CppCon 2017カンファレンスの一連のレビュー記事の続き。
- BjörnStraustrup:モダンC ++の学習と指導
- Lars Knoll:C ++ Qtフレームワーク:歴史、現在、未来
- Herb Sutter:C ++でのメタプログラミングとコード生成
- マット・ゴッドボルト:私のコンパイラーは私のために何をしましたか?
今回は、Compiler Explorer( godbolt.org )の著者による非常に興味深いプレゼンテーションです。 速度のために、シフト(少なくともx86-64)で2を掛けるすべての人に必ず読んでください。 x86-64アセンブラに精通している場合は、例(「乗算」、「除算」など)を含むセクションに巻き戻すことができます。 著者のさらなる言葉。 私のコメントは斜体の角括弧で囲まれています。
私の目標は、アセンブラーを恐れないことです。これは便利なことです。 そしてそれを使用しました。 必ずしも常にではありません。 そして、私はあなたがすべてをやめてアセンブラーを学ぶべきだと言っているのではありません。 ただし、コンパイラの結果を表示できるはずです。 そして、これを行うと、コンパイラーがどれだけの作業を行い、どれほどスマートであるかがわかります。
背景
したがって、要約する古典的な方法があります(C ++ 11より前):
int sum(const vector<int> &v) { int result = 0; for (size_t i = 0; i < v.size(); ++i) result += v[i]; return result; }
Range-For-Loopの出現により、より快適なコードに置き換えることができるかどうか疑問に思いました。
int sum(const vector<int> &v) { int result = 0; for (int x : v) result += x; return result; }
私たちの恐怖は、他の言語のイテレータにすでに噛まれていたという事実に関連していました。 イテレータが構築されたコンテナを反復処理した経験があり、ガベージコレクタに作業が追加されました。 これはC ++には当てはまらないことがわかっていましたが、確認する必要がありました。
警告
アセンブリコードの読み取り:ここで何が起こっているかを見ることができ、指示が少ないためにそれよりも速く動作すると考えると、簡単にだまされる可能性があります。 現代のプロセッサでは、非常に複雑なことが起こり、予測できません。 パフォーマンスを予測する場合は、常にベンチマークを実行してください。 たとえば、Googleまたはオンラインオンラインhttp://quick-bench.comから 。
X86-64アセンブラーの基本
登録
- 16整数64ビット汎用レジスター(RAX、RBX、RCX、RDX、RBP、RSI、RDI、RSP、R8-R15)
- 8つの80ビット浮動小数点レジスター(ST0-ST7)
- 16個の128ビットSSEレジスタ(XMM0-XMM15)
ABI関数を呼び出すための規則があります 。これは、特に、関数が相互に「通信」する方法です。
- rdi、rsi、rdx-引数
- rax-戻り値
また、どのレジスタを上書きできるか、どのレジスタを保持するかというルールもあります。 ただし、アセンブラーで記述しない場合は、それらを知る必要はありません。
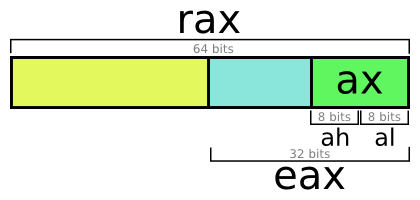
汎用レジスタは64ビットですが、名前は異なります。 たとえば、eaxレジスタを参照すると、raxレジスタの下位32ビットが取得されます。 ただし、複雑な理由により、eaxに書き込むとraxの上位32ビットがリセットされます(理由) 。 これは、,、ああ、アルには適用されません。
運営
Intel構文を使用しています 。 部屋でIntel構文を使用するのは誰ですか? AT&Tはどうですか? ああ、今日は自分のために敵を作ったようです。
操作の種類(Intel構文):
op op dest op dest, src op dest, src1 src2
ニーモニックコード(op)の例:call、ret、add、sub、cmp。 オペランド(dest、src)は、次の形式のレジスタまたはメモリ参照です。
[base + reg1 + reg2 * (1, 2, 4 or 8)]
メモリ参照が絶対値になることはめったにありません。 レジスタの値を使用するだけでなく、別のレジスタの値で指定されたオフセットを追加することもできます。
例を考えてみましょう:
mov eax, DWORD PTR [r14] add rax, rdi add eax, DWORD PTR [r14+4] sub eax, DWORD PTR [r14+4*rbx] lea rax, [r14+4*rbx] xor edx, edx
彼の擬似コード:
int eax = *r14; // int *r14; rax += rdi; eax += r14[1]; eax -= r14[rbx]; int *rax = &r14[rbx]; edx = 0;
行を分析しましょう:
- r14レジスタから4バイトを読み取り、eaxに配置します。
- RDI値をraxに追加します。
- r14 + 4に保存された4バイトの値をeaxに追加します。 このようなメモリアクセスは、r14が4バイト数の配列の先頭へのポインタである場合、最初の(ゼロからカウントする)配列値を取得することに似ています。
- 前のものと似ていますが、配列のインデックスを変更できます。
- leaコマンドは、実効アドレスをロードするために使用されます。 [
mov rax, r14+4*rbx
ようなもの、それが書かれていれば 。] - ここにリセットするような奇妙な方法があります。 実際、
mov edx, 0
は4バイト、xor edx, edx
は2バイトを使用します。
コンパイラエクスプローラーv0.1
まず、コンパイラーの動作を調べるために、次のことを行いました。 コマンドによってコンパイルされます:
$ g++ /tmp/test.cc -O2 -c -S -o - -masm=intel \ | c++filt \ | grep -vE '\s+\.'
説明
-
g++
実行:
- コンパイルtest.cc
- 最適化を有効にした場合(-O2)
- リンカーを呼び出さずに(-c)
- アセンブリー・リスト生成(-S)
- 標準ストリームへの出力(-o-)
- Intel表記を使用(-masm = intel)
-
c++filt
filt-名前デコードユーティリティ(デマングル)。 -
grep -vE '\s+\.'
-すべての面白い行を削除します。
監視ユーティリティを使用して一定の間隔でこのコマンドを実行し、 -d
(diff)フラグを設定して差分を表示しました。 次に、 tmuxを使用して端末を半分に分割し、一方にスクリプトを配置し、他方にviを配置しました。 そして、私はコンパイラエクスプローラを手に入れました。
コンパイラエクスプローラー
Compiler Explorerの最新バージョンについて簡単に説明します。 コードで新しいウィンドウを作成するには、「エディター」をクリックして、必要な場所にドラッグしてドラッグする必要があります。 コンパイル結果を含むウィンドウを作成するには、上矢印のボタンをクリックして押したままドラッグします。 黄色の線にカーソルを合わせると、アセンブラー部分の対応する線が太くなります。
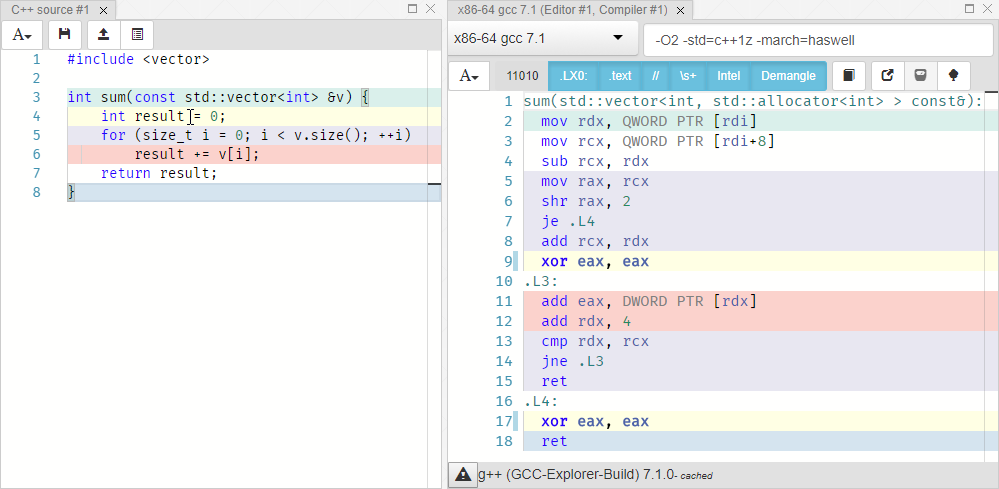
引数-O2 -std=c++1z -march=haswell
してGCC 7.1を選択し-O2 -std=c++1z -march=haswell
。 int result = 0;
xor eax eax
対応します。 rdxレジスタには、ベクターの現在の要素へのポインターが含まれています。 累積result += x;
rdxのアドレスにある値だけeax
レジスタの値を増やし、その後の配列の次の要素への移行として実装されます。 文字列をreturn result;
ハイライトされていません。つまり、明示的に一致するものはありません。 これは、ループが終了した後、eaxレジスタ(戻り値を格納するためによく使用される)に既に値が含まれているためです。 最適化により、コンパイラーは私たちが要求したとおりになりました。
次に、最適化なしでコンパイル結果を表示します(-O0)。
-O1
でコンパイルする場合、GCCは何らかの理由でmov eax, 0
代わりにxor eax, eax
を使用する必要があるとは考えません。
-O3
変更し-O3
。 これは驚くべきことです。見てみましょう:

クソ、これらすべてのクールな操作が使用されています! ただし、このようなコードが単純なバージョンよりも高速であることを確認するには、ベンチマークを使用する必要があります。
例に戻りましょう。
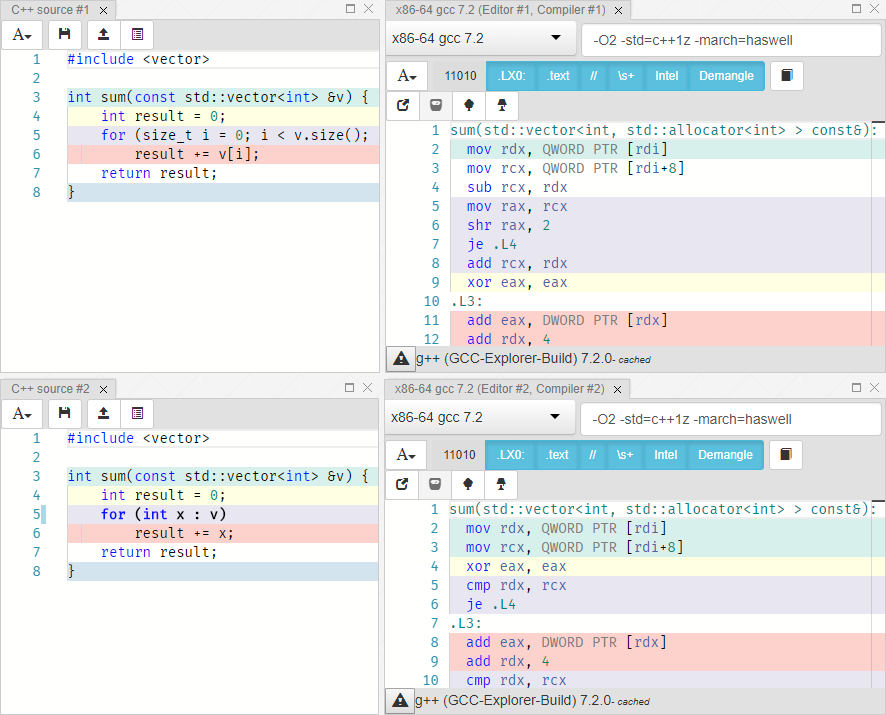
比較(diff) :
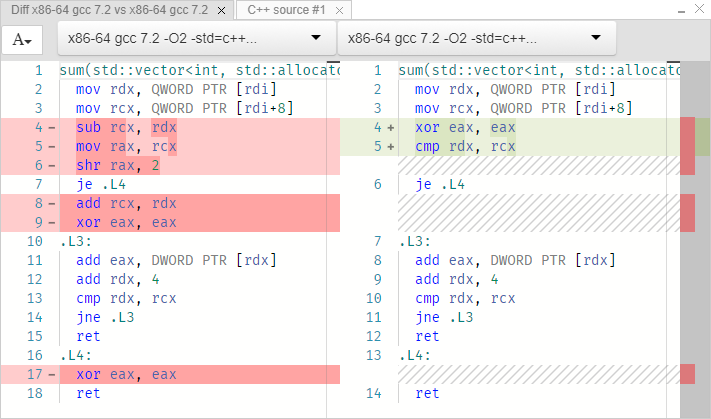
左側には0からサイズまでのサイクルがあり、右側には範囲があります。 ループを実装するコードは、どちらの場合も同じです。 この方法を試してみましょう:
int sum(const vector<int> &v) { return std::accumulate(std::begin(v), std::end(v), 0); }
同じこと。
詳細分析
最初の2行から始めましょう。
; rdi = const vector<int> * mov rdx, QWORD PTR [rdi] ; rdx = *rdi ≡ begin() mov rcx, QWORD PTR [rdi+8] ; rcx = *(rdi+8) ≡ end()
参照によりベクトルを渡しました。 しかし、リンクのようなものはありません。 ポインターのみ。 rdiレジスタは、送信されたベクトルを示します。 値はアドレスrdiおよびrdi + 8で読み取られます。rdiがint配列への直接のポインターであると考えるのは誤りです。 これは、ベクターへのポインターです。 少なくともGCCでは、ベクターの実装は次のとおりです。
template<typename T> struct _Vector_impl { T *_M_start; T *_M_finish; T *_M_end_of_storage; };
つまり、ベクトルは3つのポインターを含む構造です。 最初のポインターは配列の始まり、2番目は終わり、3番目はこのベクトルの予約済みメモリー(割り当て済み)の終わりです。 配列のサイズはここに明示的に保存されません。 これは面白いです。 サイクルの開始前に実装の違いを見てみましょう。 最初の例(インデックス付きの通常のループ):
sub rcx, rdx ; rcx = end-begin mov rax, rcx shr rax, 2 ; (end-begin)/4 je .L4 add rcx, rdx xor eax, eax
最初の行は、配列のバイト数を計算します。 3番目では、この値を4で割って要素の数を見つけます(intは4バイトであるため)。 つまり、単なるサイズ関数です。
size_t size() const noexcept { return _M_finish - _M_start; }
シフト操作後にサイズ0を取得した場合、Equal Flagが設定され、移行操作je
(Jump If Equal)がトリガーされ、プログラムは0を返します。したがって、サイズがゼロかどうかをチェックしました。 さらに、反復中に、サイズを指定したインデックスチェックが実行されると想定しています。 しかし、コンパイラは実際にこのインデックスを必要としないと推測し、ループ内で配列要素への現在のポインタと配列の最後(rcx)を比較します。
次に、2番目の例(範囲付き):
xor eax, eax cmp rdx, rcx ; begin==end? je .L4
開始ポインタが終了と等しいかどうかを単純に比較し、等しい場合はプログラムの最後にジャンプします。 実際、これは起こりました:
auto __begin = begin(v); auto __end = end(v); for (auto __it = __begin; __it != __end; ++it)
サイクル自体は両方の場合で同一です:
; rcx ≡ end, rdx = begin, eax = 0 .L3: add eax, DWORD PTR [rdx] ; eax += *rdx add rdx, 4 ; rdx += sizeof(int) cmp rdx, rcx ; is rdx == end? jne .L3 ; if not, loop ret ; we're done
私たちは見つけました:
- Range-forの方が若干優先されるオプションであることが判明しました。
- コンパイラオプションは重要です。
- std :: collectは同じ結果を示します。
乗算
次に、小さいながらもクールな例を示します。
int mulByY(int x, int y) { return x * y; }
mulByY(int, int): mov eax, edi imul eax, esi ret
ediは最初のパラメーター、esiは2番目のパラメーターです。 imulを使用した通常の乗算。 これは、4ビットの手動乗算のようです。
1101 (13) x 0101 (5) -------- 1101 0000 1101 + 0000 -------- 01000001 (65)
4つの追加を完了する必要がありました。 Haswellでは、32ビットの乗算がわずか4クロックサイクルで実行されるのは奇跡です。 1ティックの追加。 しかし、さらに高速な例を見てみましょう。
int mulByConstant(int x) { return x * 2; }
1の左シフトが発生することが予想されます。
lea eax, [rdi+rdi]
1つの操作。 leaの利点は、ソースを非常に柔軟に設定できることです。 シフトを使用して実装するには、値をeaxにコピーしてシフトするという2つの操作を行う必要があります。
int mulByConstant(int x) { return x * 4; }
lea eax, [0+rdi*4]
leaは、2、4、8による乗算をサポートします。したがって、8による乗算は同様になります。
lea eax, [0+rdi*8]
すでにシフトしている16歳までに:
mov eax, edi sal eax, 4
65599で:
imul eax, edi, 65599
ええ、これらのコンパイラ開発者は思っているほど賢くありません。 より効率的に実装できます:
int mulBy65599(int a) { return (a << 16) + (a << 6) - a; // ^ ^ // a * 65536 | // a * 64 // 65536a + 64a - 1a = 65599a }
私たちはチェックします:
imul eax, edi, 65599
ああ! [ 笑い、拍手 ]。 それは何ですか、コンパイラは私よりも賢いですか? はい、確かに、乗算はこれらの少数のシフトおよび加算よりも効果的です。 しかし、これは最新のプロセッサ上にあります。 時間を遡ってみましょう-O2 -std=c++1z -march=i486 -m32
:
mov edx, DWORD PTR [esp+4] mov eax, edx sal eax, 16 mov ecx, edx sal ecx, 6 add eax, ecx sub eax, edx
さて、 return a * 65599;
ましょうreturn a * 65599;
:
mov edx, DWORD PTR [esp+4] mov eax, edx sal eax, 16 mov ecx, edx sal ecx, 6 add eax, ecx sub eax, edx
コンパイラーにこれらすべての同様のことをさせてください。
部門
一般的な場合:
int divByY(int x, int y) { return x / y; }
divByY(int, int): mov eax, edi cdq idiv esi ret
Haswellでは、32ビット除算は22〜29サイクルで実行されます。 もっと良くできますか?
unsigned divByConstant(unsigned x) { return x / 2; }
mov eax, edi shr eax
魔法ではなく、右へのシフトです。 また、4、8、16などで割っても驚くことではありません。3を試してみましょう。
mov eax, edi mov edx, -1431655765 mul edx mov eax, edx shr eax
どうした
mov eax, edi ; eax = x mov edx, 0xaaaaaaab mul edx ; eax:edx = x * 0xaaaaaaab mov eax, edx ; (x * 0xaaaaaaab) >> 32 ; ≡ (x * 0xaaaaaaab) / 0x10000000 ; ≡ x * 0.6666666667 shr eax ; x * 0.333333333 ret
2/3 * xに等しい値は、edx-64ビット乗算結果の上位32ビットであることが判明しました。 つまり、実際には、2/3の乗算と右への1のシフトがありました。 [ はっきりしていない場合は、16進数の計算機0xaaaaaaabで3、4、5、6を掛けて、上位桁を確認してください]。
除算の残り
一般的な場合:
int modByY(int x, int y) { return x % y; }
modByY(int, int): mov eax, edi cdq idiv esi mov eax, edx ret
特に、3で割った残りの部分:
int modBy3(unsigned x) { return x % 3; }
mov eax, edi mov edx, 0xaaaaaaab mul edx mov eax, edx shr eax lea eax, [rax+rax*2] sub edi, eax mov eax, edi
最初の5行は、すでに検討されている部門です。 以下では、除算結果に3を掛けて、元の値から減算します。 つまり、x-3 * [x / 3]。 モジュロ除算に注意を払うのはなぜですか? ハッシュマップで使用されているため-すべての人に愛されているコンテナ。 オブジェクトを検索またはコンテナに追加するために、ハッシュをハッシュテーブルのサイズで割った余りが計算されます。 この残りは、テーブル要素(バケット)のインデックスです。 この操作ができるだけ早く機能することが非常に重要です。 一般的に、それはかなり長い間機能します。 したがって、libc ++は有効なテーブルサイズに2のべき乗を使用します。 しかし、これらはあまり良い値ではありません。 Boost multi_indexの実装には、多くの有効なサイズとそれらをリストするスイッチが含まれています。
[ 聴衆からの質問から判断すると、誰もがこの説明を理解したわけではありません。 大まかに言うと、そのような実装は次のとおりです。 ]
switch(size_index): { case 0: return x % 53; case 1: return x % 97; case 2: return x % 193; ... }
ビット数
次の関数は、単一ビットをカウントします。
int countSetBits(int a) { int count = 0; while (a) { count++; a &= (a-1); } return count; }
各反復で、最も若いユニットの番号は、整数がゼロになるまで消えます。 GCCは巧妙に行いました:
countSetBits(int): xor eax, eax test edi, edi je .L4 .L3: add eax, 1 blsr edi, edi test edi, edi jne .L3 ret .L4: ret
ここで、式a &= (a-1);
blsr
命令に置き換えられました。 この公演の準備をする前に私は彼女に会ったことがありませんでした。 最後のユニットをクリアし、指定されたレジスタに結果を入れます。 別のコンパイラを選択してみましょうx86-64 clang (trunk)
:
popcnt eax, edi
これは、インテルが追加したほど多くの人が望んでいたビットカウント命令です。 clangを実行する必要があると考えてください。 彼には「ビットを数えたい」という手がかりはありませんでした。
追加
0からxまでのすべての整数の加算:
constexpr int sumTo(int x) { int sum = 0; for (int i = 0; i <= x; ++i) sum += i; return sum; } int main(int argc, const char *argv[]) { return sumTo(20); }
mov eax, 210
わかりました ここでconstexprはそれほど重要ではありません。 これをstatic [ 関数が1つの翻訳単位でのみ表示されるように ]に置き換えると、同じ結果が得られます。 sumTo(argc)
を呼び出すと、ループはどこにも行きません。 clangを試してみましょう。
test edi, edi js .LBB0_1 mov ecx, edi lea eax, [rdi - 1] imul rax, rcx shr rax add eax, edi ret .LBB0_1: xor eax, eax ret
興味深いことに、サイクルはなくなりました。 最初の2行は引数のゼロをチェックします。 次の5は単純な合計式です:x(x + 1)/ 2 == x + x(x-1)/ 2。 INT_MAXが渡された場合、最初のバージョンはオーバーフローを引き起こすため、式の2番目のバージョンが実装されます。
Compiler Explorerの仕組み
[ 著者が話したように、フロントエンド、Docker、仮想化などを理解していないため、愚かさを曖昧にしないために、実装の微妙な点をすべて説明しないことにしました ]
node.jsで記述されています。 Amazon EC2で起動しました。 これはこの会議での2回目のスピーチで、JavaScriptについて話し、とても気分が悪いです。 もちろん、C ++を批判することもあります...しかし、JavaScriptだけを見ると、ああ...
すべて次のようになります。
function compile(req, res, next) { // exec compiler, feed it req.body, parse output } var webServer = express(); var apiHandler = express.Router(); apiHandler.param('compiler', function (req, res, next, compiler) { req.compiler = compiler; next(); }); apiHandler.post('/compiler/:compiler/compile', compile); webServer.use('/api', apiHandler); webServer.listen(10240);
Amazon EC2
次の機能:
- エッジキャッシュ
- ロードバランサー
- 仮想マシン
- Dockerイメージ
- 共有コンパイラストレージ
コンパイラー
apt-getを使用してインストールしました。 MicrosoftコンパイラはWINEを介して動作します。
安全性
大きなセキュリティホール。 コンパイラは実行するのではなくコンパイルするだけですが、たとえばGCCはプラグインをサポートしており、動的ライブラリ( -fplugin=/path/to/name.so
)をロードできます。 またはspecsファイル。 最初は潜在的な脆弱性を見つけようとしましたが、すべてを考慮することは非常に難しいという結論に達しました。 そして、私は、起こりうる最悪の事態とは何ですか? Dockerコンテナを停止できますが、再び起動します。 仮想マシンの外に出ても、特権はありません。 Dockerはそのようなトリックから私を守ります。
フロントエンド
Microsoft Monacoは、オンラインコードエディターとして使用されます。 ウィンドウのドラッグドロップは、GoldenLayoutを使用して実装されます。
ソースコード
近日公開
- CFG-コントロールグラフビューア[ IDAのように、私が理解しているように ]。
- 言語の統一。 Compiler Explorerは他の言語({d、swift、haskell、go、ispc} .godbolt.org)をサポートしています。 異なるドメインではなく、1つの場所でそれらを結合したいと思います。 異なる言語での同じ実装を比較できるように。
- コードを実行しています!
ご質問
Boostなど、他のライブラリのサポートを希望します。
すでにいくつかあります:
Boost multi_indexで可能なすべてのテーブルサイズの切り替えについて説明しました。 ただし、このような実装は非効率的です。値が非常にまばらなので、ジャンプテーブルを使用するのではなく、バイナリ検索のみを使用します。
スイッチはサイズ自体をリストしませんが、インデックスをリストします。
Webアセンブリをサポートする予定ですか
Webアセンブリ用のバックエンドがない多くのコンパイラがあります。 まあ、はい、それはいいでしょうが、他のもので忙しい間。
費用はいくらですか?
私はAmazonサーバーに月に約120〜150ドルを費やしています。
llvm中間表現のサポートは予定されていますか?
はい、 -emit-llvm
フラグを-emit-llvm
して実行した場合、すでに存在します。 コンパイラ自体がこのダンプを生成しますが、私は何もしません。 バックライトの改善が計画されています。
ソースコードとアセンブラーコードの対応する行をどのように色付けしますか?
「-g」フラグを指定して実行するだけです。 結果のリストには、行番号付きのコメントが含まれています。