当社のグローバルヒートマップは、最大かつ最も詳細であり、この種の世界最高のデータセットです。 これは、グローバルStravaアスリートネットワークの活動を直接視覚化したものです。 スケールの概念を示すために、新しいヒートマップには以下が含まれます。
- 10億のアクティビティ
- 3兆分の経度/緯度
- ラスタライズ後の13兆ピクセル
- 10テラバイトの生データ
- 総ルート距離:270億キロメートル
- 総活動時間の記録:20万年
- 陸地の5%はタイルで覆われています

モスクワのヒートマップは、Mapbox GLでパン/チルト機能を示しています
単にデータ量を増やすだけでなく、ヒートカードコードを完全に書き直しました。 これにより、レンダリングの品質が大幅に向上しました。 ハイライトされた領域では、解像度が2倍になります。 アクティビティデータは、ポイントごとではなく、ルートごとにラスタライズされます。 正規化手法も改善され、より詳細で美しい視覚化が可能になりました。
ヒートマップは、 Strava LabsおよびStrava Route Builderですでに利用可能です。 記事の残りの部分では、このアップデートのより技術的な説明に専念します。
背景
ヒートマップの更新は、2つの技術的な問題によって妨げられました。
- ヒートマップの以前のバージョンは低レベルCで記述されており、1台のマシンでのみ動作するように設計されていました。 この制限があるため、ヒートマップの更新には数か月かかります。
- ストリームデータにアクセスするには、アクティビティごとに1つのS3リクエストが必要であるため、10億のアクティビティの入力データを読み取るには数千ドルの費用がかかり、管理が困難になります。
ヒートマップ生成コードは、 Apache SparkとScalaを使用して完全に書き直されました。 新しいコードは、アクティビティフローに大量にアクセスできる新しいインフラストラクチャを活用し、開始から終了までのすべての段階で並列化をサポートします。 これらの変更の後、スケーリングのすべての問題を完全に解決しました。 完全なグローバルヒートマップは、わずか数時間で数百台のマシン上に構築され、コンピューティング操作の総コストはわずか数百ドルです。 将来、変更により、ヒートマップを定期的に更新できるようになります。
この記事の他の部分では、Sparkヒートマップタスクの各ステップがどのように機能するかを詳細に説明し、特定のレンダリングの改善点について説明します。
入力とフィルタリング
初期アクティビティデータを含む入力ストリームは、Spark / S3 / Parquetデータウェアハウスから受信されます。 このデータには、これまでStravaにアップロードされた3兆個のGPSポイントのそれぞれが含まれています。 いくつかのアルゴリズムがこのデータをクリーンアップしてフィルターします。
プラットフォームには、守らなければならない多くのプライバシー制限があります。
- プライベートアクティビティはすぐに処理から除外されます
- アクティビティエリアは、ユーザー定義のプライバシーゾーンに従ってトリミングされます
- プライバシー設定でメトロ/ヒートマップ機能を無効にしたアスリートのデータは、処理から完全に除外されます
追加のフィルターは、誤ったデータを排除します。 実行速度が妥当な速度よりも高いアクティビティは、誤って「実行」とラベル付けされた可能性が高いため、ランナーのヒートレイヤーから除外されます。 サイクリストが車や飛行機からそれらを分離するための同じ上限速度制限があります。
不動のオブジェクトに関するデータには望ましくない副作用があります。人々が住んでいる、または働いている住所を示しています。 新しいアルゴリズムは、アスリートの停止ポイントをより適切に識別します。 アクティビティフローの時間平均レートの値がいつでも小さくなりすぎると、アクティビティが初期停止ポイントから特定の半径に達するまで、このアクティビティの対応するポイントが除外されます。
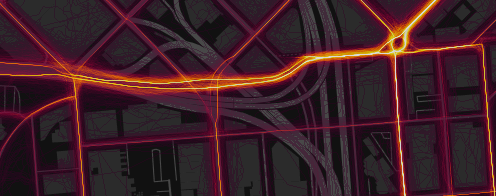
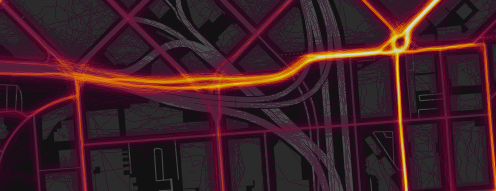
人工ノイズを追加する前(上)と後(下)のレンダリングの比較。最も近い道路の座標に従ってGPSデータを修正するデバイスからのアーティファクトを除去します。
多くのデバイス(主にiPhone)は、住宅地域のGPS信号を「修正」し、実際の座標ではなく、道路網の既知のジオメトリにリンクします。 これは、一部の道路で熱経路の幅が1ピクセルしかない場合、見苦しいアーティファクトにつながります。 これで、各アクティビティのすべてのポイントに(2メートル幅の正規分布から)ランダムバイアスを追加することでこれを修正しています。 このノイズレベルは、他のデータを目立たなくすることなくアーティファクトを抑制するのに十分です。
Zwift自転車レースなどの「仮想」アクティビティには、偽のGPSデータが含まれるため、除外します。
熱ラスタライゼーション
フィルタリング後、すべてのポイントの緯度/経度座標がズームレベル16でWebメルカトルタイルに送信されます。このレベルは、サイズがそれぞれ256×256ピクセルの2 16 ×2 16タイルの世界のモザイクです。
古いヒートマップは、各GPSポイントを正確に1ピクセルずつラスタライズしました。 アクティビティは1秒あたり1データポイントの最大速度で記録されるため、このアプローチはしばしば障害となりました。 このため、目に見えるアーティファクトは、アクティビティの少ない領域でよく発生します。書き込み速度は、ピクセル間のスペースが現れるほどです。 さらに、アスリートの動きが遅くなる領域に偏差が現れます(丘への上昇と下降を比較してください)。 追加のより詳細なズームレベルが新しいヒートマップに表示されたため(最大空間解像度が4メートルから2メートルに増加しました)、問題はさらに顕著になりました。 古いアルゴリズムの代わりに、新しいマップは、各アクティビティを連続的なGPSポイントを組み合わせた理想的なピクセルルートとして表示します。 平均して、16番目のズームレベルでの2点間のセグメント長は4ピクセルであるため、変化は非常に顕著です。
並列計算でこれを実現するには、隣接するルートポイントが異なるタイルに属している場合を処理する必要があります。 このようなポイントの各ペアは、交差する各タイルの境界にあるルートラインに沿った中間ポイントを含むように再処理されます。 このような処理の後、すべてのラインセグメントは同じタイルで開始および終了するか、長さがゼロであるためスキップできます。 したがって、データを直接製品(Tile、Array [TilePixel])として提示できます。ここで、 Array [TilePixel]は、タイル内の各アクティビティのルートを記述する連続した一連の座標です。 その後、データセットはタイルごとにグループ化されるため、各タイルの描画に必要なすべてのデータが1台のマシンにマッピングされます。
次に、タイル内の連続するピクセルの各ペアが、ブレゼンハムアルゴリズムを使用してラインセグメントとしてラスタライズされます 。 線を描くこのステップは、何兆回も実行されるため、非常に高速です。 この段階でのタイル自体は、単純にArray [Double]配列(256 * 256)であり、各ピクセルを含むセグメントの総数を表します。
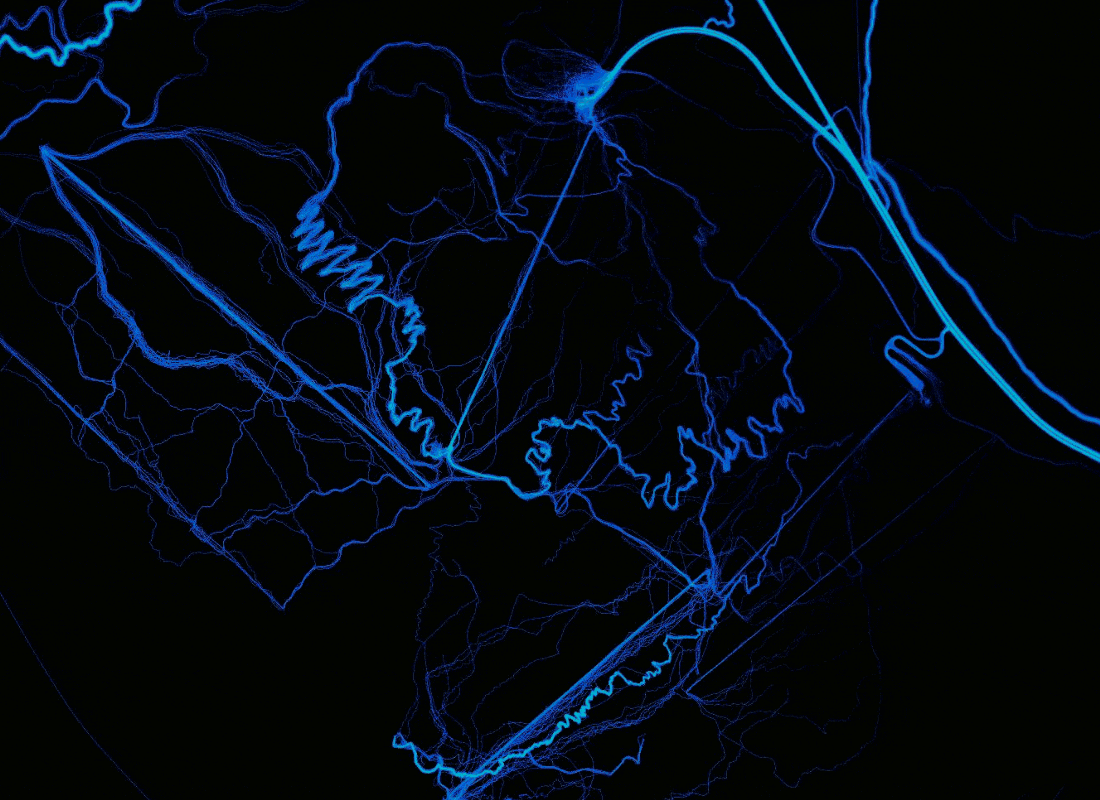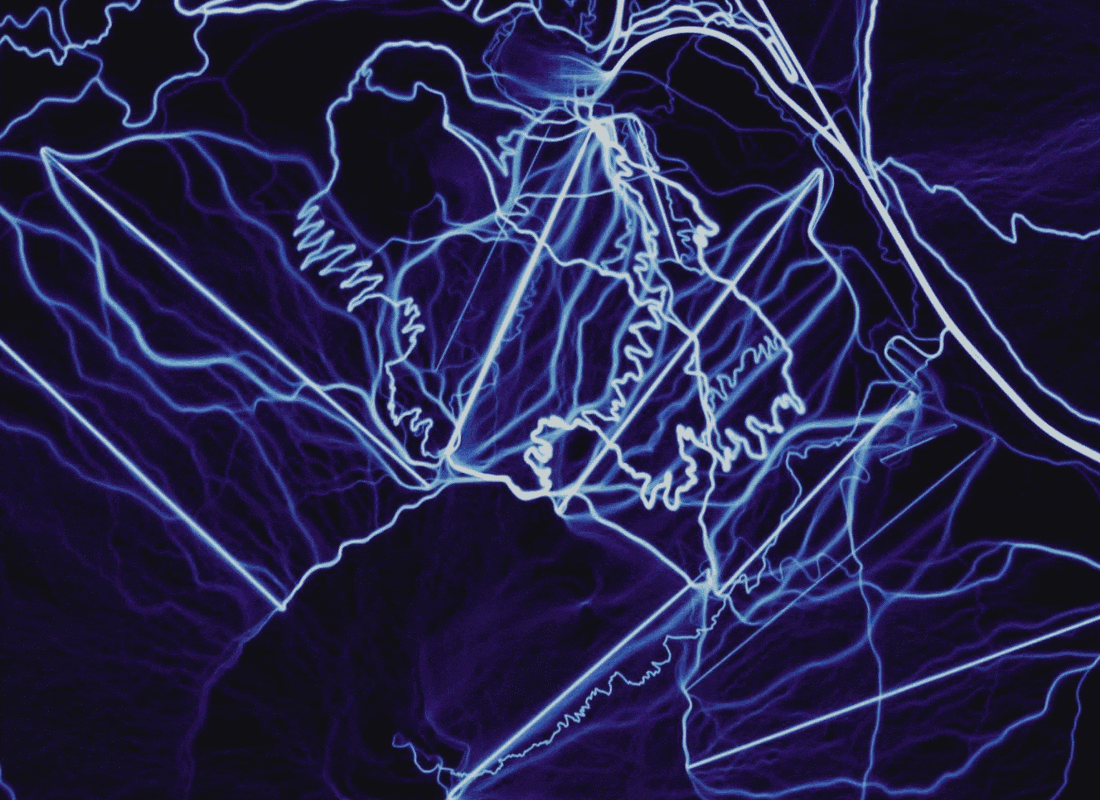
レンダリングを比較すると、ポイントに対するパスのラスタライズと追加データの追加の利点がわかります。 場所: オレゴン州バチェラー火山 。
最大のズームでは、6000万個以上のタイルを埋めます。 これは問題です。各タイルをダブル配列の形式で直接保存するには、最低でも6,000万×256×256×8バイト=〜30テラバイトのメモリが必要です。 この量のメモリは一時的なクラスターに割り当てることができますが、ほとんどのピクセル値がゼロであるため、タイルでは通常強力な圧縮が可能になるという事実を考慮すると、これはリソースの不必要な無駄になります パフォーマンス上の理由から、スパース配列は効果的なソリューションではないと判断しました。 Sparkでは、この段階で並列処理を構成すると、必要なメモリの最大量を大幅に削減できます。これは、クラスター内のアクティブなタスクの数の何倍にもなります。 完了したタスクのタイルはすぐに変換され、圧縮されてディスクに書き込まれるため、非圧縮形式では、アクティブなタスクセットに対応するタイルセットのみが保存されます。
熱正規化
正規化は、カラーマップの無制限の領域[0、Inf)と制限された領域[0、1]からのラスタライズ後の各ピクセルの初期発熱量を比較する関数です。 正規化方法の選択は、ヒートマップの外観に大きく影響します。 この関数は単調である必要があり、値が大きいほど強い「熱」に対応しますが、この問題に対処する方法はたくさんあります。 単一のグローバリゼーション機能をマップ全体に適用すると、Stravaの最も人気のあるエリアでのみ最大熱レベルの色が表示されます。
滑らかな正規化方法は、元の値のCDF(分布関数)を計算します。 したがって、このピクセルの正規化された値は、発熱量の少ないピクセルの割合になります。 この方法は最大のコントラストを提供し、各色の同じピクセル数を保証します。 写真処理では、この手法はヒストグラム調整と呼ばれます 。 訪問頻度の低いエリアでの量子化によるアーチファクトを避けるために、わずかな変更を加えて使用します。
通常、少なくとも5×5タイル(各256×256ピクセル)のサイズのマップが画面に表示されるため、実際には1タイルのみの熱の初期値のCDFを計算してもあまり良い結果にはなりません。 したがって、タイルの発熱量と半径5タイル内の隣接領域の値を使用して、タイルの合計CDFを計算します。 これにより、正規化機能は、表示用の通常の画面のサイズよりも大きくのみ拡大縮小できます。
実際のコンピューティングでは、パフォーマンスのために、おおよそのCDFが使用されます。このため、入力データは単純にソートされ、そこから一定数のサンプルが取得されます。 配列の終わりに近づくほど、より多くのサンプルを取得することで、オフセットCDFを計算する方が良いことがわかりました。 これは、ほとんどの場合、熱に関する興味深いデータがピクセルのごく一部に含まれているためです。

33%ズームでの正規化方法の比較(左:古い、右:新しい)。 新しい方法は、あらゆる範囲の熱源データの単一画像での可視性を保証します。 さらに、タイル間の正規化関数の双一次補間により、タイルの境界で目に見えるアーチファクトが防止されます。 場所: サンフランシスコ湾岸地帯 。
このアプローチの利点は、ヒートマップの色が完全に均一に分布していることです。 ある意味では、これは、ヒートマップが熱の相対値に関する最大情報を送信するという事実につながります。 また、主観的には本当に美しく見えると信じています。
このアプローチの欠点は、ヒートマップが現在、絶対的な定量値に対応していないことです。 同じ色は、ローカルレベルでのみ同じ熱レベルに対応します。 そのため、政府機関、計画、セキュリティ、および輸送部門向けに、正確な定量バージョンのヒートマップを備えたより複雑な製品Strava Metroを提供しています。
タイル境界を越えた正規化関数の補間
これまで、各タイルに正規化関数を使用しました。これは、いくつかの隣接するタイル内のピクセルのCDFです。 ただし、CDFはまだタイルの境界で急激に変化しているため、特に絶対熱の勾配が大きい領域ではいアーティファクトのように見えます。
この問題を解決するために、双線形補間を適用しました。 各ピクセルの実際の値は、4つの最も近い隣接タイルの双線形係数の合計から得られます: max(0、(1-x)(1-y))ここで、 x、yはタイルの中心からの距離です。 このような補間では、ピクセルごとに1つではなく4つのCDFを評価する必要があるため、より多くの計算リソースが必要です。
ズーム再帰
これまで、1つのズームレベルでの発熱についてのみ説明してきました。 他のレベルに移動すると、初期データは単純に加算されます-4つのタイルは、元の4分の1の解像度で1つにマージされます。 次に、正規化プロセスが再開されます。 これは、最後のズームレベル(全世界で1つのタイル)に達するまで続きます。
Sparkプロセスの新しい段階がますます少ないデータを指数関数的にキャプチャするのを見るのは非常にエキサイティングです。 最初のズームレベルの計算に約1時間を費やした後、最後のいくつかのレベルを1秒未満で計算することにより、プロセスは事実上終了しました。

ロンドン(イギリス)の1つのタイルから全世界にズームする
発行
結果として、各ピクセルの正規化された熱データは、カラーマップに値を表示し、熱値が256色の配列に含まれているため、1バイトかかります。 このデータはS3に保存され、隣接するタイルを1つのファイルにグループ化して、ホスト上のファイルの総数を減らします。 リクエスト時に、サーバーはS3から対応するメタタイルを取得してキャッシュし、その場でソースデータとリクエストされたカラーマップに基づいてPNGを生成します。 次に、CDN(Cloudfront)はすべてのタイル画像をキャッシュします。
さまざまなフロントエンドの更新も行われています。 Mapbox GLに切り替えました。 このおかげで、スムーズなズームが可能になり、奇妙な回転と傾斜を制御できるようになりました。 この更新されたヒートマップの探索をお楽しみください。