
レコメンダーシステムは選択に大いに役立ちますが、どこにでも、必ずしも私たちが望むように選択できるわけではありません。 多くの場合、コンテンツのセマンティクスは考慮されません。 さらに、 「 ロングテール 」の問題は、推奨事項が最も人気のある位置にのみ集中しており、興味深いが、あまり人気のないものがマスでカバーされていない場合、その全高で発生します。
興味深いテキストを検索することで、この方向で実験を開始することにしました。これはかなり小さいですが、 LiveJournalブログプラットフォームに残っている作家のコミュニティを作成するためです。 独自のレコメンデーションシステムを作成し、その結果、夕方のワインを選ぶ際にアシスタントを取得する方法について-カットの下で
LiveJournalを選ぶ理由
まあ、まず第一に、これはブログのプラットフォームであり、多くの場合興味深いものがそこに書かれています。 ユーザーのLJ上のFacebookへの移行にもかかわらず、私の推定によると、約35〜4万のアクティブなブログがまだ残っています。 ビッグデータツールを使用せずに、実験にかなり適したボリュームを作成します。 まあ、同じFacebookで作業するのとは対照的に、クロールプロセス自体は非常に簡単です。
その結果、興味深い著者からの推奨ツールを入手したかったのです。 プロジェクトに取り組む過程で、ウィッシュリストは拡大し、拡大しましたが、すべてがすぐにカバーされるわけではありませんでした。 可能だったことと将来の計画については、この記事で説明します。
クロール
すでに述べたように、LJプラットフォームでのブログのクロールは非常に簡単です-投稿のテキスト、写真(必要な場合)、さらには投稿のコメントを構造とともに簡単に取得できます。 このプラットフォームで何人かの著者を保持しているのは、Habréのような階層的なコメントシステムであると言わなければなりません。
したがって、シンプルなPerlクローラーは、コードを数週間のゆったりとした作業のためにgithubで取得でき、2017年夏と2016年夏の期間に約4万のブログからテキストとコメントをアップロードしました。年ごとのLJの活動の並行比較。
なぜperl
私はこの言語が好きなので、私はそれに取り組んでおり、予測できないフローと結果を持つタスクに非常に適していると感じています-最大のパフォーマンスを必要としないが最大の柔軟性が必要な場合の実験的な情報検索とデータマイニングに必要なものだけです。 もちろん、データ処理の場合、Pythonを多数のライブラリとともに使用することをお勧めします。
そのため、調査の初期データは次のようになりました。
-分析期間:6か月
-著者:約45,000
-出版物:約250万
-単語:約7億4,000万
分析モデルと処理

私はデータサイエンティストではないので( 時折kaggleで競技を見ていますが)、アルゴリズムは非常に単純に選択されています-著者の近接性を、テキストを特徴付けるベクトル間の余弦距離と考えてください。
著者のテキストの特性を持つベクトルを構築するためのいくつかのアプローチがありました:
1.明らか-アセンブルされたテキストコーパスに従って、 TF-IDFメトリックでベクトルを構築します。 欠点は、ベクトル空間が非常に多次元(約6万)で、非常にまばらであることです。
2.トリッキーなのは 、 word2vecを使用してテキスト本文をクラスター化し、結果のクラスター上のテキストの投影としてベクトルを取得することです。 利点は、クラスター数の点で比較的短いベクトルです(通常〜1000)。 欠点は、word2vecをトレーニングし、クラスター化するクラスターの数を選択し、クラスターにテキストを投影する方法を考える必要があることです。混乱します。
3.また、悪くない-gensim doc2vecでベクターを構築する。 2番目のオプションとほぼ同じですが、側面図とトレーニングを除くすべての問題はすでに解決されています。 しかし、Pythonで。 そして、私はそれを望みませんでした。
その結果、最初のモデルは、結果のマトリックス「ドキュメント」-「ターム」のSVD分解の形式でLSA(潜在意味解析)メソッドによって補完されて選択されました。 この方法はHabréで何度も説明されましたが、私はやめません。
用語を整理するため、またはロシア語の単語を基本形にするために、Yandex mystemユーティリティとその周りのラッパーを使用しました。これにより、複数のドキュメントを1つのファイルに結合してユーティリティ入力に渡すことができます。 以前に行ったすべてのドキュメントで呼び出すことができますが、あまり効果的ではありません。 3文字より長く、 コーパス全体で使用頻度が100を超える名詞、形容詞、動詞、副詞がコーパスに選択されました。
ここで、たとえば、上位名詞は基本形式に縮小されます。
1.男
2.時間
3.ロシア
4.日
5.国
SVD分解は外部ユーティリティSVDLIBCを使用して行われました 。これは、int型の最大値より大きい要素数で「密な行列」を作成しようとするとクラッシュするため、非常に大きな行列を使用するためにパッチを適用する必要がありました。 しかし、このユーティリティは、スパース行列で機能し、必要な数の特異ベクトルのみを計算できるため、時間を大幅に節約できるという点で優れています。 ところで、Perlには、このユーティリティのコードに基づいたPDL :: SVDLIBCモジュールがあります。
ベクトルの長さ(展開中の特異ベクトルの数)の選択は、雑誌のテストセットで「エキスパート分析」(目で読む)によって行われました。 その結果、彼はn = 500で停止しました。
分析の結果は、著者の類似度係数のマトリックスです。
結果の可視化
初期段階では、次に何をすべきかを理解するために、テーマコミュニティの構造を自分の目で評価したかったのです。
SVD後の500値のベクトルの入力に適用することにより、分析パッケージDeductorから自己組織化マップ(SOM)の形式でクラスタリングと視覚化を使用しようとしました。 結果は長らく待ち構えていましたが(マルチスレッド?いいえ、聞いていません)、満足できませんでした-マップフィールド全体に3つの大きなクラスターとかなり密集した著者の配置がありました。
特定のしきい値より大きい近接係数を持つエッジを保存することにより、距離行列をグラフに変換できることが明らかでした。 マトリックスコンバーターをGDF形式のグラフに書き込んで(さまざまなパラメーターを視覚化するのに最も適しているように思えた)、このグラフをGephiグラフ視覚化パッケージに供給し、さまざまなレイアウトと表示パラメーターを実験して、次の図を取得しました:

写真をクリックすると、3000x3000の解像度で瞑想できます。 また、LJブログに時々アクセスすると、おなじみの名前が見つかるかもしれません。
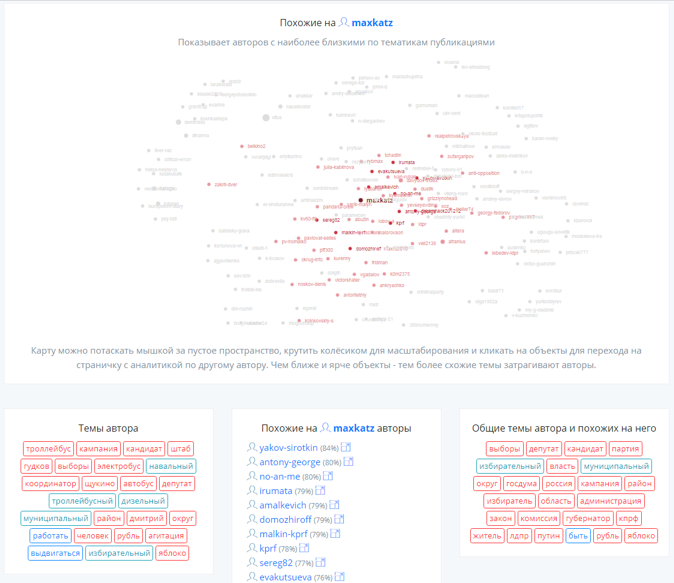
この図は、著者のテーマ構造に関する私の考えと非常に一致していますが、理想的ではありません(密度が高すぎます)。 少し残っています-自分や他の人に個人的な著者の好みに基づいて推奨事項を受け取る機会を与えるために: 著者の名前を設定し、彼に似た推奨事項を受け取りました。
この目的のために、関心のある著者に隣接するグラフ領域の小さな視覚化が、 force layoutを使用してd3jsで記述されました。 各著者(および、既に述べたように4万人以上)に対して、jsonファイルは、グラフの近くのノードの説明、この著者の人気のある単語のソートされたリストに基づく「タグ注釈」 、および近くを含む彼のグループの同様の注釈で生成されましたノード。 注釈は、著者が書いていることや、類似のブロガーに関連するトピックについての洞察を与える必要があります。
結果は、推奨事項とグラフィックカードを備えた、 similarity.meミニ検索エンジンでした。
何を改善できますか?
- 妥当性 -データ収集プロセスが進行中であるため、投稿の対象範囲が拡大し、マップ上の著者の意味的近接性がより適切になるはずです。 さらに、著者の事前選択を追加する予定です-「半死」、恋人の再投稿、自動パブリッシャーを除外する-これにより、ごみからグラフを少し細くすることができます。
- 精度 -ニューラルネットワークを使用してドキュメントベクトルを形成し、コサイン以外の異なる距離で実験するというアイデアがあります。
- 視覚化 -六角形の投影とすべて同じ自己組織化マップを使用して、著者間の関係の構造に主題構造を課そうとします。 さて、マップ全体のより明確なクラスタリングを実現するために。
- 注釈 -コロケーションで注釈アルゴリズムを試してください。
ビニールはどうですか?
タイトルの写真は味の特徴に応じたワインリストです ))
この研究の副産物は、「このアプローチを使用して製品の説明に従って製品を推奨するのではなく」という考えでした。 このために、デイリーワインテレグラフデイリーのブログで、ワイン評論家のデニスルデンコによるテイスティングノートは完璧でした。 残念なことに、彼はずっと前に彼らの出版物を放棄しましたが、そこに蓄積されたワインの2000以上の記述はそのような実験のための優れた資料です。
特別なテキストの前処理は行われませんでした。 彼らのシステムを食べさせて、私は同様の推薦で700の最高のワインの味のリストを得ました :

最も人気のあるブドウ品種のワインを、その主観的な(テイスターの観点から)味に応じて強調することができます。
いくつかの形容詞を名詞に変換することにより、推奨事項を少し最適化する計画があります。たとえば、「blueberry」-「blueberry」です。 そして、2,000以上の味のあるワインすべてを地図上に配置します。
どういうわけか、これらのアプローチを他の領域に拡張することで、選択の問題に対処することができます(突然問題になった場合)。