最近、Stackoverflow に関する質問に出くわしました。略語から元の単語を復元する方法です。たとえば、 wtrbtlから水のボトルを 、 bsktballからバスケットボールを取得します。 質問にはさらに複雑な問題がありました:すべての可能なソースワードの完全な辞書はありません。 アルゴリズムは新しい単語を思い付くことができるはずです。
この質問に興味をそそられ、現代のスペルチェッカーの根底にあるアルゴリズムと数学を理解することができました。 優れた愛人は、n-gram言語モデル、単語の歪みの確率のモデル、および貪欲なビーム検索アルゴリズムから組み立てることができることが判明しました。 構造全体を合わせて、 ノイズの多いチャネルモデルと呼びます。
この知識とPythonを武器に、夜中に「ロードオブザリング」(!)というテキストから学んだモデルをゼロから作成し、完全に現代的なスポーツ用語の略語を認識できました。
機会は、携帯電話のキーボードから検索エンジンや音声アシスタントまで、多くの場合に使用されます。 優れたグリーバーサーを作るのはそれほど簡単ではありません。なぜなら、彼は迅速かつ何に対しても準備ができている必要があるからです。 それがまさにグリーバーで多くの科学が使われている理由です。 この記事の目的は、この科学についてのアイデアを提供し、ただ楽しむことです。
ガード内の数学
ノイズの多いチャネルモデルは、各略語を元のフレーズのランダムな歪みの結果と見なします。
元のフレーズを復元するには、2つの質問に答える必要があります。どのソースワードがありそうか、どのようなフレーズの歪みがありそうですか。
ベイズの定理により、
p(フレーズ|略語) simp(フレーズ)p(略語|フレーズ)=
=p(フレーズ) sump(変換|フレーズ)
どこで 変換 オリジナルにそのような変更はありますか フレーズ 観測可能になります 略語 。 記号 sim は直接比例を示します。
統計モデルを使用して、あらゆる種類のフレーズの確率と変換の確率の両方を推定できます。 最も単純な種類のモデル-文字n-gramを使用します。 より複雑なモデル(リカレントニューラルネットワークなど)を適用することも可能ですが、これは基本的に何も変更しません。
このようなモデルでは、貪欲な方向探索アルゴリズムであるビーム検索を使用して、最も可能性の高いソースフレーズを文字ごとに選択できます。
Nグラム言語モデル
フレーズの前のn-1文字からのn-gramモデルは、次のn番目の文字の確率を決定します(そして、それらの前にあったすべての文字を無視します)。 たとえば、シーケンス「bowlin」の後の文字「g」の確率は、4-gモデルによって次のように計算されます。 p(g|bowlin)=p(g|lin) なぜなら これらの4つに先行するすべての文字は、簡単にするためにモデルによって無視されます。 このような条件付き確率は、テキストのトレーニングコーパスによって決定(「学習」)されます。 例を続けると、
p(g|lin)= frac\#(ling)\#(lin bullet)= frac\#(ling)\#(lina)+\#(linb)+ #(linc)+...
どこで \#(ling) トレーニングビルディング内のlingの組み合わせの数、および \#(lin bullet) -「lin」で始まるテキスト内のすべての4グラムの数。
まれなn-gramの確率をより適切に評価するために、2つのトリックを適用しました。 まず、各カウンターに数字を追加します \デルタ -これにより、ゼロで除算しないことが保証されます。 第二に、計算には、n-gram(テキストでは小さいかもしれません)だけでなく、(n-1)-gram(より一般的です)なども使用します。コンテキストを調べます。 しかし、より小さな次数のカウンターが使用され、重みはペースとともに指数関数的に減少します。 alpha 。 したがって、実際には、確率 p(g|lin) 計算方法
p(g|lin)= frac(\#(ling)+1)+ alpha(\#(ing)+1)+ alpha2(\#(ng)+1)+ alpha3(\#(g)+1)(\#(lin bullet)+1)+ alpha(\#(in bullet)+1)+ alpha2(\#(n bullet)+1)+ alpha3(\#( bullet)+1)
しかし、かなり理論的です! Pythonでモデルコードがどのように見えるかをよく見てみましょう
from collections import defaultdict, Counter import numpy as np import pandas as pd class LanguageNgramModel: """ , . : order - ( ), n-1 smoothing - , recursive - , : counter_ - n-, . vocabulary_ - , """ def __init__(self, order=1, smoothing=1.0, recursive=0.001): self.order = order self.smoothing = smoothing self.recursive = recursive def fit(self, corpus): """ : corpus - . """ self.counter_ = defaultdict(lambda: Counter()) self.vocabulary_ = set() for i, token in enumerate(corpus[self.order:]): context = corpus[i:(i+self.order)] self.counter_[context][token] += 1 self.vocabulary_.add(token) self.vocabulary_ = sorted(list(self.vocabulary_)) if self.recursive > 0 and self.order > 0: self.child_ = LanguageNgramModel(self.order-1, self.smoothing, self.recursive) self.child_.fit(corpus) def get_counts(self, context): """ , : context - ( self.order ) : freq - , pandas.Series """ if self.order: local = context[-self.order:] else: local = '' freq_dict = self.counter_[local] freq = pd.Series(index=self.vocabulary_) for i, token in enumerate(self.vocabulary_): freq[token] = freq_dict[token] + self.smoothing if self.recursive > 0 and self.order > 0: child_freq = self.child_.get_counts(context) * self.recursive freq += child_freq return freq def predict_proba(self, context): """ , : context - ( self.order ) : freq - , pandas.Series """ counts = self.get_counts(context) return counts / counts.sum() def single_log_proba(self, context, continuation): """ . : context - , continuation - , """ result = 0.0 for token in continuation: result += np.log(self.predict_proba(context)[token]) context += token return result def single_proba(self, context, continuation): """ . : context - , continuation - , """ return np.exp(self.single_log_proba(context, continuation))
タイプミスモデル
元のフレーズが通常何であるかを理解するには、言語モデルが必要でした。 元のフレーズが通常どのように歪んでいるかを理解するには、歪みモデルが必要です。
考えられる唯一の歪みは、フレーズから一部の文字を削除することであると想定します。 必要に応じて、文字の置換や再配置など、他の歪みを考慮してモデルを変更できます。
複雑なモデルをトレーニングするための大きなサンプルがありません。 したがって、歪みの確率を評価するために、1グラムを使用します。 つまり、私のモデルは、各文字について、略語から削除される確率を単純に記憶します。 ただし、万が一の場合に備えて、n-gramモデルとしてコーディングします。
class MissingLetterModel: """ , : order - , n+1 smoothing_missed - , smoothing_total - , """ def __init__(self, order=0, smoothing_missed=0.3, smoothing_total=1.0): self.order = order self.smoothing_missed = smoothing_missed self.smoothing_total = smoothing_total def fit(self, sentence_pairs): """ : sentence_pairs - ( , ) . """ self.missed_counter_ = defaultdict(lambda: Counter()) self.total_counter_ = defaultdict(lambda: Counter()) for (original, observed) in sentence_pairs: for i, (original_letter, observed_letter) in enumerate(zip(original[self.order:], observed[self.order:])): context = original[i:(i+self.order)] if observed_letter == '-': self.missed_counter_[context][original_letter] += 1 self.total_counter_[context][original_letter] += 1 def predict_proba(self, context, last_letter): """ , last_letter context""" if self.order: local = context[-self.order:] else: local = '' missed_freq = self.missed_counter_[local][last_letter] + self.smoothing_missed total_freq = self.total_counter_[local][last_letter] + self.smoothing_total return missed_freq / total_freq def single_log_proba(self, context, continuation, actual=None): """ , context continuation actual actual , , continuation . """ if not actual: actual = continuation result = 0.0 for orig_token, act_token in zip(continuation, actual): pp = self.predict_proba(context, orig_token) if act_token != '-': pp = 1 - pp result += np.log(pp) context += orig_token return result def single_proba(self, context, continuation, actual=None): """ , context continuation actual actual , , continuation . """ return np.exp(self.single_log_proba(context, continuation, actual))
モデルの例
言語モデルと略語モデルの仕組みを理解するために、簡単な例を見てみましょう。 1つの単語で言語モデルを教え、単語「bra」の継続を予測する方法を確認します。 彼女の観点からすると、「b」はもっともらしい続編です(この手紙は「a」の後に来ることが最も多いため)。
lang_model = LanguageNgramModel(1) lang_model.fit(' abracadabra ') print(lang_model.predict_proba(' bra'))
0.181777 a 0.091297 b 0.272529 c 0.181686 d 0.181686 r 0.091025 dtype: float64
また、1つの例(単語、略語)を使用して略語モデルをトレーニングします。 この例では、文字「a」のみを削減したため、モデルでは削減の可能性が高いと推定され、文字「b」は低くなります。 モデルでは、文字「c」が欠落する確率は「b」よりも高いと推定されました。これは、トレーニング例で「c」が表示される可能性が低いためです。
missed_model = MissingLetterModel(0) missed_model.fit([('abracadabra', 'abr-cd-br-')]) print({letter: missed_model.predict_proba('abr', letter) for letter in 'abc'})
{'a': 0.7166666666666667, 'b': 0.09999999999999999, 'c': 0.15}
したがって、略語モデルは、「abra」が「abr-」と略される可能性を推定します
print(missed_model.single_proba('', 'abra', 'abr-'))
0.164475
最も可能性の高いフレーズの貪欲な検索
言語と歪みのモデルがあるため、ソースフレーズの可能性を理論的に評価することが可能です。 これを行うには、 すべての可能なペア(元のフレーズ、変換)を整理し、それぞれの可能性を評価する必要があります。 しかし、それらは多すぎます。たとえば、27文字のアルファベットでは可能です 2710 10文字のフレーズ。 それらをすべて整理するのは非現実的です。 より巧妙なアルゴリズムが必要です。
両方のモデルが1文字であるという事実を利用し、元のフレーズの文字を次々に選択します。 これを行うために、 一連の不完全な候補フレーズを開始し、それぞれについて、略語にどれだけ対応するかを評価します。 最適な候補を、それらが省略されてヒープに追加されたかどうかに関するさまざまな継続文字と仮説で補完します。 あまり多くのオプションを作成しないために、「十分な」続編のみを使用します。 すでに完全なソースフレーズになっている可能性のある候補者は脇に置き、最終的に回答として提供します。 ヒープまたは最大反復回数が終了するまで手順を繰り返します。
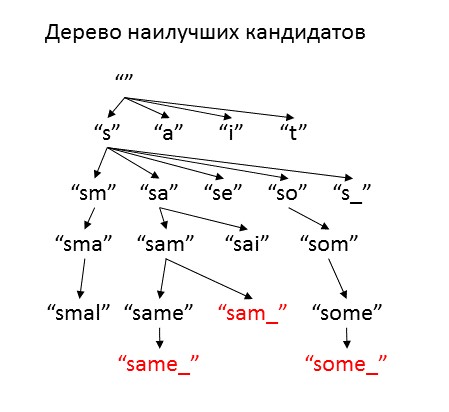
候補の品質の尺度として、既存の略語の確率の対数の推定値を使用します。ただし、元のフレーズはこの候補から始まり、略語自体で終了します。 検索を制御するために、 楽観主義と自由という 2つのパラメーターを導入します。 楽観主義は、略語の終わりに到達したときに復号化がどのように改善されるかを評価します。 この係数は0から1の間で選択するのが理にかなっており、1に近いほど、アルゴリズムは復号化に新しい文字を追加しようとする速度が速くなります。 自由度とは、候補の品質が現在の最適なオプションよりもどれだけ悪いかであり、このパラメーターが増加すると、アルゴリズムはより多くの異なるオプションを考慮します。 非常に高い自由度の値を設定すると、アルゴリズムはすべてのオプション(無限大)を繰り返し処理し、非常に長い時間動作しますが、 自由度の値が小さいと、少なくとも1つの適切なオプションが見つかる前にヒープが終了します。
from heapq import heappush, heappop def generate_options(prefix_proba, prefix, suffix, lang_model, missed_model, optimism=0.5, cache=None): """ ( ) : prefix_proba - prefix - suffix - lang_model - missed_model - optimism - , cache - : ( , , , , ) """ options = [] for letter in lang_model.vocabulary_ + ['']: if letter: # , next_letter = letter new_suffix = suffix new_prefix = prefix + next_letter proba_missing_state = - np.log(missed_model.predict_proba(prefix, letter)) else: # , next_letter = suffix[0] new_suffix = suffix[1:] new_prefix = prefix + next_letter proba_missing_state = - np.log((1 - missed_model.predict_proba(prefix, next_letter))) proba_next_letter = - np.log(lang_model.single_proba(prefix, next_letter)) if cache: proba_suffix = cache[len(new_suffix)] * optimism else: proba_suffix = - np.log(lang_model.single_proba(new_prefix, new_suffix)) * optimism proba = prefix_proba + proba_next_letter + proba_missing_state + proba_suffix options.append((proba, new_prefix, new_suffix, letter, proba_suffix)) return options
コードを注意深く読んでいると、別の単純化が行われていることに気付くでしょう。元の単語のすべての歪みの確率を合計するのではなく、歪みを1つだけと考えています。 これは常に正しいとは限りません。たとえば、「ボール」は、最初の文字(「b-l」)と2番目の文字(「bl-」)の両方を削除することで「bl」に短縮できます。 しかし、そのような繰り返しがない場合、ほとんどの場合、適切な削減オプションが唯一の選択肢です。
def noisy_channel(word, lang_model, missed_model, freedom=3.0, max_attempts=10000, optimism=0.9, verbose=False): """ , word : word - lang_model - missed_model - freedom - max_attempts - optimism - , verbose - : - - . , . """ query = word + ' ' prefix = ' ' prefix_proba = 0.0 suffix = query full_origin_logprob = -lang_model.single_log_proba(prefix, query) no_missing_logprob = -missed_model.single_log_proba(prefix, query) best_logprob = full_origin_logprob + no_missing_logprob # heap = [(best_logprob * optimism, prefix, suffix, '', best_logprob * optimism)] # - candidates = [(best_logprob, prefix + query, '', None, 0.0)] if verbose: print('baseline score is', best_logprob) # cache = {} for i in range(len(query)+1): future_suffix = query[:i] cache[len(future_suffix)] = -lang_model.single_log_proba('', future_suffix) # rough approximation cache[len(future_suffix)] += -missed_model.single_log_proba('', future_suffix) # at least add missingness for i in range(max_attempts): if not heap: break next_best = heappop(heap) if verbose: print(next_best) if next_best[2] == '': # # , if next_best[0] <= best_logprob + freedom: candidates.append(next_best) # if next_best[0] < best_logprob: best_logprob = next_best[0] else: # it is not a leaf - generate more options prefix_proba = next_best[0] - next_best[4] # all proba estimate minus suffix prefix = next_best[1] suffix = next_best[2] new_options = generate_options(prefix_proba, prefix, suffix, lang_model, missed_model, optimism, cache) # add only the solution potentioally no worse than the best + freedom for new_option in new_options: if new_option[0] < best_logprob + freedom: heappush(heap, new_option) if verbose: print('heap size is', len(heap), 'after', i, 'iterations') result = {} for candidate in candidates: if candidate[0] <= best_logprob + freedom: result[candidate[1][1:-1]] = candidate[0] return result
アルゴリズムを使用して、略語「brc」の可能なデコードを検索します。
result = noisy_channel('brc', lang_model, missed_model, verbose=True, freedom=1) print(result)
baseline score is 7.68318306228 (6.9148647560475442, ' ', 'brc ', '', 6.9148647560475442) (6.755450684372974, ' b', 'rc ', '', 4.7044649199466617) (5.8249119494605051, ' br', 'c ', '', 2.6863637325526679) (7.088440394887126, ' brc', ' ', '', 1.7075575253192956) (7.1392598304831516, ' bra', 'c ', 'a', 2.6863637325526679) (7.6831830622750497, ' brc ', '', '', -0.0) (8.0284469273601662, ' brac', ' ', '', 1.7075575253192956) (8.3621576081202385, ' a', 'brc ', 'a', 6.776535093383159) (7.6954572168460142, ' ab', 'rc ', '', 4.7044649199466617) (6.7649184819335453, ' abr', 'c ', '', 2.6863637325526679) (8.0284469273601662, ' abrc', ' ', '', 1.7075575253192956) (8.0792663629561936, ' abra', 'c ', 'a', 2.6863637325526679) (8.6231895947480908, ' abrc ', '', '', -0.0) (8.6231895947480908, ' brac ', '', '', -0.0) (8.6740629096242063, ' brca', ' ', 'a', 1.7075575253192956) heap size is 0 after 15 iterations {'brc': 7.6831830622750497, 'abrc': 8.6231895947480908, 'brac': 8.6231895947480908}
ホビットのテスト
優れた言語モデルでのみ、書かれたアルゴリズムを真にテストできます。 意図的に限定されたケース-1冊の本、さらには特定のトピックで勉強して、モデルがどの程度定性的に略語を解読できるのか疑問に思っていました。 私の腕に来た最初の本は、指輪物語:指輪の交わりです。 さて、ホビット言語が現代のスポーツ用語を解読するのにどのように役立つかを見てください。
はじめに-モデルをトレーニングするためのコード
import re # with open('Fellowship_of_the_Ring.txt', encoding = 'utf-8') as f: text = f.read() # text2 = re.sub(r'[^az ]+', '', text.lower().replace('\n', ' ')) all_letters = ''.join(list(sorted(list(set(text2))))) print(repr(all_letters)) # ' abcdefghijklmnopqrstuvwxyz' # : missing_set = ( [(all_letters, '-' * len(all_letters))] * 3 # + [(all_letters, all_letters)] * 10 # + [('aeiouy', '------')] * 30 # ) # big_lang_m = LanguageNgramModel(order=4, smoothing=0.001, recursive=0.01) big_lang_m.fit(text2) big_err_m = MissingLetterModel(order=0, smoothing_missed=0.1) big_err_m.fit(missing_set)
' abcdefghijklmnopqrstuvwxyz'
私は、「テストサンプル」上のさまざまなモデルの可能性を比較することにより、4グラム言語モデルを選択しました-本の最後です。 モデルの次数を4に増やすと、文字の確率を予測する品質が向上することがわかりました。次数を増やすと、モデルの速度が低下するため、さらに高い次数を使用しませんでした。
for i in range(5): tmp = LanguageNgramModel(i, 0.001, 0.01) tmp.fit(text2[0:-5000]) print(i, tmp.single_log_proba(' ', text2[-5000:]))
0 -13858.8600648 1 -11608.8867664 2 -9235.21749986 3 -7461.78935696 4 -6597.9544372
アルゴリズムをさまざまな略語に適用します。 たとえば、Samは私にとって間違いを犯しました。モデルは問題なく認識され、他のオプションを追加しました(ただし、速度が速いほど、信頼性が低くなります)。
noisy_channel('sm', big_lang_m, big_err_m)
{'sam': 7.3438449620080997, 'same': 9.5091694602417469, 'some': 7.6890573935288824}
フロドも問題なく認識されます。
noisy_channel('frd', big_lang_m, big_err_m)
{'frodo': 6.8904938902680888}
リングは明確に推測されます。
noisy_channel('rng', big_lang_m, big_err_m)
{'ring': 7.6317120419343913}
wtrbtlを実行する前に、部分的に復号化を確認してください。 すべては水で大丈夫です。
noisy_channel('wtr', big_lang_m, big_err_m)
{'water': 8.6405279255413898}
モデルはボトルをそれほど自信を持って認識しません。 それでも、ロード・オブ・ザ・リングの戦いはボトルよりも頻繁に言及されています。
noisy_channel('btl', big_lang_m, big_err_m)
{'battle': 12.620490427990008, 'bottle': 13.3327872548629, 'but all': 14.66815480120338, 'but ill': 15.387630853411283}
たとえば、そのようなフレーズでは:
noisy_channel('batlhrse', big_lang_m, big_err_m)
{'battle horse': 25.194823785457018, 'battle horses': 27.40528952535044}
水筒には多くの選択肢がありました:
noisy_channel('wtrbtl', big_lang_m, big_err_m)
{'water battle': 23.76999162985074, 'water bottle': 23.962598992336815, 'water but all': 24.445047133561353, 'water but ill': 25.164523185769259, 'water but lay': 25.601336188357113, 'water but lie': 26.668305553728047}
しかし、バスケットボール(見たことがない)は、トレーニングテキストで「バスケット」という単語が使用されていたため、モデルによってほぼ正しく認識されました。 しかし、これを行うには、モデルがオプションを選択する「ビーム」の幅を手動で増やす必要がありました。
print(noisy_channel('bsktball', big_lang_m, big_err_m, freedom=5))
{'bsktball': 33.193085889457429, 'basket ball': 33.985227947093364}
しかし、トレーニングテキスト内の単語「ボール」は一度も発生せず、モデル自体はそれを復元しませんでした(ただし、「bl」のビルボの名前が疑われました)。 「ロード・オブ・ザ・リング」の「ボウリング」という言葉も決して発生しませんでしたが、言語の一般的な考えに基づいて、モデルはそれを提案しました。
print(noisy_channel('bwlingbl', big_lang_m, big_err_m, freedom=5))
{'bwling blue': 31.318936077746862, 'bwling bilbo': 30.695249686758611, 'bwling ble': 34.490254059547475, 'bwling black': 31.980325659562851, 'bwling blow': 33.15061216480305, 'bewilling blue': 30.937989778499748, 'bewilling bilbo': 30.314303387511497, 'bewilling ble': 34.109307760300361, 'bewilling black': 31.599379360315737, 'bewilling blin': 34.685939493896406, 'bewilling blow': 32.769665865555929, 'bewilling bill': 32.156071732628014, 'bewilling below': 32.195518180732158, 'bwling bill': 32.537018031875135, 'bewilling belia': 32.550377929021479, 'bwling below': 32.576464479979279, 'bwling belia': 32.931324228268608, 'bwling belt': 33.203704016765826, 'bwling bling': 33.393527121566656, 'bwling bell': 34.180762531759534, 'bowling blue': 30.676613106535022, 'bowling bilbo': 30.052926715546771, 'bowling ble': 33.847931088335635, 'bowling black': 31.338002688351011, 'bowling blin': 34.42456282193168, 'bowling blow': 32.508289193591203, 'bowling bill': 31.894695060663285, 'bowling below': 31.934141508767446, 'bowling bl': 34.983414721126472, 'bowling blad': 34.992926061009179, 'bowling belia': 32.289001257056761, 'bwling blind': 35.000922570770712}
頑固なテキストの生成
最後に、少し元気づけるために、私はすでに「ロード・オブ・ザ・リング」というテキストの一部をカットに変えようとしました。 奇妙なことが判明した。
part = text[10502:11149] result = '' for i, letter in enumerate(part): if np.random.rand() * 0.5 < big_err_m.single_proba(part[0:i], letter): result += letter print(result)
This bok s largly cncernd wth Hbbts, nd frm its pges readr ma dscver much f thir charctr nd littl f thir hstr. Furthr nfrmaton will als b fond n the selction from the Red Bok f Wstmarch that hs already ben publishd, ndr th ttle of The Hobbit. Tht stor was dervd from the arlir chpters of the Red Bok, cmpsed by Blbo hmslf, th first Hobbit t bcome famos n the world at large, nd clld b him There and Bck Again, sinc thy tld f his journey into th East and his return: n dvntr whch latr nvolved all the Hobbits n th grat vnts of that Ag that re hr rlatd.
ただし、言語モデルを使用して、「トールキンスタイル」のテキストを生成できますが、意味はありません。
np.random.seed(20) text = "Frodo" for i in range(300): proba = big_lang_m.predict_proba(text) text += np.random.choice(proba.index, size=1, p=proba)[0] print(text+'.')
Frodo would me but them but his slipped in he see said pippin silent the names for follow as days are or the hobbits rever any forward spoke ened with and many when idle off they hand we cried plunged they lit a simply attack struggled itself it for in a what it was barrow the will the ears what all grow.
データサイエンスは、一貫したテキストをゼロから生成する方法をまだ学習していません。 そのためには、プロットを理解した真の人工知能が必要であり、中つ国で一度展開されます。
おわりに
自然言語処理は、実際には科学、技術、および魔法の非常に複雑な混合物です。 言語学者でさえ、どのスピーチが組織されているかによって法律を完全に理解していない。 そして、機械が言葉の完全な意味でテキストを理解することができるそれらの日まで、それは非常にすぐではありません。
自然言語処理も楽しいです。 一対の統計モデルで武装しているため、非自明な略語を認識して生成することができます。 私の楽しみを続けたい人のために、 ここに完全な実験コードがあります。
しかし、n-gramモデルをリカレントニューラルネットワークに置き換えると、より高度な接続性(およびほとんどコンパイルされたコード)のテキストを生成できます。 近い将来、 ニューロンを使用してHabr(既に解析済み )のスタイルで典型的な記事を生成しようとするので、購読して待ってください:)