
はじめに
想像してみてください。同社はロシアのほとんどすべての集落に4万台以上のユニットを持っています。 ある時点で、彼らはスケーラビリティの天井にぶつかり、何かを変えて新しい技術的ソリューションを使用する時が来たことに気付きました。
その後、私たちと一緒に、AzureサービスとMicrosoft SQL Server DBMSに基づいてソリューションが開発されました。 彼と一緒に、データ処理用の特別なソフトウェアをインストールする必要はなく、エラーは早い段階で検出され始めました。 その結果、宝くじチケットを扱う支店の数は8から22,000に増加し、チケット販売量は3倍に増加しました。
記事の著者であるPavelにフロアを渡します。
今日、クラウドサービスがより一般的になっています。 多くの人が「なぜそんなに良いのか」という質問に答えると思います。「まず第一に、拡張性、高品質のインフラストラクチャ、豊富なサービスを備えています。」しかし、時には知識が時間とお金の節約に役立ちます。 この記事では、Entity Framework + Azure SQLバンドルで開発する際に考慮すべきいくつかの機能についてのみ説明します。
Azure SQLから始めましょう
開発者の観点から見ると、これは最新のMicrosoft SQL Serverとほぼ同じです。 最も重要な違いは、クラウドベースのDBMSの価格が依存する人為的なパフォーマンス制限の存在です。
- オンプレミスサーバーでは、CPUパワー、HDD速度、およびRAM容量によって制限されますが、原則として、これらはすべて適切な供給で購入されます。
- クラウドバージョンでは、所有しているハードウェアリソースの量がわかりません。代わりに、DTU(データ転送ユニット)と呼ばれる推定パフォーマンス値があります。
もちろん、このパラメーターの計算には、CPUとディスクおよびログの入出力操作の数の両方が関与しますが、式の正確な構成は不明です。 そして最も重要なこと-リーズナブルな価格で、多くのDTUはありません。 また、多くのDTUの費用は絶対に下品です。 明らかに、それらは保存され、無駄にならない必要があります。 また、純粋に財務上の考慮事項に加えて、もう1つ非常に重要なことがあります。DBMSのスケーリングはかなり不十分です。
「どのように?」と尋ねます。 -「私たちはクラウドの中にいます。使用したリソースに対してのみ支払いを行い、ソリューションを迅速にスケーリングできるようにします。 クリックして、使用可能なDTUの数をいつでも5倍に増やすことができます。
ただし、プラットフォーム内で異なるパフォーマンスカテゴリへの移行がどのように発生するかを同時に念頭に置いてください。
そして、それはこのように起こります :
- バックアップからのデータベースの回復が行われます。
- 拠点間のレプリケーションが構成されています。
- ベースが同期されると、切り替えが発生します(当然、可用性にわずかなギャップがあり、この時間は30秒を超えないことが示されています)。
復旧と同期のプロセスにかかる時間はゼロではなく、標準レベルのデータベースの50 GBごとに約1時間かかります。これは、負荷のないデータベースの場合です。 つまり、データベースの重量が150 GBで、広告キャンペーン後の午前中にデータベースの負荷が100%になり、すべてが遅くなる場合、昼食までにDTUの数を最大で増やすことができます。 もちろん、この時間中にあなたのビジネス部門はあなたに魔法の雲を見た場所をカラフルに説明し、また彼らの誇れるスケーラビリティと安定性がどこにあるかを尋ねます。
最終的な結論は簡単です。パフォーマンスには常にマージンが必要であり、パフォーマンスレベルの切り替えは事前に行う必要があります。
なぜデータベースリソースを節約する必要があるのかという問題を理解したら、「どのように」という質問に答えようとします。
最初のアプローチ-必要なもののみを取ります
まず、最新の設計アプローチでは、ストアドプロシージャの使用がほぼ完全になくなることに注意してください。 いいえ、誰も禁止していませんが、このアプローチは主要なものであってはなりません。 従来の2層アプリケーションの時代では、DBMSサーバーでのストアドプロシージャの積極的な使用は良い形でした。 しかし、それは、ASP.NETアプリケーションによって現在実装されているまさにアプリケーションサーバーを実装する手段でした。 もちろん、ロジックをDBMSに転送すると、再び「問題点1」と呼ばれるスケーリングの問題が発生します。
そのため、クエリを作成するためのASP.NET + Entity FrameworkとLINQ to SQL Webアプリケーションがあります。 便利-すでに恐怖。 データベースを忘れることができます...うん、ここが主な危険です。 残念ながら、単純な場合にのみデータベースについて忘れることができます。 そして、複雑で重い負荷で.... 以下に具体例を示します。 条件によっていくつかのレコードを取り出す必要があるとします:
myContext.MyTable.Where(x=>x.Amount>100).ToList();
すべてが素晴らしく、シンプルで明確です。 以下に相当する単純なクエリ:
Select * from MyTable where amount>100
次のコードでは、このテーブルの20のフィールドのうち3つだけを使用する必要があることを想像してください-Amount、ClientID、AccountIDとします。 そして、常に20をすべて取得します。適切なワークロードでは、Amountインデックスがある場合でも、すべてのフィールドを選択すると大量のディスクアクセスが作成され、そうでない場合はテーブル全体のフルスキャンが行われることがすぐに明らかになります。 このような場合はすべて2つの側面で解決されます。アプリケーション側では、絶対に必要なフィールドのみを選択します。
myContext.MyTable.Where(x=>x.Amount>100) .Select(x=>new MyTableViewModel{ ClientID = x.ClientID, AccountId = x.AccountID, Amount = x.Amount }) .ToList();
そして、この例のように、そのようなフィールドがtotalテーブルのフィールドよりも大幅に少ない場合、フィールドが含まれたインデックスが作成されます。
create index IX_AmountEx on MyTable(Amount) include(AccountID, ClientID)
クエリプランを見ると、すべてのデータがインデックスから取得されているため、ディスクアクセスはほとんどありません。 DTUは非常に経済的に消費されます。
最も興味深いのは、プラットフォーム自体が、説明されたシナリオに従って改良が必要な要求を通知することです。 稼働中のデータベースでは、プラットフォームが提供するインデックスに関する推奨事項に注意深く従う必要があります。 これらの推奨事項は、メニュー項目のパフォーマンスに関する推奨事項に収集されています。
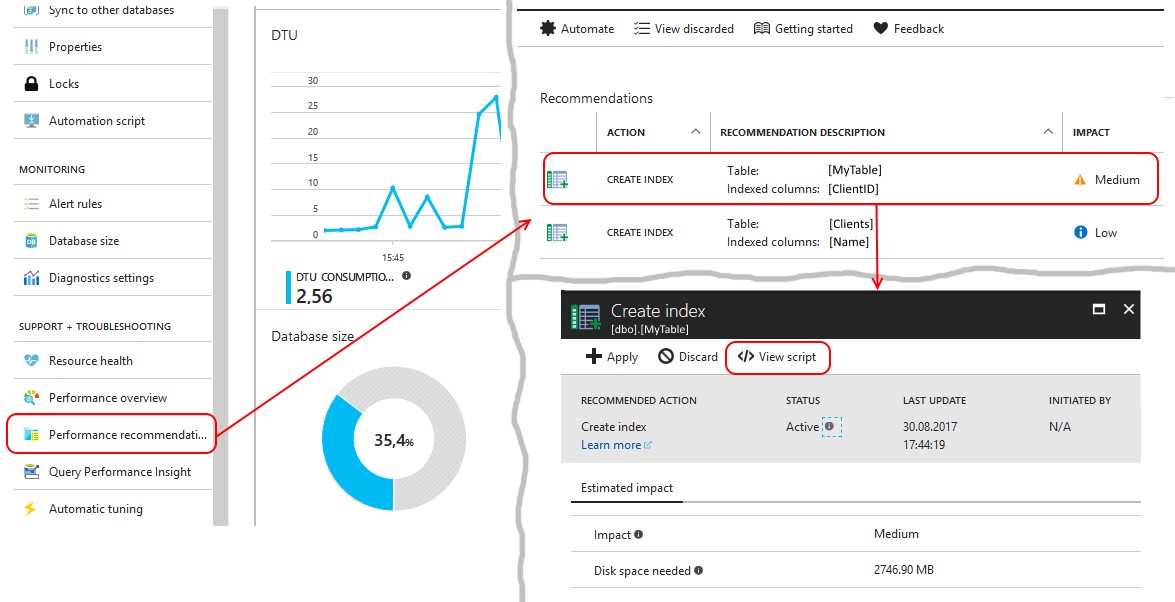
システムが提供するインデックスを作成するには、リクエストを確認する必要があります。 そして、INCLUDEがキーのフィールドを除くテーブルのすべてのフィールドをリストするインデックスを作成することが提案されている場合、これは上記のケースにすぎません!
2番目のアプローチ-より簡単に
ディスクストレージの低コストにより、DBMSのデータを非正規化する一般的な傾向が生まれています。 ここから、NoSQLデータベースが登場し始めました。NoSQLデータベースを使用するには、特定のアプローチが必要ですが、速度が大幅に向上します。 ある程度までは、通常のリレーショナルDBMSにも同様の原則を適用する必要があります。
6階建ての結合がどれほど美しいものであっても、その実装はサーバーにとってかなり難しい作業です。 サーバーをデータベースの半分に「シャベル」して2桁の数字を生成するのはまともな作業ですが、スケーリングが大幅に制限されます。 実践では、サーバーに1つの複雑なクエリを強制するよりも、DBMSに対して2つの単純なクエリを作成し、その結果をメモリに貼り付ける方が簡単な場合が多いことが示されています。 さらに、3行を生成する要求を作成するよりも、単純な要求で5〜7,000行を取得し、アプリケーションサーバーによる作業を完了する方が、より簡単で高速ですが、同時に利用可能なすべてのリソースを使い果たします。 このため、論理負荷の一部をアプリケーションサーバーに転送します。このスケーリングには2分かかり、多くの場合自動的に行われます。 また、DBMSのスケーリングの難しさについては、すべて上記で既に述べました。
例
顧客の注文の合計数について統計を選択しようとしているとします。各注文は1万からでした。 合計金額、そのような注文の数、クライアントの名前を提供する必要があります。 操作は特定の
Transactions
テーブルに保存され、クライアントはそれぞれ
Clients
保存されます。 典型的なクエリは次のようになります。
from t in dc.Transactions where t.Amount>10000m group t by t.ClientID into tg join cli in dc.Clients on tg.Key equals cli.ID into resTable from xx in resTable select new { Amount = tg.Sum(x => x.Amount), ClientID = tg.Key, ClientName = xx.Name, ItemCount = tg.Count() };
Entity Frameworkが何に変えるか見てみましょう:
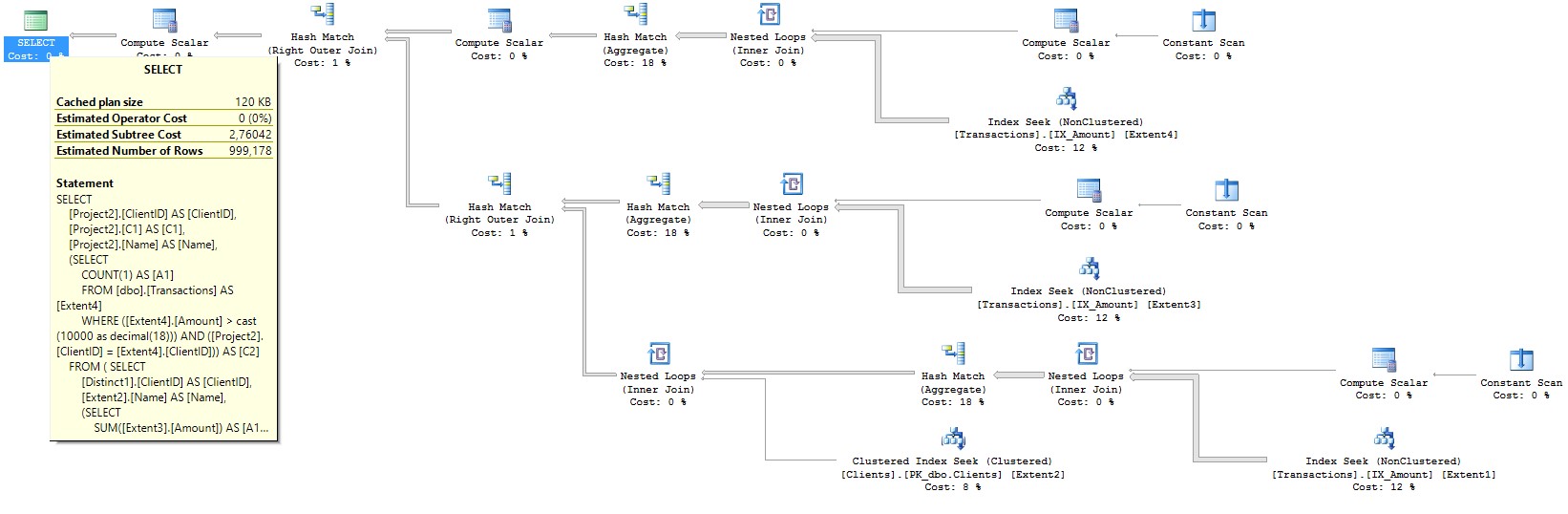
SELECT [Project2].[ClientID] AS [ClientID], [Project2].[C1] AS [C1], [Project2].[Name] AS [Name], (SELECT COUNT(1) AS [A1] FROM [dbo].[Transactions] AS [Extent4] WHERE ([Extent4].[Amount] > cast(10000 as decimal(18))) AND ([Project2].[ClientID] = [Extent4].[ClientID])) AS [C2] FROM ( SELECT [Distinct1].[ClientID] AS [ClientID], [Extent2].[Name] AS [Name], (SELECT SUM([Extent3].[Amount]) AS [A1] FROM [dbo].[Transactions] AS [Extent3] WHERE ([Extent3].[Amount] > cast(10000 as decimal(18))) AND ([Distinct1].[ClientID] = [Extent3].[ClientID])) AS [C1] FROM (SELECT DISTINCT [Extent1].[ClientID] AS [ClientID] FROM [dbo].[Transactions] AS [Extent1] WHERE [Extent1].[Amount] > cast(10000 as decimal(18)) ) AS [Distinct1] INNER JOIN [dbo].[Clients] AS [Extent2] ON [Distinct1].[ClientID] = [Extent2].[ID] ) AS [Project2]
リクエストは複雑ではないようですが、そのような「複雑でない」リクエストが大量に発生すると、かなりの負荷が発生します。 そして、それらが多数ある場合、クライアントのリストをキャッシュに保持することは論理的です。 サンプルコードは次のようになります。
var groupedTransactions= (from t in dc.Transactions where t.Amount > 10000m group t by t.ClientID into tg select new { Amount = tg.Sum(x => x.Amount), ClientID = tg.Key, ItemCount = tg.Count() }).ToList();
どのEntity Frameworkがはるかに単純なクエリになります:
SELECT [GroupBy1].[K1] AS [ClientID], [GroupBy1].[A1] AS [C1], [GroupBy1].[A2] AS [C2] FROM ( SELECT [Extent1].[ClientID] AS [K1], SUM([Extent1].[Amount]) AS [A1], COUNT(1) AS [A2] FROM [dbo].[Transactions] AS [Extent1] WHERE [Extent1].[Amount] > cast(10000 as decimal(18)) GROUP BY [Extent1].[ClientID] ) AS [GroupBy1]
その後、既にメモリにある顧客データで選択を終了します。
from tdata in groupedTransactions join client in clientCache on tdata.ClientID equals client.ID select new { Amount = tdata.Amount, ItemCount = tdata.ItemCount, ClientID = tdata.ClientID, ClientName = client.Name };
「正しい」インデックスでも:
reate index IX_Amount on Transactions (Amount) include(ClientID)
2番目のケースのリクエストプランには、推定サブツリーコストの半分が含まれています。 クエリプランの写真:
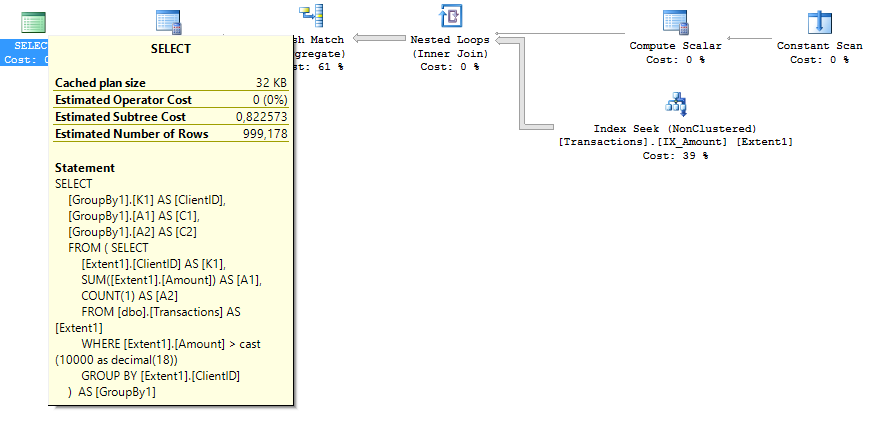
まとめ
- Azure SQLを使用する場合、非常に高い価格に陥らないように、DTUを非常に合理的に使用する必要があります。 同時に、データベースの限界生産性の変更には数時間かかる可能性があるため、生産性に余裕が必要です。
- これを行うには、必要なデータのみを要求するリクエストを慎重に作成します。 INCLUDEフィールドを持つインデックスを積極的に使用します。
- リクエストを簡素化し、アプリケーションのサーバー側で最終的なデータ接続を実行します-安価であり、より速く拡張します。
説明したアプローチにより、システム速度を10〜40倍に向上させ、Azure SQLのパフォーマンスに必要なレベルを比例的に低下させることができます。
著者について
 Pavel Kutakov-さまざまなビジネス分野のソフトウェアシステムの開発者および設計者として15年以上の経験。 プロジェクトのリストには、米国からパプアニューギニアまで世界中で運営されている銀行情報システムと、Firebird DBMSの統合開発環境が含まれています。 現在、彼は全国宝くじ事業者向けの専門的な取引サービスの開発を指揮しています。
Pavel Kutakov-さまざまなビジネス分野のソフトウェアシステムの開発者および設計者として15年以上の経験。 プロジェクトのリストには、米国からパプアニューギニアまで世界中で運営されている銀行情報システムと、Firebird DBMSの統合開発環境が含まれています。 現在、彼は全国宝くじ事業者向けの専門的な取引サービスの開発を指揮しています。
Azureを無料で試すことができます 。
広告の分 。 プロジェクトで新しいテクノロジを試してみたいが、実際に試していない場合は、Microsoft Tech Accelerationプログラムにアプリケーションを残してください。 その主な機能は、お客様と一緒に必要なスタックを選択し、パイロットの実装を支援し、成功した場合、市場全体がお客様について知るよう最大限の努力を払うことです。