この例では、トルストイの小説「アンナ・カレーニナ」のテキストを受信すると、オリジナルを幾分連想させる独自のテキストを生成し、次のキャラクターがどうあるべきかを予測するリカレントニューラルネットワークを構築します。
このネットワーク内で何が起こっているのかを詳細に理解しなくても、初心者がすべてのステップを繰り返すことができるようなプレゼンテーション構造を作成しようとしました。 ディープラーニングの専門家は、ここでは何もおもしろいとは思わないでしょう。これらの技術を研究しているだけの人は、猫をお願いします。
はじめに
このミニプロジェクトは、Andrej Karpathyの記事(下のリンク)とudacityトレーニング資料に基づいています。
以下で説明するすべてを繰り返す最も簡単な方法:
- Pythonバージョン3.6でanacondaディストリビューションをPCにインストールする
- 作業コンダ環境を作成する
- この環境にtensorflow、numpy、jupyterライブラリをインストールします
- Jupyter Notebookでコードを記述して実行します。これにより、適切な対話性が得られます。
- 小説のテキストをtxt形式でダウンロードする
Windowsにanacondaをインストールする場合、次の手順を実行します。
1.作業するフォルダを作成し、そこに「anna.txt」という名前でテキストをコピーします
2. Anaconda Promtを実行し、作成されたフォルダーに移動して、必要なライブラリ「tolstoy」をそこに作成し、アクティブにします:
(C:\anaconda3) C:\DL\rnn-tolstoy>conda create -n tolstoy ... (C:\anaconda3) C:\DL\rnn-tolstoy>activate tolstoy (tolstoy) C:\DL\rnn-tolstoy>conda install numpy tensorflow jupyter ...
3.すべてのライブラリがインストールされたら、jupyter Notebookを実行します。ここで作業します:
(tolstoy) C:\DL\rnn-tolstoy>jupyter notebook
4.ブラウザーでノートブックメニューが開き、「新規」に移動して、図に示すように「ノートブック」->「Python 3」を選択します。
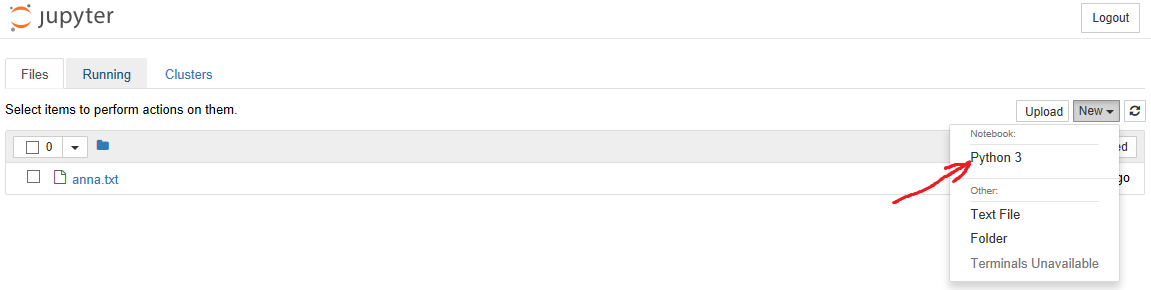
その後、ノートブック自体が開き、コードを入力して、その作業の結果を楽しみます。 たとえば、コードを「In」セルに挿入すると、Shift + Enterを押して実行し、すぐに結果を取得できます。
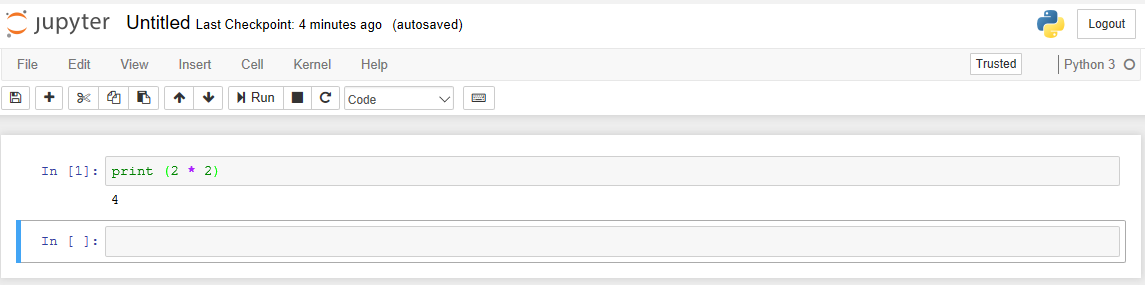
この時点で、基本的なことを理解したので、タスク自体に進むことができます。
以下は、次のシンボルを予測するリカレントニューラルネットワーク(RNN)の一般的なアーキテクチャです( ここから引用 )。
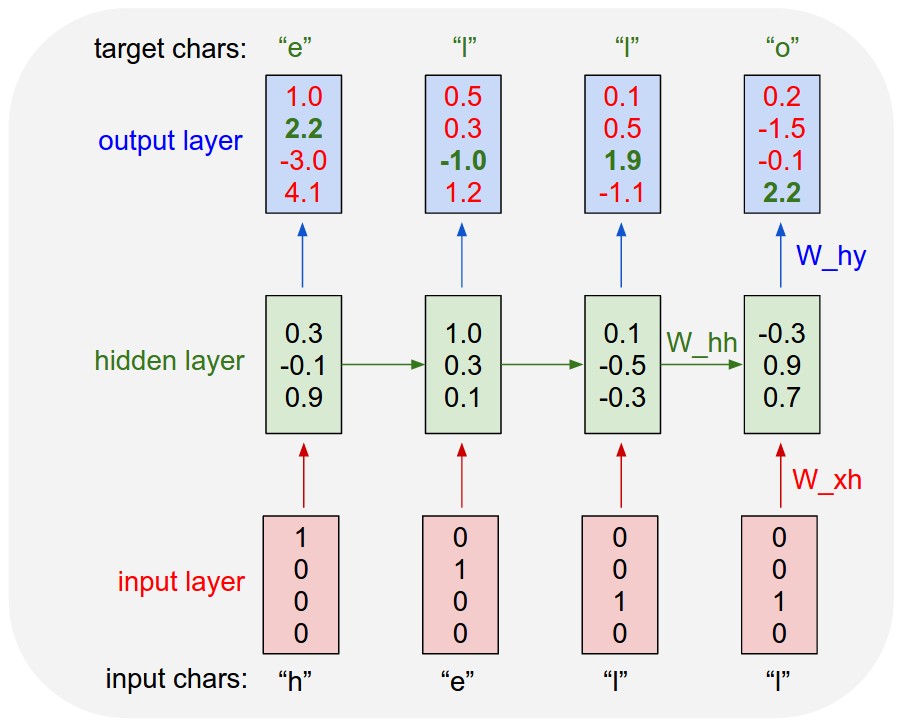
RNNの主要な機能は図で見ることができます-入力から出力に移動するときに情報を周期的に処理でき、(従来のニューラルネットワークとは異なり)メモリ効果を提供し、接続されたシーケンスの処理を可能にします。
データの初期化と準備
必要なライブラリをインポートします。
import time from collections import namedtuple import numpy as np import tensorflow as tf
小説のテキストを読み込み、語彙文字辞書、シンボルを翻訳するための辞書オブジェクト->コード、コード->シンボルを作成し、小説のテキスト全体(エンコードされた配列)をエンコードします。
with open('anna.txt', 'r') as f: text=f.read() vocab = sorted(set(text)) vocab_to_int = {c: i for i, c in enumerate(vocab)} int_to_vocab = dict(enumerate(vocab)) encoded = np.array([vocab_to_int[c] for c in text], dtype=np.int32)
冒頭、有名なフレーズを確認してください、すべてが順調です:
text[:110]
Out: ' \n\n\n\nI\n\n , -.'
エンコードされた形式での表示を確認します(この形式では、データがネットワークで処理されます)。
encoded[:110]
Out: array([ 99, 77, 93, 94, 102, 1, 91, 82, 92, 79, 77, 105, 0, 0, 0, 0, 30, 0, 0, 79, 123, 111, 1, 123, 129, 106, 123, 124, 117, 114, 108, 133, 111, 1, 123, 111, 118, 134, 114, 1, 121, 120, 127, 120, 112, 114, 1, 110, 122, 125, 109, 1, 119, 106, 1, 110, 122, 125, 109, 106, 7, 1, 116, 106, 112, 110, 106, 137, 1, 119, 111, 123, 129, 106, 123, 124, 117, 114, 108, 106, 137, 1, 123, 111, 118, 134, 137, 1, 119, 111, 123, 129, 106, 123, 124, 117, 114, 108, 106, 1, 121, 120, 8, 123, 108, 120, 111, 118, 125, 9])
私たちのネットワークは個々の文字で動作するため、前のテキストから次の文字を予測しようとするとき、分類の問題に対処しています。 辞書の長さは、基本的にネットワークが選択するクラスの数です。
len(vocab)
Out: 140
辞書には多くの文字がありますが、大文字と小文字は異なる文字であり、フランス語の大量のテキストも覚えています。 基本的に2つのアルファベットがあります。
データをパッケージに分割する
ネットワークを効果的にトレーニングするには、データをパケットに分割する必要があります(ミニバッチ)。 まず、RAMを節約します。 すべてのデータを一度にネットワークに送信しようとすると、十分なメモリがない可能性があります。 第二に、データをパケットに粉砕するとき、ネットワークははるかに速く学習します-各データパケットを渡すたびにニューラルネットワークの重みを更新し、図に示すようにパケットを並列にロードできます。
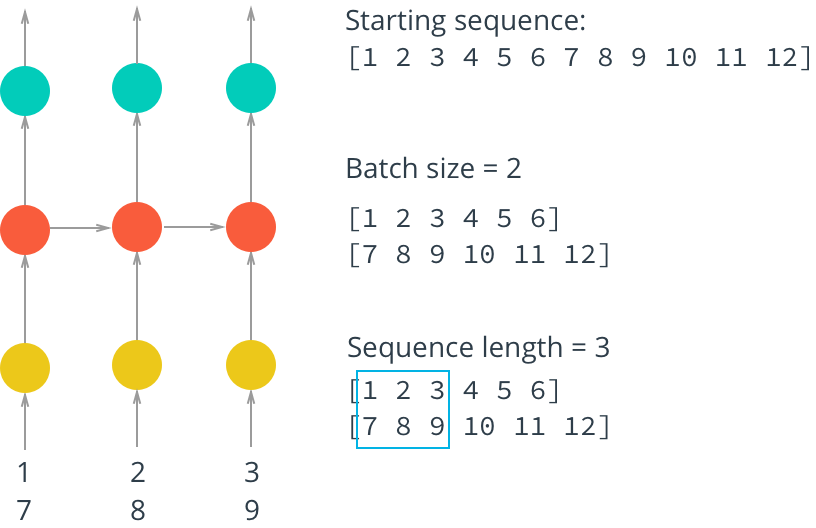
ソースパケットを取得するための手順を作成します。ソースパケットは、ニューラルネットワーク(機能)の入力と、ネットワーク(ターゲット)の予測が比較される制御パケットに入力されます。
def get_batches(arr, n_seqs, n_steps): ''' , n_seqs x n_steps arr. --------- arr: , n_seqs: Batch size, n_steps: Sequence length, "" ''' # , characters_per_batch = n_seqs * n_steps n_batches = len(arr)//characters_per_batch # , arr = arr[:n_batches * characters_per_batch] # reshape 1D -> 2D, n_seqs , arr = arr.reshape((n_seqs, -1)) for n in range(0, arr.shape[1], n_steps): # , x = arr[:, n:n+n_steps] # , , "x" y = np.zeros_like(x) y[:, :-1], y[:, -1] = x[:, 1:], x[:, 0] yield x, y
この関数はジェネレーターとして機能し、各呼び出しにより、たとえば次の「x」と「y」のペアを取得できます。
batches = get_batches(encoded, 10, 50) x, y = next(batches) print('x\n', x[:5, :5]) print('\ny\n', y[:5, :5])
x [[ 99 77 93 94 102] [ 1 110 108 114 112] [ 79 120 124 1 120] [114 119 1 109 120] [106 108 111 110 117]] y [[ 77 93 94 102 1] [110 108 114 112 111] [120 124 1 120 124] [119 1 109 120 108] [108 111 110 117 114]]
出力は、パケット「x」に対するパケット「y」のシフトを示しています。
モデルを構築する
以下に、RNNモデルの図を示します。
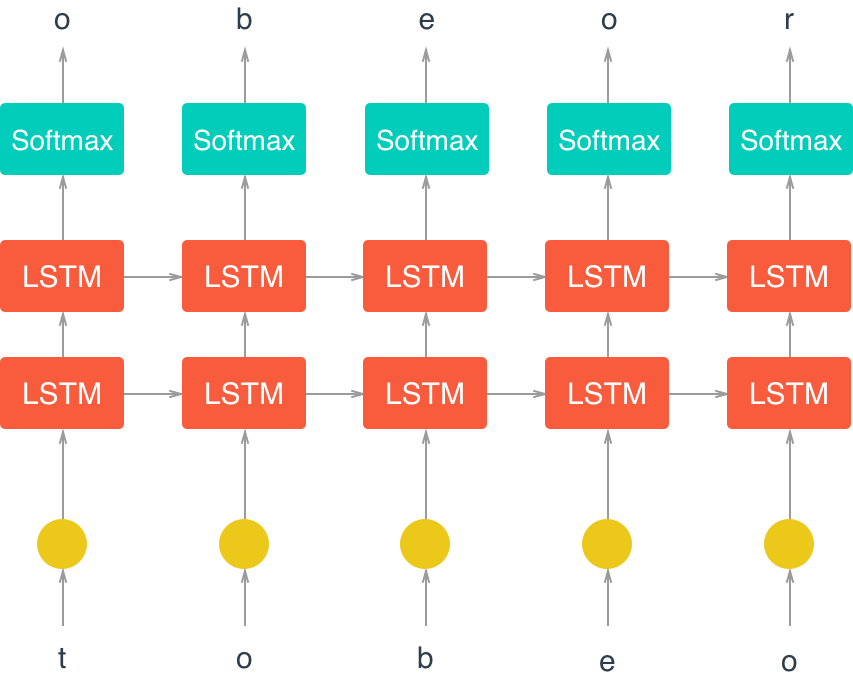
学習の主な魔法は、LSTM(Long Short Term Memory)セルで発生します。
以下に、LSTMに基づいたそのようなセルおよびニューラルネットワークの操作の論理を、シンプルでわかりやすい英語で説明した素晴らしい記事を示します。
モデルを構築するとき、最初に入力パラメーターを決定します。
def build_inputs(batch_size, num_steps): ''' placeholder' , , drop out --------- batch_size: Batch size, num_steps: Sequence length, "" ''' # placeholder' inputs = tf.placeholder(tf.int32, [batch_size, num_steps], name='inputs') targets = tf.placeholder(tf.int32, [batch_size, num_steps], name='targets') # Placeholder drop out keep_prob = tf.placeholder(tf.float32, name='keep_prob') return inputs, targets, keep_prob
Tensorflowのデータはテンソルに格納されていることを思い出してください。
「 プレースホルダー 」-データのタイプと形式(たとえば、マトリックスの次元)を決定するテンソルのタイプ。データ自体は、実際には将来適切なタイミングでロードされます。
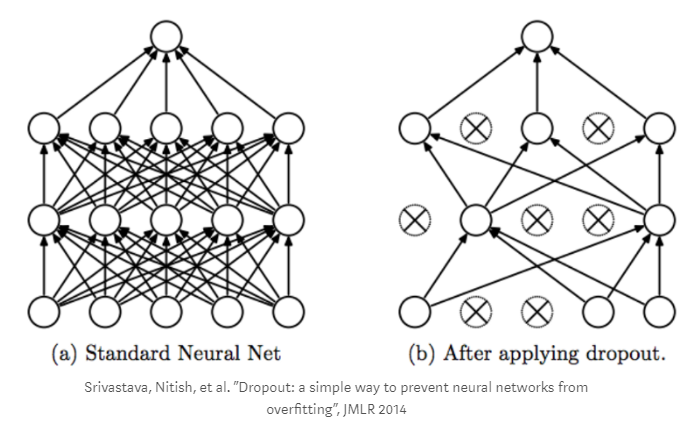
ドロップアウトに関しては、これはネットワークの「再トレーニング」効果に対抗するメカニズムです。このプロセスでは、グラフの頂点の一部をランダムに計算から除外します。
次に、LTSMセルの構造を構築します。
def build_lstm(lstm_size, num_layers, batch_size, keep_prob): ''' LSTM . --------- keep_prob: (tf.placeholder) dropout keep probability lstm_size: LSTM num_layers: LSTM batch_size: Batch size ''' ### LSTM def build_cell(lstm_size, keep_prob): # LSTM lstm = tf.contrib.rnn.BasicLSTMCell(lstm_size) # dropout drop = tf.contrib.rnn.DropoutWrapper(lstm, output_keep_prob=keep_prob) return drop # LSTM deep learning cell = tf.contrib.rnn.MultiRNNCell([build_cell(lstm_size, keep_prob) for _ in range(num_layers)]) # LTSM initial_state = cell.zero_state(batch_size, tf.float32) return cell, initial_state
次に、出力レイヤーを構築します。 寸法を決定します。
入力データに次元M (バッチサイズ)、 N (シーケンス長)があり、サイズL単位の隠れ層を通過した場合、出力は次元MxNxLの 3Dテンソルになります。 問題を単純化するために、3D-> 2Dの形状を変更し、テンソルを(M ∗ N)×Lの形に縮小します。 したがって、各シーケンスと各「ステップ」と各行の値に対して1行があります-LSTMユニットを終了します。
このマトリックスに出力レベルの重みのマトリックスを掛け、出力レベルのオフセットを追加します。
この場合、切り捨てられた正規分布(2標準偏差の範囲)を持つランダム変数で重みを初期化し、ゼロで初期化するバイアスをニューラルネットワークで推奨されています。
出力層の結果は、この関数の結果を予測子として使用して、softmaxアクティベーション関数に渡されます(アクティベーション関数の詳細はこちら )。
def build_output(lstm_output, in_size, out_size): ''' softmax . --------- x: LSTM in_size: , (- LSTM ) out_size: softmax ( ) ''' # , 3D -> 2D seq_output = tf.concat(lstm_output, axis=1) x = tf.reshape(seq_output, [-1, in_size]) # LTSM softmax with tf.variable_scope('softmax'): softmax_w = tf.Variable(tf.truncated_normal((in_size, out_size), stddev=0.1)) softmax_b = tf.Variable(tf.zeros(out_size)) # logit- logits = tf.matmul(x, softmax_w) + softmax_b # softmax out = tf.nn.softmax(logits, name='predictions') return out, logits
次に、損失関数を決定します(つまり、どれだけ間違えたかを測定します)。 これを行うには、ロジット関数とラベルの値の間のソフトマックスクロスエントロピーを計算します(これは、ワンホットコーディングを通過したターゲット値です)。
ディープラーニングでは、カテゴリ変数をバイナリベクトルとして表すためにワンホットコーディングがよく使用されるため、以降の計算で使用するのに便利です。 たとえば、データシーケンス:
[red, yellow, green]
(上記のエンコードされた変数で行ったように)整数でエンコードできます。
[0, 1, 2]
ワンホットコーディングの後、次のようになります。
[[1, 0, 0],
[0, 1, 0],
[0, 0, 1]]
ディープラーニングの損失関数は別の方法で考慮されます。 相互に排他的なクラスに属するオブジェクトを分類するタスクの場合(この場合、次の文字を同時に「a」と「b」にすることはできません)、 ロジット関数によるソフトマックスクロスエントロピーを通じて損失関数が考慮され、すべての次元のすべての要素のこの関数の平均値が返されますテンソル。
def build_loss(logits, targets, lstm_size, num_classes): ''' logit- . --------- logits: logit- targets: , lstm_size: LSTM num_classes: ( ) ''' # one-hot logits y_one_hot = tf.one_hot(targets, num_classes) y_reshaped = tf.reshape(y_one_hot, logits.get_shape()) # softmax cross entropy loss loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_reshaped) loss = tf.reduce_mean(loss) return loss
次に、勾配降下法に基づくオプティマイザーを構築します。 同時に、2つの問題から身を守ります(詳細はこちら )。
- 勾配の「消失」(保護はLSTMセルのロジックに組み込まれています)。
- グラデーションの「爆発」(このため、ここではグラデーションクリッピングを使用します)。
最適化関数として、Adamオプティマイザーを使用します
def build_optimizer(loss, learning_rate, grad_clip): ''' , . Arguments: loss: learning_rate: ''' # , "" tvars = tf.trainable_variables() grads, _ = tf.clip_by_global_norm(tf.gradients(loss, tvars), grad_clip) train_op = tf.train.AdamOptimizer(learning_rate) optimizer = train_op.apply_gradients(zip(grads, tvars)) return optimizer
次に、パズルの詳細をすべて収集し、ネットワークを説明するクラスを作成します。 RNNネットワークを形成するキーオペレーターはtf.nn.dynamic_rnnです。 各シーケンスの各ステップで、各パケットの各LSTMセルの出力を返します(ミニバッチ)。 さらに、LSTMセルの最終ステータスを返します。これは保存され、次のデータパケットをロードするときに最初のLSTMセルの入り口に渡されます。 入力tf.nn.dynamic_rnnで、セル(セル)、build_lstmから取得した初期ステータス、および入力データシーケンスを送信します。
class CharRNN: def __init__(self, num_classes, batch_size=64, num_steps=50, lstm_size=128, num_layers=2, learning_rate=0.001, grad_clip=5, sampling=False): # ( ), # if sampling == True: batch_size, num_steps = 1, 1 else: batch_size, num_steps = batch_size, num_steps tf.reset_default_graph() # input placeholder' self.inputs, self.targets, self.keep_prob = build_inputs(batch_size, num_steps) # LSTM cell, self.initial_state = build_lstm(lstm_size, num_layers, batch_size, self.keep_prob) ### RNN # one-hot x_one_hot = tf.one_hot(self.inputs, num_classes) # RNN outputs, state = tf.nn.dynamic_rnn(cell, x_one_hot, initial_state=self.initial_state) self.final_state = state # (softmax) logit- self.prediction, self.logits = build_output(outputs, lstm_size, num_classes) # ( ) self.loss = build_loss(self.logits, self.targets, lstm_size, num_classes) self.optimizer = build_optimizer(self.loss, learning_rate, grad_clip)
ハイパーパラメーターを選択します
次に、モデルのハイパーパラメーターを設定します。 これらのパラメータを変更することにより、ネットワークからより多くの「絞り込み」ができるため、創造性のためのスペースがたくさんあります。 これは個別の大きなトピックであり、多くの記事や研究に当てられているため、チューニング戦略については詳しく説明しません。
batch_size = 100 # num_steps = 100 # lstm_size = 512 # LSTM num_layers = 2 # LSTM learning_rate = 0.001 # keep_prob = 0.5 # Dropout keep probability
トレーニングモデル
次に、モデルのトレーニングを開始します。
入力データとターゲットデータをネットワークに投入し、最適化を開始します。 各パケット(ミニバッチ)について、最終LSTMステータスを保存します。これは、次のパケットでネットワーク入り口に与えられ、継続性を保証します。 定期的に(save_every_n変数によって決定されます)モデルの状態(すべての変数、重みなどを含む)をcheckpointに保存します。 ここにはもう1つのパラメーターがあります-エポックの数(完全なモデル学習サイクル)。 また、Tensorflow内のデータを扱うすべての作業は、通常は
with tf.Session() as sess:
始まるコード
with tf.Session() as sess:
始まるオープンセッションの一部として実行されることを思い出してください
with tf.Session() as sess:
epochs = 20 # N save_every_n = 200 model = CharRNN(len(vocab), batch_size=batch_size, num_steps=num_steps, lstm_size=lstm_size, num_layers=num_layers, learning_rate=learning_rate) saver = tf.train.Saver(max_to_keep=100) with tf.Session() as sess: sess.run(tf.global_variables_initializer()) # checkpoint' #saver.restore(sess, 'checkpoints/______.ckpt') counter = 0 for e in range(epochs): # new_state = sess.run(model.initial_state) loss = 0 for x, y in get_batches(encoded, batch_size, num_steps): counter += 1 start = time.time() feed = {model.inputs: x, model.targets: y, model.keep_prob: keep_prob, model.initial_state: new_state} batch_loss, new_state, _ = sess.run([model.loss, model.final_state, model.optimizer], feed_dict=feed) end = time.time() print('Epoch: {}/{}... '.format(e+1, epochs), 'Training Step: {}... '.format(counter), 'Training loss: {:.4f}... '.format(batch_loss), '{:.4f} sec/batch'.format((end-start))) if (counter % save_every_n == 0): saver.save(sess, "checkpoints/i{}_l{}.ckpt".format(counter, lstm_size)) saver.save(sess, "checkpoints/i{}_l{}.ckpt".format(counter, lstm_size))
さらに、学習プロセスを観察します。
Epoch: 1/20... Training Step: 1... Training loss: 4.9402... 7.7964 sec/batch Epoch: 1/20... Training Step: 2... Training loss: 4.8530... 7.1318 sec/batch ... Epoch: 20/20... Training Step: 3400... Training loss: 1.4003... 6.6569 sec/batch
トレーニング損失は徐々に減少します。
私のPCでは、この学習プロセスに約6時間かかりました。 優れたGPUを搭載したマシンがある場合、この期間は大幅に短縮できます。
保存されたチェックポイントの確認:
tf.train.get_checkpoint_state('checkpoints')
model_checkpoint_path: "checkpoints\\i3400_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i200_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i400_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i600_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i800_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i1000_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i1200_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i1400_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i1600_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i1800_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i2000_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i2200_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i2400_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i2600_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i2800_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i3000_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i3200_l512.ckpt" all_model_checkpoint_paths: "checkpoints\\i3400_l512.ckpt"
テキストを生成する
これで、サンプリング、つまりテキストの生成を開始できます。
アイデアは、1つのシンボルをネットワーク入力に供給することにより、出力で予測シンボルを取得し、生成されたテキストに追加して、次の反復でネットワーク入口に再度供給するなどです。 例外は、primeパラメーターの入力に供給されるモデルを「ウォームアップ」するためのテキストです。
pick_top_n
関数
pick_top_n
使用して予測の「ノイズ」を減らし、指定した数(デフォルトでは5)の文字オプションのみを選択用に残し、他のオプションはすべて破棄します。
def pick_top_n(preds, vocab_size, top_n=5): p = np.squeeze(preds) p[np.argsort(p)[:-top_n]] = 0 p = p / np.sum(p) c = np.random.choice(vocab_size, 1, p=p)[0] return c
def sample(checkpoint, n_samples, lstm_size, vocab_size, prime=" ."): samples = [c for c in prime] model = CharRNN(len(vocab), lstm_size=lstm_size, sampling=True) saver = tf.train.Saver() with tf.Session() as sess: saver.restore(sess, checkpoint) new_state = sess.run(model.initial_state) for c in prime: x = np.zeros((1, 1)) x[0,0] = vocab_to_int[c] feed = {model.inputs: x, model.keep_prob: 1., model.initial_state: new_state} preds, new_state = sess.run([model.prediction, model.final_state], feed_dict=feed) c = pick_top_n(preds, len(vocab)) samples.append(int_to_vocab[c]) for i in range(n_samples): x[0,0] = c feed = {model.inputs: x, model.keep_prob: 1., model.initial_state: new_state} preds, new_state = sess.run([model.prediction, model.final_state], feed_dict=feed) c = pick_top_n(preds, len(vocab)) samples.append(int_to_vocab[c]) return ''.join(samples)
次に、テキストを生成し、何が起こったのかを確認します。
手始めに-モデルの初期状態(200回の反復後)。
checkpoint = 'checkpoints/i200_l512.ckpt' samp = sample(checkpoint, 1000, lstm_size, len(vocab)) print(samp)
INFO:tensorflow:Restoring parameters from checkpoints/i200_l512.ckpt . – ,, , , , , , , , , , , , ,.. – , , , ,
一方では、それはある種のナンセンスであることが判明しました。 一方、ニューラルネットワークは、単語をスペースで区切られた一連の文字として理解し始め、句読点も使用し始めることがわかります。
さらに先へ進みます(600回目の反復後)。
checkpoint = 'checkpoints/i600_l512.ckpt' samp = sample(checkpoint, 1000, lstm_size, len(vocab)) print(samp)
INFO:tensorflow:Restoring parameters from checkpoints/i600_l512.ckpt . , , , - , , , , , . – , , . , – . – , , , , , , , , ,
ここで、「言葉」がより本物になり、対話の始まりが概説されました。 ある時点で、ネットはさらに呪われました:)
一般的に、ポジティブなダイナミクスは明らかです。
さて、最後の反復の結果。
checkpoint = tf.train.latest_checkpoint('checkpoints') samp = sample(checkpoint, 2000, lstm_size, len(vocab)) print(samp)
INFO:tensorflow:Restoring parameters from checkpoints\i3400_l512.ckpt . , , , , . . , , . – , , – , – , - , , , , , , . . , , , . – . , , , . – , , – . – , , , . , , . , – . – . – , , – , – , , – . – , , – , – , , , , – , , – . «, , . , , , – , , , – - . – , . . , – , . ,
ここで、単語は主に文字で構成されていることがわかります。ダイアログがマークされている、句読点が適切に配置されているなど。あなたが遠くから見て、テキストを読まなければ、それはまともに見えます。
おわりに
明らかに、私たちのネットワークはまだLeo Tolstoyとして書く方法を学んでいませんが、学習するにつれて進歩は明らかです。同時に、より大きな意味に向けて移動するには、他の方法(たとえば、単語の埋め込み)を使用する必要があります。char-wiseRNNを使用すると、適切な文法を取得するのは比較的簡単ですが、テキストから意味を理解することは明らかに容易ではないためです。
それにもかかわらず、この例は、ルールや言語の文法が彼女に提供されておらず、彼女自身がこれらすべてを考えなければならないという事実にもかかわらず、ニューラルネットワーク内でどのような魔法が発生する可能性があるかを示しています。
もちろん、任意の言語で別のテキストを入力に送信し(できればボリュームが大きいこともあります)、ハイパーパラメーターを操作して、他の結果を取得することができます。説明した手順を簡単に繰り返しても、ここですべてがどのように機能するかを誰かに理解してもらい、途中で多くの興味深い発見があることを保証します:)