現在、ほとんどの企業は、そのプロセスで取得したさまざまなデータを蓄積しています。 多くの場合、データはさまざまなソースから取得されます-構造化されたものではなく、時にはリアルタイムで、時には厳密に定義された期間で利用可能です。 この多様性はすべて、構造化された方法で保存する必要があります。そうすることで、後で正常に分析し、美しいレポートを作成し、異常に気付くことができます。 これらの目的のために、データウェアハウス (データウェアハウス、DWH)が設計されています。
このようなユニバーサルリポジトリを構築するには、アーキテクトが一般的な問題を回避し、最も重要なことに、DWHの適切なレベルの柔軟性と拡張性を確保するのに役立ついくつかのアプローチがあります。 これらのアプローチの1つについてお話したいと思います。
この記事に興味があるのは誰ですか?
- 「スター」パターンと第3正規形のより機能的な代替手段をお探しですか?
- データウェアハウスは既にありますが、変更するのは難しいですか?
- 歴史性に対する適切なサポートが必要であり、現在のアーキテクチャはこれに適していませんか?
- 複数のソースからのデータ収集に問題がありますか?
これらの質問のいずれかに「はい」と回答し、Data Vaultに精通していない場合は、カットをご覧ください!
Data Vaultは、おなじみの「スター」スキームと3つの通常の形状の利点を組み合わせたハイブリッドアプローチです。 この方法論は、2000年にDan Linstedtによって最初に発表されました。 このアプローチは、米国国防総省のデータウェアハウスを開発する過程で考案され、それ自体が十分に証明されています。 その後、2013年、Danはバージョン2.0を発表し、急速に普及しているテクノロジー(NoSQL、Hadoop)とDWHの新しい要件を考慮して改訂しました。 Data Vault 2.0について具体的に説明します。
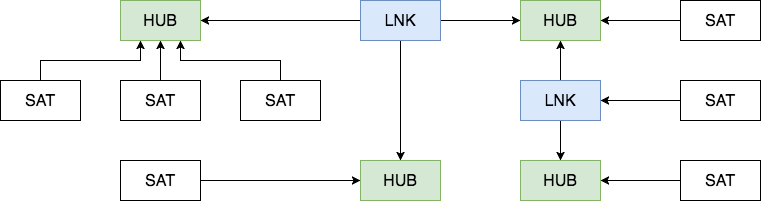
Data Vaultは、 Hub 、 Link 、およびSatelliteの3つの主要コンポーネントで構成されています。
ハブ
ハブ-ビジネスの観点からのエンティティ(顧客、製品、注文)の主な表現。 ハブテーブルには、ビジネスコンセプトのエンティティを反映する1つ以上のフィールドが含まれます。 総合すると、これらのフィールドは「ビジネスキー」と呼ばれます。 ビジネスキーの理想的な候補は組織のTINまたはVINであり、IDシステムで生成されたIDは最悪の選択肢になります。 ビジネスキーは常に一意で不変でなければなりません。
ハブには、 ロードタイムスタンプとレコードソースメタフィールドも含まれており、エンティティおよびリポジトリへの初期ロード時間(データのダウンロード元のシステム、データベース、またはファイルの名前)が保存されます。 ハブのプライマリキーとして、ビジネスキーのMD5またはSHA-1ハッシュを使用することをお勧めします。
ハブテーブル 
リンク
リンクテーブルは、多対多の関係で複数のハブをリンクします。 ハブと同じメタデータが含まれています。 リンクは別のリンクに接続される場合がありますが、この方法ではロード中に問題が発生するため、別のハブでリンクの1つを選択することをお勧めします。
リンクテーブル 
衛星
ハブまたはリンク(コンテキスト)のすべての記述属性は、サテライトテーブルに配置されます。 コンテキストに加えて、サテライトにはメタデータの標準セット( ロードタイムスタンプとレコードソース )と1つだけの親キーが含まれています。 Satelliteでは、ソースシステムのコンテキストを更新するときに新しいレコードを追加するたびに、コンテキスト変更履歴を簡単に保存できます。 大規模なサテライトの更新プロセスを簡素化するために、 ハッシュ差分フィールドをテーブルに追加できます。MD5またはSHA-1ハッシュをそのすべての記述属性から取得します。 ハブまたはリンクの場合、必要な数のサテライトを含めることができます。通常、コンテキストは更新頻度に応じて分類されます。 異なるソースシステムのコンテキストは、通常、別々のサテライトに配置されます。
サテライトテーブル 
どのように作業するのですか?

* Data Vault 2.0を使用したスケーラブルなデータウェアハウスの構築の図に基づく画像
まず、オペレーティングシステムからのデータがステージング領域に送られます 。 ステージング領域は、データ読み込みプロセスの中間として使用されます。 ステージングゾーンの主な機能の1つは、クエリの実行時に運用ベースの負荷を軽減することです。 ここの表は元の構造を完全に繰り返していますが、破損していないデータや不完全なデータを挿入する機能を残しておくために、 null以外や外部キーの整合性のチェックなど、データの挿入に関する制限をオフにする必要があります(これは特にExcelテーブルや他のファイルに当てはまります)。 さらに、ステージテーブルには、ビジネスキーのハッシュと、ロード時間とデータソースに関する情報が含まれています。
その後、データはハブ、リンク、およびサテライトに分割され、 Raw Data Vaultにロードされます。 ダウンロードプロセス中、それらはいかなる方法でも集約または再計算されません。
Business Vaultは、Raw Data Vault用のオプションのヘルパーアドオンです。 同じ原則に基づいて構築されていますが、処理結果のデータ(集計結果、換算通貨など)が含まれています。 分離は純粋に論理的であり、物理的にBusiness VaultはRaw Data Vaultと同じデータベースにあり、主に店頭の形成を簡素化することを目的としています。
ビジネス衛星
b_sat_order_total_price
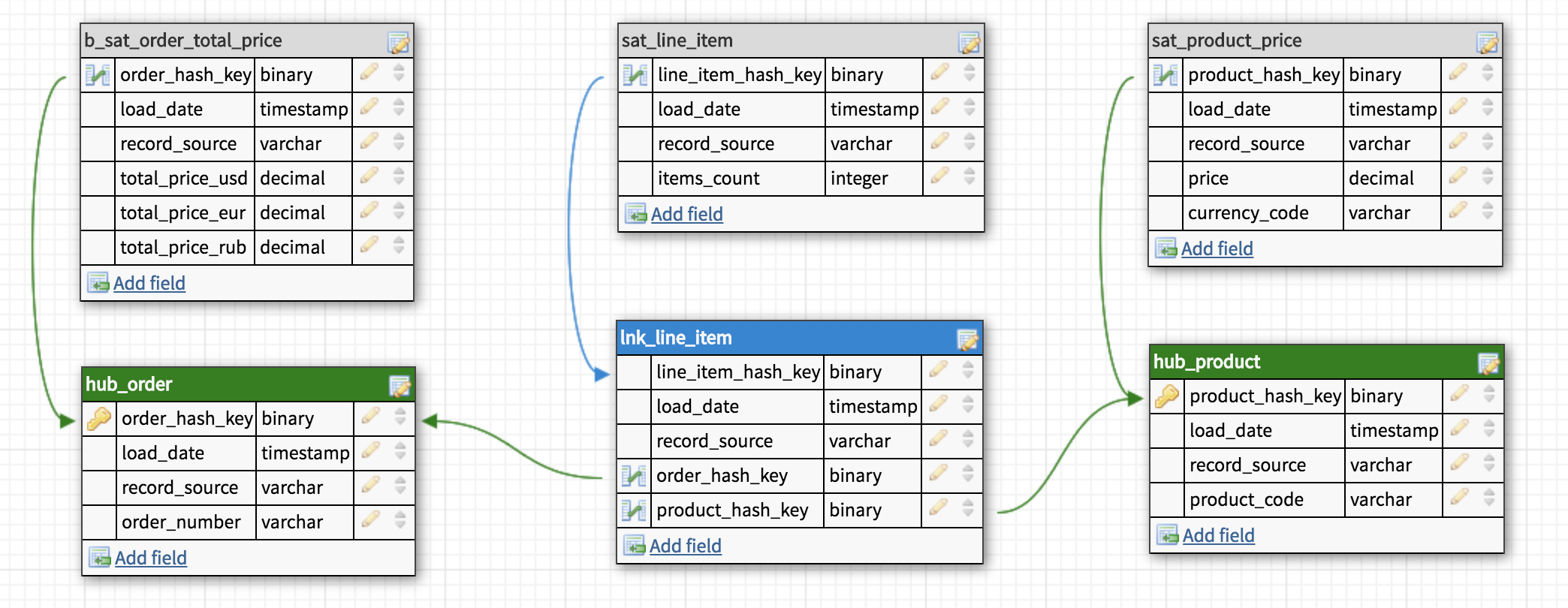
必要なテーブルが作成され、 データが取り込まれると、 データマートターンが始まります。 各ショーケースは、さまざまなユーザーまたは部門の問題を解決するために設計された個別のデータベースまたはスキームです。 特別にアセンブルされた「スター」または非正規化されたテーブルのコレクションがあります。 可能であれば、ウィンドウ内のテーブルを仮想化、つまりオンザフライで計算することをお勧めします。 このため、通常はSQLビューが使用されます。
データボルトの入力
ここでは、すべてが非常に簡単です。最初にハブがロードされ、次にリンク、次にサテライトがロードされます。 もちろんリンクツーリンクが使用されない限り、ハブはサテライトとリンクと同様に並行してロードできます。
完全性チェックを完全にオフにして、すべてのデータを同時にロードするオプションがあります。 このようなアプローチは、DVの主要な原則の1つである「すべてのデータを常にロードする(すべてのデータを常にロードする)」に対応し、ビジネスキーが決定的な役割を果たします。 一番下の行は、データの読み込み時に起こりうる問題を最小限に抑える必要があることであり、最も一般的な問題の1つは整合性の違反です。 もちろん、このアプローチは議論の余地がありますが、私は個人的にそれを使用しており、本当に便利だと感じています。 リンクを読み込むときにいくつかのハブにエントリが存在しないという問題が発生することがあり、特定のハブが完全にいっぱいにならない理由を順番に把握し、プロセスを再起動して新しいエラーを調べます。 別の方法は、ロード後に欠落データを表示し、すべての問題を一度に表示することです。 おまけとして、エラー許容度とテーブルのロード順に従わない機能があります。
長所と短所
[+]柔軟性と拡張性。
Data Vaultでは、ストレージ構造の拡張と、新しいソースからのデータの追加と照合の両方が問題になりません。 生データの最も完全なストレージと便利なストレージ構造により、ビジネス要件のショーケースを作成できます。また、DBMS市場の既存のソリューションは、膨大な情報に対応し、非常に複雑なクエリでも迅速に処理できるため、ほとんどの店頭を仮想化できます。
[+]すぐに使えるアジャイルアプローチ。
Data Vault方法論を使用したストレージのモデリングは非常に簡単です。 新しいデータは、既存の構造を壊したり変更したりすることなく、単に既存のモデルに「接続」します。 同時に、可能な限り分離されたタスクを解決し、必要な最小値のみをロードします。おそらく、そのようなタスクの推定時間はより正確になります。 スプリント計画はより簡単になり、結果は最初の反復から予測可能です。
[-]豊富な参加
結合操作の数が多いため、テーブルが非正規化される従来のデータウェアハウスよりもクエリが遅くなる可能性があります。
[-]困難。
上記の方法論では、数時間以内に解明されそうにない多くの重要な詳細があります。 これに、インターネット上の少量の情報と、ロシア語での資料のほぼ完全な不足を追加できます(これを修正したいと考えています)。 その結果、Data Vaultを実装する際、チームのトレーニングに問題があり、特定のビジネスのニュアンスに関して多くの疑問が生じます。 幸いなことに、これらの質問をすることができるリソースがあります。 Data Vault自体は直接クエリには適していないため、データマートが存在するための必須の要件は複雑さの大幅な欠如です。
[-]冗長性。
かなり物議を醸す欠陥ですが、冗長性についての質問をよく見ますので、この点については私の観点からコメントします。
多くの人は、データマートの前にレイヤーを作成するという考えを好みません。特に、このレイヤーには3番目の通常形式よりも約3倍多いテーブルがあることを考えると、3倍のETLプロセスを意味します。 これは事実ですが、ETLプロセス自体は均一であるため非常に単純になり、リポジトリ内のすべてのオブジェクトは非常に理解しやすくなります。
一見冗長なアーキテクチャは、非常に具体的な問題を解決するために構築されており、もちろん特効薬ではありません。 いずれにしても、上記のData Vaultの利点が必要になるまで、何も変更しないことをお勧めします。
結論として
この記事では、入門記事に最低限必要なData Vaultの主要コンポーネントのみに言及しました。 背後には、ポイントインタイムテーブルとブリッジテーブル、ビジネスキーのコンポーネントを選択するための機能とルール、削除されたレコードを追跡する方法がありました。 トピックがコミュニティに興味がある場合は、次の記事でそれらについて話す予定です。