2017年上半期、SIEMシステムによって処理され、Solar JSOCがサービスを提供するために使用したISイベントの1日あたりの平均合計フローは61億5,600万に達しました。 インシデントが疑われるイベント- 1日あたり平均約960 。 6回ごとの事件は重大です。 同時に、Tinkoff Bank、STS Media、またはPochta Bankなどのクライアントにとって、攻撃についての情報を迅速に送信し、対抗策に関する推奨事項を受け取るという問題は非常に深刻です。
私たちはこの問題をどのように解決したか、どの問題に遭遇したか、そして最終的にどのような方法で作業を整理するかを伝えることにしました。

チームビルディング
明らかに、インシデント管理を成功させるには、インシデントの排除を調整し、顧客との単一の連絡先として機能するディスパッチサービスのようなものを作成する必要があります。
サービス内の職務と責任を区別するために、サービスをいくつかのレベルに分割し、新しいタスクに応じて時間をかけてスケールしました。 シェルに対する数多くの試みとアプローチの後、次の図が得られました。
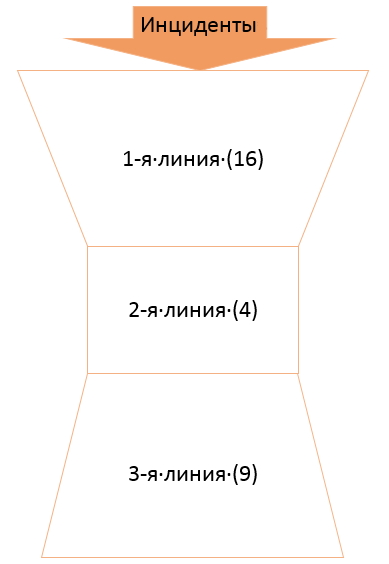
Solar JSOCの最初のラインは、インシデントとその分析へのタイムリーな対応、誤検知のフィルタリング、およびすべてのタイプされたインシデントに関する分析情報の準備を担当するエンジニアを監視することです。 SLA要件を満たす応答はタイムリーと見なされます。 最初の行はシフトで機能し、24時間365日のインシデント対応と分析を提供します。
2行目は、応答エンジニア、特定のIS製品および分野の専門家であり、非典型的なインシデントは専門分野に応じて分類されます。
通常、Service Deskサービスには「逆ピラミッド」の構造があり、ご覧のとおり「砂時計」があります。 事実は、3行目でやや非定型的なストーリーが生じたことです。 3行目は、特定の顧客に割り当てられ、インフラストラクチャと内部プロセスに関する最も完全な情報を所有するアナリストで構成されています。 次の状況でエスカレートします。
- インシデントを識別するための異常なアクティビティの分析。
- 顧客の非典型的な重大インシデントへの対応。
- 監視によって記録されていない情報セキュリティインシデントの調査への参加。
- また、アナリストは、ソース設定の技術的な調査、接続、および適応に従事しています。
夜間、週末、休日に年中無休で監視できるように、オンラインアナリストが割り当てられます。 そのため、顧客数の増加とサービスの拡大に伴い、まず第一にアナリストの必要性が高まっていることがわかりました。
マルウェアのフォレンジックとリバースエンジニアリングの専門家のチームが離れています。 インシデントがウイルス感染または侵入攻撃に関連している場合、それらは接続されています。
効果を維持するには、監視センターのサービスを継続的に開発する必要があります。 たとえば、監視の品質はSIEMシステムの内容に大きく依存するため、インシデントを検出して既存のシナリオを最適化するための新しいシナリオを絶えず開発する必要があります。 さらに、新しいテクノロジについて常に最新情報を入手し、サービスで使用することで得られる利点を評価する必要があります。 たとえば、SIEMツールによる侵害の指標の遡及的分析には時間がかかりすぎるため、このタスクをより迅速に完了するツールを見つける必要があります。 3人で構成され、サービスの開発に専念している別のグループを作成しました。
コンテンツを各顧客に適合させる必要があることを明確にすることが重要です。ルールを調整して誤検知の数を減らし、新しいセグメントの接続プロファイルを収集するなど。 選択されたグループはこのような量の作業に対応できないため、顧客の特性を徹底的に調査し、どこで何が痛いのかを知っているサードラインアナリストを任命しました。
内部構造を処理した後、インシデント調査の一環として、コミュニケーションに加えて、顧客との対話プロセスの構築を開始しました。 言い換えると、サービスレベルと顧客満足度を制御できるSLA管理を構築する必要がありました。 この段階で、別の専門家グループの役割が生じました-契約で事前に規定されたサービス品質のパラメーターの監視に関与するサービスマネージャー。 これらのパラメータは常に測定可能、つまり数値メトリックの形で表現可能である必要があります。
監視サービスの品質を監視するために選択した指標は次のとおりです。
- インシデントが記録された瞬間からのインシデントへの反応時間は、リクエストの受信と登録の瞬間から作業開始の瞬間までに経過した時間です。 このインジケータは、着信アラートのフローの処理にコミットする速さを反映しています。 私たちの場合、これは重大なインシデントの場合20分です。
- インシデントの分析および分析情報の準備の時間は、問題の実際の作業が開始されてからアプリケーションが終了するまでに経過した時間です。 ここではすべてが簡単です-お客様は、状況を分析し、対抗策に関する推奨事項を提供できる速さを理解する必要があります。 SLAは、この時間が通常のインシデントでは60分、重大なインシデントでは40分を超えないことを意味します。
サービスを提供するプロセスでは、インシデントを直接監視することに加えて、より頻繁に発生する2つのアクティビティが特定されました。新しいイベントソースの接続とインシデント検出シナリオの起動/終了です。 これらの操作を制御するために、2つの新しいメトリックを導入しました。
- 新しい標準ソースの接続を完了する時間。 私たちの標準は24時間です。
- スクリプトをファイナライズするリクエストの実行時間。 SLAに従って、この問題を72時間で解決する必要があります。
最後のメトリックは、サービスの可用性に関するものです。 制御を簡素化するために、サービスの提供に関連するすべての技術的手段の可用性の指標のセットを1つ、つまりプラットフォームの可用性に結合しました。
最終的にどのようなチームを編成したかを見てみましょう。





最初の問題
プロセスが規制され、役割がスケジュールされ、相互作用が確立され、戦いの時が来たようです。 しかし、サービスを開始し、最初の顧客をつなぐと、問題の軸に直面し始めました。 インシデントの流れ全体が最初に最初の行に落ちると、それとともに困難が現れ始めました。
いずれの場合でも、最初の行は他の行よりも資格が低く、24時間365日モードで動作します。 このような状況では、常にエラーのリスクがあります。たとえば、軍事事件を偽陽性として閉じることです。 これが顧客に深刻な結果をもたらす場合、誰もが有罪当事者を探すことはなく、評判の損害はチーム全体に降りかかります。
したがって、重要な質問:ケースの解析および分析の品質を制御する方法は? あなたの人生を簡素化したい場合、専門家は彼がよりよく知っているトピックに簡単または近いトピックを選択することができます。 このアプローチでは、誰も取りたがらない「望ましくない」インシデントが表示され、SLAの外にゆっくりと浮かんだり、期限切れになったり、解体されたりすることさえありません。
次のリスクは、商業監視センターにのみ適用されます。 オペレーターは、多数の顧客からのアラートの連続ストリームを処理することを余儀なくされ、大騒ぎで間違ったアドレスに回答を送信できます。 結果は何であるかを説明する必要はないと思います。
しかし、負荷が増加し、インシデントの洪水の下で最初の行が沈み始めたらどうでしょうか?
さて、順番に始めましょう:
最初の行の作業を容易にするために、すべての典型的なインシデントを処理するための詳細な指示とルールを開発しました。 手順は次のとおりです。

- インシデントの基本情報(ターゲット、イベントのソース、名前)。
- トリガーロジック。
- 誤検知の兆候。
- インシデントの考えられる結果。
- 対策などの推奨事項
この指示は、エンジニアがインシデントSLAを遵守し、ケースをさらにエスカレーションするか、それとも単独で処理できるかどうかを迅速に判断するのに非常に役立ちます。
最初の行の操作を制御する問題を解決するために、使用済みのケースを評価するシステムを開発しました。これには、12を超えるカテゴリが含まれます。 たとえば、アラートの情報コンテンツ、正しい分析、インシデントカードの記入など。
各サードラインアナリストの責任には、最初のラインでソートされた数十件のインシデントの毎週のレビューが含まれます。 レビューの結果に基づいて、アナリストは上記のカテゴリの詳細についてコメントできます。 レビューを可能な限り有効にするために、ケースを選択するための明確な基準を開発しました。
- 重大度の高いインシデント。
- 重要なソースに関連するインシデント(たとえば、CBDの銀行ワークステーションおよび同様の非常に重要なワークステーション)。
- プロファイリングインシデント(最初の2つのカテゴリに割り当てられていない場合)。
- 脅威情報フィード。
- 新しいインシデントシナリオ(最初の行の起動日から1か月未満)。
短いレビューは次のようになります。
評価の結果は、最初の行の動機付けスキームでプラスとマイナスの両方で考慮されます。 もちろん、このような問題の解決策は非常に高価です。 ただし、私たちにとってこれが最良のオプションです。 インシデントを逃した場合の結果は、はるかにコストがかかります。 また、不適切に処理されたインシデントの公開報告が行われ、間違いが繰り返されなくなります。
インシデントを簡単に選択する誘惑を回避するために、分析のためにケースを選択する機会を第一線のエンジニアから奪いました。 スコアリングシステムがそれを決定し、各インシデントを緑、黄、赤の3つのゾーンのいずれかに分配します。 分布では、5つの指標が考慮されます。
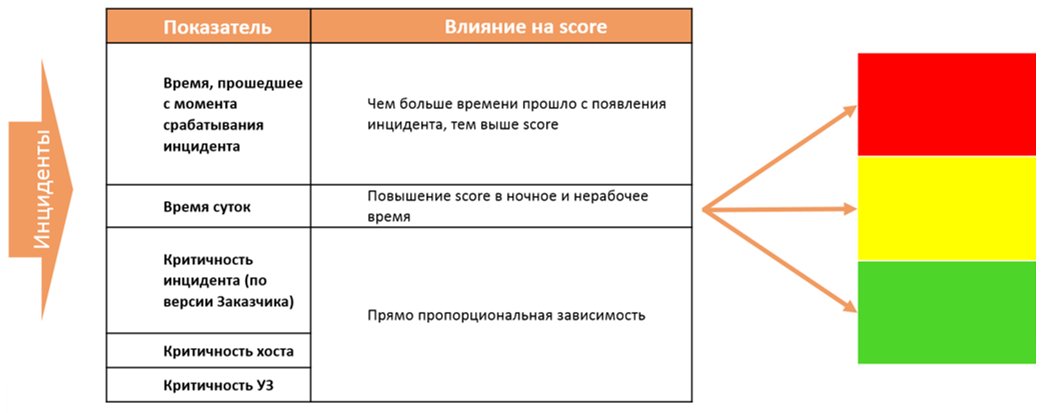
その結果、無料のエンジニアが自動的に最高スコアのインシデントを受け取ります。
オペレーターが電子メールを直接操作しないため、間違ったアドレスに応答を送信するリスクを最小限に抑えました。 監視サービスの作業を自動化するために、Kayako HelpDeskシステムを選択し、仕様に合わせてメールに統合し、監視サービスを送信しました。 応答を送信すると、事前設定された通知プロファイルがトリガーされ、関連する顧客スペシャリストへのルートが登録されます。 インシデントを分析できるようにするために、SIEMシステムコンソールのチケットにインシデントへのリンクが添付されています。

現在のシフト負荷、計画決定時間、および着信アラートフラックス密度から開始して、負荷を予測します。 ここでも、ゾーンごとの分布を使用します。多くの「赤」インシデントが蓄積した場合は、利用可能なすべての部隊で火を消します。 必要に応じて、2行目の専門家がケースの最初の分析または重大な状況(オンラインアナリスト)に接続します。
結果は何ですか
もちろん、これらはすべて私たちが途中で遭遇した問題ではなく、最後まですべてを解決することができませんでした。 たとえば、ここにいくつかの「中断された」質問があります。顧客がフィードバックを提供しなかった場合、インシデントをどうするか? 応答を受け取る前に1日で閉じるか、そのままにしておく必要がありますか? 顧客がインシデントの除去について報告し、1日後に再び発生した場合はどうすればよいですか? または、顧客からのフィードバックがなく、インシデントは毎日発生しますか?
しかし、それでも、その道は進み、結果から、プロセスの組織化において十分に高いレベルの成熟度に達したと言うことができます。
その結果、説明したすべての役割とタスクを、責任配分のRACIマトリックスに重ね合わせます。 すぐに、この表がSOCのタスクと責任のごく一部のみを記述していることを予約してください(正直なところ、記事全体で公開するには大きすぎて怖いです)。

SOCを構築することは、技術的な側面に触れることなく、多くの異なるレーキを収集するための長い道のりです。 それらのいくつかを指摘し、回避策を提案できたと思います。 残念ながら、私はあなたがあなたに特有の問題に遭遇しないことを保証することはできません。 しかし、繰り返し述べたように、道は歩く道によって圧倒されます。 さて、額を準備してください:)。