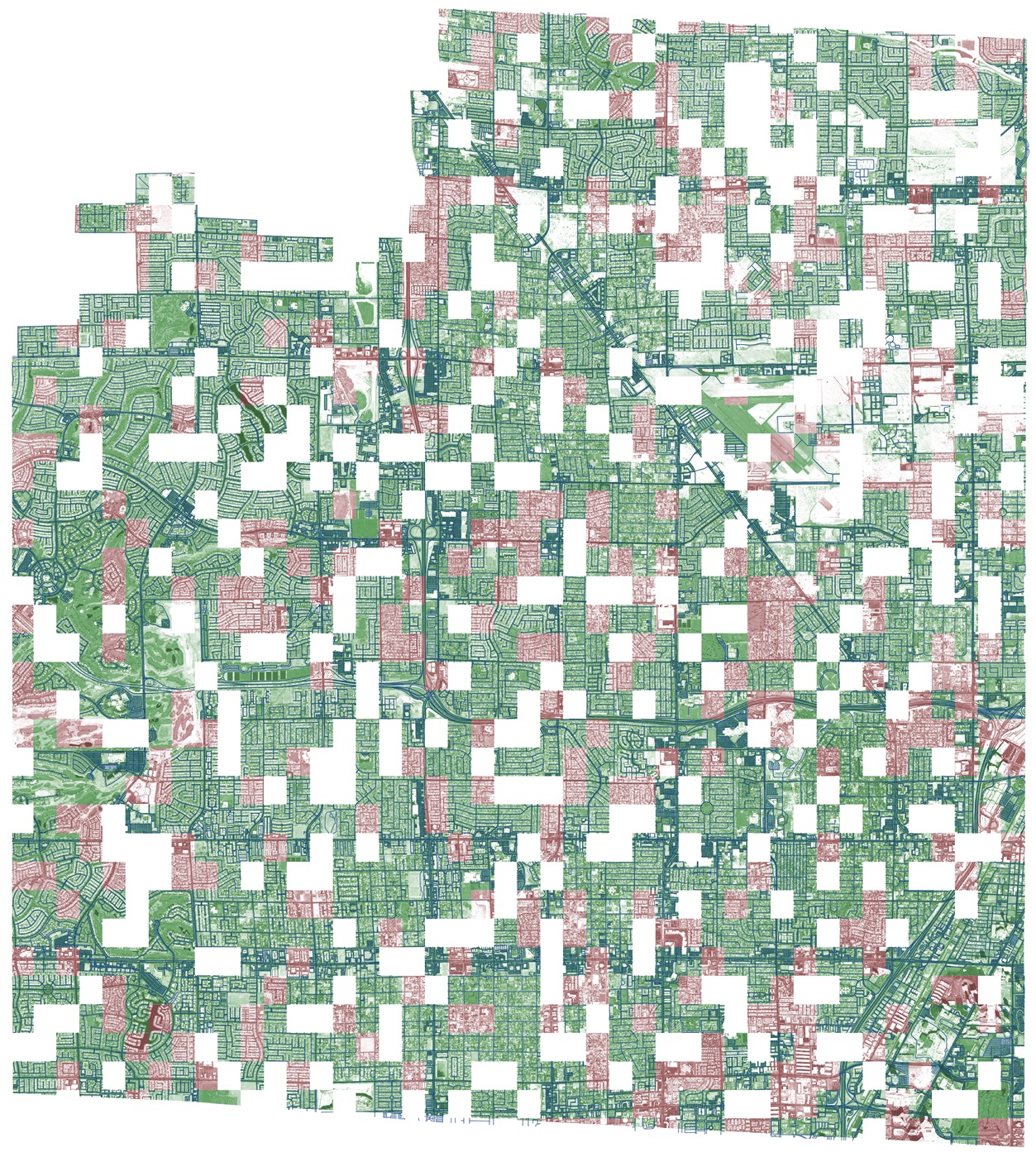
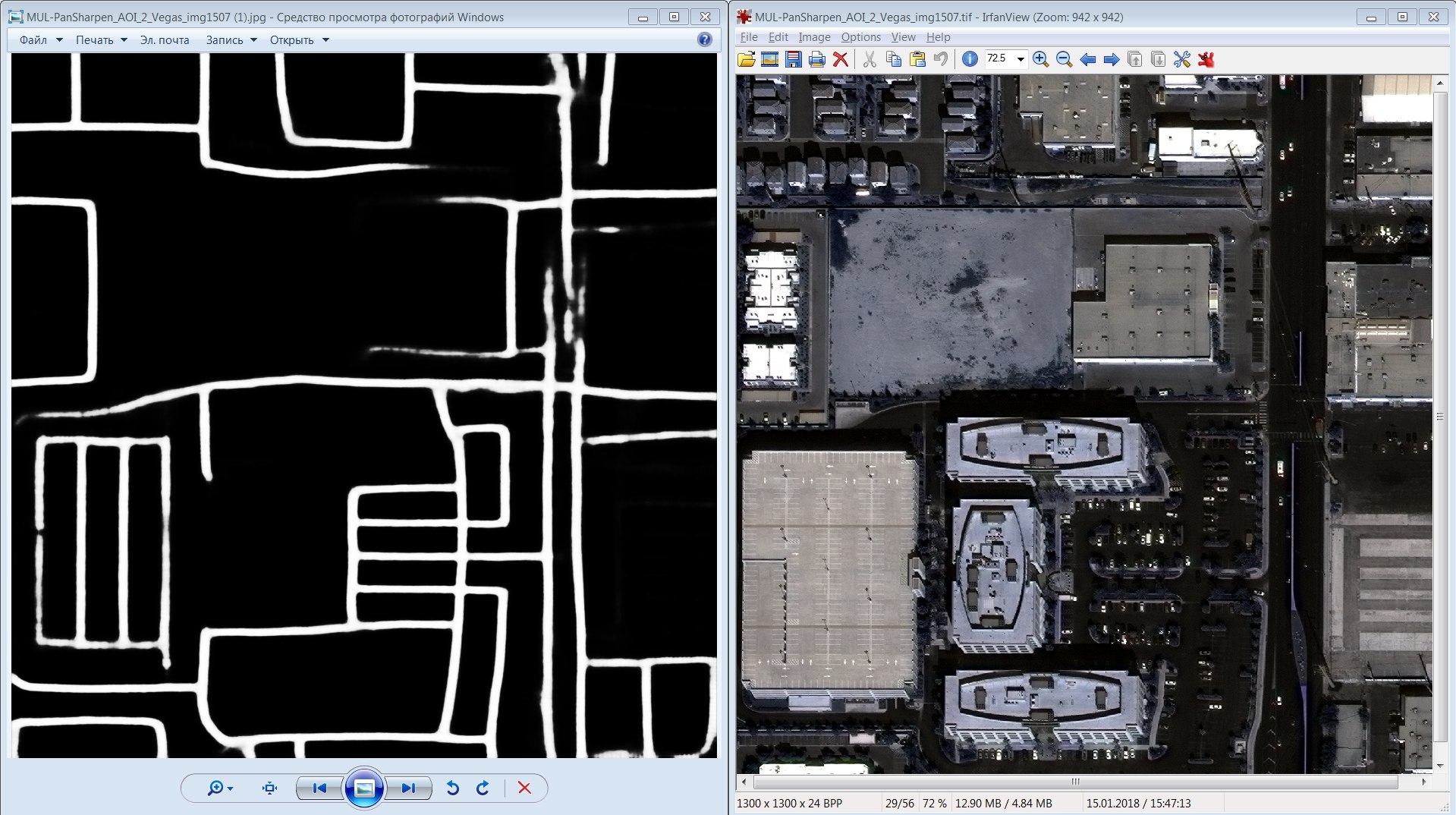
これは、提供されたマークアップ、テストデータセット、およびおそらく白い正方形を備えたVegasです。これは遅延検証(プライベート)です。 かっこいい。 確かに、このパノラマは4つの都市すべての中で最高です。それはデータのために起こりましたが、それについては以下で詳しく説明します。
0. TLDR

9位で暫定的に終了しましたが、主催者による提出物の追加テストの後に位置が変わる可能性があります。
また、 PyTorchで読み取り可能な適切なコードおよびデータジェネレーターを作成するのにも少し時間を費やしました。 あなた自身の目的のために恥ずかしがらずに使用することができます(プラス記号を付けるだけです)。 コードは可能な限りシンプルでモジュール化されており、さらにセマンティックセグメンテーションのベストプラクティスについてもお読みください。
さらに、 Skeleton Networkの理解と分析に関する投稿を書くこともできます。この投稿は、結果として、競合のトップにいるすべてのファイナリストがイメージマスクをグラフに変換するために使用しました。
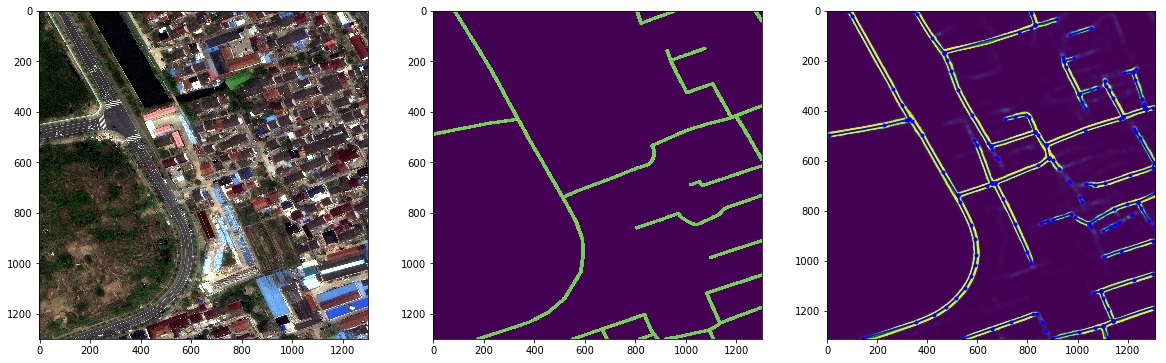
1枚の写真での競争の本質
1.競争
私の過去の記録からわかるように、私たちは時々競技に参加し( 1および2 )、そのような競技の選択基準の特定のセットを持っています-まず、適切なレベルの競技(通常、サイズに関する十分に公表されたコンテストはスタッカーの大群を引き付け、それほど難しくありません) )、第2に、トピックに対する共通の関心、第3に、課題。
この競争にはすべての基準がありました。
- 厳しい挑戦とods.aiチームが立派な対戦相手になる可能性が高い(彼らは2017年に3〜4回のサテライト大会に参加した)。
- 競争では、適切なセマンティック画像セグメンテーションを構築するだけでなく、予測されたマスクからグラフを構築することも必要でした。 これにより、混乱を招く興味深いメトリックが発生しました( 1回 、 2回 、 カブについての投稿)。 リポジトリのコードを試してみた人は、Pythonコードはリーダーボードとどういうわけか大きく異なるため、最終的には誰もがJavaで記述された視覚化ツールを使用したと言いました。
- 興味深いエリアは、豊富な情報を備えた衛星画像、さまざまなチャンネルの4つの都市からの約4000のHD画像です(主に帯域幅、8チャンネルMUL画像、 パンシャープン MUL画像、および通常のRGBの高周波放送がありました)。
- 興味深いデータ(グラフ、ジオイソン、衛星画像)と探索する新しい領域(TLDR- skimageとrasterioを使用できます-ホストが提供するリストにある他のすべてのライブラリはAWESOMEです )。 また、skimageは16ビット画像、tiff、およびその他の奇妙な形式でもうまく機能することが判明しました。
- これが良いか悪いかはわかりませんが、TopCoderプラットフォームには参加者の高度なプロ意識が必要です(すべての決定はドッキングされている必要があります。ドッキングが好きではないからです。ユニットテストも作成します)。 しかし、プラットフォーム自体は単純にひどいものであり、提供されたコードの品質は議論の余地がほとんどないように思えました。 これは私を非常に悩ませました-あなたが実際に問題を解決するのに多くの時間を費やした後、彼らはあなたにコンテストとコードのまさに説明が読みにくい非常にこのソリューションを詰め込むためにもっと時間を費やすよう頼みます。
- Kaggleは多くの投手であり、少なくとも2017年にはほとんどがビジネス指向のタスクです。
- TopCoderは時々非常に興味深く、複雑なニッチなタスクですが、全体的にプラットフォームは怖く、参加者の要件は高くなります。
- DrivenDataは最小ですが、最高です。 おもしろい分野、仕事をしていて、あなたからあまり多くを必要としない優秀な主催者。
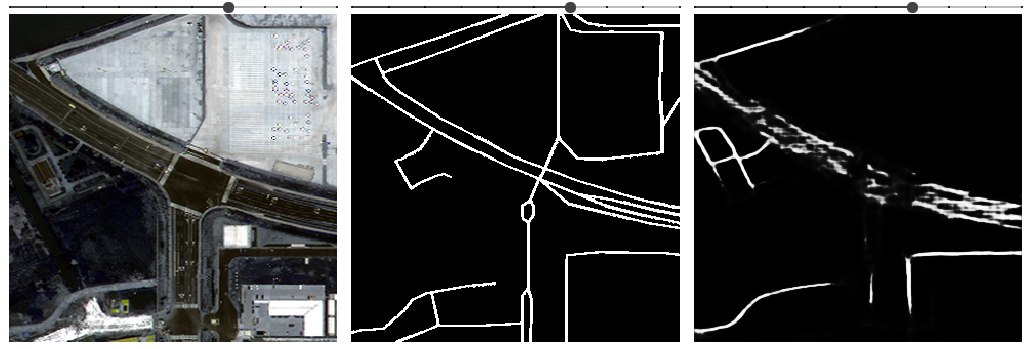
2.初期データ分析と興味深いエッジケースについてすばやく


反射率グラフでは、地面とアスファルトには実際には鋭いピークがないことがわかります。 だから私は異なるチャンネルの組み合わせをテストするのに少し時間を費やしました
上記の図で入力を確認できますが、実際に何が起こるかを説明する興味深い点と注目すべきエッジケースがいくつかあります。

元の16ビット画像のヒストグラム
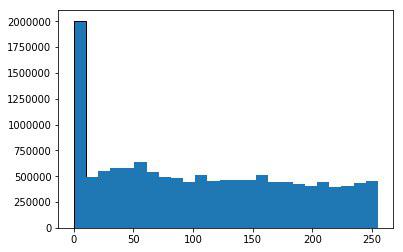
8ビット画像のヒストグラム、一部の情報が失われました
アスファルト道路とアスファルト道路

非舗装道路と交差点がある舗装道路の例

車線の組み合わせ-いくつかの12車線道路に注意してください-国境検問所では、

パリの典型的なマークアップはあまり良くない
3.便利な読書
以下は、競技中に学んだトピックに関する最高の資料のリストです。
- 衛星画像に関する基本的な情報を提供するTinkoff企業がハブに投稿
- 衛星画像チャンネルとパンシャープニングに関する情報
- この領域には、関連するページャーは1つしかありませんでした。
- セマンティック画像のセグメンテーションに関する関連作業:
- イメージマスクをグラフに変換するためのカブツール-Sknw
- アマゾンジャングルコンペティション 。 あらゆる種類の詳細と経験。 1、2、3 。
- フィッシング 一 二つ 。
- 霧の除去: ページャーといくつかのリポジトリ。 回。 2。 (動作しますが、ゆっくり)
- PyTorchに実装されたセマンティックセグメンテーションアーキテクチャ
- Carvanaコンテストの資料:
すべてのアーキテクチャと実験を要約すると、次のようなものが出てきます。
- UNET + Imagenetは悪くありませんが、LinkNetの方が優れています(わずかに精度が低下しますが、2倍高速で簡単です)。
- 転移学習が必要であり、より良い結果につながります。
- スケルトンネットワークは、マスクをグラフに変換するのに最適なツールですが、カスタマイズが必要です。
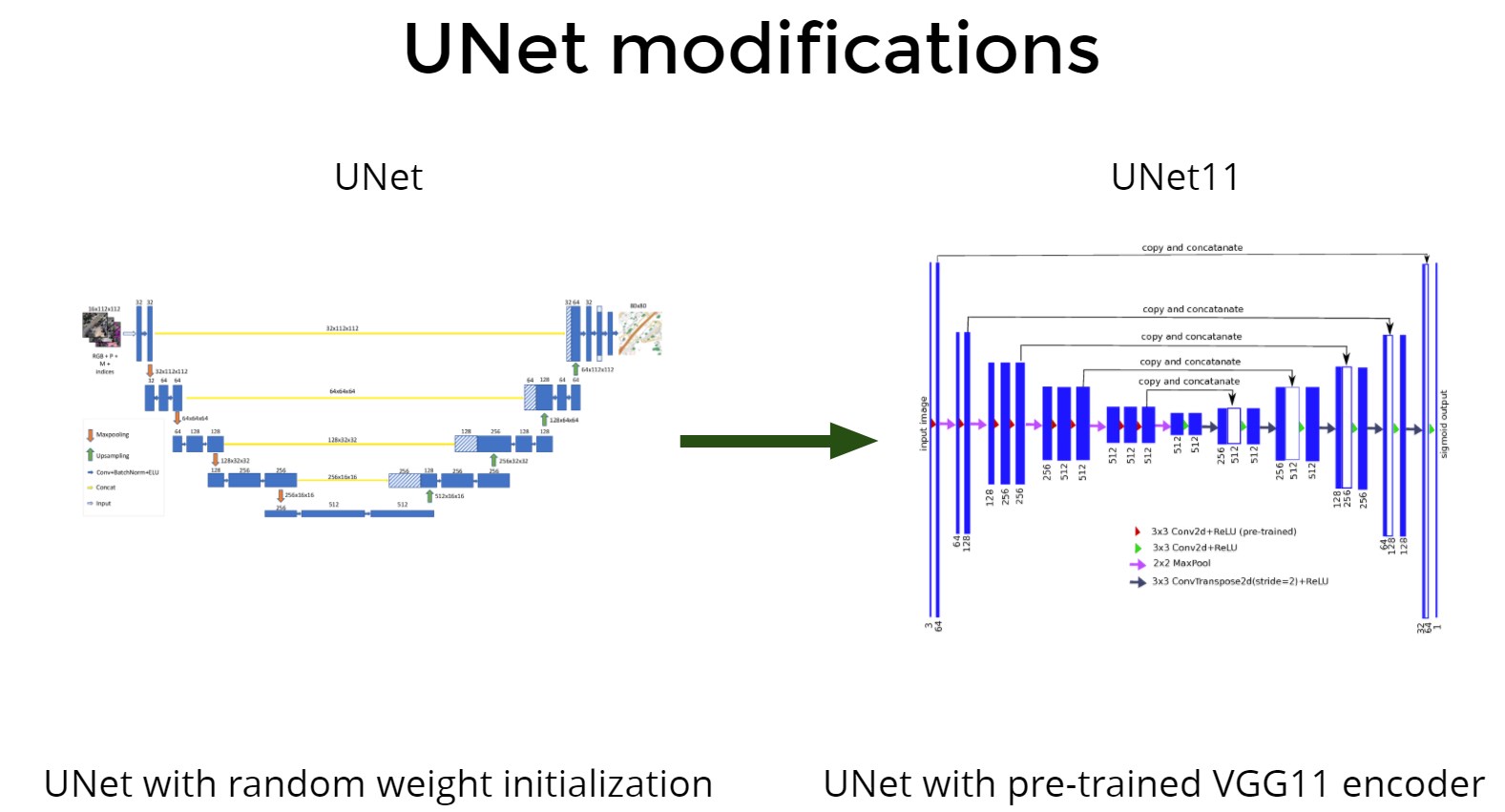
Unet +転送学習
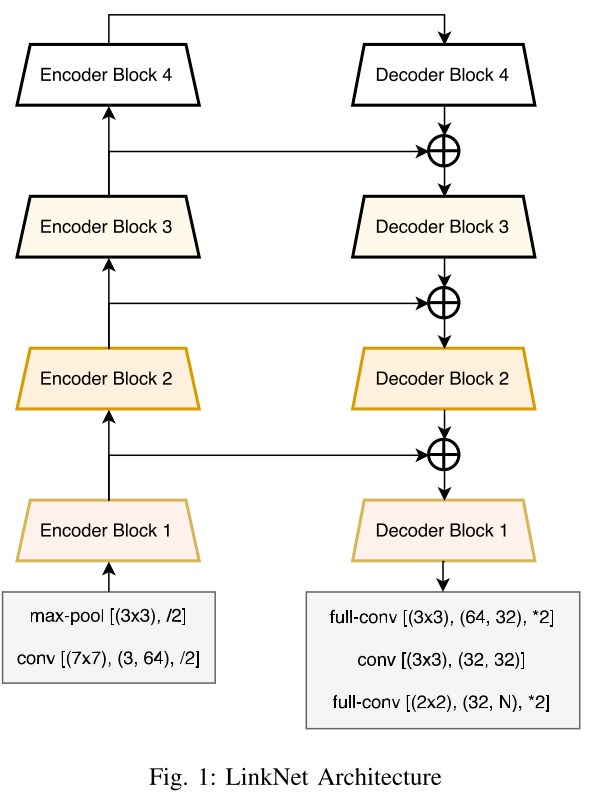
LinkNet
一部の科学者はまだMSEを使用しています...
4.初期アーキテクチャオプションとジャム
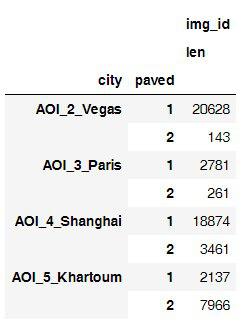
リーダーボード上のポイントは、約900のテスト画像に対して0からほぼ900kで始まり、各画像に0〜1が割り当てられました。パリの速度が大幅に低下したため、最終メトリックは都市間の平均と見なされました。
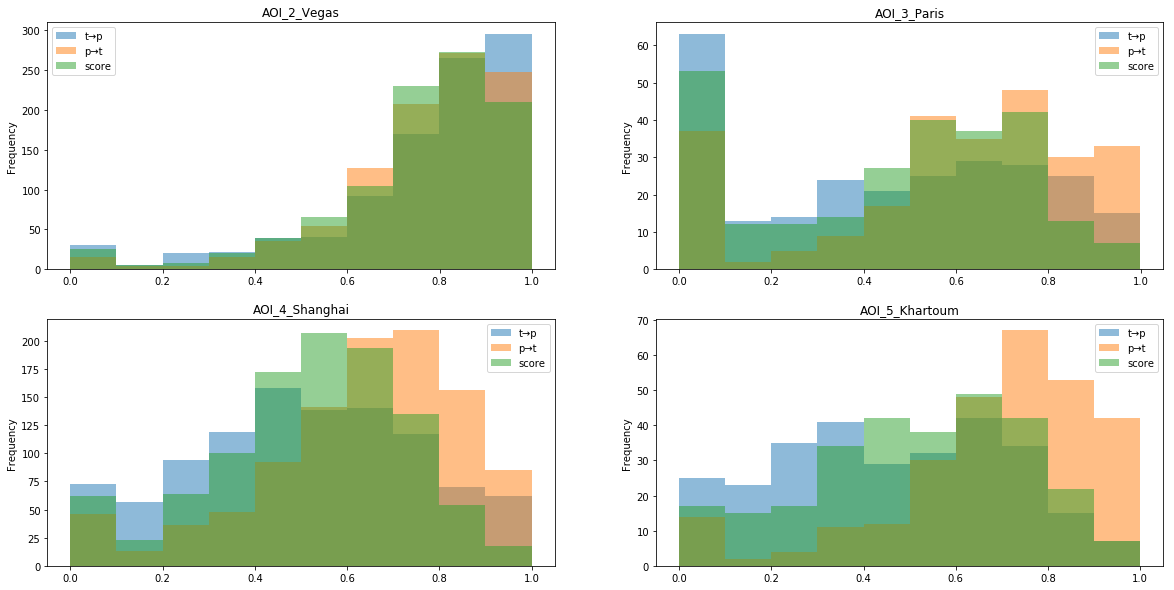
最も効率的なモデルのタイル速度分布。 パリでは、植生と郊外のタイルが多く、レイアウトに問題があり、速度に影響します。 さらに、上海とハルツームではtpとptの推定値の差がより大きくなります。つまり、モデルの場合、グラフのすべてのエッジが正しいことを確認するのははるかに簡単ですが、自然のグラフのすべてのエッジを見つけることははるかに困難です
私は多くのアイデアとアーキテクチャを試しましたが、驚いたことに、最も単純で最も素朴なモデルが最もうまく機能しました。少なくとも他のモデルよりも悪くありませんでした(他の参加者もすべてバリエーションで使用しました)。
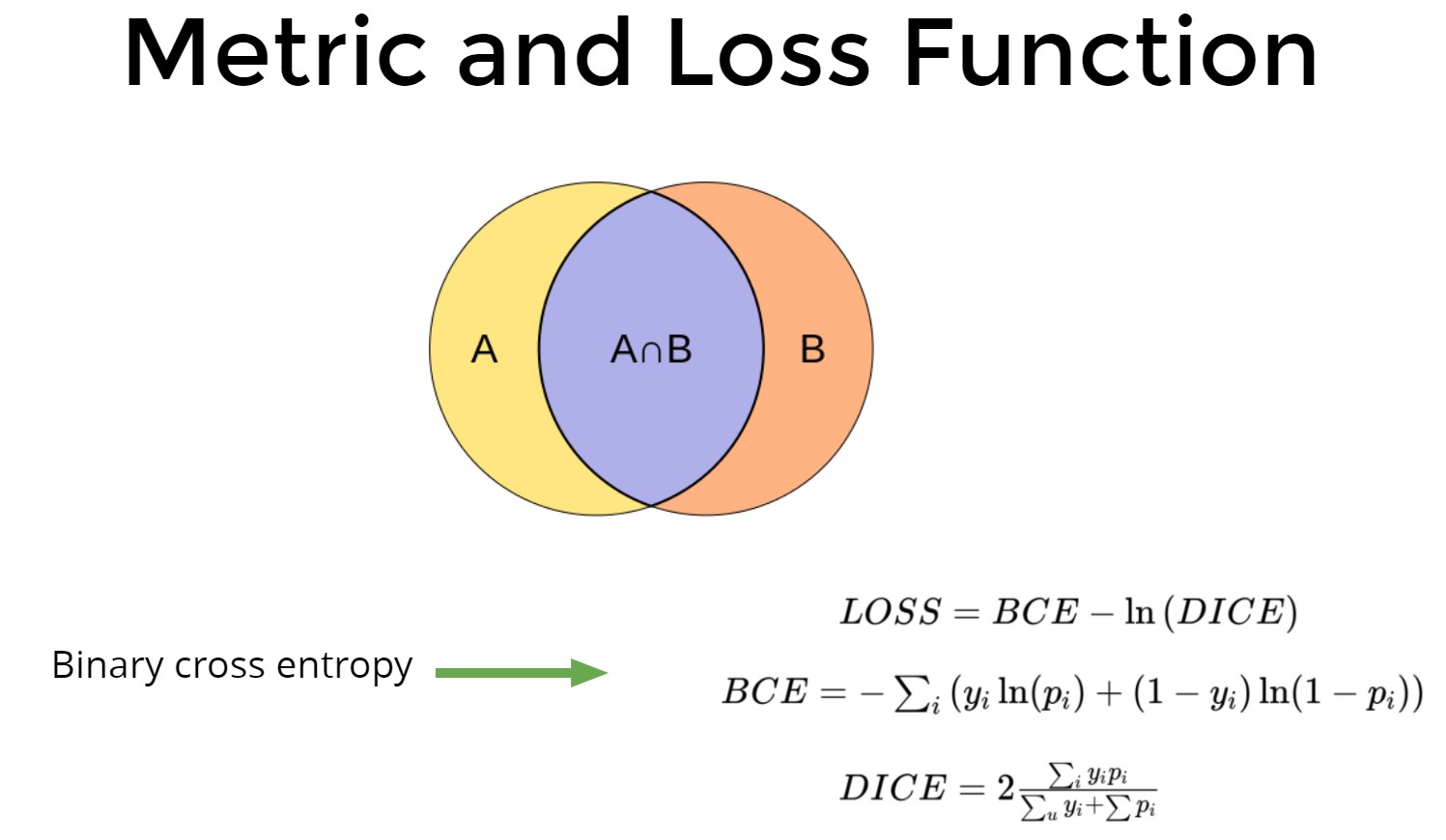
損失関数
- BCE + DICE / BCE + 1-DICE-ほぼ同じ姿を見せた
- ここでのクリッピング損失関数はひどいことが判明しました
- N BCE + DICE、BCE + N DICE-私の場合はうまくいきませんでした。 その後、チャットの同僚は、DICEではなくハードDICE(実際には推測ピクセルの割合)と4 * BCE + DICEがうまくいくことを提案しました。ハードDICEのより良い時代をとる必要があることを考慮して。
CNN
- LinkNet34(Resnet34 +デコーダー)-最高の速度と精度。
- Linknet50、LinkNext101(ResNeXt + LinkNet)、VGG11-Resnet-すべて同じであることが判明しましたが、2〜4倍のリソースが必要でした。
- すべてのエンコーダーは、ImageNet、essnoで事前トレーニングされています。
- 8チャンネルグリッドの場合、最初のレイヤーを単に置き換えましたが、3チャンネルグリッドとほぼ同じように動作しました(ただし、CPUリソースを多く消費しました)。
処理中
- 二値化マスク;
- チャンネルのすべての合理的な組み合わせのアブレーション分析を行いました-最良は植生、rgb、8チャンネル、都市(コード/src/presets.pyで対応するものを参照)でしたが、違いは最小でした(3-5%);
- 当然、HD画像の方がパフォーマンスが向上しました。
- 8ビット画像と16ビット画像も、それ自体がほぼ同じでした。
- 画像の正規化-Imagenetの平均値と標準偏差を抽出すると、損失関数が+2〜3%減少しましたが、リーダーボードではあまり差がありませんでした。
マスク
- APLSカブのマスク。 マスクの10%は作成されませんでした。 オーガナイザーのコードにはエラー処理が含まれておらず、道路もありませんでした。 最初はスチームバスに乗ってトレーニングに含めませんでしたが、その後はおそらく間違いでしたが、通常は確認できませんでした。
- ラインをskimageにロードし、空のイメージの約10%で仕上げるだけで損失は減少しましたが、最終結果への影響は明確ではありませんでした。
- 同じことは、道路の幅が実際の幅に対応するマスクにも与えられました-損失のように、より良く収束しますが、グラフは良くなりません。 おそらくハードDICEがこの問題を解決するでしょう。
- 舗装されていない道路のモデルは、貧弱なデータのために非常に悪く機能しました。
- 多層マスクも機能しませんでした(交差点に1層、未舗装道路に1層、アスファルト道路に1層)。
メタモデル
「ワイド」マスクと「ナロー」マスクのモデルの予測を明確にするシャムネットワークも機能しませんでした。 興味深いことに、「ワイド」マスクでのモデル予測ははるかに良く見えましたが、グラフは悪化しました。
パイプライン
- 3チャンネルまたは8チャンネルの画像は、ほとんど同じでした。
- 90度の回転、水平および垂直フリップ、小さなアフィン変換により、損失がさらに15〜20%減少しました。
- 私の最高のモデルはフル解像度でしたが、ランダムな800x800のクロップもうまく機能しました。
アンサンブル
私の場合、3倍+ 4倍TTAは増加しませんでした。
明らかに競合他社にLBを押し上げた他のアイデア
- LinkNet34(LinkNet + Resnet)=> Inception encoder-+ 20〜30k(Inception Resnetを試してみたかったのですが、一連の失敗の後、絶望して試さなかった)。
- 電車の中で-フル解像度のトレーニング。 推論:downsize => predict => upsize => ensemble-+ 10-20k;
- グラフを後処理し、タイルの端に持ってきます-+ 20〜30k。
- RGB画像(MULとは対照的に)-+ 10〜15k(元のデータに一貫性がないため)。
- 4 BCE + 1 DICE、ハードDICEをメトリックとして監視-+ 10〜30k。
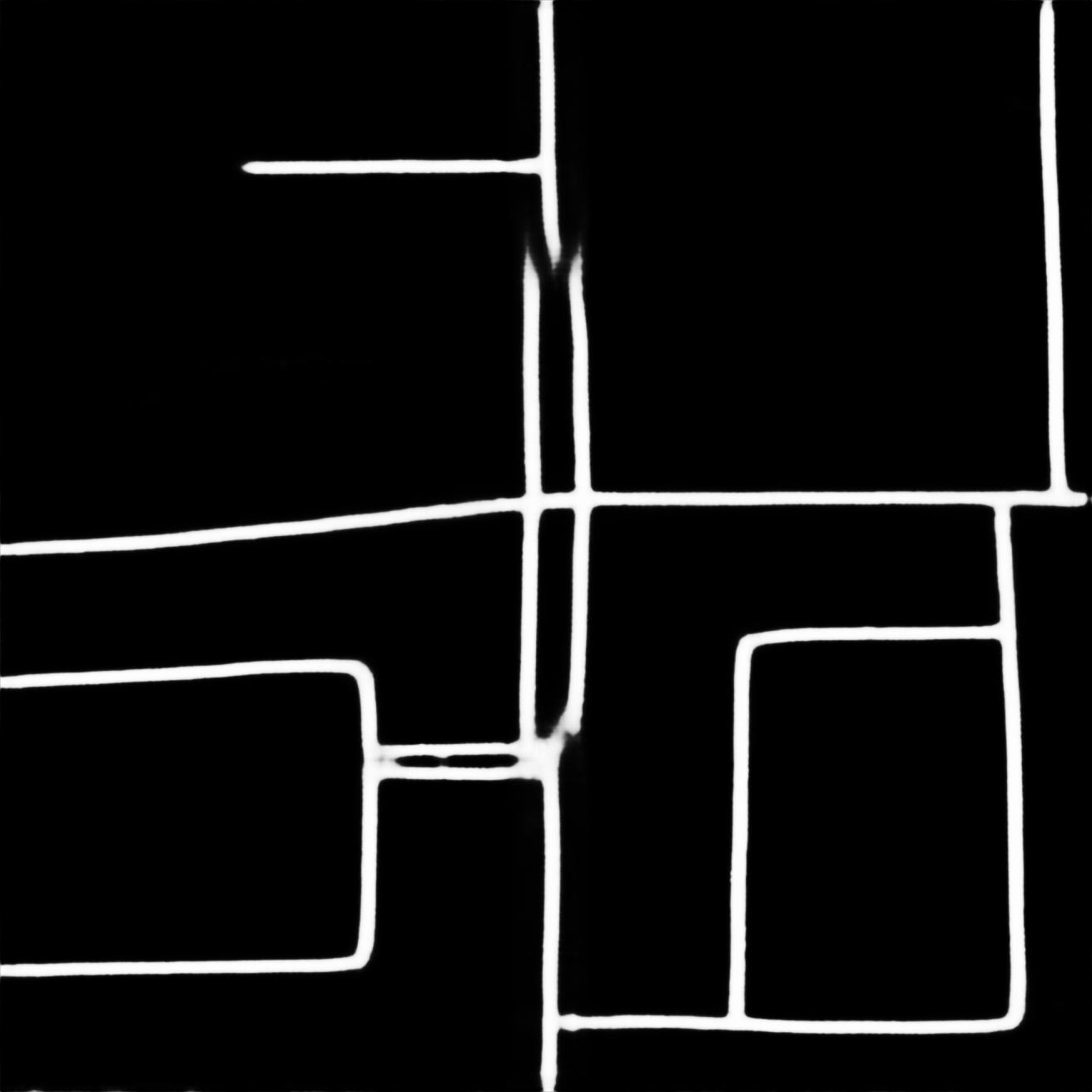
メインの横枠。 私の知る限り、誰もこの問題を解決していません。 幅の広いマスクはおそらく解決しますが、それらのグラフはうまく機能しませんでした。
ワイドマスクがkosyachatである主な理由-彼らはポリープとタコを生成します=)
同じ問題
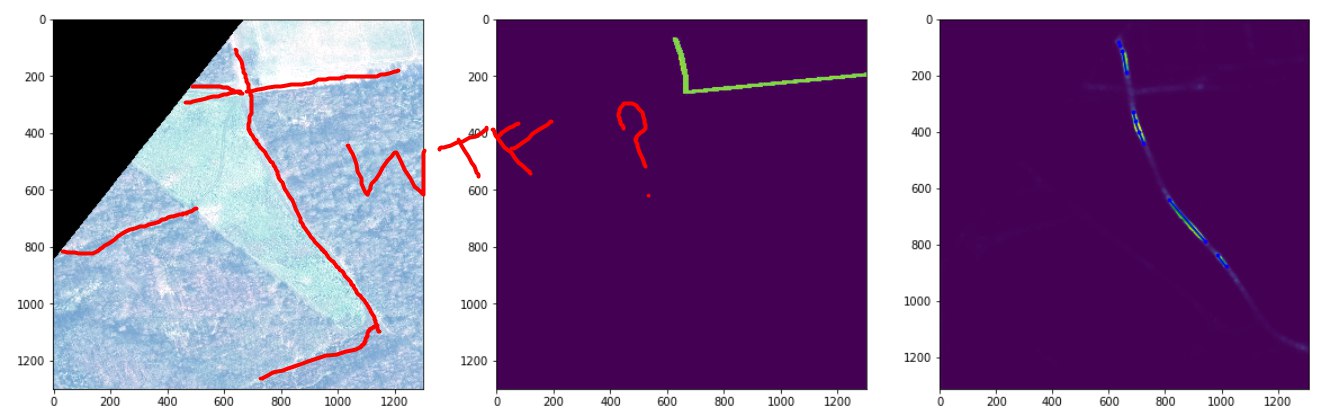
パリは貧弱なマークアップです。 森林地帯も草刈りのケースです。

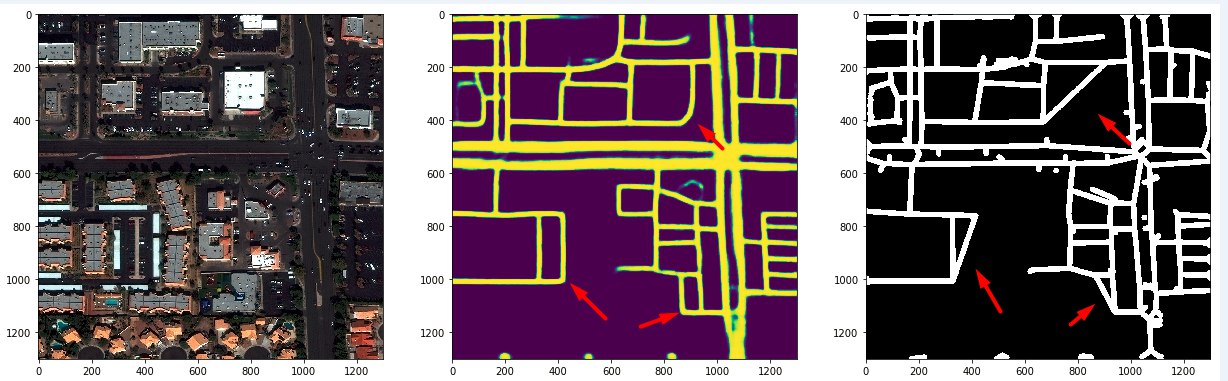
階層化された道路-ワイドモデルとナローモデルの予測
モデルは駐車場上の道路を思いついた=)

時々PyTorchはバグがあり、そのようなアーティファクトを生み出した
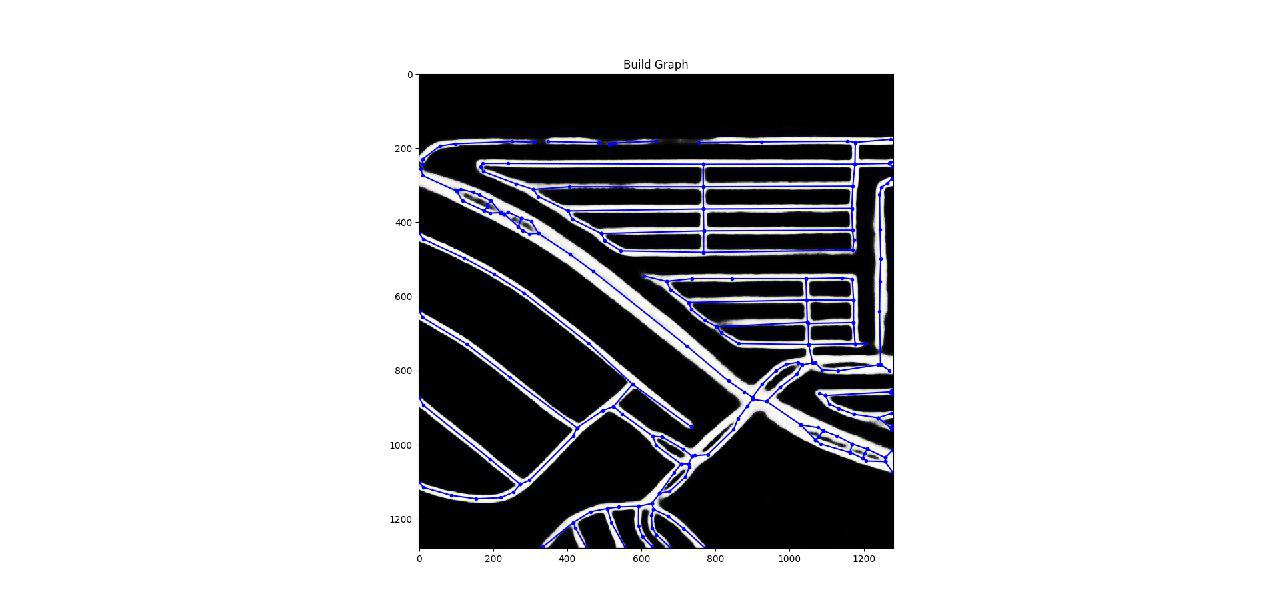
5.グラフ化と基本的なマッシュアップケース
重要な要素は、スケルトンネットワーク+曲線道路のグラフエッジを追加することです(ヒントをくれたDmytroに感謝します!)。 これだけで、あなたがトップ10にいることが保証されます。
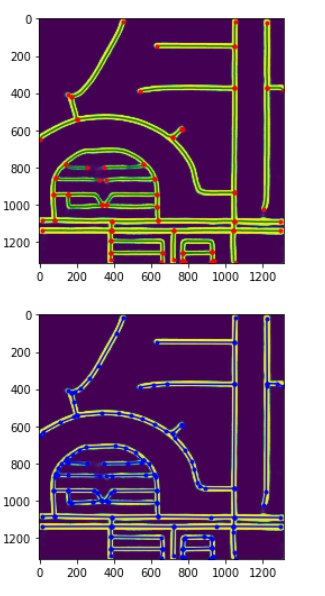
これらの手順がなければ、すべてのマスクは次のようになりました
私が試した代替パイプライン
- スケルトン化+ skimageからのコーナー検出
- ここからの拡張のいくつかのバリエーション
- これはすべていくつかのrib骨を生み出しましたが、スケルトンネットワークはまだはるかに優れています
時々他のメンバーを助けた余分なもの
- 治療前後の拡張;
- グラフの端をセルの端に移動します。
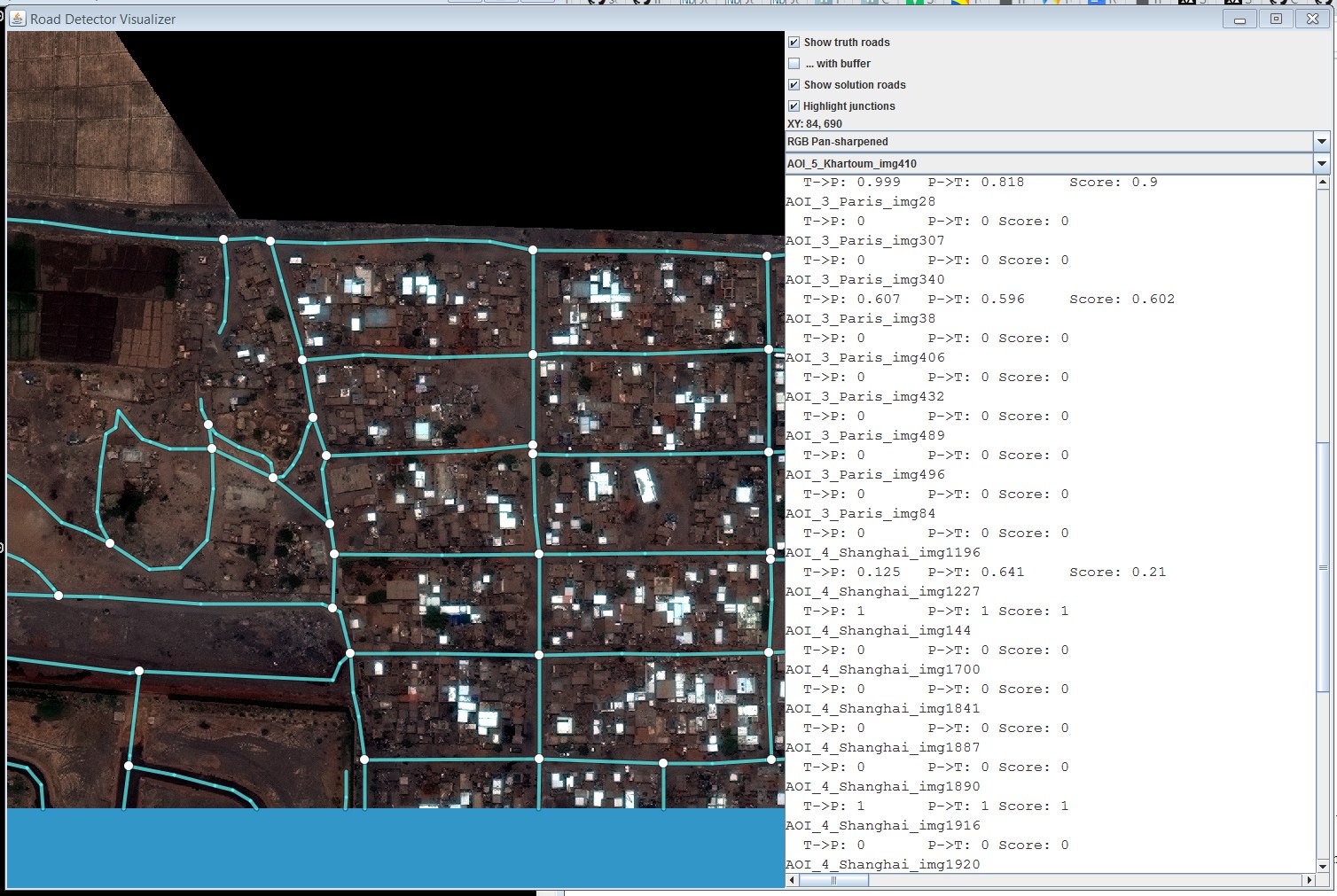
組織からの視覚化のためのタルサ
6.最終決定

本質的にTLDRの代替品
7.美しい視覚化-すべての都市のタイルが統合されました
前回の大会の伝統に従い、チャットの1人が、tif画像のジオデータを使用してジオセルから都市のフルサイズの写真を作成しました。
それらをクリックすると、高解像度で表示できます。
ラスベガス
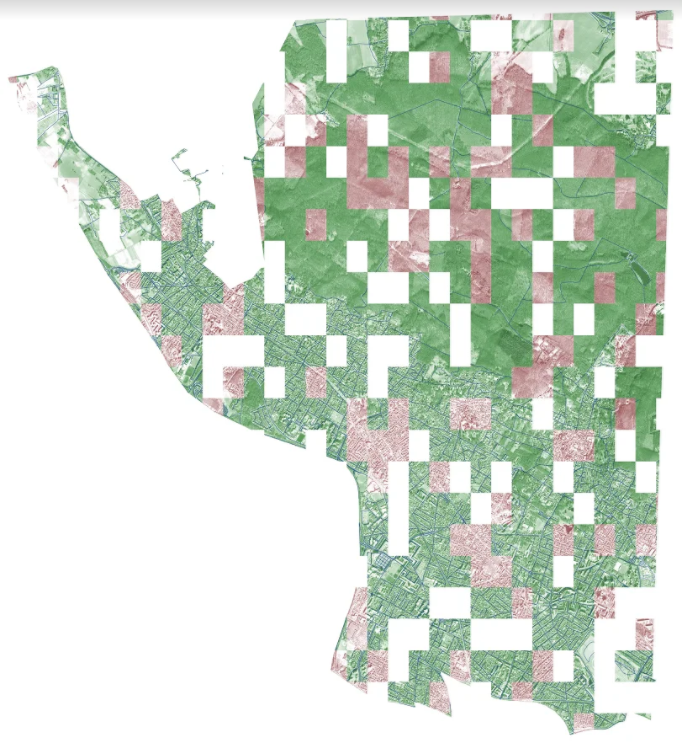
パリ

上海
ハルツーム
- コンテストのウェブサイト
- スケルトンネットワーク -マスクからグラフへの変換ライブラリ
- SpaceNet Road Detection and Routing Challenge-競合指標に関する長い投稿
- パートII-メトリックに関する2番目のパート
- https://github.com/CosmiQ/apls-メトリックを評価するためのリポジトリ
- パンシャープン画像 。 -ローズG.
- 地球の画像 -habr
- Deep Residual U-Netによる道路抽出 。 -Zhengxin Zhang、Qingjie Liu、Yunhong Wang
- 高密度オブジェクト検出のための焦点損失 。 -ツンイリン、プリヤゴヤル、ロスギルシック、カイミンヒ、ピョートルドラー
- LinkNet:効率的なセマンティックセグメンテーションのためのエンコーダー表現の活用 。 -Abhishek Chaurasia、Eugenio Culurciello
- Kaggle:アマゾンの衛星画像解析 -habr
- Dstl衛星画像コンテスト、1位受賞者インタビュー:カイルリー
- プラネット:宇宙からアマゾンを理解する、1位受賞者インタビュー
- Two Sigma Financial Modeling Challenge、Winner's Interview:2nd Place、Nima Shahbazi、Chahhou Mohamed
- ツーシグマファイナンシャルモデリングコードコンペティション、5位入賞者インタビュー:チームベストフィッティング| ベストフィッティング、ゼロ、およびサークルサークル
- Dark Channel Priorを使用した単一画像のヘイズ除去 。 -Kaiming He、Jian Sun、Xiaoou Tang
- 長年にわたる完全たたみ込みネットワークを使用したセマンティックセグメンテーション