PostgreSQLのインデックス作成メカニズムとアクセス方法のインターフェースにすでに慣れており、 ハッシュインデックス 、 Bツリー 、 GiST 、およびSP-GiSTインデックスを調べました。 この部分では、GINインデックスを扱います。
ジン
-ジン?..ジン-こんなアメリカの酒のように見える?
-私は飲み物ではありません 老人は再び顔を赤らめ、再び自分を捕まえ、再び一緒に引っ張りました。 -飲み物ではなく、強力でand然とした精神、そして私が買う余裕のないような魔法は世界にはありません。
ラザーラギン、「老人ホットタブ」。
GinはGeneralized Inverted Indexの略で、飲み物ではなく精霊と見なされるべきです。
Readme
一般的な考え方
GINはGeneralized Inverted Indexの略です。これはいわゆる逆インデックスです。 値がアトミックではなく、要素で構成されるデータ型で機能します。 同時に、値自体にインデックスが付けられるのではなく、個々の要素にインデックスが付けられます。 各要素は、それが発生する値を参照します。
この方法の良い例えは、本の最後の索引です。各用語には、この用語が記載されているページのリストがあります。 本のポインターと同様に、indexメソッドはインデックス付きアイテムのクイック検索を提供する必要があります。 これを行うために、それらはすでに馴染みのあるBツリーの形式で保存されます (別のより単純な実装が使用されますが、この場合は必須ではありません)。 各要素は、この要素の値を含むテーブル行へのリンクの順序付きセットによってバインドされます。 データサンプリングでは順序付けは重要ではありません(TIDの並べ替え順序はあまり意味がありません)が、インデックスの内部構造の観点からは重要です。
GINインデックスからアイテムが削除されることはありません。 要素を含む値は消えたり、出現したり、変化したりする可能性があると考えられていますが、要素を構成する要素のセットは非常に静的です。 このソリューションは、複数のプロセスのインデックスを使用して並列操作を提供するアルゴリズムを大幅に簡素化します。
TIDのリストが十分に小さい場合は、アイテムと同じページに配置されます(投稿リストと呼ばれます)。 ただし、リストが大きい場合は、より効率的なデータ構造が必要であり、既にわかっています-これもBツリーです。 このようなツリーは、個別のデータページに配置されます(投稿ツリーと呼ばれます)。
したがって、GINインデックスは、BツリーまたはTIDのフラットリストが添付されているリーフレコードに、要素のBツリーで構成されます。
前述のGiSTおよびSP-GiSTインデックスと同様に、GINは、複雑なデータ型に対するさまざまな操作をサポートするインターフェイスをアプリケーション開発者に提供します。
全文検索
ginメソッドの主な適用分野は全文検索の高速化です。この例では、このインデックスをより詳細に検討することが論理的です。
GiSTについては、全文検索の簡単な紹介が既にありましたので、これを繰り返して要点を説明しません。 この場合の複雑な値はドキュメントであり、これらのドキュメントの要素はトークンであることは明らかです。
GiSTに関する部分で検討したのと同じ例を取り上げます(リフレインを2回繰り返します)。
postgres=# create table ts(doc text, doc_tsv tsvector);
CREATE TABLE
postgres=# insert into ts(doc) values
(' '), (' '),
(', , '), (', , '),
(' '), (' '),
(', , '), (', , '),
(' '), (' '),
(', , '), (', , ');
INSERT 0 12
postgres=# set default_text_search_config = russian;
SET
postgres=# update ts set doc_tsv = to_tsvector(doc);
UPDATE 12
postgres=# create index on ts using gin(doc_tsv);
CREATE INDEX
このようなインデックスの可能な構造を図に示します。
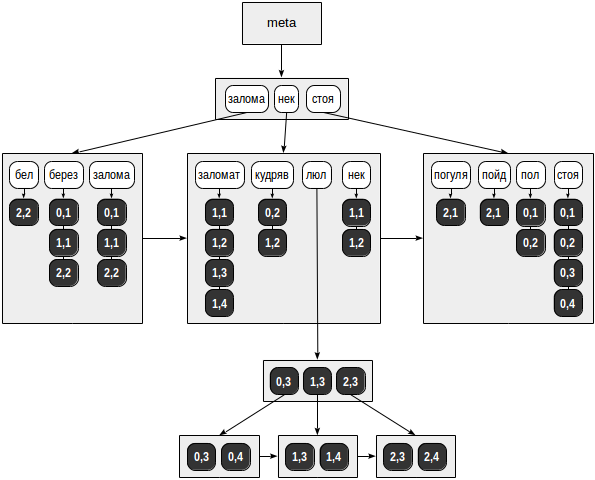
前のすべての図とは異なり、テーブル行(TID)へのリンクは矢印ではなく、暗い背景の数値(ページ番号とページ内の位置)で表示されます。
postgres=# select ctid, doc, doc_tsv from ts;
ctid | doc | doc_tsv
--------+-------------------------+--------------------------------
(0,1) | | '':3 '':2 '':4
(0,2) | | '':3 '':2 '':4
(0,3) | , , | '':1,2 '':3
(0,4) | , , | '':1,2 '':3
(1,1) | | '':2 '':3 '':1
(1,2) | | '':3 '':2 '':1
(1,3) | , , | '':3 '':1,2
(1,4) | , , | '':3 '':1,2
(2,1) | | '':3 '':2
(2,2) | | '':1 '':2 '':3
(2,3) | , , | '':3 '':1,2
(2,4) | , , | '':3 '':1,2
(12 rows)
投機的な例では、TIDのリストは、「lyul」を除くすべてのトークンの通常のページに収まります。 このトークンは最大6つのドキュメントで検出され、TIDのリストは別のBツリーに配置されました。
ところで、トークンを含むドキュメントの数をどのように理解するのですか? 以下に示すように、小さなテーブルの場合、「直接」メソッドも機能します。また、大きなテーブルの場合は後で説明します。
postgres=# select (unnest(doc_tsv)).lexeme, count(*) from ts group by 1 order by 2 desc;
lexeme | count
---------+-------
| 6
| 4
| 4
| 3
| 3
| 2
| 2
| 2
| 1
| 1
| 1
(11 rows)
また、通常のBツリーとは異なり、GINインデックスページは双方向ではなく単方向リストによってリンクされていることに注意してください。 ツリートラバーサルは常に一方向にのみ実行されるため、これで十分です。
リクエスト例
この例では、次のクエリはどのように実行されますか?
postgres=# explain(costs off)
select doc from ts where doc_tsv @@ to_tsquery(' & ');
QUERY PLAN
------------------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery(' & '::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery(' & '::text))
(4 rows)
最初に、検索クエリから独立したトークン(検索キー)が選択されます:スタンディングとカーリー。 これは、演算子クラスで定義されたデータ型と戦略を考慮する特別なAPI関数によって行われます。
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'tsvector_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
@@(tsvector,tsquery) | 1
@@@(tsvector,tsquery) | 2 @@ ( )
(2 rows)
次に、トークンのBツリーで両方のキーを見つけ、TIDの準備完了リストを反復処理します。 取得するもの:
- 「立っている」場合-(0.1)、(0.2)、(0.3)、(0.4);
- 「カール」の場合-(0.2)、(1.2)。
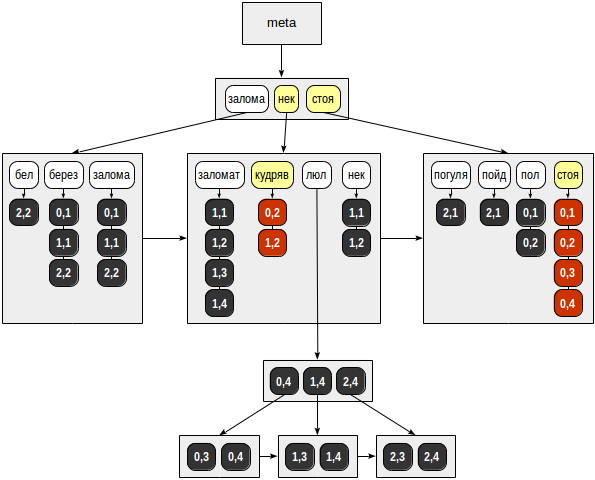
最後に、見つかったTIDごとに、一致するAPI関数が呼び出されます。これにより、検索された行のどれが検索クエリに適しているかが判断されます。 クエリトークンでは論理的な「and」で結合されているため、1行が返されます(0,2):
| | |
| | |
TID | | | &
-------+------+--------+-----------------
(0,1) | T | f | f
(0,2) | T | T | T
(0,3) | T | f | f
(0,4) | T | f | f
(1,2) | f | T | f
そして、結果が得られます。
postgres=# select doc from ts where doc_tsv @@ to_tsquery(' & ');
doc
-------------------------
(1 row)
このアプローチをGiSTに関して検討したアプローチと比較すると、全文検索に対するGINの利点は明らかです。 しかし、それほど単純ではありません。
遅い更新の問題
実際、GINインデックスでのデータの挿入または更新は比較的遅いです。 通常、各ドキュメントには、インデックス付けされるトークンが多数含まれています。 したがって、1つのドキュメントが表示または変更されると、インデックスツリーに大幅な変更を加える必要があります。
一方、複数のドキュメントが一度に変更されると、一部のトークンが一致する場合があり、ドキュメントを1つずつ変更する場合よりも総作業量が少なくなります。
GINインデックスには、インデックスの作成時に指定したり、後で変更したりできるfastupdateストレージパラメータがあります。
postgres=# create index on ts using gin(doc_tsv) with (fastupdate = true);
CREATE INDEX
このオプションを有効にすると、変更は、個別の順序付けられていないリストの形式で(個別のリンクページに)蓄積されます。 このリストが十分に大きくなるか、クリーニングプロセス中に、累積されたすべての変更がすぐにインデックスに加えられます。 「十分に大きい」リストと見なされるものは、gin_pending_list_limit構成パラメーターまたは同じ名前のインデックスストレージパラメーターによって決定されます。
しかし、このアプローチにはマイナス面もあります:まず、検索が遅くなります(ツリーに加えて、順序付けられていないリストも確認する必要があるため)。次に、順序付けられていないリストがいっぱいになると、次の変更に突然時間がかかることがあります。
部分一致検索
全文検索では、部分一致を使用できます。 リクエストは、たとえば次のように定式化されます。
gin=# select doc from ts where doc_tsv @@ to_tsquery(':*');
doc
-------------------------
, ,
, ,
, ,
, ,
(7 rows)
このようなクエリは、「ホール」で始まるトークンを含むドキュメントを検索します。 つまり、この例では、「折り目」(「break」という単語から取得)と「折り目」(「crease」という単語から)です。
もちろん、クエリはインデックスがなくても動作しますが、GINを使用するとこの検索も高速化できます。
postgres=# explain (costs off)
select doc from ts where doc_tsv @@ to_tsquery(':*');
QUERY PLAN
--------------------------------------------------------------
Bitmap Heap Scan on ts
Recheck Cond: (doc_tsv @@ to_tsquery(':*'::text))
-> Bitmap Index Scan on ts_doc_tsv_idx
Index Cond: (doc_tsv @@ to_tsquery(':*'::text))
(4 rows)
この場合、検索クエリで指定されたプレフィックスを持つすべてのトークンは、トークンツリーに配置され、論理「or」によって結合されます。
頻繁かつまれなトークン
実際のデータでインデックス作成がどのように機能するかを確認するには、GiSTスレッドで既に使用したpgsql-hackersメーリングリストアーカイブを利用します。 このアーカイブバージョンには、出発日、件名、著者、およびテキストを含む356125文字が含まれています。
fts=# alter table mail_messages add column tsv tsvector;
ALTER TABLE
fts=# set default_text_search_config = default;
SET
fts=# update mail_messages
set tsv = to_tsvector(body_plain);
NOTICE: word is too long to be indexed
DETAIL: Words longer than 2047 characters are ignored.
...
UPDATE 356125
fts=# create index on mail_messages using gin(tsv);
CREATE INDEX
多数のドキュメントで見つかったトークンを取得します。 unnestを使用したクエリは、このようなデータ量では機能しなくなります。正しい方法は、トークンに関する情報、それらが発生したドキュメントの数、およびエントリの総数を表示するts_stat関数を使用することです。
fts=# select word, ndoc
from ts_stat('select tsv from mail_messages')
order by ndoc desc limit 3;
word | ndoc
-------+--------
re | 322141
wrote | 231174
use | 176917
(3 rows)
「書き込み」を選択します。
また、開発者のメーリングリストで「タトゥー」などのまれな言葉を取り上げます。
fts=# select word, ndoc from ts_stat('select tsv from mail_messages') where word = 'tattoo';
word | ndoc
--------+------
tattoo | 2
(1 row)
これらのトークンが同時に発生するドキュメントはありますか? それは次のとおりです。
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
問題は、この要求を満たす方法です。 上記のように、両方のトークンのTIDのリストを受け取った場合、検索は明らかに非効率的です。20万を超える値を整理する必要があり、結果として1つだけが残ります。 幸いなことに、プランナーの統計を使用して、アルゴリズムは「トークン」トークンが一般的であり、「タトゥー」がまれであることを理解します。 したがって、検索はまれなトークンを使用して実行され、結果の2つのドキュメントで「書き込まれた」トークンの存在が確認されます。 ご覧のとおり、リクエストは迅速に実行されます。
fts=# \timing on
Timing is on.
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote & tattoo');
count
-------
1
(1 row)
Time: 0,959 ms
検索は単に「書いた」が、はるかに長い:
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
--------
231174
(1 row)
Time: 2875,543 ms (00:02,876)
もちろん、このような最適化は、2つのトークンだけでなく、より複雑なケースでも機能します。
サンプリング制限
ginアクセスメソッドの特徴は、結果が常にビットマップの形式で返されることです。このメソッドは、一度に1つずつTIDを発行することはできません。 そのため、この部分で発生するすべてのクエリプランでビットマップスキャンが使用されます。
そのため、LIMIT句を使用してインデックスで選択を制限することはあまり効果的ではありません。 操作の予測コスト(制限ノードの「コスト」フィールド)に注意してください。
fts=# explain (costs off)
select * from mail_messages where tsv @@ to_tsquery('wrote') limit 1;
QUERY PLAN
-----------------------------------------------------------------------------------------
Limit (cost=1283.61..1285.13 rows=1)
-> Bitmap Heap Scan on mail_messages (cost=1283.61..209975.49 rows=137207)
Recheck Cond: (tsv @@ to_tsquery('wrote'::text))
-> Bitmap Index Scan on mail_messages_tsv_idx (cost=0.00..1249.30 rows=137207)
Index Cond: (tsv @@ to_tsquery('wrote'::text))
(5 rows)
コストは1283.61と推定され、ビットマップ1249.30全体を構築するコスト(ビットマップインデックススキャンノードの「コスト」フィールド)よりわずかに高くなります。
したがって、インデックスには結果の数を制限する特別な機能があります。 しきい値は、構成パラメーターgin_fuzzy_search_limitで設定され、デフォルトではゼロになります(制限は発生しません)。 ただし、インストールすることはできます。
fts=# set gin_fuzzy_search_limit = 1000;
SET
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
5746
(1 row)
fts=# set gin_fuzzy_search_limit = 10000;
SET
fts=# select count(*) from mail_messages where tsv @@ to_tsquery('wrote');
count
-------
14726
(1 row)
ご覧のとおり、クエリは異なるパラメータ値に対して異なる行数を返します(インデックスアクセスが使用されている場合)。 制限は厳密ではありません。 指定された行より多くの行が返される可能性があるため、ファジーです。
コンパクトなパフォーマンス
とりわけ、GINインデックスはコンパクト性に優れています。 最初に、同じトークンが複数のドキュメントで見つかった場合(通常これが発生します)、インデックスに1回だけ格納されます。 第二に、TIDは規則的にインデックスに格納され、これにより単純な圧縮を使用することができます:リスト内の次の各TIDは実際には前のものとの差分として格納されます-通常、これは完全な6よりもはるかに少ないビットで済みますバイトTID。
ボリュームのアイデアを得るには、文字のテキストからBツリーを作成します。 もちろん、正直な比較は機能しません。
- GINは異なるデータ型(テキストではなくtsvector)に基づいて構築されており、より小さく、
- ただし、Bツリーの文字のサイズは約2キロバイトに短縮する必要があります。
しかし、それでも:
fts=# create index mail_messages_btree on mail_messages(substring(body_plain for 2048));
CREATE INDEX
同時に、GiSTインデックスを作成します。
fts=# create index mail_messages_gist on mail_messages using gist(tsv);
CREATE INDEX
フルクリーニング後のインデックスサイズ(バキュームフル):
fts=# select pg_size_pretty(pg_relation_size('mail_messages_tsv_idx')) as gin,
pg_size_pretty(pg_relation_size('mail_messages_gist')) as gist,
pg_size_pretty(pg_relation_size('mail_messages_btree')) as btree;
gin | gist | btree
--------+--------+--------
179 MB | 125 MB | 546 MB
(1 row)
プレゼンテーションがコンパクトであるため、Oracleからビットマップインデックスの代わりとして移行するときにGINインデックスを使用することができます(詳細には触れませんが、好奇心mind盛な人のために、ルイスポストへのリンクを残します)。 通常、ビットマップインデックスは、わずかに一意の値を持つフィールドに使用されます-これはGINに適しています。 PostgreSQLは、最初のパートで見たように、 GINを含む任意のインデックスに基づいてその場でビットマップを構築できます。
GiSTまたはGIN?
多くのデータ型には、GiSTとGINの両方の演算子クラスがあり、疑問を提起します。何を使用するのですか? おそらく、いくつかの結論を引き出すことはすでに可能です。
原則として、GINは精度と速度においてGiSTよりも優れています。 データが頻繁に変更されないが、すぐに検索する必要がある場合-ほとんどの場合、選択はGINに当てはまります。
一方、データがアクティブに変更される場合、GINを更新するオーバーヘッドが大きすぎる可能性があります。 この場合、両方のオプションを比較し、インジケーターのバランスがより良いオプションを選択する必要があります。
配列
ginメソッドを使用する別の例は、配列のインデックス付けです。 この場合、配列の要素はインデックスに分類されるため、それらの要素に対する多くの操作を高速化できます。
postgres=# select amop.amopopr::regoperator, amop.amopstrategy
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname = 'array_ops'
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
amopopr | amopstrategy
-----------------------+--------------
&&(anyarray,anyarray) | 1
@>(anyarray,anyarray) | 2
<@(anyarray,anyarray) | 3
=(anyarray,anyarray) | 4
(4 rows)
デモデータベースには、フライト情報を含むルートビューがあります。 特に、days_of_week列(フライトが行われる曜日の配列)が含まれています。 たとえば、VnukovoからGelendzhikへのフライトは火曜日、木曜日、日曜日に出発します。
demo=# select departure_airport_name, arrival_airport_name, days_of_week
from routes
where flight_no = 'PG0049';
departure_airport_name | arrival_airport_name | days_of_week
------------------------+----------------------+--------------
| | {2,4,7}
(1 row)
インデックスを作成するには、ビューをテーブルに「マテリアライズ」します。
demo=# create table routes_t as select * from routes;
SELECT 710
demo=# create index on routes_t using gin(days_of_week);
CREATE INDEX
インデックスの助けを借りて、火曜日、木曜日、日曜日に出発するすべてのフライトを見つけることができます。
demo=# explain (costs off) select * from routes_t where days_of_week = ARRAY[2,4,7];
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(4 rows)
そのうちの6つが判明しています。
demo=# select flight_no, departure_airport_name, arrival_airport_name, days_of_week from routes_t where days_of_week = ARRAY[2,4,7];
flight_no | departure_airport_name | arrival_airport_name | days_of_week
-----------+------------------------+----------------------+--------------
PG0005 | | | {2,4,7}
PG0049 | | | {2,4,7}
PG0113 | - | | {2,4,7}
PG0249 | | | {2,4,7}
PG0449 | | | {2,4,7}
PG0540 | | | {2,4,7}
(6 rows)
そのようなリクエストはどのように実行されますか? 上記とまったく同じ方法で:
- 配列{2,4,7}がその役割を果たしている検索クエリから、要素(検索キー)が強調表示されます。 明らかに、これらは「2」、「4」、「7」という値になります。
- 選択されたキーは要素ツリーに配置され、それぞれに対してTIDのリストが選択されます。
- 見つかったすべてのTIDのうち、整合性機能は、要求からオペレーターに適合するものを選択します。 演算子=の場合、3つのリストすべてにあるTIDのみが適切です(つまり、ソース配列にはすべての要素が含まれている必要があります)。 しかし、これでは十分ではありません。他の値を含まない配列も必要です。また、インデックスでこの条件を確認することはできません。 したがって、この場合、アクセス方法は、テーブルに従って発行されたすべてのTIDを二重チェックするようにインデックス作成メカニズムに要求します。
まったく何もチェックできず、テーブルから見つかったすべてのTIDを二重チェックすることを余儀なくされる戦略(たとえば、「配列に含まれる」)があることは興味深いことです。
しかし、火曜日、木曜日、日曜日にモスクワから出発するフライトを知る必要がある場合はどうでしょうか? 追加の条件はインデックスによってサポートされず、フィルター列に分類されます。
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = '';
QUERY PLAN
-----------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: (days_of_week = '{2,4,7}'::integer[])
Filter: (departure_city = ''::text)
-> Bitmap Index Scan on routes_t_days_of_week_idx
Index Cond: (days_of_week = '{2,4,7}'::integer[])
(5 rows)
この場合、これは恐ろしいことではありません(インデックスはすでに6行のみを選択しています)が、追加の条件が選択性を高める場合、そのような機会が欲しいです。 確かに、インデックスを作成するだけでは機能しません。
demo=# create index on routes_t using gin(days_of_week,departure_city);
ERROR: data type text has no default operator class for access method "gin"
HINT: You must specify an operator class for the index or define a default operator class for the data type.
ただし、通常のBツリーの動作を模倣するGIN演算子のクラスを追加するbtree_gin拡張機能が役立ちます。
demo=# create extension btree_gin;
CREATE EXTENSION
demo=# create index on routes_t using gin(days_of_week,departure_city);
CREATE INDEX
demo=# explain (costs off)
select * from routes_t where days_of_week = ARRAY[2,4,7] and departure_city = '';
QUERY PLAN
---------------------------------------------------------------------
Bitmap Heap Scan on routes_t
Recheck Cond: ((days_of_week = '{2,4,7}'::integer[]) AND
(departure_city = ''::text))
-> Bitmap Index Scan on routes_t_days_of_week_departure_city_idx
Index Cond: ((days_of_week = '{2,4,7}'::integer[]) AND
(departure_city = ''::text))
(4 rows)
ジョンブ
組み込みのGINサポートがある複雑なデータ型のもう1つの例はJSONです。 JSON値を操作するために、現在いくつかの演算子と関数が定義されていますが、その一部はインデックスを使用して高速化できます。
postgres=# select opc.opcname, amop.amopopr::regoperator, amop.amopstrategy as str
from pg_opclass opc, pg_opfamily opf, pg_am am, pg_amop amop
where opc.opcname in ('jsonb_ops','jsonb_path_ops')
and opf.oid = opc.opcfamily
and am.oid = opf.opfmethod
and amop.amopfamily = opc.opcfamily
and am.amname = 'gin'
and amop.amoplefttype = opc.opcintype;
opcname | amopopr | str
----------------+------------------+-----
jsonb_ops | ?(jsonb,text) | 9
jsonb_ops | ?|(jsonb,text[]) | 10 -
jsonb_ops | ?&(jsonb,text[]) | 11
jsonb_ops | @>(jsonb,jsonb) | 7 JSON-
jsonb_path_ops | @>(jsonb,jsonb) | 7
(5 rows)
明らかに、jsonb_opsとjsonb_path_opsの2つのクラスの演算子があります。
デフォルトでは、演算子の最初のクラスjsonb_opsが使用されます。 配列のすべてのキー、値、および要素は、元のJSONドキュメントの要素としてインデックスに分類されます。 この要素がキーであるかどうかにかかわらず、それぞれに記号が追加されます(これは、キーと値を区別する「既存の」戦略に必要です)。
たとえば、この方法でJSONとしてルートからのいくつかの行を想像してください:
demo=# create table routes_jsonb as
select to_jsonb(t) route
from (
select departure_airport_name, arrival_airport_name, days_of_week
from routes
order by flight_no limit 4
) t;
SELECT 4
demo=# select ctid, jsonb_pretty(route) from routes_jsonb;
ctid | jsonb_pretty
-------+-----------------------------------------------
(0,1) | { +
| "days_of_week": [ +
| 1 +
| ], +
| "arrival_airport_name": "", +
| "departure_airport_name": "-" +
| }
(0,2) | { +
| "days_of_week": [ +
| 2 +
| ], +
| "arrival_airport_name": "-", +
| "departure_airport_name": "" +
| }
(0,3) | { +
| "days_of_week": [ +
| 1, +
| 4 +
| ], +
| "arrival_airport_name": "", +
| "departure_airport_name": "-"+
| }
(0,4) | { +
| "days_of_week": [ +
| 2, +
| 5 +
| ], +
| "arrival_airport_name": "-", +
| "departure_airport_name": "" +
| }
(4 rows)
demo=# create index on routes_jsonb using gin(route);
CREATE INDEX
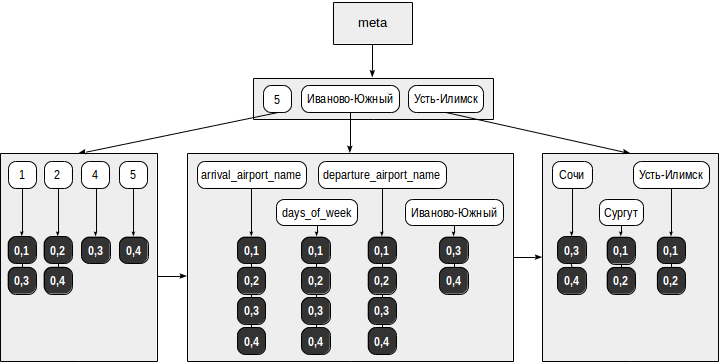
インデックスは次のようになります。
現在、たとえば、そのようなクエリはインデックスを使用して実行できます。
demo=# explain (costs off)
select jsonb_pretty(route)
from routes_jsonb
where route @> '{"days_of_week": [5]}';
QUERY PLAN
---------------------------------------------------------------
Bitmap Heap Scan on routes_jsonb
Recheck Cond: (route @> '{"days_of_week": [5]}'::jsonb)
-> Bitmap Index Scan on routes_jsonb_route_idx
Index Cond: (route @> '{"days_of_week": [5]}'::jsonb)
(4 rows)
@>
演算子は、指定されたパス(
"days_of_week": [5]
)が存在するかどうかを、JSONドキュメントのルートから確認します。 この場合、クエリは1行を返します。
demo=# select jsonb_pretty(route) from routes_jsonb where route @> '{"days_of_week": [5]}';
jsonb_pretty
----------------------------------------------
{ +
"days_of_week": [ +
2, +
5 +
], +
"arrival_airport_name": "-",+
"departure_airport_name": "" +
}
(1 row)
クエリは次のように実行されます。
- 検索クエリ(
"days_of_week": [5]
)から、要素(検索キー): "days_of_week"および "5"が選択されます。 - キーツリーには選択されたキーが含まれ、それぞれに対してTIDのリストが選択されます:「5」-(0.4)および「days_of_week」-(0,1)、(0,2)、(0,3) 、(0.4)。
- 見つかったすべてのTIDのうち、整合性機能は、要求からオペレーターに適合するものを選択します。
@>
演算子の場合、検索クエリのすべての要素を含まないドキュメントは明らかに適切ではないため、(0.4)のみが残ります。 ただし、インデックスでは、見つかった要素がJSONドキュメントで見つかった順序が明確ではないため、残りのTIDはテーブルで再確認する必要があります。
ドキュメントで他の演算子の詳細をお読みください。
JSONを操作するための通常の操作に加えて、jsquery拡張機能は長い間存在しており、より豊富な機能(そしてもちろんGINインデックスのサポート)を備えたクエリ言語を定義しています。 2016年には、独自の操作セットとSQL / JSONパスクエリ言語を定義する新しいSQL標準がリリースされました。 この標準の実装は既に完了しており、PostgreSQL 11での登場を期待しています。
内側
pageinspect拡張機能を使用して、GINインデックスの内部を確認できます 。
fts=# create extension pageinspect;
CREATE EXTENSION
メタページからの情報は、一般的な統計を示しています。
fts=# select * from gin_metapage_info(get_raw_page('mail_messages_tsv_idx',0));
-[ RECORD 1 ]----+-----------
pending_head | 4294967295
pending_tail | 4294967295
tail_free_size | 0
n_pending_pages | 0
n_pending_tuples | 0
n_total_pages | 22968
n_entry_pages | 13751
n_data_pages | 9216
n_entries | 1423598
version | 2
ページ構造は、vacuumなどの通常のプログラムに「不透明」と呼ばれる特別な領域を提供します。この領域には、アクセスメソッドが情報を保存できます。 GINのこのデータは、gin_page_opaque_info関数によって示されます。 たとえば、インデックスページの構成を見つけることができます。
fts=# select flags, count(*)
from generate_series(1,22967) as g(id), -- n_total_pages
gin_page_opaque_info(get_raw_page('mail_messages_tsv_idx',g.id))
group by flags;
flags | count
------------------------+-------
{meta} | 1
{} | 133 B-
{leaf} | 13618 B-
{data} | 1497 B- TID-
{data,leaf,compressed} | 7719 B- TID-
(5 rows)
gin_leafpage_items関数は、{data、leaf、compressed}ページに保存されているTIDに関する情報を返します。
fts=# select * from gin_leafpage_items(get_raw_page('mail_messages_tsv_idx',2672));
-[ RECORD 1 ]---------------------------------------------------------------------
first_tid | (239,44)
nbytes | 248
tids | {"(239,44)","(239,47)","(239,48)","(239,50)","(239,52)","(240,3)",...
-[ RECORD 2 ]---------------------------------------------------------------------
first_tid | (247,40)
nbytes | 248
tids | {"(247,40)","(247,41)","(247,44)","(247,45)","(247,46)","(248,2)",...
...
ここで、TIDツリーのリーフページには、実際にはテーブル行への個別のポインターではなく、小さな圧縮リストが含まれていることがわかります。
プロパティ
ginアクセスメソッドのプロパティを見てみましょう(リクエストは以前に与えられました ):
amname | name | pg_indexam_has_property
--------+---------------+-------------------------
gin | can_order | f
gin | can_unique | f
gin | can_multi_col | t
gin | can_exclude | f
興味深いことに、GINは複数列インデックスの作成をサポートしています。 この場合、通常のBツリーとは異なり、複合キーは保存されませんが、要素は分離されますが、列番号が示されるだけです。
インデックスプロパティ:
name | pg_index_has_property
---------------+-----------------------
clusterable | f
index_scan | f
bitmap_scan | t
backward_scan | f
一度に1つの結果の出力(インデックススキャン)はサポートされていないことに注意してください。ビットマップスキャン(ビットマップスキャン)のみを構築できます。
後方スキャンはサポートされていません。この機能はインデックススキャンにのみ関連し、ビットマップスキャンには関連しません。
列レベルのプロパティ:
name | pg_index_column_has_property
--------------------+------------------------------
asc | f
desc | f
nulls_first | f
nulls_last | f
orderable | f
distance_orderable | f
returnable | f
search_array | f
search_nulls | f
ここでは何も利用できません:ソート(理解可能)、インデックスをカバーとして使用(ドキュメント自体はインデックスに保存されません)、未定義の値の操作(複合型の要素には意味がありません)もありません。
その他のデータ型
一部のデータ型にGINサポートを追加するいくつかの拡張機能を次に示します。
- pg_trgmを使用すると、3文字(トライグラム)の一致シーケンスの数を比較することで、単語の「類似性」を判断できます 。 2つのクラスの演算子gist_trgm_opsとgin_trgm_opsが追加され、LIKEと正規表現を使用した比較など、さまざまな演算子がサポートされます。 この拡張機能は、スペルミスの単語を提案するために、フルテキスト検索と組み合わせて使用できます。
- hstoreはキーと値のストレージを実装します。 このデータ型には、GINを含むさまざまなアクセス方法の演算子クラスがあります。 ただし、jsonbデータ型の出現により、hstoreを使用する特別な理由はありません。
- intarrayは、整数配列の機能を拡張します。 インデックスサポートには、GiSTとGIN(演算子クラスgin__int_ops)の両方が含まれます。
また、2つの拡張機能がすでに本文で言及されています。
- btree_ginは、通常のデータ型のGINサポートを追加して、複合型とともにマルチカラムインデックスで使用します。
- jsqueryは、JSONクエリ言語とそのインデックスサポート用の演算子クラスを定義します。 この拡張機能は、標準のPostgreSQLディストリビューションの一部ではありません。
継続する 。