
素晴らしいことわざがあります、「そして、老婦人のためにぼったくりがあります。」 業界のモットーとすることができます。データ損失に対する保護の適切に設計されたマルチレベルシステムでさえ、予期しないバグや人為的エラーの犠牲になります。 悲しいかな、そのような話は珍しくなく、今日はすべてがうまくいかなかったとき、私たちの練習から2つのケースについて話したいです。 昔のフォレストガンプが言っていたように、たわごとが起こります。
ケース1:バグは遍在する
お客様の1人は、ハードウェア障害から保護するために設計されたバックアップシステムを使用しました。 機能レベルのインフラストラクチャとアプリケーションの高可用性を確保するために、Veritas Cluster Serverソフトウェアに基づくクラスターソリューションが使用されました。 データバックアップは、外部ディスクアレイを使用した同期レプリケーションを使用して実現されました。 システムまたはその個々のコンポーネントを更新する前に、ソフトウェアメーカーの推奨事項に従って、常にベンチで継続的なテストが実行されました。
このシステムは有能であり、1つのデータセンターが全体的に失われた場合に備えて、複数のサイトに分散されています。 すべてが正常であり、バックアップソリューションが優れており、自動化が構成されているように見えるため、ひどいことは起こりません。 システムは長年機能し、問題はありませんでした。障害が発生した場合、すべて正常に機能しました。
しかし、サーバーの1つが落ちた瞬間がやってきました。 バックアップサイトに切り替えると、最大のファイルシステムの1つが利用できないことがわかりました。 私たちは長い間それを整理し、ソフトウェアのバグを踏んだことがわかりました。
これらのイベントの直前に、システムソフトウェアの更新がロールアップされたことが判明しました。開発者は生産性を高めるために新しい機能を追加しました。 しかし、これらの機能の1つにはバグがあり、その結果、データベースデータファイルの1つのデータブロックが破損していました。 重さはわずか3 GBでしたが、全体の問題は、バックアップから復元する必要があることです。 そして、システムの最後の完全バックアップは...ほぼ1週間前でした。
まず、顧客は1週間前にバックアップからデータベース全体を取得し、その週のすべてのアーカイブログを適用する必要がありました。 SRKは実際には現在の負荷、空きドライブ、テープドライブに依存しているため、テープから数テラバイトを取得するのに多くの時間がかかりました。
私たちの場合、すべてがさらに悪化しました。 トラブルは一人で起こるわけではありません。 リボンとドライブの両方が割り当てられているため、完全バックアップからの回復は十分に高速でした。 しかし、アーカイブログのバックアップは同じテープ上にあることが判明したため、複数のストリームで並列リカバリを開始することはできませんでした。 私たちは座って、システムがテープ上の目的の位置を見つけ、データを読み取り、巻き戻し、再び目的の位置を検索するなど、円を描くように待ちました。 また、SRKは自動化されていたため、各ファイルのリカバリ用に個別のタスクが生成され、一般的なキューに落ち、その中の必要なリソースの解放を待ちました。
一般に、残念なことに13時間の3ギガバイトを復元しました。
この事故の後、顧客は予約システムを改訂し、IBSの作業を加速することを考えました。 ソフトウェアストレージのオプションとさまざまな分散ファイルシステムの使用を考慮して、テープを放棄することにしました。 当時、顧客にはすでに仮想ライブラリがありましたが、その数は増え、重複排除とローカルデータストレージのソフトウェアコンプレックスを導入して、アクセスを高速化しました。
ケース2:人は間違いを犯しやすい
2番目の話はより平凡です。 分散バックアップシステムを構築するためのアプローチは、サーバー管理コンソールの背後に誰もスキルの低い人員を期待していなかったときに標準化されました。
監視システムはファイルシステムの高い使用率で機能し、勤務中のエンジニアはデータベースを使用してサーバー上のファイルシステムをクリーンアップおよびクリーンアップすることを決定しました。 エンジニアがデータベース監査ログを見つけました-彼にはそう思われます! -そして、そのファイルを削除します。 ただし、データベース自体が「AUDIT」とも呼ばれていました。 その結果、顧客のオンデマンドエンジニアがカタログを混同し、データベース自体を有名に削除しました。
しかし、データベースはその時点で機能しており、削除後に空きディスク容量は増加しませんでした。 エンジニアは、ファイルシステムのサイズを縮小する他の可能性を探し始めました。何が行われたのかを誰にも伝えずに、それらを見つけて落ち着きました。
データベースが遅く、一部の操作がまったく実行されないというメッセージがユーザーから届き始めるまでに約10時間かかりました。 私たちの専門家は理解し始め、ファイルがないことがわかりました。
同期レプリケーションはアレイレベルで機能したため、バックアップサイトに切り替える意味はありませんでした。 一方で行われたすべての変更は、すぐに他方に反映されます。 つまり、メインサイトにもバックアップサイトにもデータがありませんでした。
自殺またはリンチ裁判のエンジニアは、従業員の経験によって救われました。 実際、データベースファイルはクロスプラットフォームのvxfsファイルシステムに配置されていました。 以前に誰もデータベースを停止したことがなかったため、削除されたファイルのiノードは空きリストに入れられず、まだ誰も使用していませんでした。 アプリケーションをインストールしてこれらのファイルを「リリース」すると、ファイルシステムは「ダーティビジネス」を終了し、データで占められたブロックを空きとしてマークし、追加のスペースを要求するアプリケーションは簡単にそれらを上書きできます。
状況を保存するために、外出先でレプリケーションを中断しました。 これにより、リモートノード上のファイルシステムがブロックのリリースを同期できなくなりました。 次に、ファイルシステムデバッガーを使用して、最新の変更を実行し、どのiノードがどのファイルに一致するかを見つけ、それらを再リンクし、データベースファイルが再び表示されることを確認し、データベースの整合性を確認しました。
次に、復元したファイルでデータベースインスタンスをスタンバイモードで起動し、オンラインデータを失うことなくバックアップサイトのデータを同期することを顧客に提案しました。 これがすべて完了したとき、私たちは何の損失もなくリザーブサイトに切り替えることができました。
すべての計算によると、IBSを使用したプライマリリカバリプランは最大1週間続きます。 この場合、それらは完全なアクセス不能性ではなく、サービスの低下を犠牲にします。 人為的ミスは、金銭的および評判の損失、さらにはビジネスの損失につながる可能性があります。
その後、エンジニアが解決策を考え出しました。 顧客システムの90%はOracleデータベースを実行しています。 古いバックアップシステムを残すことを提案しましたが、アプリケーションレベルでバックアップシステムを追加することを提案しました。 つまり、アレイによる同期レプリケーションに加えて、Oracle Data Guardによるソフトウェアも追加されました。 唯一の欠点は、フェイルオーバー後に、自動化に問題のある多くのアクティビティを実行する必要があることです。 これらを回避するために、データベース構成の代わりにクラスターソフトウェアを使用して、サイト間のインスタンスの切り替えを実装しました。
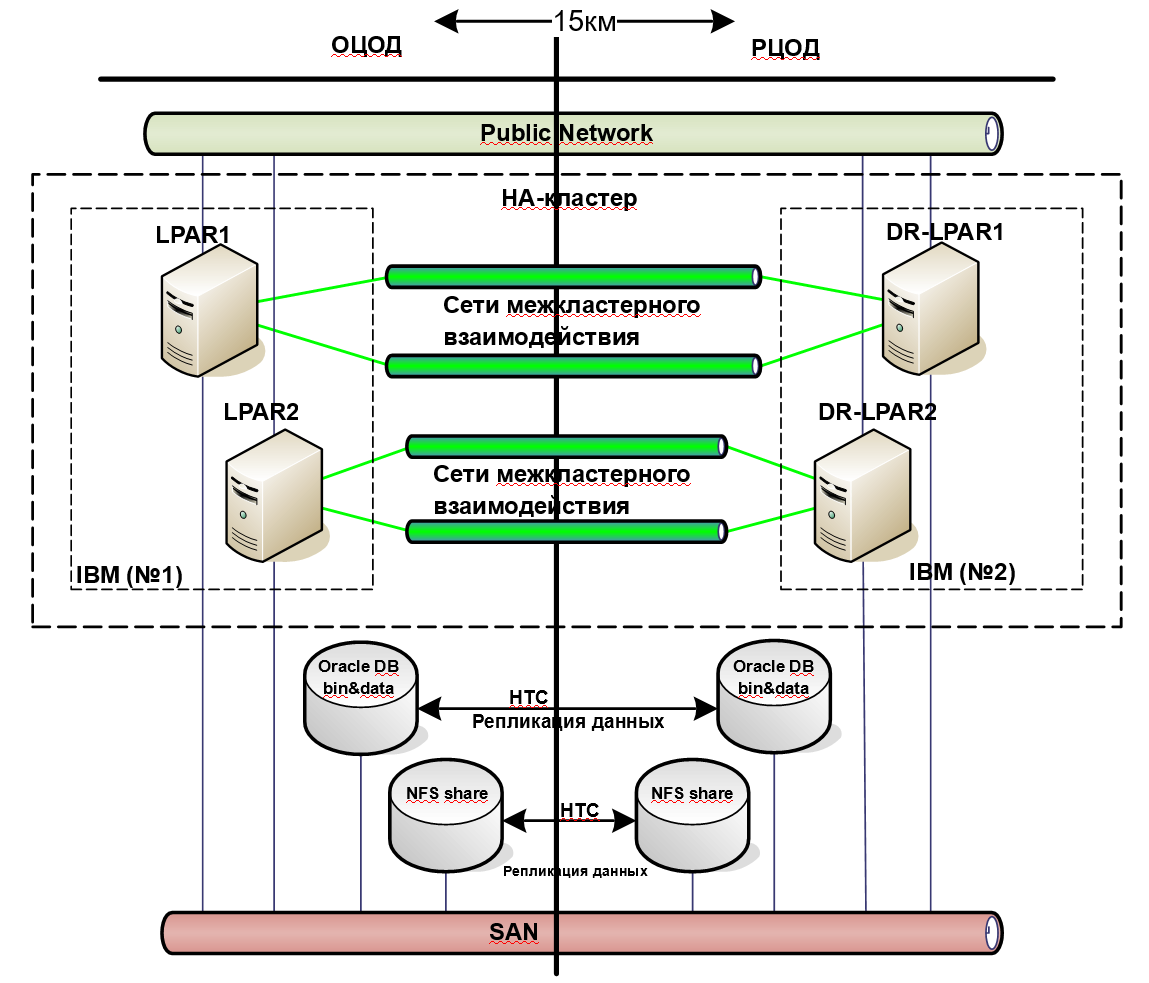
その結果、データ保護のレイヤーが追加されます。 さらに、新しい冗長システムはアレイの要件を削減するのに役立ちました。そのため、顧客はハイエンドレベルのアレイからミッドレベルストレージシステムに切り替えることでコストを節約しました。
こんなハッピーエンドです。
Jet Infosystemsエンタープライズシステムサポートチーム