翻訳者から
少し前に、大きなテキストで単語のセットを見つける問題に遭遇しました。 もちろん、主な問題はパフォーマンスでした。 既製のソリューションの検索では、回答よりも多くの質問が出されました。 多くの場合、サードパーティ製のボックスまたはオンラインサービスを使用する例に出くわしました。 そして何よりもまず、シンプルで簡単なソリューションが必要でしたが、将来的には独自のユーティリティを実装することを考えました。
数週間前、オープンソースのpython-library FlashTextに関する素晴らしい英語の記事が公開されました 。 このライブラリは、テキスト内のキーワードの検索と置換の問題に対する迅速に機能するソリューションを提供しました。
なぜなら この主題に関するロシア語の資料はそれほど多くないので、この記事をロシア語に翻訳することにしました。 カットの下に、問題の説明、ライブラリの原理の分析、およびパフォーマンステストの例があります。
開始する
テキストを操作する際の主なタスクは、テキストをクリアすることです。 通常、このプロセスは非常に簡単です。 たとえば、「Javascript」というフレーズを「JavaScript」に置き換える必要があります。 しかし、多くの場合、テキスト内のフレーズ「Javascript」へのすべての参照を見つける必要があります。
データクリーニングのタスクは、データロジー(データサイエンス)の分野で作業するほとんどのプロジェクトの典型的なタスクです。
データロジーはデータクレンジングから始まります
最近、まさにそのような問題を解決しました。 私はBelong.coで研究者として働いており、 自然言語処理にかかる時間は半分です。
Word2Vecを使用してテキストコーパスを分析し始めたとき、同義語は単一の値として分析されることに気付きました。 たとえば、「Jacascript」などの代わりに「Javascripting」という用語が使用されました。
この問題を解決するには、テキストをクリアする必要がありました。 これを行うために、「Javascript」というフレーズの可能なすべての同義語を元の形式に置き換える正規表現を使用してアプリケーションを作成しました。 ただし、これは新しい問題のみを作成しました。
問題に直面したときに考える人もいる
「私は正規表現を使用することを知っています。」今、2つの問題があります。
私がここでこの引用に出会ったのはこれが初めてであり、私のケースを特徴付けたのは彼女でした。 ソーステキスト内で検索および置換する必要のあるキーワードの数が数百を超えない場合にのみ、正規表現が比較的迅速に実行されることがわかります。 しかし、私たちのテキストコーパスは、300万を超えるドキュメントと2万のキーワードで構成されていました。
すべてのキーワードを正規表現に置き換えるのにかかる時間を見積もると、テキストコーパスを1回実行するのに5日かかることがわかりました。

同様の問題に対する最初の解決策は、複数の検索プロセスと置換プロセスを並行して実行することを示唆しています。 ただし、このアプローチは、データ量が増加した後は効果的ではなくなりました。 現在、テキストコーパスは、数千万のドキュメントと数十万のキーワードで構成されています。 しかし、私はこの問題に対するより良い解決策があるはずだと確信しました! そして私は彼を探し始めました...
私はオフィスの同僚に質問し、 Stack Overflowについて質問をしました。 その結果、いくつかの良い提案がありました。 ヴィネイ・パンディ、スレシュ・ラクシュマナン
議論では 、Aho-Korasikアルゴリズムとプレフィックスツリーを試すことをお勧めしました。
既製のソリューションを見つける私の試みは失敗しました。 価値のあるライブラリは1つも見つかりませんでした。 その結果、提案されたアルゴリズムをタスクのコンテキストで実装することにしました。 だからFlashTextが生まれました。
FlashText実装の詳細を説明する前に、 検索速度がどのように向上したかを見てみましょう。
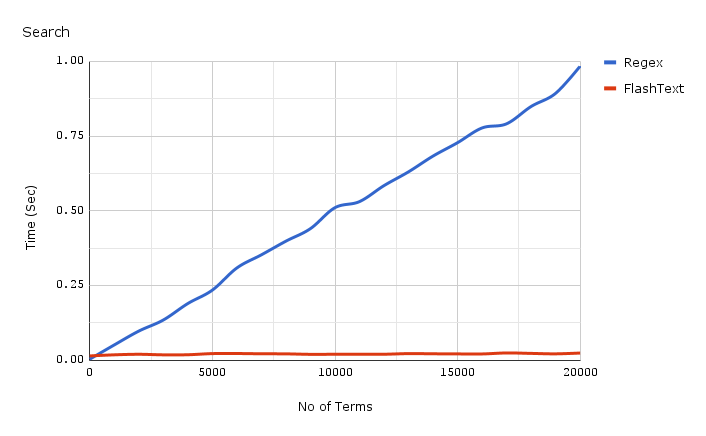
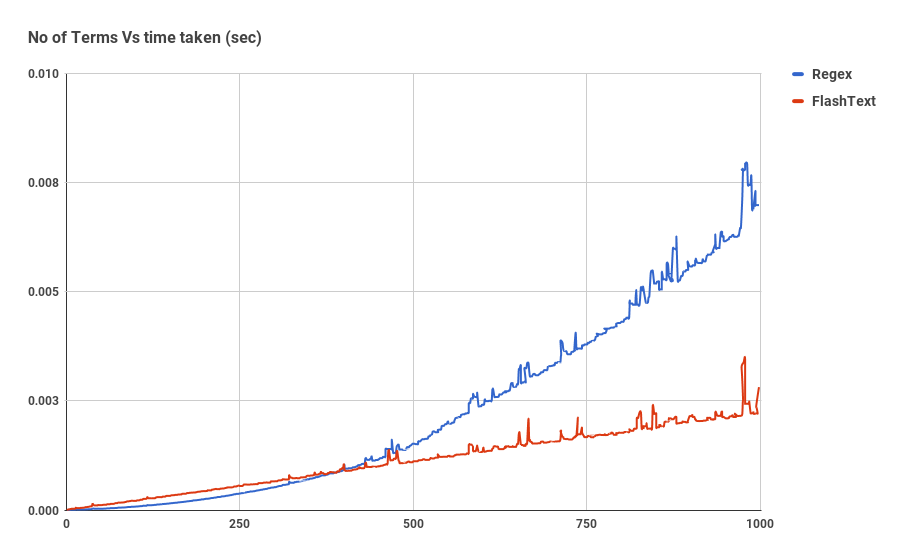
このグラフは、1つのドキュメント内のキーワードの検索操作を実行する場合の、キーワードの数に対する操作時間の依存性を示しています。 ご覧のとおり、正規表現を使用するアプリケーションにかかる時間は、キーワードの数に線形に依存します。 FlashTextの場合、この関係は観察されません。
FlashTextは、テキスト本文の1回の実行にかかる時間を5日から15分に短縮しました。

以下は、1つのドキュメントで置換操作中にキーワードの数に費やされた時間のグラフです。
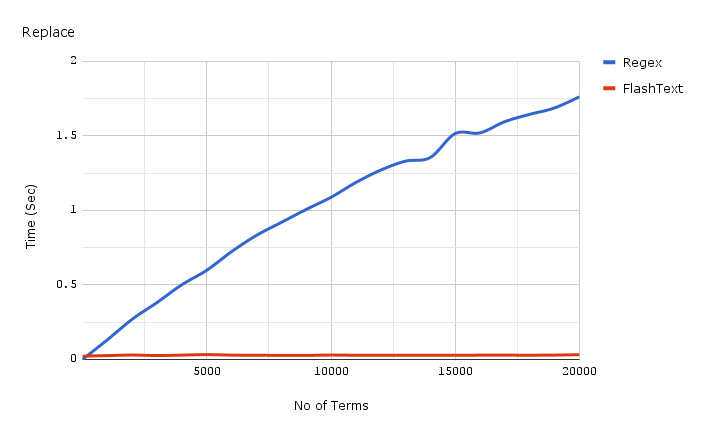
上に提示されたグラフに使用されたベンチマークを得るコードはここで見つけることができます 、そして、ベンチマーク自体はここで 。
では、FlashTextとは何ですか?
FlashTextは、 GitHubで利用できる小さなオープンソースのPythonライブラリです。 検索タスクとテキスト文書のキーワードを置き換えるタスクの両方に同様にうまく対処します。
FlashTextを使用する場合の最初のステップは、ライブラリがプレフィックスツリーの構築に使用するキーワードのコーパスをコンパイルすることです。 その後、検索または置換手順が実行されるテキストがライブラリ入力に提供されます。
置換されると、 FlashTextは置換されたキーワードで新しい行を作成します。 検索時に、ライブラリは入力文字列で見つかったキーワードのリストを返します。 どちらの場合も、結果は入力文字列の1つのパスで取得されます。
幸せなユーザーからの最初の肯定的なレビューはすでにツイッターに掲載されています:
FlashTextがなぜこんなに高速なのですか?
仕事の例を見てみましょう。 3つの単語で構成されるテキストがあるとします。
I like Python
と4つの単語で構成されるキーワードの本体が
I like Python
:
{ Python, Java, J2ee, Ruby }
。
ソーステキスト内のコーパスから各キーワードの存在を確認すると、検索が4回繰り返されます。
is 'Python' in sentence? is 'Java' in sentence? ...
擬似コードから、キーワードのリストがn個の要素で構成されている場合、 n回の反復が必要であることがわかります。
しかし、逆のことができます。キーワードのコーパス内のソーステキストから各単語の存在を確認します。
is 'I' in corpus? is 'like' in corpus? is 'python' in corpus?
文がm個の単語で構成されている場合、 m回の反復があります。 操作の合計実行時間は、テキスト内の単語の数に正比例します。 キーワード本文での単語検索は、テキストでのキーワード検索よりも高速になることに注意してください。 キーワードのコーパスは辞書です。
FlashTextは2番目のアプローチに基づいています。 Akho-Korasikアルゴリズムとプレフィックスツリーも実装に使用されます。
操作アルゴリズムは次のとおりです。
最初に、キーワード本体のプレフィックスツリーが作成されます。 次のようになります。
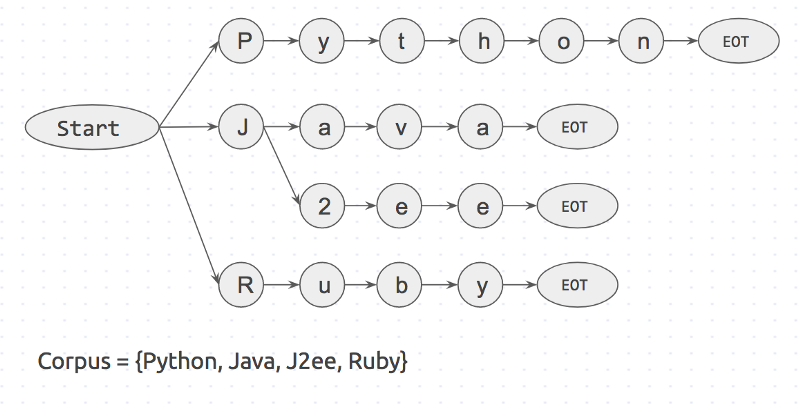
「開始」と「EOT」は単語の境界です:スペース、改行など。 キーワードは、単語の両側に境界文字がある場合にのみ、入力値と一致します。 このアプローチは、リンゴやパイナップルなどの誤った一致を排除します。
次に、例を考えます。
I like Python
行
I like Python
取り、その中のキーワードの要素ごとの検索を開始します。
Step 1: is <start>I<EOT> in dictionary? No Step 2: is <start>like<EOT> in dictionary? No Step 3: is <start>Python<EOT> in dictionary? Yes
以下は、手順3のプレフィックスツリーです。
is <start>Python<EOT> in dictionary? Yes
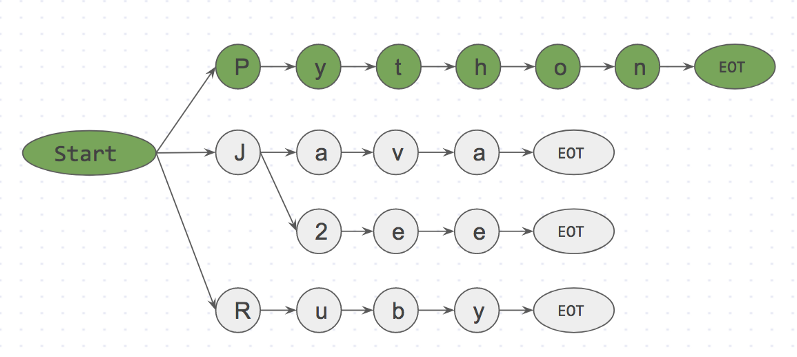
このアプローチのおかげで、最初のキャラクターに<EOT />のようにドロップできます。これは、キャラクター
i
start
隣にないためです。 したがって、コーパスに入力されず、時間を無駄にしない単語をほぼ即座に破棄できます。
FlashTextアルゴリズムは
I like Python
入力文字列文字が
I like Python
と解析しますが、キーワードの本文は任意のサイズにすることができます。 大文字と小文字の区別キーワードの大文字と小文字は、アルゴリズムのパフォーマンスに影響しません。 これがFlashTextアルゴリズムの主な秘密です。
いつFlashTextを使用する必要がありますか?
すべてが非常に簡単です。キーワードの本文のサイズが500を超えるとすぐに、このグラフが表示されます。
ただし、FlashTextとは異なり、正規表現は、FlashTextアルゴリズムではサポートされていない
^,$,*,\d,,
などのソース文字列内の特殊文字を検索できることに注意してください。 つまり、キーワード本体に
word\dvec
要素を含める
word\dvec
ませんが、
word2vec
要素を使用すると、すべてが
word2vec
機能します。
FlashTextを実行してキーワードを検索する方法
# pip install flashtext from flashtext.keyword import KeywordProcessor keyword_processor = KeywordProcessor() keyword_processor.add_keyword('Big Apple', 'New York') keyword_processor.add_keyword('Bay Area') keywords_found = keyword_processor.extract_keywords('I love Big Apple and Bay Area.') keywords_found # ['New York', 'Bay Area']
githubでも同じ
FlashTextを実行してキーワードを置き換える方法
一般に、これはFlashTextが開発された主なタスクでした。 処理する前にデータを消去するために使用します。
from flashtext.keyword import KeywordProcessor keyword_processor = KeywordProcessor() keyword_processor.add_keyword('Big Apple', 'New York') keyword_processor.add_keyword('New Delhi', 'NCR region') new_sentence = keyword_processor.replace_keywords('I love Big Apple and new delhi.') new_sentence # 'I love New York and NCR region.'
githubでも同じ
テストデータの分析、 エンティティの言及の認識 、自然言語またはWord2vecの 処理に取り組む同僚がいる場合は、この記事を共有してください。
このライブラリは私たちにとって非常に有用であることが判明し、他の誰かにとっても有用であると確信しています。
それは長くなりました。 読んでくれてありがとう。