64本の記事を読んで、5冊の本のセクションをめくって、IRCとStackOverflowについてたくさんの質問をした後、私( Joe "begriffs" Nelsonによる元記事の著者)が、パズルのピースを組み立てて、対戦相手を調整できるようになりました。 キーに関する多くの紛争は、実際には、他の人の視点の誤解のために発生します。
内容
問題をいくつかの部分に分けてみましょう。最終的には再び収集します。 まず、質問をします-「キー」とは何ですか?
「キー」とは何ですか?
しばらく主キーを忘れて、より一般的なアイデアに興味があります。 キーは、行に重複値を持たない列です。 さらに、列は還元不可能に一意である必要があります。つまり、列のサブセットはそれほど一意ではありません。
たとえば、カードゲームでカードをカウントするためのテーブルを考えてみましょう。
CREATE TABLE cards_seen ( suit text, face text );
1つのデッキを追跡する場合(つまり、重複するカードがない場合)、シャツと顔の組み合わせは一意であり、同じシャツと顔を重複してテーブルに追加することは望ましくありません。 カードがテーブルにある場合、私たちはそれを見ました;さもなければ、私たちはそれを見ませんでした。
以下を追加することにより、この制限をデータベースに設定できます。
CREATE TABLE cards_seen ( suit text, face text, UNIQUE (suit, face) );
それ自体では、
suit
(シャツ)も
face
(顔)もユニークではなく、同じシャツまたは顔で異なるカードを見ることができます。
(suit, face)
一意であり、個々の列は一意ではないため、それらの組み合わせは既約であり、
(suit, face)
がキーであると主張できます。
より一般的な状況では、カードのいくつかのデッキを追跡する必要がある場合、新しいフィールドを追加して、カードを見た回数を記録できます。
CREATE TABLE cards_seen ( suit text, face text, seen int );
トリプル
(suit, face, seen)
は一意であることが判明しましたが、サブセット
(suit, face)
も一意である必要があるため、キーではありません。 これは、シャツと顔が同じで、値が異なる2つの行が競合する情報になるために必要です。 したがって、キーは
(suit, face)
であり、このテーブルにはこれ以上キーはありません。
一意性の制限
PostgreSQLでは、一意の制約を追加する好ましい方法は、例のように直接宣言することです。 場合によっては、一意性制約に準拠するためにインデックスを使用する必要がありますが、直接問い合わせないでください。 既に一意であると宣言されている列のインデックスを手動で作成する必要はありません。 このようなアクションは、インデックスの自動作成を単純に複製します。
また、テーブルにはいくつかのキーが問題なく存在する可能性があり、データベースでそれらの一意性を維持するためにすべてを宣言する必要があります。
以下に、複数のキーを持つ2つのサンプルテーブルを示します。
-- CREATE TABLE tax_brackets ( min_income numeric(8,2), max_income numeric(8,2), tax_percent numeric(3,1), UNIQUE(min_income), UNIQUE(max_income), UNIQUE(tax_percent) ); -- CREATE TABLE flight_roster ( departure timestamptz, gate text, pilot text UNIQUE(departure, gate), UNIQUE(departure, pilot) );
簡潔にするために、この例には実用的な他の制限はありません。 たとえば、カードのビューの数が負であってはならず、NULLは検査された列のほとんどに対して無効です(NULLは無限を示すことができる税グループの
max_income
列を除く)。
主キーの奇妙なケース
前のセクションで単に「キー」と呼んだものは、通常「候補キー」と呼ばれます。 「候補」という用語は、そのようなすべてのキーが「プライマリキー」の名誉ある役割をめぐって競合し、残りが「代替キー」(代替キー)として割り当てられることを意味します。
SQL実装がキーとリレーショナルモデルの間の不一致をなくすには時間がかかりました。初期のデータベースは、主キーの低レベルの概念によって強化されました。 このようなデータベースの主キーは、データへの順次アクセスでメディア上の文字列の物理的な場所を識別するために必要でした。 Joe Selcoが説明する方法は次のとおりです。
「キー」という用語は、シリアルファイルシステムで処理操作を実行するために必要なファイルソートキーを意味していました。 パンチカードのセットは、たった1つの順序で読み取られました。 「戻る」ことは不可能でした。 最初のテープドライブは同じ動作をシミュレートし、双方向アクセスを許可しませんでした。 つまり、元のSybase SQL Serverが前の行を読み取るには、テーブルを先頭に「巻き戻す」必要がありました。
現代のSQLでは、情報の物理的表現に焦点を当てる必要はなく、テーブルモデルの関係と内部行の順序はまったく重要ではありません。 ただし、現在でも、SQLサーバーは既定で主キーのクラスター化インデックスを作成し、古い伝統に従って、行の順序を物理的に配置します。
ほとんどのデータベースでは、主キーは過去の遺物として保持されており、物理的な場所の反映または決定以外にはほとんど何も提供しません。 たとえば、PostgreSQLテーブルでは、主キーを宣言すると、自動的にNOT NULL制約が課され、デフォルトの外部キーが定義されます。 主キーは、JOIN演算子の優先列でもあります。
主キーは、他のキーの宣言を排除しません。 同時に、プライマリとしてキーが割り当てられていない場合、テーブルは引き続き正常に機能します。 いずれにせよ、雷はあなたを打つことはありません。
自然キーの検索

上記で説明したキーは、誰もキーを作成したくない場合でも、モデル化されたオブジェクトのプロパティであるため、「ナチュラル」と呼ばれます。
考えられる自然キーについてテーブルを調べるときに最初に覚えておくべきことは、あまりスマートにならないようにすることです。 StackExchangeのsqlvogelユーザーは、次のアドバイスを提供します。
一部の人々は、特定のキーが一意ではないという仮想的な状況に陥るため、「自然な」キーを選択するのが困難です。 彼らはタスクの意味そのものを理解していません。 キーの意味は、特定のテーブルで属性が常に一意であり、常に一意であるルールを決定することです。 テーブルには、特定の十分に理解されたコンテキスト(「主題領域」または「談話領域」)のデータが含まれ、唯一の値はこの特定の領域での制限の適用です。
練習は、列が既存の値で一意であり、可能性のあるシナリオではそうである場合、キー制約を入力する必要があることを示しています。 また、必要に応じて、制限を削除できます(これが気になる場合は、以下にキーの安定性について説明します)。
たとえば、趣味クラブのメンバーのデータベースは、first_name、last_nameの2つの列に一意性を持っている場合があります。 少量のデータでは、重複はほとんどありません。実際の競合が発生する前に、そのようなキーを使用することは非常に合理的です。
データベースの成長と情報量の増加により、自然キーの選択はより困難になる可能性があります。 格納するデータは外部の現実を単純化したものであり、座標が時間とともに変化するなど、世界のオブジェクトを区別するいくつかの側面は含まれていません。 オブジェクトにコードがない場合、空間内の位置または重量またはパッケージのわずかな違いを除いて、2缶の飲料または2箱のオートミールを区別する方法は?
それが、標準化団体が製品に独特のラベルを作成して貼る理由です。 車には車両識別番号(VIN)が刻印され、ISBNは本に印刷され、UPCは食品の包装に刻印されています。 これらの数値は自然なものではないと主張するかもしれません。 では、なぜそれらを自然キーと呼ぶのですか?
データベース内の一意のプロパティの自然性または人工性は、外部の世界に関連しています。 標準化団体または国家機関で人工的に作成されたキーは、世界中で標準になり、オブジェクトに印刷されるため、私たちにとって自然になります。
通貨、言語、金融商品、化学薬品、医療診断など、さまざまな施設には多くの業界、社会、および国際規格があります。 以下は、自然キーとしてよく使用される値の一部です。
- ISO 3166に準拠した国コード
- ISO 639言語コード
- ISO 4217に準拠した通貨コード
- 交換指定ISIN
- UPC / EAN、VIN、GTIN、ISBN
- ユーザー名
- メールアドレス
- 部屋番号
- ネットワークMACアドレス
- (緯度、経度)地球の表面上のポイント
可能かつ妥当な場合はキーを宣言することをお勧めします。テーブルごとにいくつかのキーを宣言することもできます。 ただし、上記のすべてに例外がある場合があることに注意してください。
- すべての人が電子メールアドレスを持っているわけではありませんが、状況によってはデータベースの使用が許容される場合があります。 さらに、人々はメールアドレスを時々変更します。 (キーの安定性については後で詳しく説明します。)
- ISIN交換シンボルは時々変更されます。たとえば、GOOGおよびGOOGLシンボルは、Googleからアルファベットへの会社の再編成を正確に説明していません。 TWTRやTWTRQなどで混乱が生じる場合があり、一部の投資家はIPO Twitterで誤って後者を購入しました。
- 社会保障番号は米国市民のみが使用し、プライバシーの制限があり、死亡後に再利用されます。 さらに、ドキュメントを盗んだ後、人々は新しい番号を取得できます。 最後に、同じ番号で個人と所得税の識別子の両方を識別できます。
- 郵便番号は都市には適していません。 一部の都市には共通のインデックスがあり、逆もまた同様です。1つの都市には複数のインデックスがあります。
人工キー

キーが各行に一意の値を持つ列である場合、それを作成する方法の1つはチートです-各行に独自の一意の値を書き込むことができます。 これらは人工的なキーです。データまたはオブジェクトを参照するために使用される発明されたコード。
コードがデータベース自体から生成され、データベースユーザー以外の誰にも知られないことが非常に重要です。 これが、人工キーと標準化された自然キーを区別するものです。
自然キーの利点は、テーブル行の重複または不整合から保護することです。一方、人為的なキーは、文字列(または複数列)比較を使用しないため、人や他のシステムが行を参照しやすくなり、検索および結合操作の速度が向上するため便利ですキー。
非代理人工キーは、データベース外の行を参照するのに役立ちます。 人工キーは、データまたはオブジェクトを簡単に識別します。URLとして指定したり、アカウントに添付したり、電話で口述したり、銀行で受け取ったり、ナンバープレートに印刷したりできます。 (私たちの車のナンバープレートは自然なキーですが、それは国家によって人工キーとして設計されています。)代理
人工キーはバインディングとして使用されます-ルールと列の変更に関係なく、1行は常に同じ方法で識別できます。 この目的で使用される人工キーは「代理キー」と呼ばれ、特別な注意が必要です。 以下で検討するサロゲート。
入力ミスやエラーを最小限に抑えるために、考えられる送信方法を考慮して、人工キーを選択する必要があります。 キーの発音、印刷、SMSによる送信、手書きの読み取り、キーボードからの入力、URLへの埋め込みが可能です。 さらに、クレジットカード番号などの一部の人工キーにはチェックサムが含まれているため、特定のエラーが発生したときに少なくともエラーを認識できます。
例:
- 米国のナンバープレートには、
O
や0
などのあいまいな記号を使用するためのルールがあり0
。 - 医師の手書きを考慮して、病院と薬局は特に注意する必要があります。
- SMS確認コードを渡しますか? GSM 03.38文字セットを超えないでください。
- 任意のバイトデータをエンコードするBase64とは異なり、 Base32は、古いコンピューターシステムで使用および処理するのに便利な制限された文字セットを使用します。
- Proquintsは、読み取り可能、書き込み可能、および音声識別子です。 これらは、明確に理解された子音と母音の発音された(PROで発音できない)5(QUINT-uplets)です。
人工キーに世界を紹介するとすぐに、人々は奇妙な方法で特別な注意を払い始めることに注意してください。 「泥棒」のナンバープレートまたは発音可能な識別子を作成するためのシステムを見てください。これは悪名高いcursesの自動生成プログラムになりました 。
数字キーに限定しても、 13階のようなタブーがあります。 プロクイントは発音された音節に関する情報の密度が高いという事実にもかかわらず、数字も多くの場合に適しています:URL、ピンキーボード、手書き入力では、キーが数字のみで構成されていることを受信者が知っている場合。
ただし、リソース(
/videos/1.mpeg
など)を
/videos/2.mpeg
たり、番号に関する情報の漏えいを作成したりできるため、公的にアクセス可能な数字キーで順番を使用しないでください。データ。 Feistelネットワークを一連の数字でオーバーレイし、一意性を保持しながら、数字の順序を隠します。
PostgreSQL wikiには、 擬似暗号化関数の例があります。
CREATE OR REPLACE FUNCTION pseudo_encrypt(VALUE int) returns int AS $$ DECLARE l1 int; l2 int; r1 int; r2 int; i int:=0; BEGIN l1:= (VALUE >> 16) & 65535; r1:= VALUE & 65535; WHILE i < 3 LOOP l2 := r1; r2 := l1 # ((((1366 * r1 + 150889) % 714025) / 714025.0) * 32767)::int; l1 := l2; r1 := r2; i := i + 1; END LOOP; RETURN ((r1 << 16) + l1); END; $$ LANGUAGE plpgsql strict immutable;
この関数はそれ自体とは逆です(つまり、
pseudo_encrypt(pseudo_encrypt(x)) = x
)。 関数の正確な再現は、あいまいさによる一種のセキュリティであり、PostgreSQLのドキュメントからFeistelネットワークを使用していることに気付いた人は、元のシーケンスを簡単に取得できます。 ただし、
(((1366 * r1 + 150889) % 714025) / 714025.0)
代わりに、0から1の値の範囲で別の関数を使用できます。たとえば、前の式の数値を試してください。
pseudo_encryptの使用方法は次のとおりです。
CREATE SEQUENCE my_table_seq; CREATE TABLE my_table ( short_id int NOT NULL DEFAULT pseudo_encrypt( nextval('my_table_seq')::int ), -- … UNIQUE (short_id) );
このソリューションは、
short_id
列にランダムな値を保存しますが、高いデータ処理速度を維持することが重要な場合は、増分シーケンス自体をテーブルに保存し、
pseudo_encrypt
表示するときに変換
pseudo_encrypt
ます。 後で見るように、ランダム化された値にインデックスを付けると、録音ボリュームが増加する可能性があります。
前の例では、通常サイズの整数値が
bigint
に使用されました
bigint
、 XTEAなどの他のFeistel関数があります。
整数のシーケンスを混同する別の方法は、それを短い文字列に変換することです。 pg_hashids拡張機能を使用してみてください。
CREATE EXTENSION pg_hashids; CREATE SEQUENCE my_table_seq; CREATE TABLE my_table ( short_id text NOT NULL DEFAULT id_encode( nextval('my_table_seq'), ' long string as table-specific salt ' ), -- … UNIQUE (short_id) ); INSERT INTO my_table VALUES (DEFAULT), (DEFAULT), (DEFAULT); SELECT * FROM my_table; /* ┌──────────┐ │ short_id │ ├──────────┤ │ R4 │ │ ya │ │ Ll │ └──────────┘ */
ここでも、整数そのものをテーブルに格納し、必要に応じて変換する方が高速ですが、パフォーマンスを測定し、本当に意味があるかどうかを確認します。
さて、人工キーと自然キーの意味を明確に区別すると、「自然対人工」論争は誤った二分法であることがわかります。 人工キーと自然キーはお互いを排除しません! 1つのテーブルに両方がある場合があります。 実際、人工キーのあるテーブルは自然キーも提供する必要がありますが、自然キーがない場合はまれに例外があります(たとえば、クーポンコードコードのテーブル内)。
-- : , -- "code" CREATE TABLE coupons ( code text NOT NULL, amount numeric(5,2) NOT NULL, redeemed boolean NOT NULL DEFAULT false, UNIQUE (code) );
人工キーがあり、自然キーが存在するときに宣言しない場合、後者を保護しないでください。
CREATE TABLE cars ( car_id bigserial NOT NULL, vin varchar(17) NOT NULL, year int NOT NULL, UNIQUE (car_id) -- -- UNIQUE (vin) ); -- , INSERT INTO cars (vin, year) VALUES ('1FTJW36F2TEA03179', 1996), ('1FTJW36F2TEA03179', 1997);
追加のキーを宣言することに対する唯一の議論は、それぞれの新しいキーが別の一意のインデックスを保持し、テーブルへの書き込みコストを増加させることです。 もちろん、それはあなたにとってデータの正確さがどれほど重要かによって異なりますが、ほとんどの場合、キーはまだ宣言する価値があります。
また、もしあれば、いくつかの人工的なキーを宣言する価値があります。 たとえば、組織には応募者と従業員がいます。 各従業員はかつて候補者でしたが、従業員のキーでもある独自の識別子で候補者を参照します。 別の例として、従業員IDとログイン名をEmployeesの2つのキーとして設定できます。
代理キー

すでに述べたように、重要なタイプの人工キーは「代理キー」と呼ばれます。 他の人工キーのように簡潔で転送可能である必要はありませんが、常に文字列を識別する内部ラベルとして使用されます。 SQLで使用されますが、アプリケーションは明示的にアクセスしません。
PostgreSQLのシステムカラム(システムカラム)に精通している場合、サロゲートはほとんどデータベース実装パラメーター(ctidなど)であると考えることができますが、変更はありません。 サロゲート値は行ごとに1回選択され、その後は変更されません。
代理キーは外部キーとして優れており、カスケードの
ON UPDATE RESTRICT
制約は、代理の不変性と一致するように指定する必要があります。
一方、公的に送信されるキーに対する外部キーは、最大限の柔軟性を提供するために
ON UPDATE CASCADE
とマークする必要があります。 (カスケード更新は、それを取り巻くトランザクションと同じ分離レベルで実行されるため、同時アクセスの問題を心配する必要はありません。厳密な分離レベルを選択すると、データベースが対処します。)
代理キーを「自然」にしないでください。 , , , ( ), . - .
, , , .
bigint
«bigserial»,
IDENTITY
. ( , PostgreSQL 10 , Oracle, IDENTITY, . CREATE TABLE .)
, , . , .
:
- 1 , . , , , , JOIN . ( , , , .)
-
nextval()
SQL, , . - , , , .
- , . , , - . .
- ( , ) -.
UUID
: (128-), . (universally unique identifier, UUID) , .
, UUID , ? , !
PostgreSQL? , , , .
, . , UUID — , : 5bd68e64-ff52-4f54-ace4-3cd9161c8b7f. , (128-) uuid, PostgreSQL bigint, .., , .
UUID , , ? , , ( ) UUID. , UUID , SQL psql , . , .
UUID , (write amplification) - (write-ahead log, WAL). , UUID.
write amplification. , . PostgreSQL , «» . , . PostgreSQL , .
PostgreSQL / / , (write-ahead log), . UUID ( 4 8 ) WAL . (full-page write, FPW).
UUID (, «snowflake» Twitter
uuid_generate_v1()
uuid-ossp PostgreSQL) . FPW.
FPW UUID, WAL. .
- EC2 ami-aa2ea6d0
- Ubuntu Server 16.04 LTS (HVM)
- EBS General Purpose (SSD)
- c3.xlarge
- vCPU: 4
- RAM GiB: 7.5
- Disk GB: 2 x 40 (SSD)
- PostgreSQL,
- ftp.postgresql.org/pub/source/v10.1/postgresql-10.1.tar.gz
-
./configure --with-uuid=ossp CFLAGS="-O3"
- , :
- max_wal_size='10GB';
- checkpoint_timeout='2h';
- synchronous_commit='off';
:
CREATE EXTENSION "uuid-ossp"; CREATE EXTENSION pgcrypto; CREATE TABLE u_v1 ( u uuid PRIMARY KEY ); CREATE TABLE u_crypto ( u uuid PRIMARY KEY );
, UUID , write-ahead log.
SELECT pg_walfile_name(pg_current_wal_lsn()); /* , pg_walfile_name -------------------------- 000000010000000000000001 */
, WAL . , :
pg_waldump --stats 000000010000000000000001
:
- UUID,
gen_random_uuid()
( pgcrypto ) -
uuid_generate_v1()
( [uuid-ossp] (https://www.postgresql.org/docs/10/static/uuid-ossp.html) -
gen_random_uuid()
,full_page_writes='off'
. , FPW.
2 20 UUID , , , .
-- , psql 16 \timing INSERT INTO u_crypto ( SELECT gen_random_uuid() FROM generate_series(1, 1024*1024) );
:
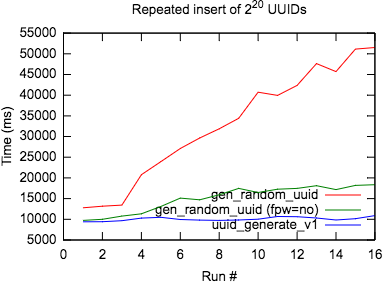
UUID
WAL :
gen_random_uuid() N (%) (%) FPI (%) ---- - --- ----------- --- -------- --- XLOG 260 ( 0.15) 13139 ( 0.09) 484420 ( 30.94) Heap2 765 ( 0.45) 265926 ( 1.77) 376832 ( 24.07) Heap 79423 ( 46.55) 6657121 ( 44.20) 299776 ( 19.14) Btree 89354 ( 52.37) 7959710 ( 52.85) 404832 ( 25.85) uuid_generate_v1() N (%) (%) FPI (%) ---- - --- ----------- --- -------- --- XLOG 0 ( 0.00) 0 ( 0.00) 0 ( 0.00) Heap2 0 ( 0.00) 0 ( 0.00) 0 ( 0.00) Heap 104326 ( 49.88) 7407146 ( 44.56) 0 ( 0.00) Btree 104816 ( 50.12) 9215394 ( 55.44) 0 ( 0.00) gen_random_uuid() with fpw=off N (%) (%) FPI (%) ---- - --- ----------- --- -------- --- XLOG 4 ( 0.00) 291 ( 0.00) 64 ( 0.84) Heap2 0 ( 0.00) 0 ( 0.00) 0 ( 0.00) Heap 107778 ( 49.88) 7654268 ( 46.08) 0 ( 0.00) Btree 108260 ( 50.11) 8956097 ( 53.91) 7556 ( 99.16)
,
gen_random_uuid
WAL - (full-page images, FPI), . , . FPW , , . , ZFS FPW, .
uuid_generate_v1()
– . uuid-ossp , RDS Citus Cloud, .
uuid_generate_v1:
MAC- . , UUID , , , , .
, , . - ,
uuid_generate_v1mc()
, mac- .
, , .
:
- .
-
<table_name>_id
uuid
uuid_generate_v1()
. . , JOIN, ..JOIN foo USING (bar_id)
JOIN foo ON (foo.bar_id = bar.id)
. . - , JOIN, .
- , URL . pg_hashids, .
-
ON UPDATE RESTRICT
, UUID , –ON UPDATE CASCADE
. , .
, . , - . , « » .
. -, , , - , ++ , 8 , DevOps . .