
インターネットリソースの監視と統計の収集に関連する多くのアプリケーションの場合、ネットワーク上のテキスト情報を見つける緊急のタスク。 これは何に役立ち、どのようにそれを行うことができますか?
興味があれば、キャットへようこそ!
鮮やかな例は、コピーライティングのタスク、借用の検索、ドキュメントリークです。 このために独自のクローラーが必要ですか、それとも検索エンジンを使用できますか? この問題を解決する過程で、「クローラー用のクローラー」、つまり特定のリクエストの検索エンジンからデータを収集するというアイデアが生まれました。
最初の合理的な質問:なぜ通常の検索エンジンAPIを使用しないのですか? 1つの検索エンジンのみを使用する場合は、APIを使用できますが、そのためには、変更を追跡してコードを編集する必要があります。 ユニバーサルメカニズムを作成することにしました。設定でXPathを置き換えると、任意の検索エンジンで動作するように調整できます(ただし、これらに限定されません)。 もちろん、プロキシリストの使用を想定する必要がありました。そのため、まず禁止されないようにし、次に、使用するプロキシのgeoIPを使用して、異なる地域の検索結果を受信できるようにしました。
アプリケーションの構造を構築する際、Dockerコンテナに基づいたマイクロサービスアーキテクチャを使用して、クロスプラットフォーム開発に向けて一歩踏み出しました。
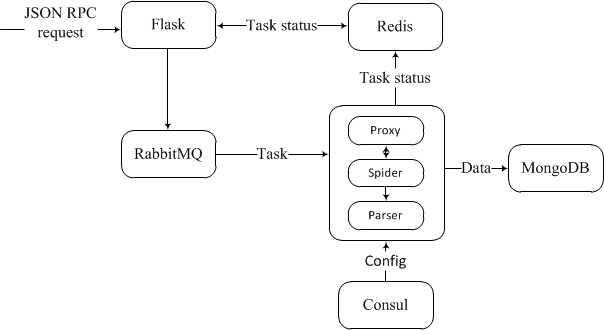
アプリケーションの作業スキームは非常に単純です。システムとの対話のインターフェイスは、次の形式のJSON-RPC形式のリクエストであることが期待されるフラスコに実装されます。
requests.post('http://127.0.0.1:5000/social', json={ "jsonrpc":"2.0", 'id':123, 'method':'initialize', 'params':{ 'settings':{ 'searcher':'< >', 'search_q':[ 'why people hate php' ], 'count':1 } } })
次に、RabbitMQキュー内のタスクが初期化されます。 実行の順番が来ると、タスク処理モジュールはそれを開発に取り込みます。 プロセスが実行されると、現在のプロキシが提供され、ブラウザエミュレータが作成されます。
なぜ私たちはその不運なエミュレーションを使用し、誰のお気に入りのリクエストも使用しないのですか? 答えは簡単です。
- 動的にロードされたコンテンツの問題を解決するため。
- プロキシブロッキングを遅らせる
ために、蛇(本物のブラウザを使用しているユーザー)になりすます
このために、 selenium webdriverが使用されます 。これにより、ユーザーがブラウザーで受信する形式でページを取得でき(すべてのスクリプトとチェックが機能します)、必要に応じて、たとえば次のデータ。
幸いなことに、ほとんどの検索エンジンでは、事前に配置されたリンクをクリックすることで次のページを取得するプロセスが発生し、GETリクエストを使用して番号を増やして実装できます。
目的のページを取得するとすぐに、問題は小さくなり、パーサーによって実行されます(必要な要素のXpathを含む設計した構成を使用)。これにより、関心のある情報がMongoDBに送信されます。
実行の各段階で、Redisはidに基づいてタスクの処理ステータスを示します。
発生する可能性のある問題を考慮してください。
- 問題の広告-ノイズの多いデータは、データベースを膨らませます。
- サイトは、たとえばページをスクロールするときなど、コンテンツを動的にロードできます。
- CAPTCHA-さて、ここではすべてが明らかです。
サイトが有用なコンテンツの広告を偽装している場合、 firefox webdriver + adblock + seleniumが役立ちます。 ただし、検索エンジンの場合、広告はXPATHを使用して非常に簡単に検出され、発行から削除されます。
したがって、キャプチャは最悪の敵です。
それを認識することは重要なタスクであり、実装にはかなりのリソースが必要です。 そのため、回避策を探します。
そして彼は私たちによって発見されました! このために、プロキシを使用します。 判明したように、パブリックドメインにあるプロキシのほとんどは、敵対者を迂回させることを許可していません(長い間酸味があり禁止されているため)、有料プロキシの状況は少し良くなりましたが、完璧ではありません王国)。
最初の考えは、ユーザーエージェントをいじることです。 ユーザーエージェントの頻繁なローテーションは、プロキシを時期尚早な終了に近づけるだけであることが実験的に判明しました(検索サービスによるプロキシのブロックをキャンセルした人はいませんでした)。 プロキシの寿命を延ばすための正しい解決策は、その使用にタイムアウトを含めることでした。リクエストには多少の遅延が生じるはずです。 もちろん、これは万能薬ではありませんが、何もないよりはましです。
アンチキャプチャサービスも使用できますが、それは別の話です...
その結果、 システムのアーキテクチャとプロトタイプを取得しました。これにより、検索およびその他のソースからデータを収集できます。
ご清聴ありがとうございました。