私の名前はVitaliy Kotovで、正規表現について少し知っています。 カットの下で、それらを使用する基本を説明します。 多くの理論的な記事がこの主題について書かれています。 この記事では、例の数に注目することにしました。 私は、これがこのツールの機能を示す最良の方法であるように思えます。
それらのいくつかは、PHPまたはJavaScriptのプログラミング言語の例によって説明目的で示されますが、一般的には、関心のある言語に関係なく機能します。
タイトルから、この記事が最も基本的なレベルを対象としていることは明らかです。つまり、プログラムで正規表現を使用したことがないか、適切に理解せずに使用した人です。
記事の最後で、正規表現では解決できないタスクと、これに使用するツールについて簡単に説明します。
行こう!

エントリー
正規表現 -テキスト内の部分文字列または部分文字列を検索する言語。 検索には、文字とメタキャラクター(それ自体ではなく、文字のセットを示す文字)で構成されるパターン(テンプレート、マスク)が使用されます。
これは、検索、文字列検証など、多くの場合に役立つかなり強力なツールです。 その機能の範囲を1つの記事に収めることは困難です。
PHPでは、正規表現の操作は一連の関数であり、その中で最もよく使用されるのは次の関数です。
- preg_match( http://php.net/manual/en/function.preg-match.php )
- preg_match_all( http://php.net/manual/en/function.preg-match-all.php )
- preg_replace( http://php.net/manual/en/function.preg-replace.php )
それらを使用するには、部分文字列を検索または置換するテキストと、検索ルールを説明する正規表現自体が必要です。
一致関数は、見つかった部分文字列の数を返します。エラーの場合はfalseを返します。 replace関数は、変更された文字列/配列、またはエラーの場合はnullを返します。 結果はブール値に還元され(値が見つからなかった場合はfalse、値が見つかった場合はtrue)、ifまたはassertTrueと組み合わせて結果を処理できます。
JSでは、ほとんどの場合、以下を使用する必要があります。
- 一致( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match )
- テスト( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/RegExp/test )
- 置換( https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/replace )
https://regex101.com/ですべての例を参照することをお勧めします 。 これは、正規表現を操作するための便利で直感的なインターフェイスです。
機能例
PHPでは、正規表現は区切り文字で始まり、区切り文字で終わる文字列です。 区切り記号の間にあるものはすべて正規表現です。
一般的に使用される区切り文字は、スラッシュ「/」、ポンド記号「#」、およびチルダ「〜」です。 以下は、有効な区切り文字を使用したパターンの例です。
- / foo bar /
- #^ [^ 0-9] $#
- %[a-zA-Z0-9 _-]%
テンプレート内でセパレータを使用する必要がある場合は、バックスラッシュでエスケープする必要があります。 読みやすくするために、テンプレートで区切り文字がよく使用される場合は、このテンプレートに別の区切り文字を選択することをお勧めします。
- / http:\ / \ //
- #http://#
JavaScriptでは、正規表現は別個のRegExpオブジェクトとして実装され、文字列メソッドに統合されます。
次のような正規表現を作成できます。
let regexp = new RegExp("", "");
または、より短いオプション:
let regexp = //; //
let regexp = //gmi; // gmi ( )
検索する最も単純な正規表現の例:
RegExp: /o/ Text: hello world
この例では、すべての文字「o」を探しています。
PHPでは、preg_matchとpreg_match_allの違いは、最初の関数が最初の一致を検出して検索を終了するのに対して、2番目の関数はすべての出現を返すことです。
PHPコード例:
<?php $text = 'hello world'; $regexp = '/o/'; $result = preg_match($regexp, $text, $match); var_dump( $result, $match );
int(1) // , .. array(1) { [0]=> string(1) "o" // , , }
2番目の関数についても同じことを試みます。
<?php $text = 'hello world'; $regexp = '/o/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match );
int(2) array(1) { [0]=> array(2) { [0]=> string(1) "o" [1]=> string(1) "o" } }
後者の場合、関数はテキスト内のすべての出現を返しました。
同じJavaScriptの例:
let str = 'Hello world'; let result = str.match(/o/); console.log(result);
["o", index: 4, input: "Hello world"]
テンプレート修飾子
正規表現には、検索の動作を変更する一連の修飾子があります。 これらは、ラテンアルファベットの1文字で示され、正規表現の末尾の「/」の後に配置されます。
- i-パターン内の文字は、大文字と小文字の両方の文字に対応します。
- m-デフォルトでは、テキストは単一行の文字列として扱われます。 文字列「^」の先頭のメタキャラクターは処理中のテキストの先頭にのみ対応し、文字列「$」の末尾のメタキャラクターはテキストの末尾に対応します。 この修飾子が使用される場合、「行頭」および「行末」のメタ文字は、翻訳および行の任意の文字の前、したがって行の後、行頭、行末の位置にも対応します。
PHP で使用されるその他の修飾子については、 こちらをご覧ください 。
JavaScriptでは、 こちら 。
ここで一般的な修飾子について読むことができます 。
JavaScript修飾子を使用した以前の正規表現の例:
let str = "hello world \ How is it going?" let result = str.match(/o/g); console.log(result);
["o", "o", "o", "o"]
通常のメタキャラクター
非常に基本的なことを知ることができるため、最初の例はかなり原始的です。 学習すればするほど、例は現実に近づきます。
ほとんどの場合、どのテキストを解析する必要があるか事前にわかりません。 事前にわかっているのはおおよそのルールセットのみです。 SMSのPINコード、レターでのメールなど。
最初の例では、テキストからすべての数値を取得する必要があります。
: “, 1528. .”
任意の番号を選択するには、「[0123456789]」を指定してすべての番号を収集する必要があります。 Shorterは「[0-9]」のように設定できます。 すべての数字にメタ文字「\ d」があります。 同じように機能します。
しかし、正規表現「/ \ d /」を指定すると、最初の数字のみが返されます。 もちろん、「g」修飾子を使用することもできますが、この場合、各桁は新しいオカレンスと見なされるため、配列の個別の要素として返されます。
部分文字列を単一の出現として表示するために、プラス記号「+」とアスタリスク「*」があります。 最初のものは、部分文字列が私たちに適していることを示しており、少なくとも1つの文字がセットに適しています。 2番目は、この文字セットがそうである場合もそうでない場合もあり、これは正常です。 さらに、次のように適切な文字の正確な値を示すことができます。「{N}」。Nは適切な量です。 または、「{N、M}」のように指定して、「from」と「to」を尋ねます。
これを念頭に置いたいくつかの例があります。
: “ 2 .” . RegExp: “/\d/”
: “ : 24356” “ .” , . RegExp: “/\d*/”
: “ 89091534357” 11 , FALSE, . RegExp: “/\d{11}/”
ほぼ同じ方法で、私たちは手紙を扱います。手紙があることを忘れないでください。 これは、文字を設定する方法です。
- [az]
- [a-zA-Z]
- [aaaaaa]
キリル文字を使用すると、指定された範囲は異なるエンコーディングに対して異なる動作をします。 たとえば、Unicodeでは、文字「」はこの範囲に含まれません。 詳細についてはこちらをご覧ください 。
いくつかの例:
: “ ” “ ” “”, “”. RegExp: “/[--]+/”
このような式は、文に含まれているすべての単語を選択し、キリル文字で記述されます。 3番目の単語が必要です。
文字と数字に加えて、次のような重要な記号も使用できます。
- \ s-スペース
- ^-行の始まり
- $-行末
- | -「または」
前の例はよりシンプルになりました。
: “ ” “ ” “”, “”. RegExp: “/[--]+$/”
検索ワードが最後であることが確実にわかっている場合、「$」を入力すると、作業の結果は文字セットのみになり、その後に行の終わりが来ます。
行の先頭と同じこと:
: “ ” “ ” “”, “”. RegExp: “/^[--]+/”
メタキャラクターをさらに理解する前に、「^」記号を個別に説明する必要があります。これは、2つの作品に一度に行くためです(これにより、より興味深いものになります)。 場合によっては、行の始まりを示しますが、否定の場合もあります。
これは、自分に合った文字よりも自分に合っていない文字を指定する方が簡単な場合に必要です。
私たちに合った文字セットをコンパイルしたとします:“ [a-z0-9]”(小さなラテン文字または数字が私たちに合っています)。 ここで、これ以外の文字に満足しているとします。 「[^ a-z0-9]」のように表示されます。
例:
: “ ” . RegExp: “[^\s]+”
すべての「スペースなし」を選択します。
したがって、ここに主要なメタキャラクターのリストがあります。
- \ d-任意の数字と一致します。 同等の[0-9]
- \ D-数字以外の文字に一致します。 同等の[^ 0-9]
- \ s-空白文字に一致します。 同等の[\ t \ n \ r \ f \ v]
- \ S-任意の非空白文字と一致します。 同等の[^ \ t \ n \ r \ f \ v]
- \ w-任意の文字または数字と一致します。 同等の[a-zA-Z0-9_]
- \ W-その逆; 同等の[^ a-zA-Z0-9_]
- 。 -(単なるドット)「キャリッジ」の翻訳以外の文字
演算子[]および()
上記で説明したように、[]を使用して複数の文字をグループ化すると推測できます。 したがって、セットのどのキャラクターも私たちに合うと言います。
例:
: “ I dont know, !” . RegExp: “/[A-Za-z\s]{2,}/”
ここでは、すべてのラテン文字とスペースをグループ(文字[]の間)にまとめます。 {}を使用して、空のスペースからエントリを除外する少なくとも 2文字のエントリに関心があることを示しました。
同様に、「[^ A-Za-z \ s] {2、}」を反転させると、すべてのロシア語の単語を取得できます。
[]とは異なり、文字()はマークされた式を収集します。 それらは「キャプチャ」と呼ばれることもあります。
これらは、選択したピース(おそらく、出力内の複数のオカレンス[]で構成される)を渡すために必要です。
例:
: 'Email you sent was ololo@example.com Is it correct?' email.
多くの解決策があります。 以下の例は、正規表現の威力を示すおおよそのオプションです。 実際、電子メールの正確さを決定するRFCがあります。 そして、RFC「規則」があります- ここにいくつかの例があります。
スペース以外のすべてを選択します(電子メールの最初の部分に任意の文字セットを含めることができるため)、その後に@記号が続き、その後にピリオドとスペース、ピリオド、小文字のラテン文字を除く...
それでは、行きましょう:
- スペースなしですべてを選択します:「[^ \ s] +」
- @記号を選択します:「@」
- ピリオドとスペース以外を選択します:「[^ \ s \。] +」
- ポイントを選択します:“ \。”(メタ文字をエスケープするにはバックスラッシュが必要です。ドット文字は任意の文字を記述するためです-上記参照)
- 小文字のラテン文字を選択します:“ [az] +”
それはそれほど難しくないことが判明しました。 これで、メールが部分的に収集されました。 PHPでのpreg_matchの結果の例を考えてみましょう。
<?php $text = 'Email you sent was ololo@example.com. Is it correct?'; $regexp = '/[^\s]+@[^\s\.]+\.[az]+/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match );
int(1) array(1) { [0]=> array(1) { [0]=> string(13) "ololo@example.com" } }
わかった! しかし、ドメインと名前を個別にメールで受信する必要がある場合はどうでしょうか? そして、なんとかコードでさらに使用しますか? これが「キャプチャ」が私たちを助ける場所です。 例のように、必要なものを選択し、記号()で囲みます。
それは:
/[^\s]+@[^\s\.]+\.[az]+/
次のようになりました:
/([^\s]+)@([^\s\.]+\.[az]+)/
私達は試みます:
<?php $text = 'Email you sent was ololo@example.com. Is it correct?'; $regexp = '/([^\s]+)@([^\s\.]+\.[az]+)/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match );
int(1) array(3) { [0]=> array(1) { [0]=> string(13) "ololo@example.com" } [1]=> array(1) { [0]=> string(5) "ololo" } [2]=> array(1) { [0]=> string(7) "example.com" } }
一致配列では、ゼロエントリは常に正規表現の完全な出現です。 次に、「キャプチャ」に進みます。
PHPでは、次の構文を使用して「キャプチャ」という名前を付けることができます。
/(?<mail>[^\s]+)@(?<domain>[^\s\.]+\.[az]+)/
それから、マッチ配列は連想的になります:
<?php $text = 'Email you sent was ololo@example.com. Is it correct?'; $regexp = '/(?<mail>[^\s]+)@(?<domain>[^\s\.]+\.[az]+)/'; $result = preg_match_all($regexp, $text, $match); var_dump( $result, $match );
int(1) array(5) { [0]=> array(1) { [0]=> string(13) "ololo@example.com" } ["mail"]=> array(1) { [0]=> string(5) "ololo" } ["domain"]=> array(1) { [0]=> string(7) "example.com" } }
これにより、コードと規則性の両方が読みやすくなり、すぐに+100になります。
実生活の例
新しいパスワードを検索するParsimの手紙:
HTMLコードが記載された手紙があります。新しいパスワードを引き出す必要があります。 テキストは英語でもロシア語でもかまいません。
: “: <b>f23f43tgt4</b>” “password: <b>wh4k38f4</b>” RegExp: “(password|):\s<b>([^<]+)<\/b>”
最初に、パスワードの前のテキストには、「または」を使用した2つのオプションがあります。
任意の数のオプションをリストできます。
(password|)
次に、コロンと1つのスペースがあります。
:\s
次はタグ記号bです。
<b>
そして、bタグが閉じていることを示すため、「<」記号以外のすべてに関心があります。
([^<]+)
私たちは彼を必要としているので、私たちは彼を捕囚に包みます。
次に、終了タグbを作成し、「/」文字をエスケープします。これは特殊文字であるためです。
<\/b>
すべてが非常に簡単です。
Parsim URL:
PHPには、URLを操作してコンポーネント部分に解析するのに役立つクールな機能があります。
<?php $URL = "https://hello.world.ru/uri/starts/here?get_params=here#anchor"; $parsed = parse_url($URL); var_dump($parsed);
array(5) { ["scheme"]=> string(5) "https" ["host"]=> string(14) "hello.world.ru" ["path"]=> string(16) "/uri/starts/here" ["query"]=> string(15) "get_params=here" ["fragment"]=> string(6) "anchor" }
定期的に同じことをしましょうか? :)
URLはスキームで始まります。 私たちにとって、これはhttp / httpsプロトコルです。 論理的な「または」を作成できます。
(http|https)
しかし、あなたはカンニングしてこのようにすることができます:
http[s]?
この場合、記号「?」は「s」が食べることができることを意味しますが、そうではありません...
次に、「://」がありますが、「/」文字をエスケープする必要があります(上記を参照)。
“:\/\/”
次に、「/」記号または行末にドメインがあります。 数字、文字、アンダースコア、ダッシュ、ピリオドで構成できます。
[\w\.-]+
ここで、メタ文字「\ w」、ドット「\」、およびダッシュ「-」を1つのグループにまとめます。
次はURIです。 ここではすべてが簡単です。すべてを疑問符または行末に移動します。
[^?$]+
これで疑問符になります。疑問符は次の場合とそうでない場合があります。
[?]?
次に、行末またはアンカーの先頭までのすべて(記号#)-この部分が次のようにならないことも忘れないでください。
[^#$]+
次は#かもしれませんが、そうでないかもしれません:
[#]?
次に、もしあれば、行末までのすべて:
[^$]+
最終的にはすべての美しさが次のようになります(残念ながら、Habrが行の一部をコメントと見なさないようにこの部分を挿入する方法はわかりませんでした)。
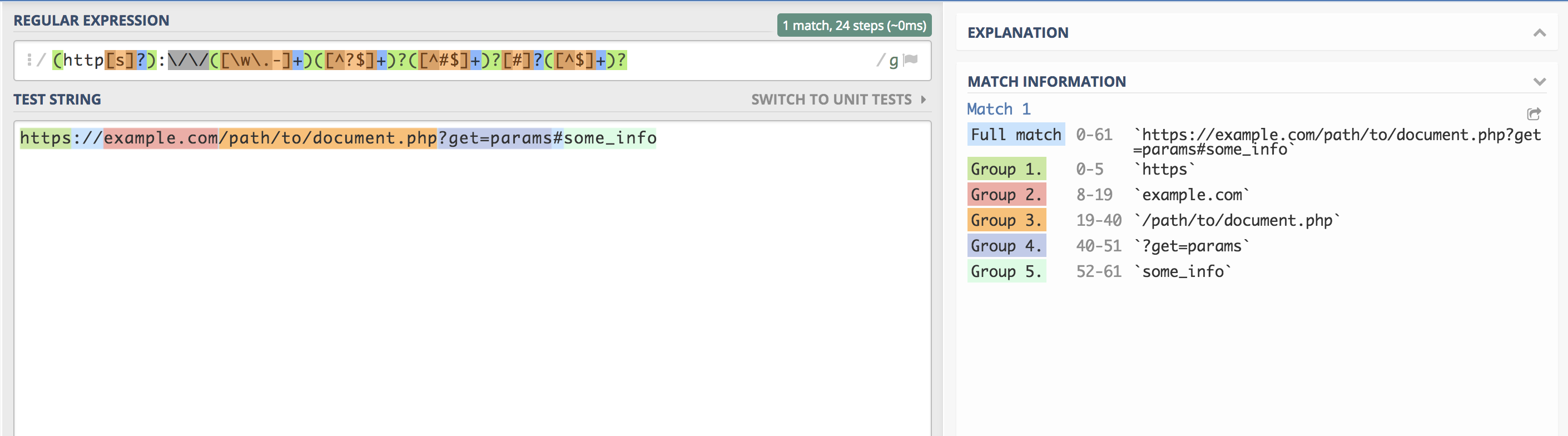
/(?<scheme>http[s]?):\/\/(?<domain>[\w\.-]+)(?<path>[^?$]+)?(?<query>[^#$]+)?[#]?(?<fragment>[^$]+)?/
主なことは点滅しないことです! :)
<?php $URL = "https://hello.world.ru/uri/starts/here?get_params=here#anchor"; $regexp = “/(?<scheme>http[s]?):\/\/(?<domain>[\w\.-]+)(?<path>[^?$]+)?(?<query>[^#$]+)?[#]?(?<fragment>[^$]+)?/”; $result = preg_match($regexp, $URL, $match); var_dump( $result, $match );
array(11) { [0]=> string(61) "https://hello.world.ru/uri/starts/here?get_params=here#anchor" ["scheme"]=> string(5) "https" ["domain"]=> string(14) "hello.world.ru" ["URI"]=> string(16) "/uri/starts/here" ["params"]=> string(15) "get_params=here" ["anchor"]=> string(6) "anchor" }
彼ら自身の手でのみ、それはほぼ同じであることが判明しました。
正規表現で解決されないタスク
一見すると、正規表現を使用してテキストを記述および解析できるようです。 しかし、残念ながら、これはそうではありません。
正規表現は形式言語の亜種であり、チョムスキー階層では最も単純な3番目のタイプに属します。 ここについて。
この言語を使用すると、たとえば、文法が埋め込まれたプログラミング言語の構文を解析できません。 またはHTMLコード。
タスクの例:
スパンがあり、その中には他にも多くのスパンがあり、どれだけの量かはわかりません。 この範囲内にあるすべてのものを選択する必要があります。
<span> <span>ololo1</span> <span>ololo2</span> <span>ololo3</span> <span>ololo4</span> <span>ololo5</span> <...> </span>
もちろん、HTMLを解析する場合、この範囲だけではありません。 :)
一番下の行は、ある時点で、スパン文字と/スパン文字を「カウント」できず、開始文字と終了文字が同じ数でなければならないことを意味します。 そして、これまでペアがなかった終了記号がブロックを分離する終了記号であることを「理解」します。
コードと{}文字についても同じです。
例:
function methodA() { function() {<...>} if () { if () {<...>} } }
このような構造では、正規表現を使用して、コード内の閉じ括弧を初期関数を完了するものと区別することはできません(コードがこの関数だけで構成されていない場合)。
このような問題を解決するには、より高いレベルの言語が使用されます。
おわりに
正規表現の世界の基本についてある程度詳しく話してみました。 もちろん、すべてを1つの記事に収めることは不可能です。 彼らとのさらなる作業は、経験とグーグルの能力の問題です。
ご清聴ありがとうございました。