect(mapProps, mapDispatch)(Blog)
何がありますか?
1.単純なマークアップを使用したBlogクラス。初期化時に、投稿を要求して表示します。
2. mapProps関数。アプリケーションの状態を変数パラメーターにマッピングします。
3.アクションをメソッド変数にマップするmapDispath関数。
4.ブログコンポーネントクラスをreduxインフラストラクチャにラップし、マッピングされたパラメーター-this.propsに渡すconnect関数。コンポーネント自体で既に作業しています。
すべてが機能するには、react-redux Providerコンポーネントでアプリケーションをラップし、ストアアプリケーションストアを作成する必要があります。
index.jsx
import React from 'react' import { render } from 'react-dom' import { createStore, applyMiddleware } from 'redux' import { Provider } from 'react-redux' import thunk from 'redux-thunk' import App from './app.jsx' import blogReducer from './blog/blogReducer.jsx' function configureStore(initialState) { return createStore(blogReducer, initialState, applyMiddleware(thunk)) } const store = configureStore() render( <Provider store={store}> <App /> </Provider>, document.getElementById('content') )
次に、データベースにいくつかの投稿エントリを追加し、何が起こったかをテストします。
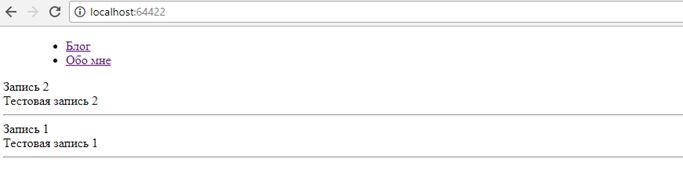
うまくいく!
残りのコンポーネントの作成は、検討したブログコンポーネントと同様に記述されているため、考慮しません。アクション/リデューサーが作成され、これらはすべて、connectメソッドによって反応コンポーネントに適用されます。
言及する価値がある唯一のことは、createStoreストレージを作成するには、1つのレデューサーを転送する必要があることですが、機能によって共通のレデューサーをレデューサーに分割することができます(ストアを正しく作成するには、後でそれらを結合する必要があります)composeReducersメソッドはこれに役立ちます。
rootReducer.jsx
import { combineReducers } from 'redux' import blog from './blog/blogReducer.jsx' import header from './header/headerReducer.jsx' export default combineReducers({ blog, header })
index.jsx
… import rootReducer from './rootReducer.jsx' function configureStore(initialState) { return createStore(rootReducer, initialState, applyMiddleware(thunk)) } …
パート3.認証
この記事で簡単に説明する最後のトピックは認証です。人気のあるJSON Web Token(JWT)認証を使用します。
操作の原理は簡単です
。1.ログインパスワードをサーバーに転送します
。2。サーバーが正しい場合、サーバーはトークンを生成します。トークンには、サーバーによる後続の承認に必要なデータが含まれ、クライアントに返します。
3.クライアントは、たとえばlocalStorageにトークンを保存し、承認を必要とする各リクエストでトークンをリクエストヘッダーに添付します。
4.サーバーはトークンの正確性、遅延を確認し、すべてが正常であればデータを返します。
asp.netコアに適切なnugetパッケージ(Microsoft.AspNetCore.Authentication.JwtBearer)を配置するか、Microsoft.AspNetCore.Allが一緒にあることを確認します。
サービスに認証を登録し、JWTトークンに基づいて認証スキームを示します。次の拡張メソッド(AddJwtBearer)が構成します。
Startup.cs
... public void ConfigureServices(IServiceCollection services) { services.AddMvc(); services.AddAuthentication(JwtBearerDefaults.AuthenticationScheme) .AddJwtBearer(options => { options.RequireHttpsMetadata = false; options.SaveToken = true; options.TokenValidationParameters = new TokenValidationParameters { ValidIssuer = "ValidIssuer", ValidAudience = "ValidateAudience", IssuerSigningKey = new SymmetricSecurityKey(Encoding.UTF8.GetBytes("IssuerSigningSecretKey")), ValidateLifetime = true, ValidateIssuerSigningKey = true, ClockSkew = TimeSpan.Zero }; }); services.AddScoped<IRepositoryContextFactory, RepositoryContextFactory>(); services.AddScoped<IBlogRepository>(provider => new BlogRepository(Configuration.GetConnectionString("DefaultConnection"), provider.GetService<IRepositoryContextFactory>())); } ...
リクエスト処理パイプラインに認証を埋め込みます。
Startup.cs
public void Configure(IApplicationBuilder app, IHostingEnvironment env, ILoggerFactory loggerFactory) { if (env.IsDevelopment()) { app.UseDeveloperExceptionPage(); app.UseWebpackDevMiddleware(); } app.UseStaticFiles(); app.UseAuthentication(); … }
APIトークン生成メソッドを追加します。GetIdentityでは、データベース(またはユーザーがいる他の場所)に移動し、すべてが問題ない場合はユーザー名/パスワードを確認し、トークンを作成してユーザーに返します。そうでない場合は401エラーを返します。
IdentityController.cs
[Route("token")] [HttpPost] public async Task<IActionResult> Token([FromBody]IdentityViewModel model) { var identity = await GetIdentity(model.Username, model.Password); if (identity == null) { return Unauthorized(); } var now = DateTime.UtcNow; var jwt = new JwtSecurityToken( issuer: AuthOptions.ISSUER, audience: AuthOptions.AUDIENCE, notBefore: now, claims: identity, expires: now.Add(TimeSpan.FromMinutes(AuthOptions.LIFETIME)), signingCredentials: new SigningCredentials(AuthOptions.GetSymmetricSecurityKey(), SecurityAlgorithms.HmacSha256)); var encodedJwt = new JwtSecurityTokenHandler().WriteToken(jwt); return Ok(encodedJwt); } private async Task<IReadOnlyCollection<Claim>> GetIdentity(string userName, string password) { List<Claim> claims = null; var user = await _service.GetUser(userName); if (user != null) { var sha256 = new SHA256Managed(); var passwordHash = Convert.ToBase64String(sha256.ComputeHash(Encoding.UTF8.GetBytes(password))); if (passwordHash == user.Password) { claims = new List<Claim> { new Claim(ClaimsIdentity.DefaultNameClaimType, user.Login), }; } } return claims; }
使用します。APIメソッドは、許可されたユーザーのみが使用できます。まあ、または属性をコントローラーに掛けることができます。
BlogController.cs
[Authorize] [Route("post")] [HttpPost] public async Task AddPost([FromBody] AddPostRequest request) { await _blogService.AddPost(request); }
クライアントでは、承認を必要とする各リクエストの前に、「Bearer」+トークンの形式でヘッダーを追加する必要があります
fetch(constants.post, { method: 'POST', headers: { 'Content-Type': 'application/json', 'Authorization': 'Bearer ' + token }, body: JSON.stringify({ header: header, body: body, tags: tags })
おわりに
この記事は予想よりもやや大きかったことが判明しましたが、それにもかかわらず、開発に必要ないくつかの重要な事項については触れていません。これは、もちろんログであり、バックとクライアントの両方にテストを記述し、これのためのライブラリ、クライアントコンポーネントのサーバー側レンダリング、CI / CDなどがあります。しかし、それでもこの記事で書いたことが誰かに役立ち、彼らのターゲットオーディエンスを見つけることを願っています。
この記事全体を書いたアプリケーションは、こちらで見ることができます。
ソースはgithubからダウンロードできます。
よろしくお願いします!