複雑なシステム(分散型/大規模/複雑なロジック/複雑なデータシステム)は、モバイル、可変、独立した生物のようなものです。 これにはすべて、開発者/管理者/ DevOpsエンジニアによる継続的な監視が必要です。
この結論に至ったのは、システムの開発、サーバーのセットアップ、運用中にシステムが数回「曲がった」ときでした。 これにより、監視は生産運用段階だけでなく、開発段階でも実施する必要があるという考えが得られました。
まず最初に...
プロジェクト(少なくともサーバー側)を監視する必要があるという結論に達したとき、理想的なオプションはスキームであると判断しました:「データコレクター→ TSDB →データを表示するためのWebクライアント」。
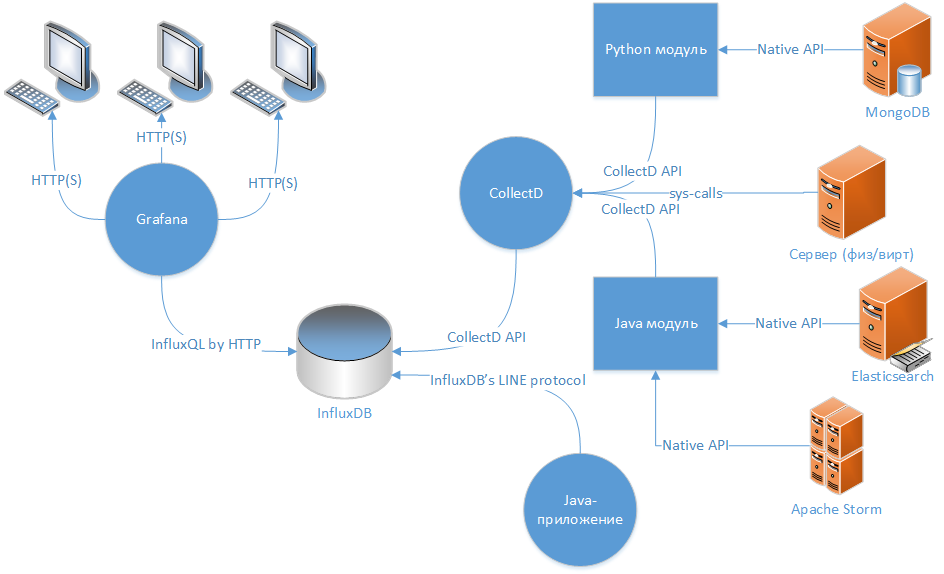
TSDBの選択
現在、 GraphiteをTSDBとして構成することに関する多くの記事がありますが、私はInfluxDBに基づいた、より現代的でレガシーのないソリューションを選択しました 。 InfluxDBについては、 Selectel社のブログの Habréですでに書かれています。 私は他の誰かのテキストをコピーしたくありません、私が言える唯一のことは、情報の一部がもはや真実ではないということですが、基礎はまだ正しいです-システムは生産的で柔軟性があり、異なる言語で動作し、他のTSDBとエージェントの異なるプロトコルをサポートします Graphiteは、Pythonで記述されたいくつかの関連デーモン(過度の複雑さと追加のコンポーネント)の存在に私を驚かせました。
InfluxDBをインストールおよび構成するためのPuppetスクリプト
class storyline_infra::influxdb () { include stdlib $params = lookup({"name" => "storyline_infra.influxdb", "merge" => {"strategy" => "deep"}}) $port_http = $params['port_http'] $port_rpc = $params['port_rpc'] $pid_file = $params['pid_file'] $init_script = $params['init_script'] $dir_data = $params['dir_data'] $dir_logs = $params['dir_logs'] $enabled_auth = $params['enabled_auth'] $enabled_startup = $params['enabled_startup'] $enabled_running = $params['enabled_running'] $version = $params['version'] $dist_name = $facts['os']['name'] user { 'influxdb': ensure => "present", managehome => true, } exec { "influxdb-mkdir": command => "/bin/mkdir -p /data/db && /bin/mkdir -p /data/logs", cwd => "/", unless => '/usr/bin/test -d /data/db -a -d /data/logs', } -> # working dir file { $dir_logs: ensure => "directory", recurse => "true", owner => "influxdb", group=> "influxdb", require => Exec['influxdb-mkdir'], } file { $dir_data: ensure => "directory", recurse => "true", owner => "influxdb", group=> "influxdb", require => Exec['influxdb-mkdir'], } # see by "gpg --verify keyfile" apt::key { 'influxdb-key': id => '05CE15085FC09D18E99EFB22684A14CF2582E0C5', source => 'https://repos.influxdata.com/influxdb.key', } -> # echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list apt::source { 'influxdb-repo': comment => 'influxdb repo', location => "https://repos.influxdata.com/${downcase($dist_name)}", release => "${facts['os']['distro']['codename']}", repos => 'stable', include => { 'deb' => true, }, } -> package { 'influxdb': ensure => $version, } -> file { "/etc/influxdb/influxdb.conf": replace => true, content => epp('storyline_infra/influxdb.epp'), owner => "influxdb", group=> "influxdb", notify => Service['influxdb'], }-> file { $init_script: replace => true, content => epp('storyline_infra/influxdb_startup.epp'), mode=>"ug=rwx,o=r", notify => Service['influxdb'], }-> service { 'influxdb': ensure => $enabled_running, enable => $enabled_startup, start => "${init_script} start", stop => "${init_script} stop", status => "${init_script} status", restart => "${init_script} restart", hasrestart => true, hasstatus => true, } if $enabled_startup != true { exec { "disable_influxdb": command => "/bin/systemctl disable influxdb", cwd => "/", } } logrotate::rule { 'influxdb': path => "${dir_logs}/*.log", rotate => 10, missingok => true, copytruncate => true, dateext => true, size => '10M', rotate_every => 'day', } }
グラファナ
データを表示するためのWebクライアントの選択はずっと前に行われました(私はずっと前に実際にそれを見て、プロジェクトで常にそれを使用したかったです)。 私のプロジェクトからのスクリーンショットは次のとおりです。
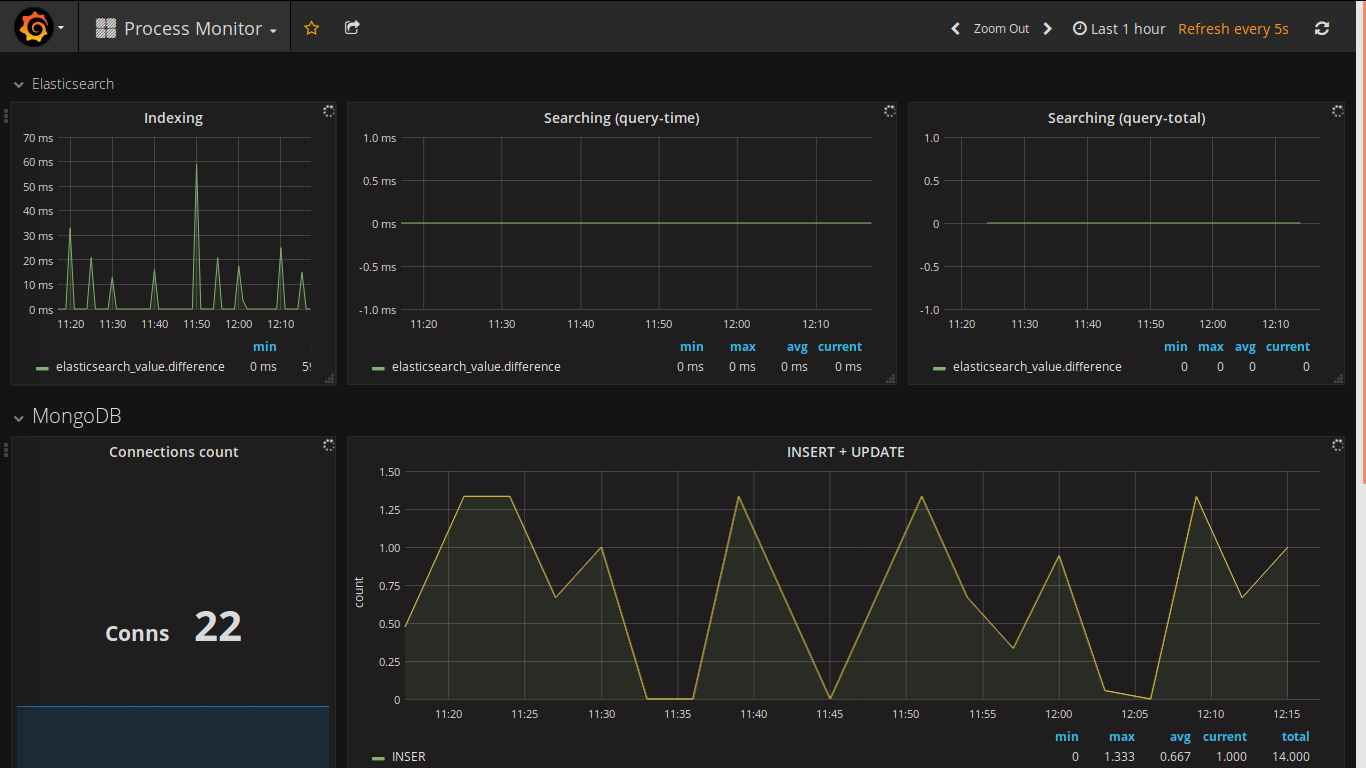
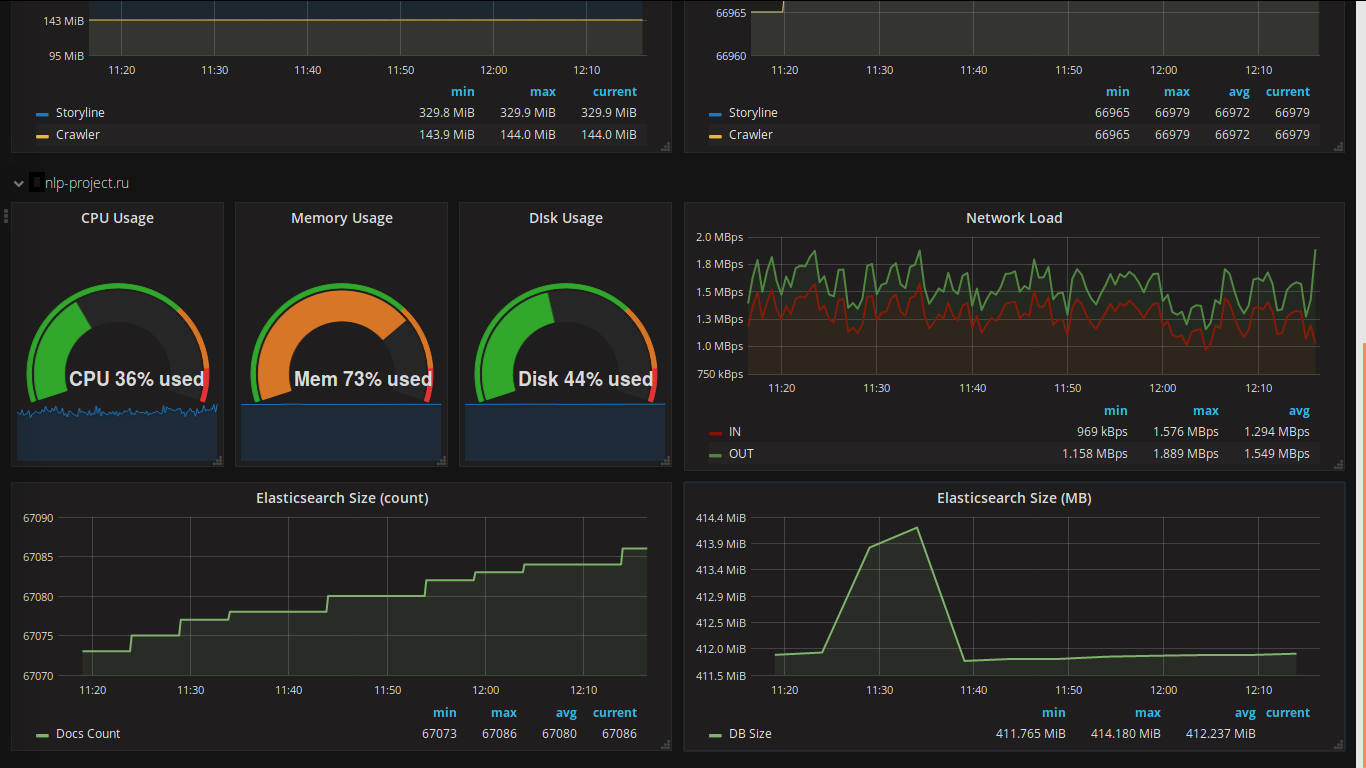
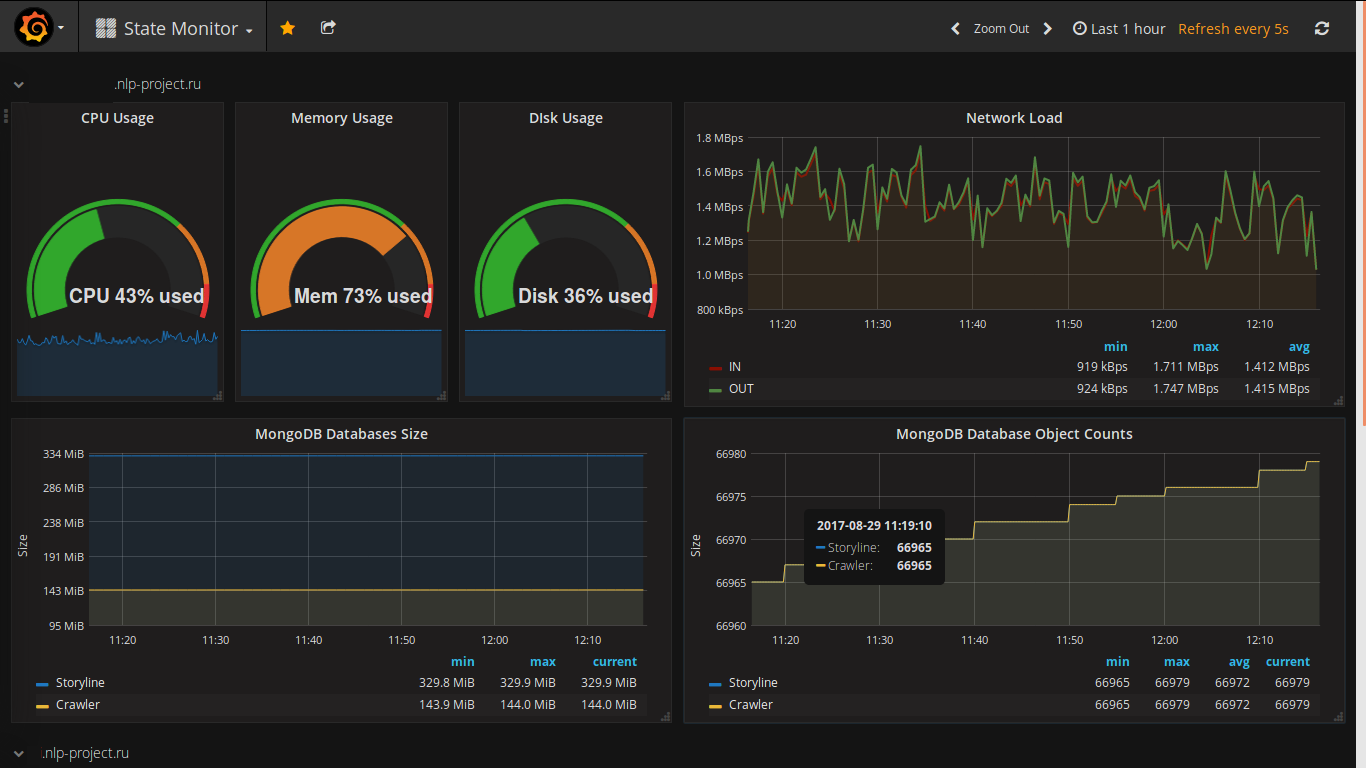
grafanaの機能は次のとおりです。
- いいね
- すべてのデータの動的更新
- ビジュアルデザイナー
- 多数の種類のデータソース(Graphite、InfluxDB、Prometheus、Elasticsearchなど)を接続する
- 多くの認証方法
- アラートを送信する機能(Slack、PagerDuty、VictorOps、OpsGenie ...)
- 機能を拡張するための多数のプラグイン
そして既製のダッシュボードへのリンク-他の人がどのようにグラフを形成し、自分のために何かを(有用および/または美しい)拾うかを見る素晴らしい機会があります。 私は拾った:)
InfluxDBにバンドルされているクライアント-Chronografは、機能面ではまだそれほど優れていません。
Grafanaをインストールおよび構成するためのPuppetスクリプト
class storyline_infra::grafana () { include stdlib $params = lookup({"name" => "storyline_infra.grafana", "merge" => {"strategy" => "deep"}}) $port = $params['port'] $pid_file = $params['pid_file'] $init_script = $params['init_script'] $dir_data = $params['dir_data'] $dir_logs = $params['dir_logs'] $enabled_startup = $params['enabled_startup'] $enabled_running = $params['enabled_running'] $version = $params['version'] user { 'grafana': ensure => "present", managehome => true, } exec { "grafana-mkdir": command => "/bin/mkdir -p /data/db && /bin/mkdir -p /data/logs", cwd => "/", unless => '/usr/bin/test -d /data/db -a -d /data/logs', } -> # working dir file { $dir_logs: ensure => "directory", recurse => "true", owner => "grafana", group=> "grafana", require => Exec['grafana-mkdir'], } file { $dir_data: ensure => "directory", recurse => "true", owner => "grafana", group=> "grafana", require => Exec['grafana-mkdir'], } # see by "gpg --verify keyfile" apt::key { 'grafana-key': id => '418A7F2FB0E1E6E7EABF6FE8C2E73424D59097AB', source => 'https://packagecloud.io/gpg.key', } -> # deb https://packagecloud.io/grafana/stable/debian/ jessie main apt::source { 'grafana-repo': comment => 'grafana repo', location => "https://packagecloud.io/grafana/stable/debian/", release => "jessie", repos => 'main', include => { 'deb' => true, }, } -> package { 'grafana': ensure => 'present', } file { '/etc/init.d/grafana-server': ensure => 'absent', } -> file { '/etc/grafana': ensure => "directory", } -> file { "/etc/grafana/grafana.ini": replace => true, content => epp('storyline_infra/grafana.epp'), owner => "grafana", group=> "grafana", notify => Service['grafana'], } -> file { $init_script: replace => true, content => epp('storyline_infra/grafana_startup.epp'), mode=>"ug=rwx,o=r", notify => Service['grafana'], }-> service { 'grafana': ensure => $enabled_running, enable => $enabled_startup, start => "${init_script} start", stop => "${init_script} stop", status => "${init_script} status", restart => "${init_script} restart", hasrestart => true, hasstatus => true, } if $enabled_startup != true { exec { "disable_grafana": command => "/bin/systemctl disable grafana", cwd => "/", } } }
データ収集について
データ表示の主なソースは、InfluxDBの時系列データであり、 collectdデーモンとjavaライブラリ「 com.github.davidb:metrics-influxdb 」の2つのソースから取得されます。
収集した
収集されるのは、Cで記述されたデーモンであり、InfluxDBがエミュレートできるプロトコルである対応するネットワークにデータを送信できます。 箱から出してすぐに、サーバー環境とサービスの部分でかなり多数のメトリックを収集できます。拡張の可能性は、PythonまたはJavaで書かれたモジュールによって実現されます。
サーバーの機能(物理および仮想)に関する情報を収集するために収集された機能は非常に適していますが、サードパーティサービス(私の場合はElsticsearch、MongoDB、Apache Storm)からデータを収集するために必要な追加設定は非常に重要であり、常に完全に機能するわけではありません(たとえば、 Elsticsearchは、異なるレプリカに複数のシャードがある場合、クエリの速度に関する情報を正しく収集しません)。 ほとんどの場合、InfluxDBのネイティブクライアント-Telegrafに注目する必要があります。
Collectdをインストールおよび構成するためのPuppetスクリプト
class storyline_infra::collectd () { include stdlib $params = lookup({"name" => "storyline_infra.collectd", "merge" => {"strategy" => "deep"}}) $server_port = $params['server_port'] $server_address = $params['server_address'] $pid_file = $params['pid_file'] $init_script = $params['init_script'] $dir_data = $params['dir_data'] $dir_logs = $params['dir_logs'] $enabled_startup = $params['enabled_startup'] $enabled_running = $params['enabled_running'] $version = $params['version'] # mongo db $enabled_mongodb = $params['enabled_mongodb'] $mongodb_user = $params['mongodb_user'] $mongodb_password = $params['mongodb_password'] # storm db $enabled_storm = $params['enabled_storm'] $storm_ui_url = $params['storm_ui_url'] # elasticsearch $enabled_elasticsearch = $params['enabled_elasticsearch'] $elasticsearch_host = $params['elasticsearch_host'] $elasticsearch_port = $params['elasticsearch_port'] $elasticsearch_cluster = $params['elasticsearch_cluster'] exec { "collectd-mkdir": command => "/bin/mkdir -p /data/db && /bin/mkdir -p /data/logs", cwd => "/", unless => '/usr/bin/test -d /data/db -a -d /data/logs', } -> # working dir file { $dir_logs: ensure => "directory", recurse => "true", require => Exec['collectd-mkdir'], } file { $dir_data: ensure => "directory", recurse => "true", require => Exec['collectd-mkdir'], } package { 'collectd': # ensure => $version, ensure => "present", } -> file { "/etc/collectd/collectd.conf": replace => true, content => epp('storyline_infra/collectd.epp'), notify => Service['collectd'], }-> file { $init_script: replace => true, content => epp('storyline_infra/collectd_startup.epp'), mode=>"ug=rwx,o=r", notify => Service['collectd'], }-> service { 'collectd': ensure => $enabled_running, enable => $enabled_startup, start => "${init_script} start", stop => "${init_script} stop", status => "${init_script} status", restart => "${init_script} restart", hasrestart => true, hasstatus => true, } if $enabled_startup != true { exec { "disable_collectd": command => "/bin/systemctl disable collectd & /bin/systemctl disable collectd.service", cwd => "/", } } if $enabled_mongodb { package { 'python-pip': ensure => "present", } -> exec { "install-pymongo": command => "/usr/bin/python -m pip install pymongo", cwd => "/", unless => '/usr/bin/python -m pip show pymongo', } -> file { "/usr/share/collectd/mongodb": ensure => "directory", }-> file { "/usr/share/collectd/mongodb.py": replace => true, content => epp('storyline_infra/collectd_mongodb_py.epp'), }-> file { "/usr/share/collectd/mongodb/types.db": replace => true, content => epp('storyline_infra/collectd_mongodb_types_db.epp'), }-> file { "/etc/collectd/collectd.conf.d/mongodb.conf": replace => true, content => epp('storyline_infra/collectd_mongodb_conf.epp'), notify => Service['collectd'], } } # if $enabled_mongodb { # https://github.com/srotya/storm-collectd if $enabled_storm { file { "/usr/share/collectd/java/storm-collectd.jar": replace => true, ensure => file, source => "puppet:///modules/storyline_infra/storm-collectd.jar", }-> file { "/etc/collectd/collectd.conf.d/storm.conf": replace => true, content => epp('storyline_infra/collectd_storm_conf.epp'), notify => Service['collectd'], } } # if $enabled_mongodb { # https://github.com/signalfx/integrations/tree/master/collectd-elasticsearch # https://github.com/signalfx/collectd-elasticsearch if $enabled_elasticsearch { file { "/usr/share/collectd/elasticsearch.py": replace => true, content => epp('storyline_infra/collectd_elasticsearch_py.epp'), }-> file { "/etc/collectd/collectd.conf.d/elasticsearch.conf": replace => true, content => epp('storyline_infra/collectd_elasticsearch_conf.epp'), notify => Service['collectd'], } } # if $enabled_mongodb { }
com.github.davidb:metrics-influxdb
指定されたライブラリは、実際には、 メトリックの既知のメトリック Javaライブラリのアダプタです。 InfluxDBのプロトコルバージョン0.9をサポートし、必要な情報を完全に転送できます。
初期化は次のように行われます。
if (metricsConfiguration.enabled) { String hostName = InetAddress.getLocalHost().getCanonicalHostName(); final ScheduledReporter reporterInfluxDB = InfluxdbReporter.forRegistry(metricRegistry) .protocol(new HttpInfluxdbProtocol("http", metricsConfiguration.influxdbHost, metricsConfiguration.influxdbPort, metricsConfiguration.influxdbUser, metricsConfiguration.influxdbPassword, metricsConfiguration.influxdbDB)) // rate + dim conversions .convertRatesTo(TimeUnit.SECONDS).convertDurationsTo(TimeUnit.MILLISECONDS) // filter .filter(MetricFilter.ALL) // don't skip .skipIdleMetrics(false) // hostname tag .tag("host", hostName) // !!! converter // al metrics must be of form: "processed_links.site_ru .crawling" -> "crawling // source=site_ru, param=processed_links value=0.1" .transformer(new CategoriesMetricMeasurementTransformer("param", "source")) .build(); reporterInfluxDB.start(metricsConfiguration.reportingPeriod, TimeUnit.SECONDS); }
将来的には、通常のMetrics APIが使用されます。これにより、いつでもソフトウェアで何がどのように行われるかについての透明性を高めることができます。
指定されたシステムにより、システムの動作モードでの動作を監視できるだけでなく、行われた変更によって生じた変更(メモリ消費量、処理速度、データ量などの増加)を追跡することもできました。 現在、原則として、共通のダッシュボードのあるページはキッチンラップトップのブックマークであり、朝の朝食には常に過去9時間のイベントが表示されます。
ご清聴ありがとうございました!