あなたはペットプロジェクトまたはサイドプロジェクトと呼ばれるものを持っていますか? あなたの喜びとあなた自身のために、自己開発またはあなたのポートフォリオを拡大するためにあなたがするのと同じプロジェクト。 個人的には、長い間見せることがありませんでした。 しかし、この秋に始まったAtos IT Challenge 2018コンテストの枠組みでは、このようなプロジェクトを開始する機会がありました。
コンテストについて
説明してみましょう。7年連続で、アトスはITの世界でいくつかのホットなトピックを選択しており、世界中の学生チームにこのトピックに特化したアイデアを思いついて実行するよう招待しています。 競争は非常に重要です。メインラウンドを完了した学生は、経験豊富なメンターの指導の下で6か月間働き、結果については6月にのみ学習します。 このような量の仕事を背景にした賞金は目を見張るものではありません。10,000、5,000、3,000ユーロが賞金のステップにありますが、実際、主にお金ではありません。
私は、自分自身のために新しい領域にポンプを入れ、同時にそれを実際のプロジェクトに適用する機会を考えています。 そしてもちろん、彼の同志たちの会社でそれをすべて実践しています。
今年のテーマについて
「生活とビジネスのためのチャットボット」は、あなたのアイデアを思い付くために必要なコアです。 「チャット」とは、コミュニケーション、音声、テキストを意味します。 したがって、NLPの知識がなくても-「自然言語処理」または「自然言語処理」-どこにもありません。
ご存知のように、学生は試験の前夜に何よりも情報を最もよく認識します。私たちは同じ論理に基づいて参加することを決め、途中でNLPの知識を向上させます。 テキストの単純な分類のようなものは長い間私たちの対象でしたが、競争の枠組みの中で、Q&Aシステムを理解し、アルゴリズムも抽象化する必要があります-一般的に、すべてがより興味深いものになります。
アプリケーションについて
12月1日まで、参加者はアイデアの説明とともに申請書を提出しましたが、申請書の作成は容易ではなかったと言わざるを得ません。 彼らは、将来のアプリケーション、技術的実現可能性、アーキテクチャ、およびユーザーとパートナーにとっての究極のメリットのビジネスモデルを求めました。
私たちは古典的なハイテクの学生であり、競争の前にビジネスモデルに精通していませんでした。 しかし、OsterwalderとPinierの優れた本、Building Business Modelsのおかげで、彼らは真実に似た何かを描くことができました。
もちろん、審査員だけが申請書を見ることができますが、参加者はライバルのアイデアの名前と説明(要約)を見ることができます。
私達について
私たちは、ヴォロネジ州立大学の4人の学生です。 4人は、芸術と音楽を愛する創造的な人々です。 おそらくそれが、チャットボットのビジネスアプリケーションからではなく、金銭的な利益とはほど遠いトピックである塗装から始めた理由です。
あなたが写真についてロボットと話すのは面白いでしょう、あなたは何を見ますか? 詳細を話し合い、経験を共有しますか?
私たちにとって、答えは明白です。もちろん、面白いでしょう! すばらしいですが、電話を見たくない場合にシステムと通信する最良の方法は何ですか? もちろん、声で。
それで、主なアイデアが形成されました。それは、あなたがアートとあなたが見るものについて話すボットです。
存在しないインターフェースの完全性。 自分の考えを言うだけで答えが得られます。 スクリプト、フレームワーク、コマンドはありません。 一言で言えば、「Zen」-そして、このようなシステムとアプリケーションの価値と未来を見ることができます。
その他について
12月1日より前に申請書が提出され、1週間後の12月7日に、他のチームからのアイデアのリストが公開されました。 それらの多くがありました:204。
ここに私たちが気に入ったものがあります:
- 容疑者の容姿を説明するための身元確認書の作成 。 ここでは、対話の部分が明確であるように見え、アプリケーションは明らかです。
- 仮想教師 。 チームは、材料を示し、質問に答えるホログラムを作成すると主張しています。
そしてここに...奇妙な:
- 症状を診断し 、夫に1時間電話をかけます。つまり、チャットボットにパッケージ化された多くのサービスは、その理由が完全には明らかではありません。
- チャットボットはチャットボットのようなものです。話すことです。 そしてそれだけです。 ( ここまたはここ )
- そして最後に、私たちのお気に入りは、特定の場所に到達すると目覚まし時計のように機能するアプリケーションです。 ボットはここにありますか? 見つかりませんでした。 しかし、「iOS、Android、Windows Phone、およびBlackBerryで動作します」。
もちろん、各アイデアの説明、怠を読んでください。 そして、プログラマーが怠けすぎて何かをすることができない場合、彼はこのためのプログラムを書きますよね?
一次データ分析
データ検索
最初は、すべてが簡単です。ライブラリをインポートし、サイトからデータをダウンロードします。
import requests as rq import bs4 as bs from toolz.functoolz import excepts root = 'https://www.atositchallenge.net/students-ideas/' soup = bs.BeautifulSoup(rq.get(root).text, 'html5lib') data = soup.select('div.ideas-wrapper a') len(data) # -> 204 mk_safe = lambda f: excepts(Exception, f, lambda _: np.NaN) def extract_short_info(r): get_href = mk_safe(lambda x: x['href']) get_title = mk_safe(lambda x: x.select_one('div.caption-container h3').text) get_uni = mk_safe(lambda x: x.select_one('div.caption-container p.university').text) get_flag = mk_safe(lambda x: x.select_one('img.flag')['alt']) return { 'url': get_href(r), 'title': get_title(r), 'university': get_uni(r), 'country': get_flag(r) } df = pd.DataFrame([extract_short_info(x) for x in data]) df.country = df.country.str.split(' ').apply(lambda x: x[-1]) df.country = df.country.map({'Turkey': '', 'China': '', 'Singapore': '', 'India': '', 'Kong': '', 'France': '', 'States': '', 'Taiwan': '', 'Kingdom': '', 'Senegal': '', 'Philippines': '', 'Malaysia': '', 'Canada': '', 'Brazil': '', 'Russia': '', 'Romania': '', 'Belgium': '', 'Japan': '', 'Germany': '', 'Cameroon': '', 'Poland': '','Netherlands': '', 'Spain': '','Egypt': '', 'Mexico': '','Morocco': '','Austria': ''})
中間結果:
df.head()
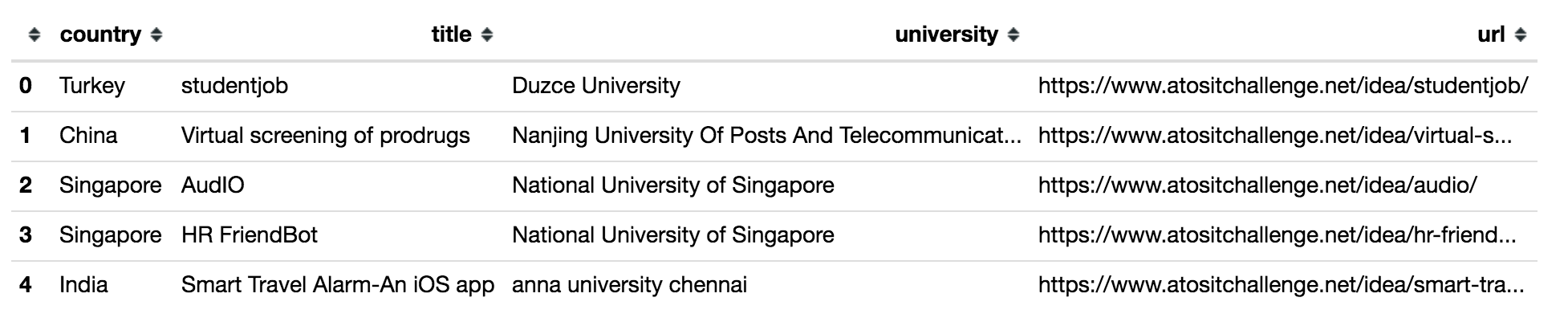
url列には、各アイデアのページが含まれています。 ただし、それらに関する新しい情報はあまりありません。チームの構成と説明のテキストです。 それらをダウンロードして、元のデータフレームに添付します。
def download_description(title, url): try: soup = bs.BeautifulSoup(rq.get(url).text, 'html5lib') get_summary = mk_safe(lambda x: x.select_one('p.summary').text) get_members = mk_safe(lambda x: x.select('p.members')[0].text) summary = get_summary(soup) members = get_members(soup) except: return None return { 'title': title, 'summary': summary, 'members': members } results = list(df.apply(lambda row: download_description(row['title'], row['url']), axis=1)) df_summaries = pd.DataFrame(list(results)) df = df.merge(df_summaries)
そして最終結果はスタジオにあります!
df.head()

可視化
さて、私たちが何を扱っているのか見てみましょう。 国とは何ですか?
counts = df.country.value_counts() counts.plot.bar();
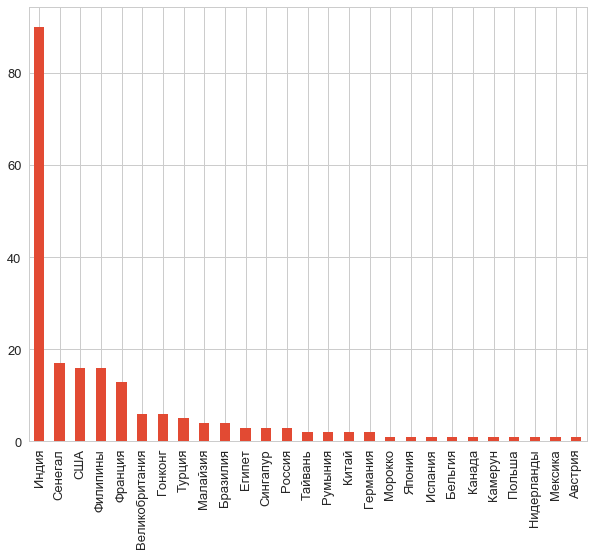
うん! インドからの学生はもう例ではありません。
india_part = pd.Series(data=[counts[0], counts[1:].sum()], index=['', ' ']) f, ax = plt.subplots(1, 1, figsize=(10, 10)) india_part.plot.pie(ax=ax); ax.set_ylabel('');
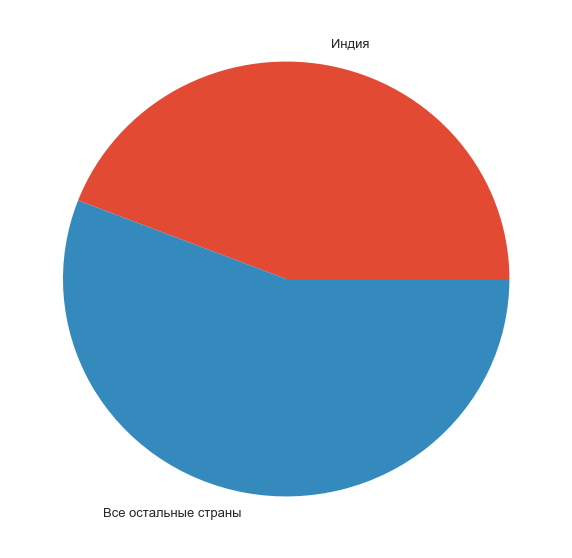
実際、すべての参加者のほぼ半数は、聖なる牛と経済的な宇宙プログラムの国の人です。
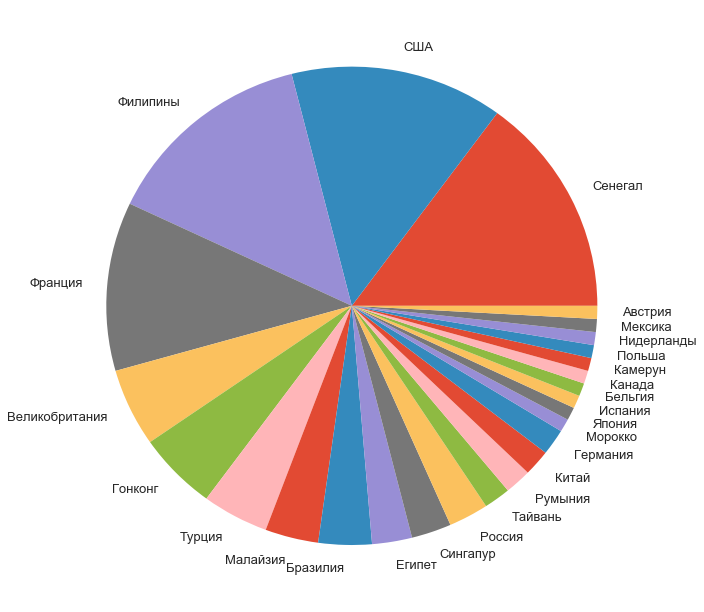
国別の他の参加者のシェアは次のように配布されました。
f, ax = plt.subplots(1, 1, figsize=(11, 11)) counts[1:].plot.pie(ax=ax); ax.set_ylabel('');
大学はどうですか?
university_counts = df.groupby('country')[['university']]\ .agg('nunique')\ .sort_values(by='university', ascending=False) university_counts\ .plot.bar(colors=['#ffea2d' if k != '' else '#ff2d2d' \ for k in university_counts.index]); plt.gca().legend_.remove() plt.ylabel(' '); plt.xlabel(''); y_ticks = list(plt.yticks()[0]) y_ticks.remove(0) plt.yticks(y_ticks + [1]);
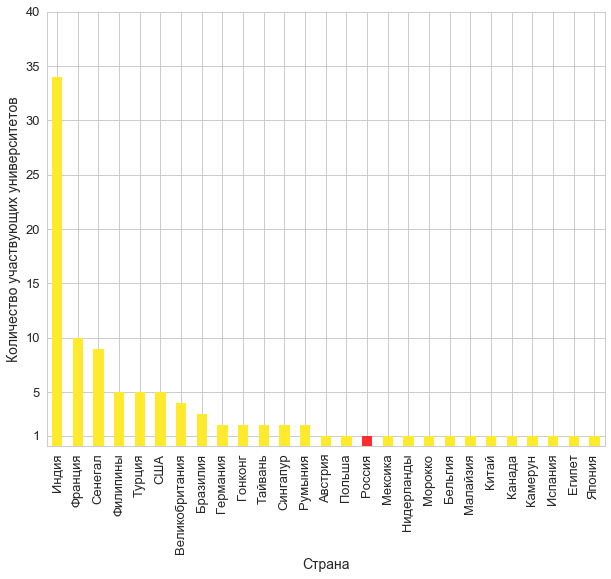
はい 行くぞ がっかり。 同じ大学のロシアからの3つの参加チームすべて-私たちのもの。 君たちはどこにいるの?
df['number_of_members'] = df.members.str.split('|').apply(lambda x: len(x)) avg_members = df.groupby('country').agg('mean').sort_values(by='number_of_members', ascending=False) avg_members.plot.bar(colors=['r' if x=='' else ('#2dbcff' if x != '' else '#ffea2d') for x in avg_members.index]); plt.gca().legend_.remove() plt.xlabel(''); plt.ylabel(' ');

私たちは友好の強さでインドを一周することができました。グラフは、チームが平均してより完全であることを示しています。
さて、最も肉付きの良いもの-テキストに取り掛かりましょうか?
テキスト分析
チーム名
ボットを呼び出すと、彼はそれについて話します。 今年のボットのテーマの傾向は、プロジェクトの名前からもわかるでしょうか? 見てみましょう:
import re from nltk import word_tokenize from nltk.corpus import stopwords from nltk import FreqDist titles = ' '.join(df.title.values) tokens = [x.lower() for x in word_tokenize(titles) if re.match("[a-zA-Z\d]+", x) is not None] tokens = [x for x in tokens if x not in stopwords.words('english')]
明らかに関連のない単語は削除しますが、確かにポップアップします(「チャット」、「チャットボット」、「インテリジェント」、「システム」など)。そして、頻度辞書を作成します。
fd = FreqDist(tokens) [fd.pop(x) for x in ['chatbot', 'bot', 'service', 'ai', 'virtual', 'companion', 'system', 'app', 'intelligent', 'chatbots', 'robot', 'assistant', 'smart', 'solutions']]; len(fd) # 328 plt.figure(figsize=(18, 3)); fd.plot(40, cumulative=False)

真実はすでに明らかです。今年、ボットは健康に役立つように設計されています。 彼らは旅行やショッピングのボットに追いついています。 アプリケーションは明らかですか? こんにちは? プロジェクトの適切な実装が表示されます。
アイデアの説明
次に、アイデアの説明のテキストの処理に進みます。
from nltk import SnowballStemmer summaries = '. '.join(df.summary) sbs = SnowballStemmer('english') tokens = [x.lower() for x in word_tokenize(summaries) if re.match("[a-zA-Z\d]+", x) is not None] tokens = [x for x in tokens if x not in stopwords.words('english')] # 18546 tokens = [sbs.stem(x) for x in tokens] len(tokens) # 18623 fd = FreqDist(tokens) len(fd) # -> 3301, 4877 plt.figure(figsize=(18, 3)); fd.plot(40, cumulative=False)
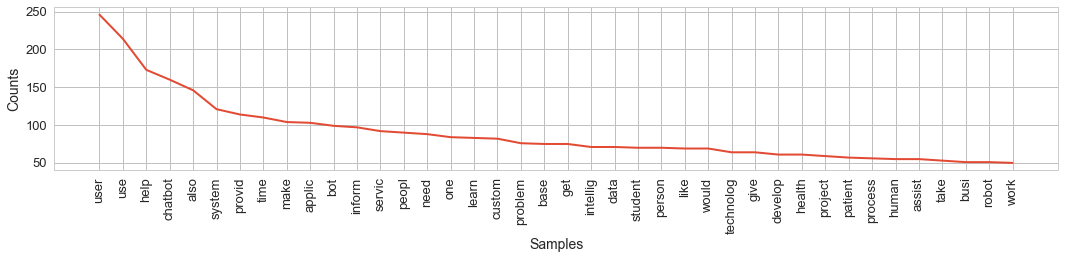
おもしろいですが、一般的に正しいステートメントは、「ユーザーが使用する」、「チャットボットが役立つ」、「システムが提供する」という結果の単語からペアで形成されます。 最も一般的な単語に注意を払うと、説明付きの平均的なテキストがどのように見えるか簡単に想像できます。それは、ボットを使用して問題が解決され、プロジェクトが技術的に進歩し、人々に役立つという事実に関するものです。 大丈夫! しかし、私は裁判官がこれらの200の利他的なistic歌を読み終える忍耐を持っていることを願っています..
ショートリテール
..、忍耐力が十分でない場合、有名なゲンシムの助けを借りて、このすべての質量の要約を求めることができます:
from gensim.summarization import summarize, keywords print(summarize(summaries, word_count=150))
オンデマンドフィード、通知、カスタマイズ(場所、食事の好み、年齢など)に応じたデータを提供する仮想旅行アシスタントは、必要なデータを取得し、人のソーシャルメディアから興味を引き、チャットを提供します。チャットボットは、フライトの詳細、タクシー施設から場所(正確なタイミング、写真、ガイド、天気など、旅行をより賢明にし、ポイントを固定して旅行を追跡することで多くのお金を節約します)、市場(市場を歩き、価格を買う価値がある)、またはナイトライフかもしれません。
そしてキーワード:
ks = keywords(summaries, words=30, lemmatize=True) for i, x in enumerate(ks.split('\n')): ending = '\t' if (i+1) % 4 != 0 else '\n' print(x.ljust(14), end=ending)
users likely inform helped basing provider chatbotics servicing humanity persons people data timings uses learns news medications health differences applicability technological customization problems businesses bots foods student experiences needed
そしてOstapは苦しみました
そして、生成モデルに新しいアイデアの新しい記述を作らせることができると思いました! 行こう!
import markovify markov = markovify.Text(summaries) for i in range(10): print(markov.make_sentence())
Ai-Cityの使用に適応するように設計された音声制御されたバリアフリーのマシンがあり、特定の時間にレビューの束の形でAIを組み込むことで、数年後にユーザーに連絡する農家に提示されますここでは、機械学習アルゴリズムを使用することにより、利用可能なクライアントを利用できます。このアルゴリズムは、記録された視覚素材の継続的な分析に支えられ、そこで処理する作物の優先順位付けに役立ちます。
まあarchiBOTはあなたの忠実なヘルパーであり、素朴な開業医にあなたの薬を服用させ、ユーザーのクエリを拾わせることができます。
ただし、場所、価格帯、座席数などの好みによります。 子供のオンラインアクティビティに表示され、Cric Queryが病院、医療機関、ドラッグストアアクセスのサービスに適用されると警告が表示されます。
それはあなたについてのすべてを知っていますが、プランナータイプのサードパーティにアクセスして使用するための重要なスキル要件があります。
テキストベースの日常会話バディモデルは、現在の一般的な人格テストと比較して、レストランの料金が無料になります。
病気の部分に基づいています。
話す用語集は、フィールドや農場で利用可能ですが。
非常に安価なサブスクリプションを待つ必要はもうありません。
AgriBudは、個人の予約サービスに利益をもたらす可能性があり、正しい道を見つけて、彼が何のためにもパニックに陥らないようにしました。
私たちは、大学で分類できる自動化された需要応答アプリケーションを信じています。
特にクールな瞬間が印象的です:
それはあなたについてのすべてを知っていることに注意してください
結果が非常に興味をそそられると、元のアイデアを見つけて、その本質を確認できます。
私たちのアイデアは、あなたのことをすべて知っている友人ボットのような個人的なチャットボットを作成することですこのボットに。 どんな問題でも役立ちます。 ユーザーの現在の気分を追跡し、いくつかの簡単な質問をします。 これらの質問は、会話療法の最良の形態と見なされる認知行動療法に基づいています。 ボットは実際のセラピストに取って代わることはできませんが、ユーザーの気分をより深く掘り下げ、ボットを元気づけるために何かをすることをお勧めします。 ユーザーがボットと話す回数が増えるほど、彼が得ようとしている助けが増えます。 それはあなたについてのすべてを知っていることに注意してください、しかし、それは誰にもそれを伝えるつもりはないので、心配することは何もありません。:)
単語の雲
誰もが単語の雲を愛しているので(そして、あなたはそれらの1人ではないと言ってはいけません!)、私はあなたを助けることができませんでした。
from wordcloud import WordCloud from PIL import Image mask_image = Image.open("mask.png") mask = np.array(mask_image) wordcloud = WordCloud(background_color="white", colormap='plasma', width=mask_image.width, height=mask_image.height, max_words=2000, mask=mask, stopwords=stopwords.words('english')) wordcloud.generate(summaries); wordcloud.to_file("cloud.png"); plt.imshow(wordcloud, interpolation='bilinear') plt.axis("off") plt.show()

おわりに
私たちの前にはまだ多くの仕事があり、その結果に失望しないことを願っています。 審査員には、それほど難しい仕事はありません。宣言されたトピックには、ヘルスケア、採用、ショッピング、教育、旅行、さらには取引やビットコインが含まれます!
それまでの間、我々は低いスタート位置にいます。 そこで進行中の開発についてのメモを書くために、 twitterアカウントを用意しました。 ちなみに、興味があるなら、彼らはプロモーション用のミニビデオを撮影しさえしました。
ご批判、ご意見をお聞かせください。