患者は医者に来て、腹痛を訴えます。 「緊急運用!」 -医師が答えます。 「今、私たちはあなたを切り刻み、身動きを取り、それをそのまま縫い付けようとします。」
ユーザーがシステムの動作を誓ってプログラマーの悪役を呼ぶと、イベントログを生成し、何が間違っているのかを確認しました。 そして、彼らはELKに切り替えました。 現在、サービスの作業を妨げることなく、エラーを瞬間的に監視しています。
この記事では、Javaおよび.NetプロジェクトでELKスタックを適応および適用し、オンラインモードでエラーを見つける方法を説明します。 はい、私たちはそれを理解し、Microsoftがこの決定を下したのかオープンソースをしたのかはさほど重要ではないことに気付きました。

どのプロジェクトについて話しているのですか?
徹底的:Javaの現実
私たちのJava製品は、連邦政府のチケットシステムです。 スムーズに動作するはずです。フリーズや作業の中断は受け入れられません。 また、障害が発生した場合、その理由を迅速かつ正確に理解する必要があります。これは、クライアントの生きているお金の損失だからです。
ここで、ELKはサポートチームのオンライン監視ツールとして機能します。 顧客が技術サポートに連絡したときに、議論しているデータ、暗号化キーなどを把握できるように、生データを記録します。
.Netプロジェクトの遡及的エラー分析
.Netプロジェクトは、主に販売サポートサービスと顧客です。 2万人以上が使用しています。 それもたくさんありますが、負荷はJavaほど大きくはありません。
エラーおよびビジネスオペレーションのダイナミクスを示す情報を記録します。 たとえば、サイトに登録したユーザーの数。 そして、2日間登録がなかったことがわかると、そこで何かが起こったことがすぐに明らかになります。 またはその逆-彼らは百万枚のチケットを販売し、これについての手紙を監督に送った、人を喜ばせた。
ELKとの連携方法
ロギング:Serilog + ELK
.Netプロジェクトでは、データを注ぐ機会が十分にあるため、主にSerilogも使用します。 Serilogは構造化された方法でログインできるため、ビートやLogstashを使用しても意味がありません。そのようなユーザーはそのようなときにシステムにログインします。 また、必要な情報(API、時間など)の値を構成することもできます。 そして、Elasticでログの書き込みを開始すると、これは文字列ではなく、検索するオブジェクトのプロパティにあります。 つまり、二重作業を除き、FilebeatとLogstashをバイパスします。
耐久モード
耐久モードと呼ばれるSerilogモードを使用します。Elasticがしばらく使用されている場合でも、メッセージの配信を保証します。 FilebeatにLogstashを加えたものとほぼ同じように機能します。最初にすべてをファイルに入れ、次にそれをElasticに緊急に配信しようとします。 Elasticに接続する頻度を設定できます。
ここで 、セットアップ手順を読むことができます。
ログコンテナ
Javaプロジェクトに関するログを大量に作成します(1日あたり最大5 GB)。 これらのファイルを5 MBの断片に分割し、スペースを節約して保存しやすくしました。 ELKは、コンピューターのDockerコンテナーに格納して持ち上げます。これにより、仮想マシンが簡単になります。誰かが既に設定してあります。
.NETプロジェクトでは、Javaプロジェクトのような大きなログではないため、サイズではなく日単位でファイルに勝っています。 そして、ログを分析し、エラーの種類を強調します。

Zabbixモニタリング
各エントリにはトレースIDがあり、ブラウザは操作の開始時間と終了時間を測定します。このデータをサーバーに記録し、Zabbixを介して監視します。
キバナ/グラファナ
Kibanaは、毎日のエラー監視に使用されます。 Kibanaでは、ログ検索を実行できます。 prodおよびテストサーバーでこの関数を使用します。 Grafanaもあります-彼女の視覚化は優れており、すべてのプロジェクトが1つのダッシュボードに表示されます。 ここですべてのデータを見ることができます。 すべてのエラーは赤でマークされています-これはKibanaに入り、詳細を確認する機会です。 エラーがどこにあるか、コード内でのその場所、発生したときの環境条件を確認します。 すべてのシステムをリンクする1つのIDがあり、完全なエラーパスを追跡できます。
エラーが不明な場合、より詳細に理解し始めます。 たとえば、最近、販売のために1つのビジネスプロセスを投稿しました。 顧客によるテストはうまくいきましたが、ログを見て、エラーがあることがわかりました。 すぐに修正しましたが、誰も気づきませんでした。
たとえば、このスクリーンショットでは、1つのプロジェクトの登録数を確認できます。
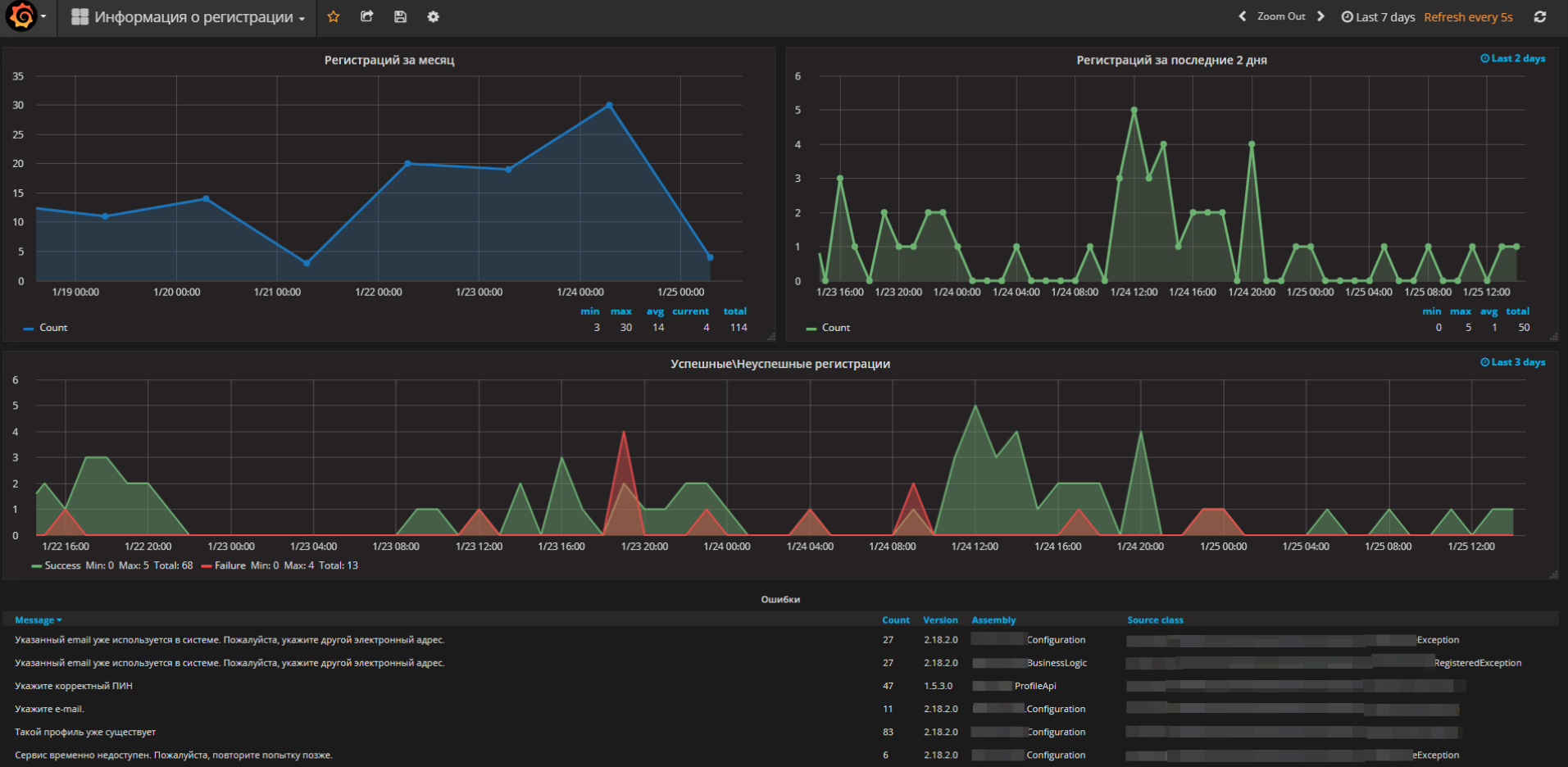
エラー分析
毎日ELKからすべてのエラーを受け取り、新しいエラーを特定し、分類し、同時に人間が読める名前を付けます。
すでに分類されたエラーのダイナミクスを観察し、バーストをキャッチし、原因を理解します。 テクニカルサポートエンジニアは、原因を取り除くためにタスクを開始します。 数千から数万の行を1日あたりのログで分析する必要があり、さらにJavaプロジェクトではさらに分析する必要があります。 多くのエラーが毎分繰り返されます。
多くのように、すべてのログを視覚的に表示することから始めました。 しかし、彼らは私たちのボリュームではそのように生きることは不可能だとすぐに気付きました。 そして、Kibanaから毎日のデータを取得し、それらからエラーを選択し、それらを既存のカテゴリに分類できるマクロを備えたExcelスプレッドシートをセットアップします。
その結果、Excelは、エラーごとにこのエラーが1日に何回発生したかに関する情報があるレポートを発行します。 別のリストにより、新しいエラーを取得し、最初にそれらを迅速に分析することができます-重大であるかどうか。
Kibanaでは、新しいエラーに関する詳細情報を確認します。
ファイルを作成できるもの:
- Elasticsearchから、適切な期間の適切なプロジェクトに適切なメッセージを1つのテーブルに取得します。 これを行うには、設定でソースデータを指定します。
- エラーに「名前」を割り当てます。 正規表現を使用して、検索パターンが指定され、人間が読み取れる指定が割り当てられます。 次に、ソーステーブルのパターンに一致するすべてのエラーにこの名前が付けられます。
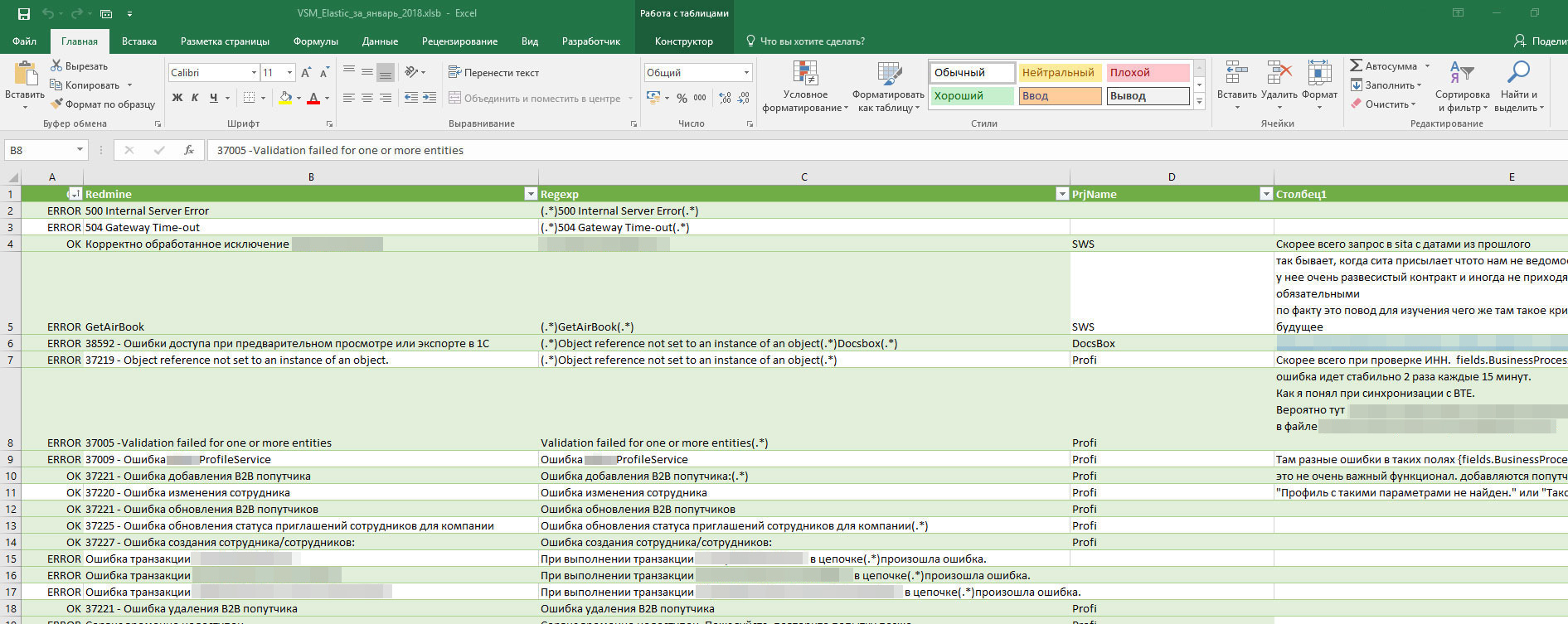
- OKおよびERRORカテゴリも割り当てられ、メッセージに注意を払う価値があるかどうかを示します。 これらのタイプでフィルタリングできます。 OTHER-プロジェクト上のメッセージの総数を表示します(エラーだけでなく、単なる情報)。 TFSで割り当てられたタスク番号(既に終了している場合)。
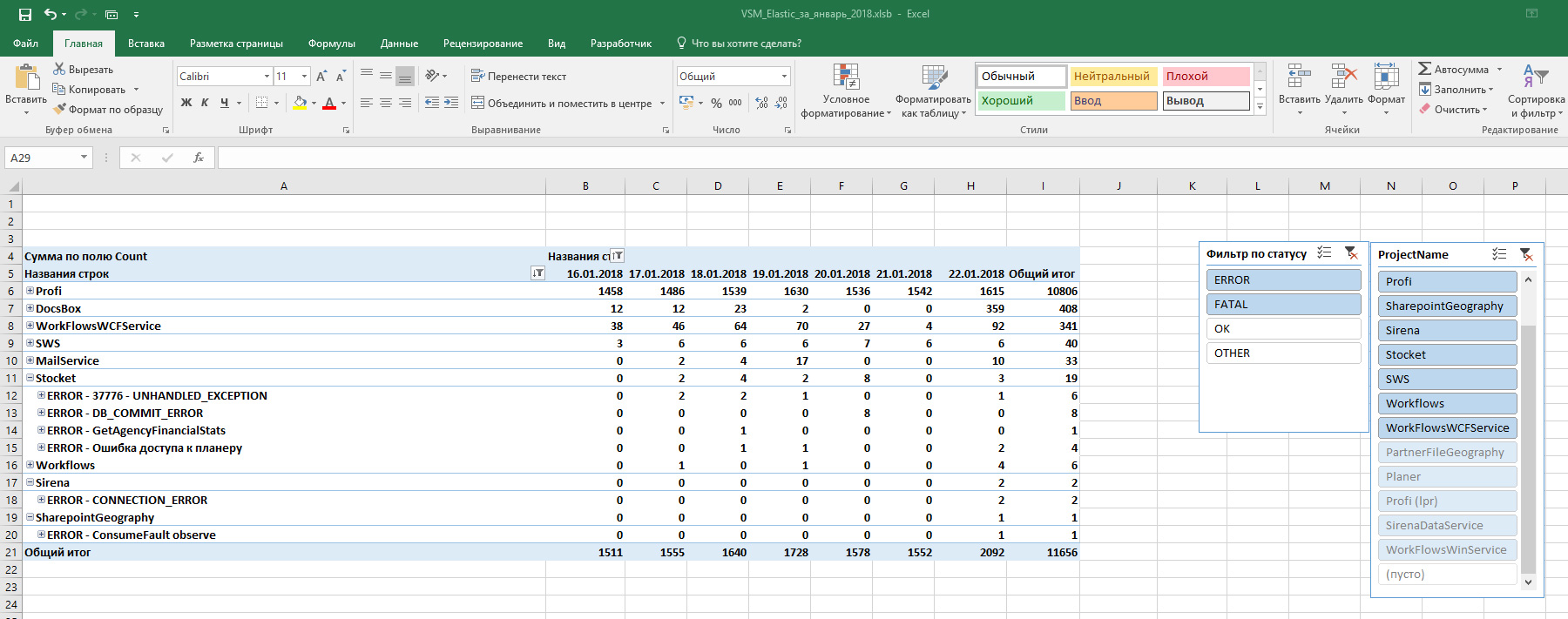
- フィルター機能を備えたより便利な分析のためにグラフがプロットされます。
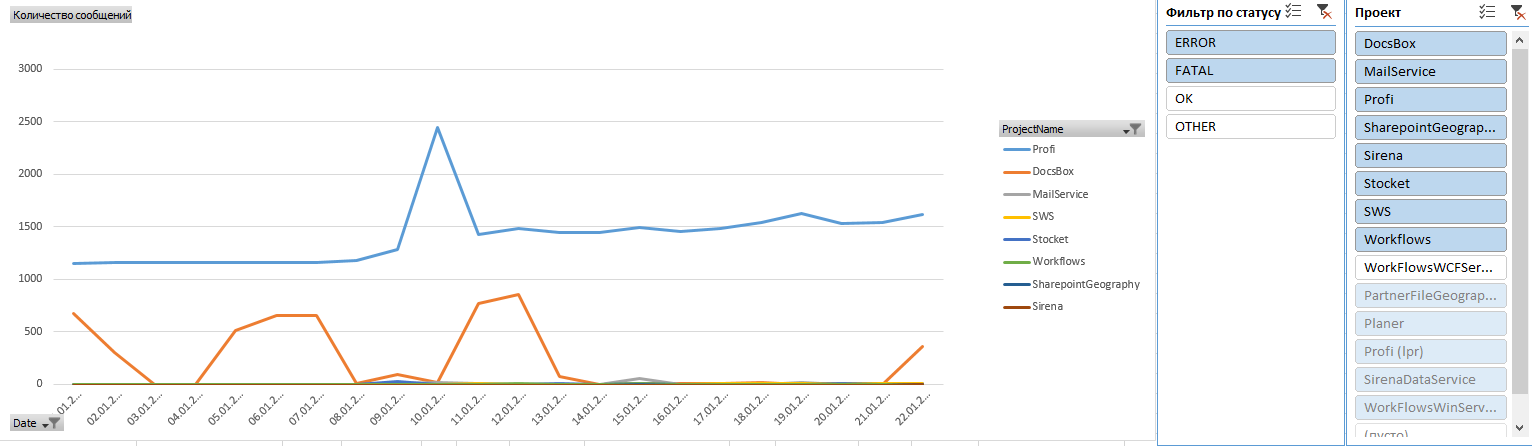
過去2日間のプロジェクトの新鮮なエラーの1つの例を見てみましょう。
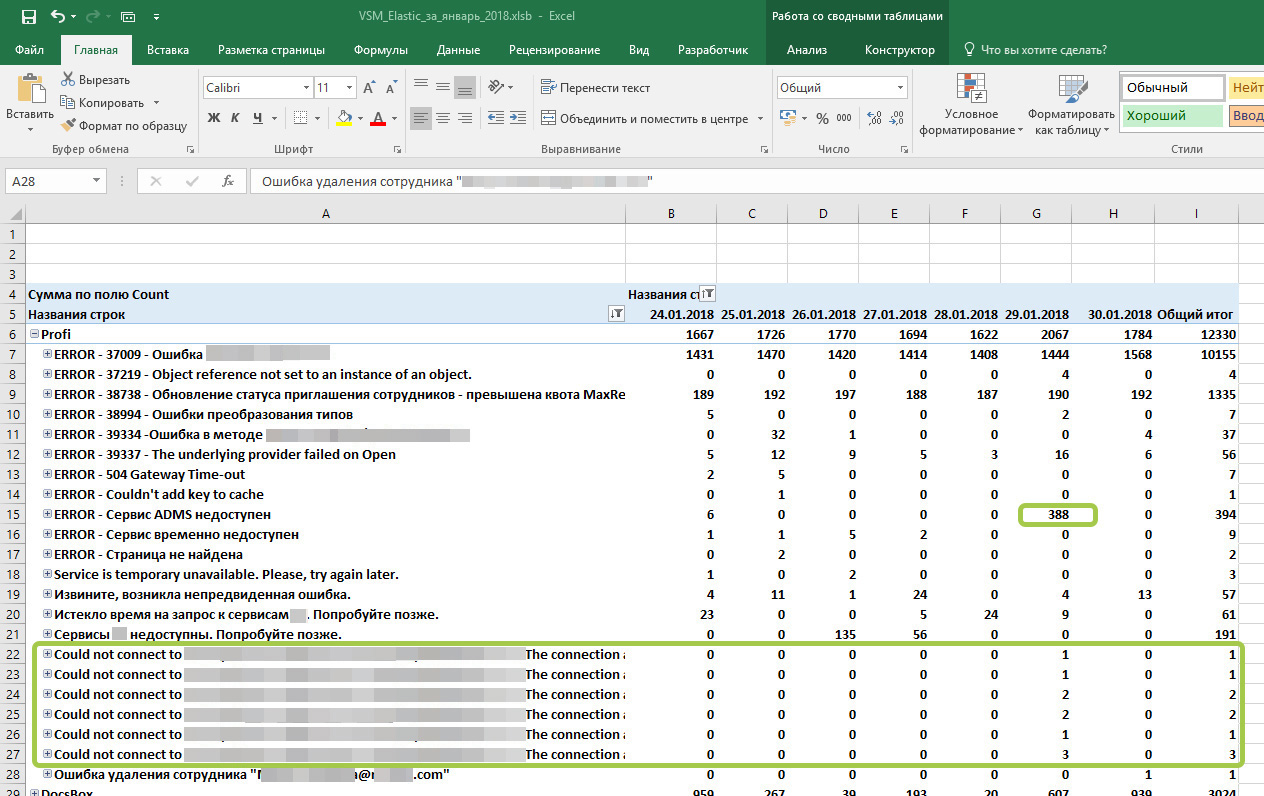
何が見えますか:
1)タスク番号が割り当てられている上部のエラーは重大ではありません。開発者は解決策を待っており、TFSからタスク番号が割り当てられています。
2)「ADMSサービスが利用できません」というエラーが1日388回発生しました-数時間サービスが利用できませんでした。
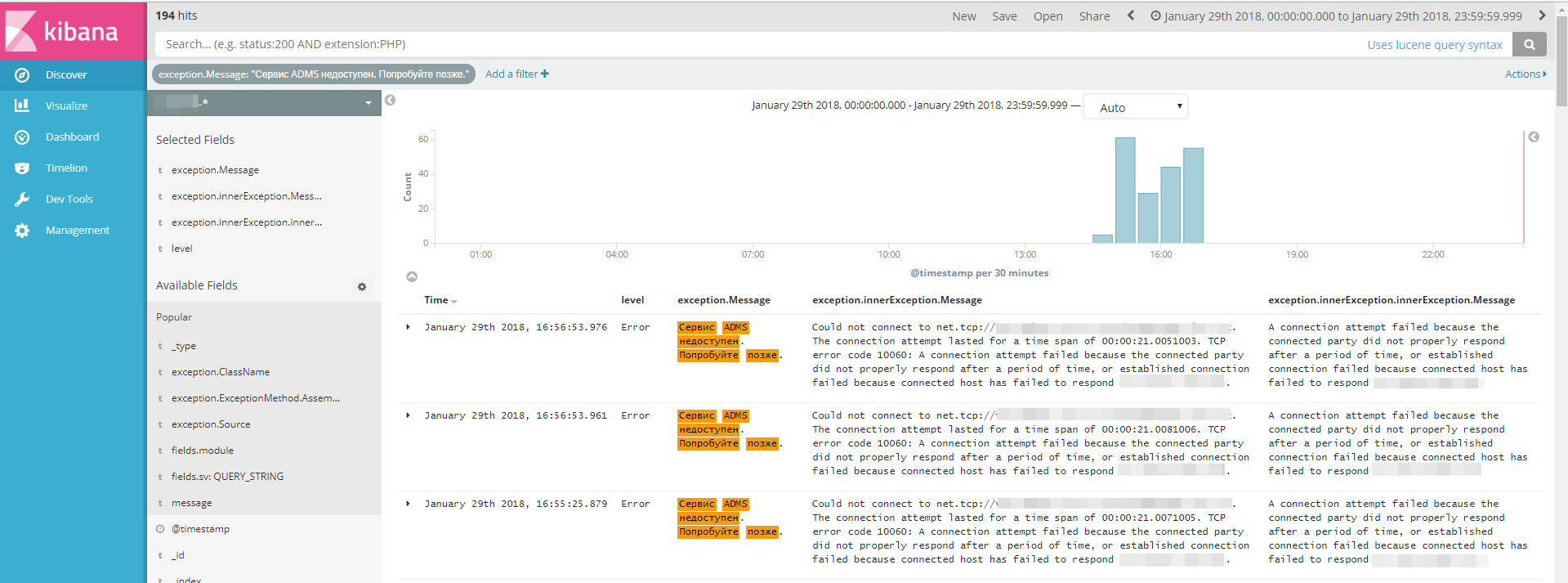
3)「接続できませんでした...」という新しいタイプのエラーが表示されました-以前のエラーと接続されており、単にもう1つの場所に記録されました。
これらの2種類のエラーを「調査」して、原因、再発の可能性、および将来的にそれらを防ぐ方法を見つけます。 これらのエラーは1行で「ロールアップ」されるように、共通の指定が与えられます。
改善する計画
現在、別のシステムで作業しています。スケジュールに従って、Elasticsearchからすべてのエラーを選択し、オペレーターに新しいエラーを通知し、エラーのバーストを通知します。 絶えず成長しているExcelファイルよりも高速に実行されます。 このシステムにより、1日だけでなく、異なる解像度でグラフを作成できます。 オペレーターは引き続き新しいエラーを分析し、名前を付けて予期しない状況に対応します。
PS今、ELKのおかげで、医師自身が患者が病気であることに気付き、すぐに診断を行い、有用な薬を投与することができます。