データサンプリング
データサンプルには、約850万行と29列が含まれています。
- 緯度
- 経度
- サンプリング方法-method_name
- サンプリング日時date-local

挑戦する
- 大気中のCOのレベルに影響するパラメーターを見つけます。
- 大気中のCOレベルを予測する仮説を作成します。
- いくつかの簡単な視覚化を作成します。
ライブラリをインポートする
import pandas as pd import matplotlib.pyplot as plt from sklearn import preprocessing from mpl_toolkits.basemap import Basemap import matplotlib.pyplot as plt import seaborn as sns import numpy as np from sklearn import preprocessing import warnings warnings.filterwarnings('ignore') import random as rn from sklearn.cross_validation import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.ensemble import RandomForestRegressor from sklearn.neighbors import KNeighborsClassifier from sklearn.linear_model import LogisticRegression from sklearn import svm
次に、ソースデータのギャップを確認する必要があります
各パラメーターの省略数の割合をパーセンテージで推定します。 以下の結果に基づいて、パラメーター['aqi'、 'local_site_name'、 'cbsa_name']のギャップの存在が表示されます。
(data.isnull().sum()/len(data)*100).sort_values(ascending=False)
method_code 50.011581 aqi 49.988419 local_site_name 27.232437 cbsa_name 2.442745 date_of_last_change 0.000000 date_local 0.000000 county_code 0.000000 site_num 0.000000 parameter_code 0.000000 poc 0.000000 latitude 0.000000 longitude 0.000000 ...
添付データセットの説明から、これらのパラメーターは無視できると結論付けました。 したがって、これらのパラメーターをデータセットから「削除」する必要があります。
def del_data_func(data,columns): for column_name in columns: del data[column_name] del_list = data[['method_code','aqi','local_site_name','cbsa_name','parameter_code', 'units_of_measure','parameter_name']] del_data_func (data, del_list)
ソースデータセットへの依存関係を特定する
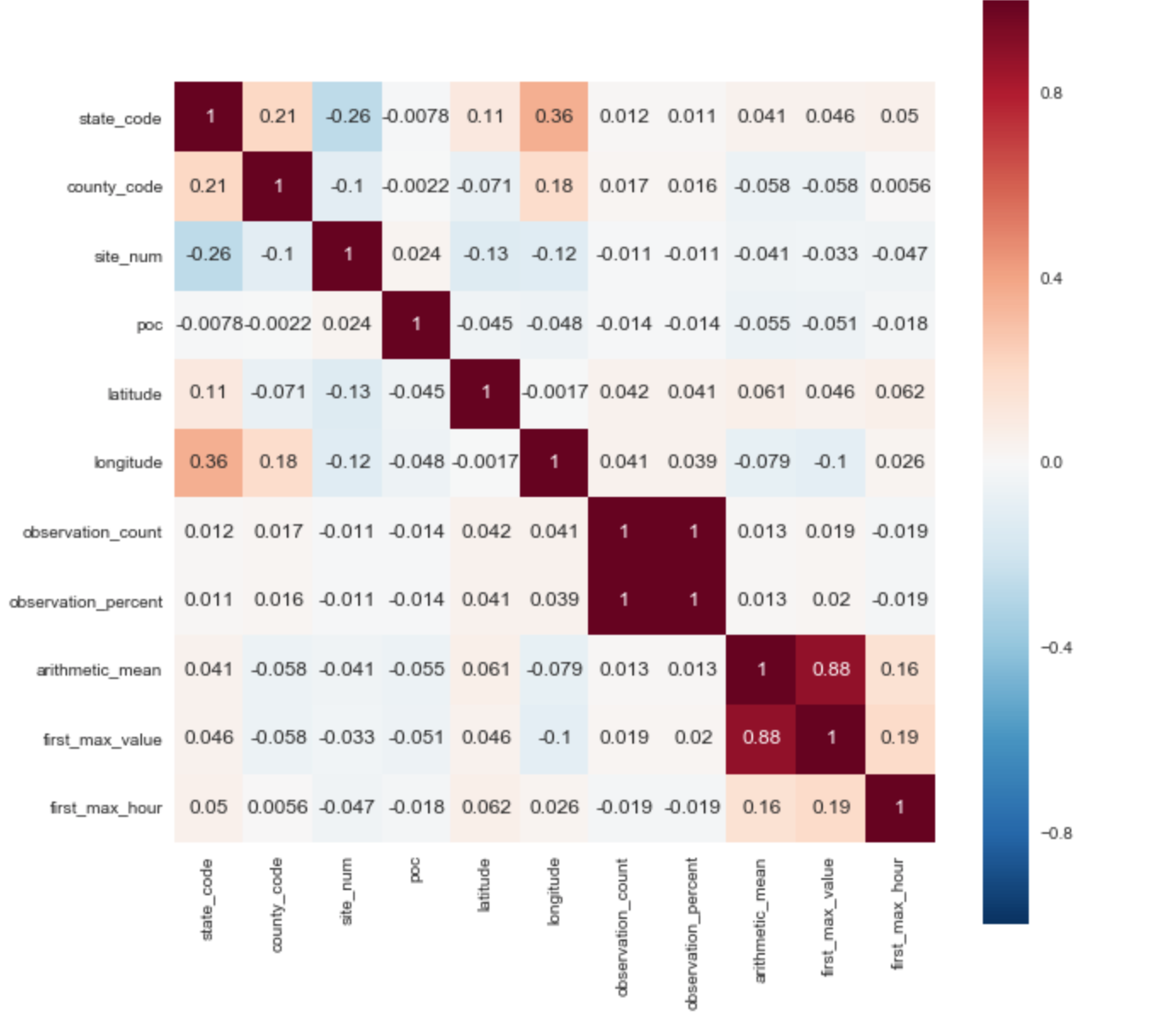
ターゲット変数として、['arithmetic_mean']パラメーターを選択しました。 相関行列に基づいて、ターゲットパラメーターとの2つの正の相関をすぐに明らかにすることができます:['arithmetic_mean']および['first_max_hour']、['first_max_hour']。
データセットの説明から、「first_max_value」はその日の最高レートであり、「first_max_hour」は最高レートが記録された時間です。
初期パラメーターの変換:
アルゴリズムが正しく機能するためには、カテゴリー記号を数値記号に変換する必要があります上記のデータでは、いくつかのパラメーターがすぐに明らかになります。
Pollutant_standard、event_type、アドレス
data['county_name'] = data['county_name'].factorize()[0] data['pollutant_standard'] = data['pollutant_standard'].factorize()[0] data['event_type'] = data['event_type'].factorize()[0] data['method_name'] = data['method_name'].factorize()[0] data['address'] = data['address'].factorize()[0] data['state_name'] = data['state_name'].factorize()[0] data['county_name'] = data['county_name'].factorize()[0] data['city_name'] = data['city_name'].factorize()[0]
機能エンジニアリング
データセットには日付と時刻があります。 新しい依存関係を特定し、
予測の精度を高めるには、季節の季節性パラメーターを導入する必要があります。
data['season'] = data['date_local'].apply(lambda x: 'winter' if (x[5:7] =='01' or x[5:7] =='02' or x[5:7] =='12') else x) data['season'] = data['season'].apply(lambda x: 'autumn' if (x[5:7] =='09' or x[5:7] =='10' or x[5:7] =='11') else x) data['season'] = data['season'].apply(lambda x: 'summer' if (x[5:7] =='06' or x[5:7] =='07' or x[5:7] =='08') else x) data['season'] = data['season'].apply(lambda x: 'spring' if (x[5:7] =='03' or x[5:7] =='04' or x[5:7] =='05') else x) data['season'].replace("winter",1,inplace= True) data['season'].replace("spring",2,inplace = True) data['season'].replace("summer",3,inplace=True) data['season'].replace("autumn",4,inplace=True) data["winter"] = data["season"].apply(lambda x: 1 if x==1 else 0) data["spring"] = data["season"].apply(lambda x: 1 if x==2 else 0) data["summer"] = data["season"].apply(lambda x: 1 if x==3 else 0) data["autumn"] = data["season"].apply(lambda x: 1 if x==4 else 0)
また、時系列の各年を個別のパラメーターとして示します。
data['date_local'] = data['date_local'].map(lambda x: str(x)[:4]) data["1990"] = data["date_local"].apply(lambda x: 1 if x=="1990" else 0) data["1991"] = data["date_local"].apply(lambda x: 1 if x=="1991" else 0) data["1992"] = data["date_local"].apply(lambda x: 1 if x=="1992" else 0) data["1993"] = data["date_local"].apply(lambda x: 1 if x=="1993" else 0) data["1994"] = data["date_local"].apply(lambda x: 1 if x=="1994" else 0) data["1995"] = data["date_local"].apply(lambda x: 1 if x=="1995" else 0) data["1996"] = data["date_local"].apply(lambda x: 1 if x=="1996" else 0) data["1997"] = data["date_local"].apply(lambda x: 1 if x=="1997" else 0) data["1998"] = data["date_local"].apply(lambda x: 1 if x=="1998" else 0) data["1999"] = data["date_local"].apply(lambda x: 1 if x=="1999" else 0) data["2000"] = data["date_local"].apply(lambda x: 1 if x=="2000" else 0) data["2001"] = data["date_local"].apply(lambda x: 1 if x=="2001" else 0) data["2002"] = data["date_local"].apply(lambda x: 1 if x=="2002" else 0) data["2003"] = data["date_local"].apply(lambda x: 1 if x=="2003" else 0) data["2004"] = data["date_local"].apply(lambda x: 1 if x=="2004" else 0) data["2005"] = data["date_local"].apply(lambda x: 1 if x=="2005" else 0) data["2006"] = data["date_local"].apply(lambda x: 1 if x=="2006" else 0) data["2007"] = data["date_local"].apply(lambda x: 1 if x=="2007" else 0) data["2008"] = data["date_local"].apply(lambda x: 1 if x=="2008" else 0) data["2009"] = data["date_local"].apply(lambda x: 1 if x=="2009" else 0) data["2010"] = data["date_local"].apply(lambda x: 1 if x=="2010" else 0) data["2011"] = data["date_local"].apply(lambda x: 1 if x=="2011" else 0) data["2012"] = data["date_local"].apply(lambda x: 1 if x=="2012" else 0) data["2013"] = data["date_local"].apply(lambda x: 1 if x=="2013" else 0) data["2014"] = data["date_local"].apply(lambda x: 1 if x=="2014" else 0) data["2015"] = data["date_local"].apply(lambda x: 1 if x=="2015" else 0) data["2016"] = data["date_local"].apply(lambda x: 1 if x=="2016" else 0) data["2017"] = data["date_local"].apply(lambda x: 1 if x=="2017" else 0)
変換後、パラメーターの数が22から114に増加したため、データセットの次元が大幅に増加しました。
以下はフラグメント(最終データセットの相関行列の1/4)です。

予測モデル:
予測仮説を構築するためのツールとして、線形回帰を選択しました。 元のデータセットでの予測の精度は、17%〜22%の範囲でした。 新しい変数を導入し、データセットを変換した後の予測の精度は次のとおりです。

データの視覚化:
測定が行われたポイントの表示と米国の地図:
m = Basemap(llcrnrlon=-119,llcrnrlat=22,urcrnrlon=-64,urcrnrlat=49, projection='lcc',lat_1=33,lat_2=45,lon_0=-95) longitudes = data["longitude"].tolist() latitudes = data["latitude"].tolist() x,y = m(longitudes,latitudes) fig = plt.figure(figsize=(12,10)) plt.title("Polution areas") m.plot(x, y, "o", markersize = 3, color = 'red') m.drawcoastlines() m.fillcontinents(color='white',lake_color='aqua') m.drawmapboundary() m.drawstates() m.drawcountries() plt.show()

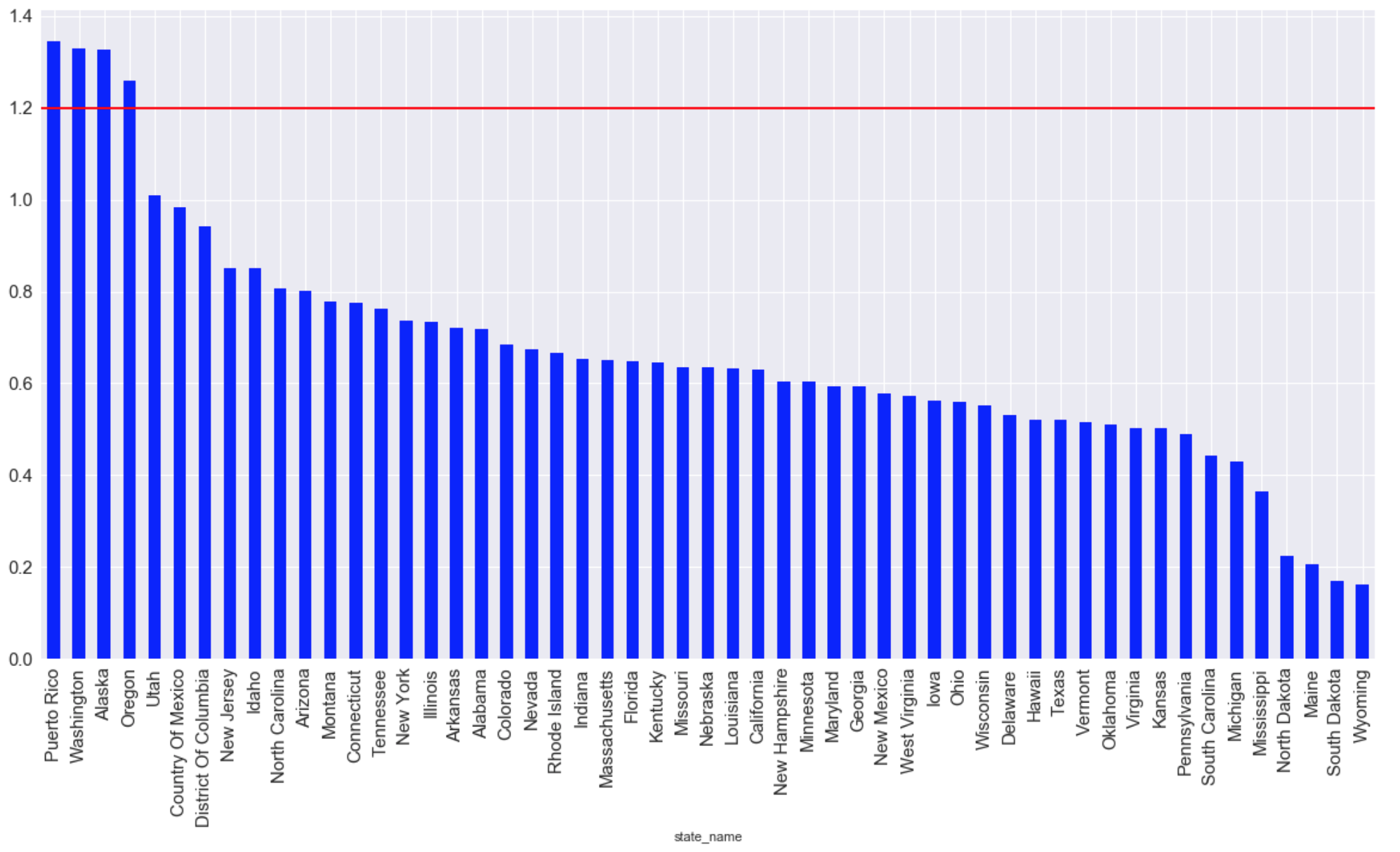
史上最高の平均CO排出量を持つ州(赤い線は最大許容生活レベルを示します):
graph = plt.figure(figsize=(20, 10)) graph = data.groupby(['state_name'])['arithmetic_mean'].mean() graph = graph.sort_values(ascending=False) graph.plot (kind="bar",color='blue', fontsize = 15) plt.grid(b=True, which='both', color='white',linestyle='-') plt.axhline(y=1.2, xmin=2, xmax=0, linewidth=2, color = 'red', label = 'cc') plt.show ();
排出レベル開発のタイムライン:
