
約1か月前、Jupyterラップトップへのアクセスを提供するGoogleの共同サービスには、13 GBのビデオメモリを搭載したTesla K80 GPUを無料で使用できる機能が含まれていました。 これまで、ニューラルネットワークの世界に足を踏み入れる唯一の障害がGPUへのアクセスの欠如であったとしたら、「ディープラーニングを待ち続けてください!」と安全に言うことができます。
Colaboratoryを使用してkaggleのタスクに取り組んでみました。 何よりも、トレーニング済みのテンソルフローモデルを便利に保存し、テンソルボードを使用する機能がありませんでした。 この投稿では、経験を共有し、これらの機能をcolabに追加する方法を説明します。 最後に、sshを使用してコンテナにアクセスし、使い慣れた便利なツールbash、screen、rsyncを使用する方法を示します。
始めに、なぜそれが面白いのか
アクセラレーターGPUの存在は、ディープラーニングモデルの学習速度にとって重要な要素です。 GPUがなければ、ニューラルネットワークのトレーニングには数時間/日かかり、ネットワークの構造を完全に実験することはできません。 ビデオメモリの量も同様に重要です。 より多くのメモリ-より大きなバッチサイズを設定し、より複雑なモデルを使用できます。 今日、13Gは十分な量です。テーブルでほぼ同じ量を得たい場合は、GTX 1080 TiレベルGPUを購入する必要があります。
共同研究とは
これは、人気のあるJupyterノートブック環境のフォークです。 ラップトップは、Googleドライブを介して.ipynb形式でアクセスでき、ローカルで実行できます。 Python 2.7および3.6がサポートされています。 コードは、ドッカーコンテナ内のサーバーで実行されます。 ブラウザを閉じても、サーバー上のすべてのプロセスは引き続き動作し、後でサーバーに再度接続できます。 Dockerコンテナは、12時間の一時的な使用のために発行されます。 ルート権限があり、コンテナ内のプログラムをインストールして実行できます。 Colaboratory(以降colab)は、google docsなどのラップトップでのコラボレーションもサポートします。 これは、ディープラーニング、機械学習の学習を開始するための優れたプラットフォームです。 Open Machine Learningコースなどの多くの無料コースでは、トレーニング資料にJupyterノートブック形式を使用しています。
トレーニングを開始
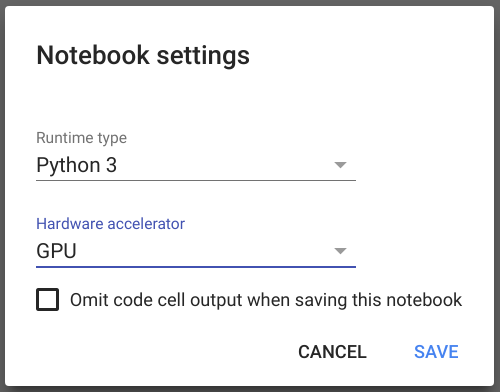
新しいラップトップを作成するには、リンクをクリックしてください 。 ログインに成功し、ラップトップを作成したら、メニューの[ランタイム]-> [ランタイムタイプの変更]を選択し、開いたダイアログの[ハードウェアアクセラレーション]オプションでGPUを設定して保存します。
その後、tensorflowがGPUを使用していることを確認できます。 このコードをラップトップの最初のセルにコピーし、 shift + Enterを押して実行します。
import tensorflow as tf tf.test.gpu_device_name()
ここで、例から単純なテンソルフローモデルを実行してみましょう。このために、githubリポジトリのクローンを作成し、スクリプトを実行します。
! git clone https://github.com/tensorflow/models.git %run models/samples/core/get_started/premade_estimator.py
このコマンドを実行すると、ネットワークが最初の予測を学習して行う方法がわかります。 Jupyterの機能を説明する資料はたくさんありますので、これについては詳しく説明しません。
Googleドライブをマウントする
すべてが正常に機能しますが、12時間後に仮想マシンが取得され、コンテナ内のすべてのデータが失われます。 永続的なストレージの世話をするのは良いことです。 クラウドストレージ、Googleシートからのインポートデータの使用方法に関する例がcolabにあります。 これは、コピー操作の明示的な呼び出しを意味しますが、コンテナ内のファイルシステムに外部ドライブをマウントし、GoogleドライブとFUSEドライバーを使用して解決したいと思います。 記事のレシピに従って 、コードを実行することでGoogleドライブに接続できます
!apt-get install -y -qq software-properties-common python-software-properties module-init-tools !add-apt-repository -y ppa:alessandro-strada/ppa 2>&1 > /dev/null !apt-get update -qq 2>&1 > /dev/null !apt-get -y install -qq google-drive-ocamlfuse fuse from google.colab import auth auth.authenticate_user() from oauth2client.client import GoogleCredentials creds = GoogleCredentials.get_application_default() import getpass !google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret} < /dev/null 2>&1 | grep URL vcode = getpass.getpass() !echo {vcode} | google-drive-ocamlfuse -headless -id={creds.client_id} -secret={creds.client_secret}
その後、コンテナを停止した後、安全にデータを失うことなくデータを記録できるディレクトリにアクセスできます。 モデル構成でmodel_dirパラメーターを定義できます。tensorflowは、最後のチェックポイントからモデルの状態を自動的に復元します。 したがって、いつでもモデルのトレーニングを続けたり、推論を実行したりできます。
テンソルボード
ニューラルネットワークの構造とパラメーターの実験でテンソルボードを使用するのが好きです。 このツールについて詳しく知りたい場合は、 プレゼンテーションをご覧になることをお勧めします。 そのため、コラボでテンソルボードを実行する方法についての機会を探していました。 答えはSOで見つかりました 。 LOG_DIR変数を使用して、モデルのtensorflow構成からmodel_dirへのパス、または多くの保存されたモデルを含むルートディレクトリへのパスを設定する必要があります。
LOG_DIR = '/tmp' get_ipython().system_raw( 'tensorboard --logdir {} --host 0.0.0.0 --port 6006 &' .format(LOG_DIR) ) ! wget -c -nc https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip ! unzip -o ngrok-stable-linux-amd64.zip get_ipython().system_raw('./ngrok http 6006 &') ! curl -s http://localhost:4040/api/tunnels | python3 -c \ "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
実行後、最後の行にURLが表示され、ブラウザーで開くと、使い慣れたテンソルボードが表示されます。
SSHアクセス
Jupyterの使用経験がある場合。 玩具モデルの範囲を超えて、ノートパソコンのjupyter形式のいくつかの利点が欠点になることをご存知でしょう。 ラップトップは読みにくいおridgeに変わり、計算結果の再現が難しくなります。 Jupyterラップトップは、トレーニング、視覚化、小規模な実験に最適なツールです。 ただし、中規模のプロジェクトでは、モジュールとクラスのパーティション分割を使用して、古典的な方法でPythonコードを構築することを好みます。 PyCharm / Vimなどで本格的なプロジェクトに取り組む方が便利です。リポジトリを介してコードを常に同期し、.pyファイルを実行することはjupyterではあまり便利ではありません。通常のツールを使用する方がはるかに便利です。
テンソルボードを起動する例に基づいて、コンテナへのsshトンネルを開くコードを作成しました。
#Generate root password import secrets, string password = ''.join(secrets.choice(string.ascii_letters + string.digits) for i in range(20)) #Download ngrok ! wget -q -c -nc https://bin.equinox.io/c/4VmDzA7iaHb/ngrok-stable-linux-amd64.zip ! unzip -qq -n ngrok-stable-linux-amd64.zip #Setup sshd ! apt-get install -qq -o=Dpkg::Use-Pty=0 openssh-server pwgen > /dev/null #Set root password ! echo root:$password | chpasswd ! mkdir -p /var/run/sshd ! echo "PermitRootLogin yes" >> /etc/ssh/sshd_config ! echo "PasswordAuthentication yes" >> /etc/ssh/sshd_config ! echo "LD_LIBRARY_PATH=/usr/lib64-nvidia" >> /root/.bashrc ! echo "export LD_LIBRARY_PATH" >> /root/.bashrc #Run sshd get_ipython().system_raw('/usr/sbin/sshd -D &') #Ask token print("Copy authtoken from https://dashboard.ngrok.com/auth") import getpass authtoken = getpass.getpass() #Create tunnel get_ipython().system_raw('./ngrok authtoken $authtoken && ./ngrok tcp 22 &') #Print root password print("Root password: {}".format(password)) #Get public address ! curl -s http://localhost:4040/api/tunnels | python3 -c \ "import sys, json; print(json.load(sys.stdin)['tunnels'][0]['public_url'])"
TCPトンネルを作成するには、 ngrok.comでアカウントを作成し、そこからauthtokenをコピーする必要があります。 ngrokの無料バージョンでは、2つのトンネルはサポートされていないため、テンソルボード上のhttpトンネルがまだ機能している場合は、無効にする必要があります。たとえば、 Ctrl + Mを押してコンテナーを再起動し、 「。」 。
トンネルを開始すると、ラップトップに次のようなものが表示されます
Root password: 3KTyBVjtD6zPZX4Helkj tcp://0.tcp.ngrok.io:15223
これで、動作中のコンピューターから任意のsshクライアントを使用してcolabコンテナーにログインでき、この例ではホスト0.tcp.ngrok.io、ポート15223になります。Linuxの例
ssh root@0.tcp.ngrok.io -p15223
kaglgleのボーナス。kaggleからデータをインポートし、 colaboratoryから直接送信するために、 pip install kaggleコマンドでインストールされた公式API クライアントを使用できます。