畳み込みニューラルネットワーク(CNN)の利点、問題、および制限は、現在かなりよく理解されています。 エンジニアのコミュニティがそれらを認識してから約5年が経過し、「今、すべての問題を解決します」という第一印象はすでに過ぎています。 だから、AIの次の一歩を踏み出すアイデアを探す時です。 たとえば、ヒントンはCapsuleNetを提案しました 。
アレクセイ・レドズボフと一緒に、脳の構造についての彼の考えに頼って、私たちは主流からも後退することを決めました。 そして今、私は見せたいものがあります:アーキテクチャ(注意を引くためにタイトル画像とともに表示されます)とMNISTのTensorflow ソース 。
より正式には、結果はarxivに関する記事に記載されています 。
なんで?
常にすべてにおいて、あいまいさに対処します。 情報が感覚器官から離れるほど、その解釈の選択肢が増えます。 ビジョンは私たちを失敗させないようです。 しかし、そうではありません。これがそうではないことを示す多くの幻想があります。 凹面マスクの錯視 (深さの凹面であることに気付くには非常に努力する必要があります)、有名な白青茶色のドレス。 うわさには、視覚的な幻想以上のものがある同じ話があります 。 これについておめでとうございます 。 そして、情報の知覚の問題が抽象的な概念に関する場合、政治に関する果てしない議論を思い出さずにはいられません。
コンテキストに応じて観察対象の意味を変更するこの原則は、何らかの方法で普遍的であり、私たちが扱っているすべての情報に対して実装されています。 また、同時に、機械学習のほとんどのアプローチにあまり反映されていないか、明示的に反映されていません。 多くの場合、機械学習タスクの定式化は、さまざまな解釈の可能性を排除します。 ただし、畳み込みネットワークの概念を別の角度から見ると、1つの畳み込み層の問題ステートメントは次のように定式化されていることがわかります:サイズ(MxM)のK個の特徴を、それらがどの位置(空間コンテキスト)にあるかに関係なく選択する必要がある ただし、X、Yに沿った転送操作が事前にプログラムされていないことが想定される場合、タスクは非常に重要になります。 リカレントネットワークでも同様に、どの時点T(時間のコンテキスト)で出現したかに関係なく、シーケンスを時間で区別する必要があります。
さらに、トレーニング後、コンテキストの変更によりデータがどのように変化するかについてのアイデアを使用できます。 人に4つの側面から新しい車のモデルを見せます。彼は後でランダムな角度からの視点で簡単にそれを認識します。 子供は相互作用の社会モデルが動物によって実証される漫画を見るでしょう、彼が人々との関係で同じ状況を認識することは難しくありません。 これは非常に強力で普遍的な原理であるため、なぜそれほど注意が払われないのか、個人的には驚いています。
強力な人工知能は、さまざまなコンテキストであらゆる処理レベルの情報を提示し、観察された状況とトレーニングの結果として得られた経験に最適なコンテキストを選択する能力によって正確に区別されると確信しています。
たたみ込みネットワーク(または、ネオコグニトロン)のインスピレーションの源は、ヒューベルとヴィーゼルの研究でした。彼らは、かつて視覚野V1とその中のミニコラムの機能について非常に効果的な研究を行い、ノーベル賞を受賞しました。 しかし、彼らの実験の結果は別の方法で解釈することができます。 詳細はこちら 。
ヒントンのカプセルネットワークは、ミニカラムの機能を再考する方法でもあります。
ミニカラムの機能を仮定します
大脳皮質は構造的にさまざまな機能を持つゾーンで構成されていますが、同時に、ゾーンに関係なく、ミニカラムは構造的に際立っています-ニューロンの列、その間の垂直接続は水平のものより密です。
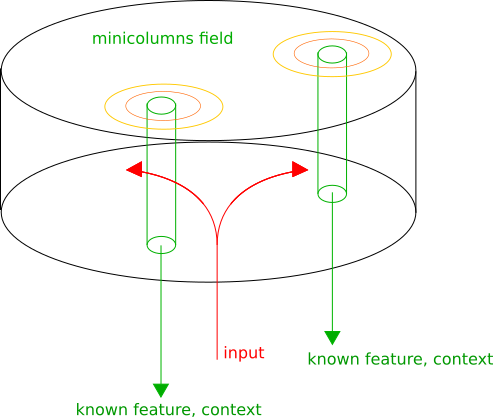
ミニカラムは、独自のコンテキストで入力を提示すると想定しています。 次に、各ミニカラムで既知のパターンが認識され、そのアクティビティは認識の信頼性の程度に比例します。 隣接するミニ列は同様の変換を表します。これにより、入力情報が解釈される最適なコンテキストに対応する皮質の局所活動の最大値を選択できます。 皮質領域の出力はリストになります:(認識されたパターン、コンテキスト)。
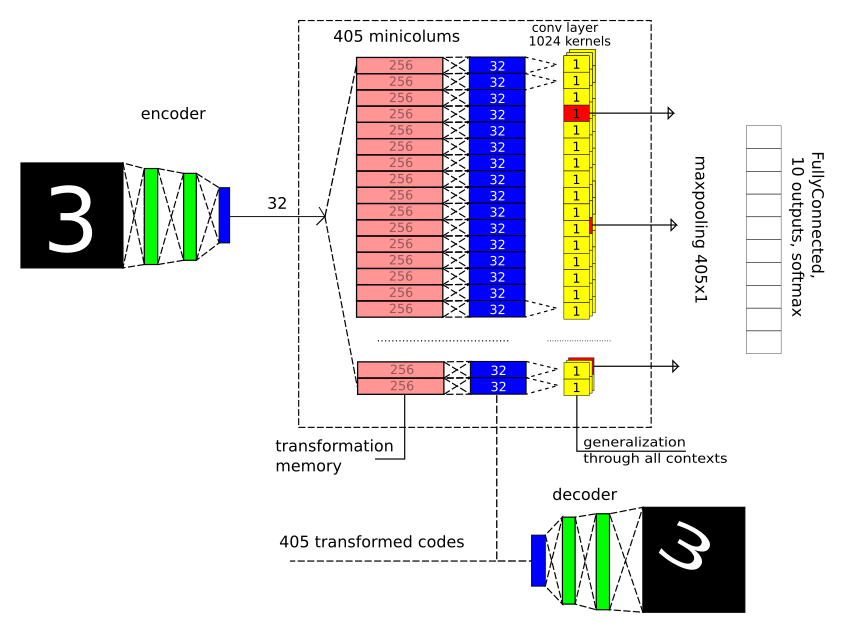
MNISTのモデル
1つのレベルの情報分析(1つのゾーン)のみがモデル化されました。次のステップは複数のゾーンです。
ここでは、画像内の空間畳み込み(Conv2D)と最大プーリング2x2を放棄することが基本的に重要です。これにより、MNISTの精度が著しく向上するため、小さな幾何学的歪みが許容されます。
テキストを読むときに巻き戻す必要がないように、写真を繰り返します。
3つの重要な部分があります。
1)長さが32のベクトルのみがゾーンに分類されます。これは、デコードとエンコードのために2つの完全に接続されたレイヤーを備えた従来の自動エンコーダーによる圧縮の結果です。
2)405の幾何学的コンテキスト変換を定義します:5ターンX 9オフセットX 9スケール。 入力画像の変換後にコード(32コンポーネント)がどのように変化するかを見て、コンテキスト変換ごとに2つの完全に接続されたレイヤー(32-> 256-> 32)をトレーニングします。 隠された1日と1日休み。 実際、もちろん覚えておいてください。
3)出現するコンテキストに関係なく、安定したパターンを探しています。パターンごとに、最適なコンテキスト(最大プール層)を1つ選択します。
次に、ゾーンの出口を完全に接続された小さなネットワークに送信します。これにより、目の前にどんな人物がいるかが決まります。
トレーニング
はい、エラーの逆伝播の原則はここで使用されていました。 彼の「長期にわたる行動」が非常に限られていたことだけです。 すなわち 段階的に勉強しましたが、実際にはそれほど「深い学習」はありませんでした。 すべてが異なるアプローチで動作するはずだという感覚がありますが、アルゴリズムが記述されるまで、実績のあるツールを使用します。
最初に、自動エンコーダーを個別にトレーニングします。

そして、エンコーダー層とデコーダー層の重みを修正します。
実際、これは完全にオプションの手順です。 さらに、データの表示が完全ではないため、精度がわずかに低下します。 しかし、ステージ3では、これにより計算の数が減ります。
次に、405個の変換すべてをトレーニングします。 すなわち これらの変換後の画像コードの変化。 何が起こったかをテストします。 変換されたコードから元の画像を復元します。

それはささいな(そしてそうである)ようです! しかし、非常に重要な点がいくつかあります。
1)モデルの観点から見ると、変換はプログラムされていませんが、トレーニングによって取得されています。 すなわち どのデータを処理し、どのようなコンテキスト変換を行うかについての制限はまったくありません。 さらにクールなのは、同じスペースに変換しないことです。 しかし、それについては後で。
2)これまでに表示されたことのないサインを受け取り、提出することができます。コンテキストによってどのように変化するかがわかります。
入力に逆三角形を付けて、以下を取得します。

もちろん、見た目はそれほど印象的ではありません。 しかし、イデオロギー的にこれは非常にクールです! 過去の経験を通して、あなたは人生で一度も見たことのないオブジェクトがあらゆる可能なコンテキストでどのように見えるかを知っています。 そして、これはワンショット学習の可能性を開きます。 オブジェクトを1つのビューで見た後、まったく異なる方法で見つけることができます。 これにより、必要なトレーニングセットが大幅に削減されます。 そして、コンピュータービジョンについて話すと、幾何学的変換だけでなく、色、明るさなどについても言えます。
そして、すべてのコンテキストに共通の検出器が必要です。 これは、コアサイズが1x1のたたみ込み層と、各コアの勝者を選択する最大プール層を使用して実装されました。 ここでの畳み込み層は、異なるコンテキストに同じ重みを使用する方法にすぎず、通常の機能(通常のサイズのコア405x1での最大プーリングなど)を満たしません。
結果
まず、トレーニングサンプルのサイズを小さくして、状況を確認することが重要でした。 最初の1000個の画像を取得し、それらについてのみトレーニングします。
学習曲線は次のとおりです。

精度96%。
たとえば、このようなアーキテクチャの畳み込みネットワークと比較する必要があります。

CNNトレーニング後の精度は95.3%でした。
注意深い読者は、比較が不公平であることに気付くでしょう。 暗黙的な増強(入力画像の幾何学的歪み)を使用しました。 そのため、畳み込みネットワークに同様の拡張を導入します。 すでに96.2%を取得しています。
悪くない、結果は畳み込みネットワークに匹敵する。
完全なトレーニングの精度は99.1%でした。 これは畳み込みネットワークよりも著しく悪いですが、いくつかのレベルの完全に接続されたネットワークよりも優れています。
たたみ込み層の使用を避けると、おそらく精度が低下します。 しかし、いずれにせよ、アーキテクチャをデバッグして適切な精度を得ることができました。
それはすべて何かに似ていますか?
はい、最初に、もちろん、予想外にヒントンのCapsuleNetのように見えます。 彼はまた、ミニカラムの機能の解釈を提供します。 主な違いは、CapsuleNetにはさまざまなコンテキストで情報を表示するという考え方が含まれていないことです。 しかし、アーキテクチャが類似していることが判明したという事実は、非常に興味深い考えにつながります。 その実装では、ミニカラムのアクティビティは数字の1つを認識することに対応し、私たちの概念では、数字はコンテキストであることがわかります。 そして、この絵は7であるという事実の文脈で何を意味しますか? そして、これがユニットであるという事実の文脈では? そして、この質問は本当に意味がないわけではありません。 コンテキストは幾何学的な変換である場合があり、コンテキストは認識可能なオブジェクトのタイプである場合があります。 これについては後で詳しく説明します。
別の変換のアイデアは、 Spartial Transformation Networksに含まれています。 幾何学的変換のレイヤーと別の小さなグリッドがレイヤーブレークに含まれ、回帰を使用して最適な変換を推定します。 同時に、微分可能性のギャップは許可されず、エラーの逆伝播の方法を使用してこれをすべてトレーニングできます。 2つの違いがあります:離散変換の処理が定式化されていない(たとえば、音声の文法で離散している)ため、最適な変換を評価する回帰の小さなネットワークは不要であるようです。 どのコンテキストでデータが既知のパターンを形成するかに基づいて、最適なコンテキストを選択する必要があり、各変換を分析する以外に最適な方法はありません。
そして、もう行かないという別の考え
視覚領域(および聴覚/音声)には、いわゆる「2ストリーム仮説」があります。 脳の一方の側(腹側の流れ)では、ミニカラムは主にオブジェクトの特性とオブジェクト自体のタイプに応答し、脳の他方の側(背側の流れ)では主に空間特性に応答します。
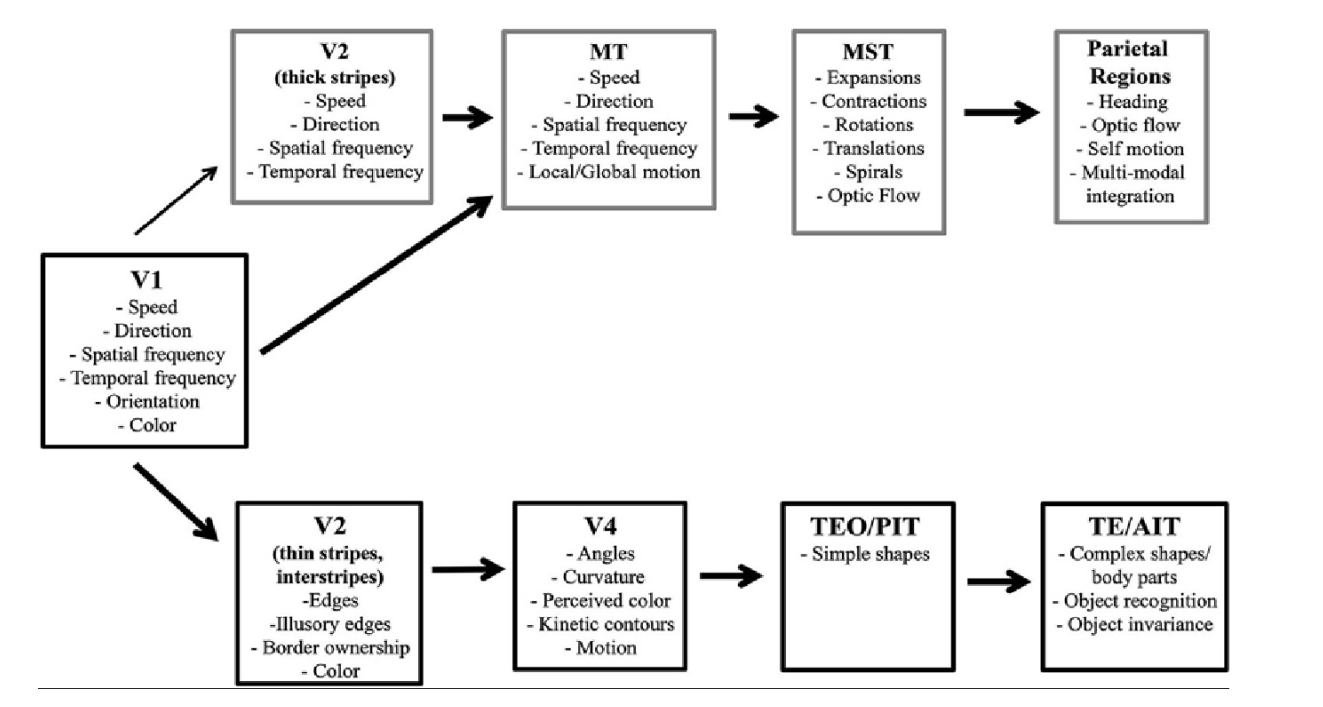
私たちの解釈では、背側の流れは空間的および時間的変換に関するものです。 V2とV3を見てみましょう:速度X方向-与えられた方向で与えられた速度で移動する基準フレームへの遷移、Spartical Frequency-単純にスケールを変換、Temporal Frequency-スケールを時間的に変更します。
しかし、Ventral Streamは完全に直観に反しています。 「単純な形状」の文脈、または曲率の文脈に入るとはどういう意味ですか? ところで、色のコンテキストでは、問題ありません。 またはTE / AITで「オブジェクトのコンテキストで」? この問題は、ミニカラムコードがオブジェクトのプロパティと特性を特徴付けると仮定することで克服できます。 たとえば、画像の境界の曲率は、コントラスト、ぼかし、色などによって特徴付けられます。これらの特性は、曲率の原因となる各ミニカラムに共通です。
CapsuleNetに非常に近いが、ミニコラム内のスタイルまたは特性は、一部の地域に共通する必要があります。 未解決のままの唯一の質問は、このタイプのコンテキスト変換をどのようにトレーニングするかです。
Stream-sの1つで得られた認識結果を別のStream-sで使用できることも注目に値します。 背側の流れの特定の位置、方向、およびスケールのコンテキストで形状を認識することにより、腹側の流れの対応するミニカラムの活性化の可能性を高めることができます。 そしてその逆。
結論
まだ多くの作業が先にあります。
PS:ソースコードで使用したContextNet という名前は、実際には既に使用されていますが、非常によく合います。