
しかし、20年前に探していたものが完全に見つかった場合、なぜ人工知能の分野の技術が必要なのでしょうか? Korolevは、ニューラルネットワークも使用した昨年のPalekhアルゴリズムとどう違うのですか? また、インデックスアーキテクチャはランキングの品質にどのように影響しますか? 特にHabrの読者には、これらすべての質問に答えます。 そして、最初から始めます。
単語の頻度からニューラルネットワークまで
存在の夜明けのインターネットは、現在の状態とは非常に異なっていました。 そして、それはユーザーとウェブマスターの数だけではありませんでした。 まず、各トピックにサイトが非常に少ないため、最初の検索サービスは検索語を含むすべてのページをリストする必要がありました。 また、多くのサイトがあったとしても、テキストで使用されている単語の数を計算すれば十分であり、複雑なランキングを処理することはできません。 インターネットにはビジネスがなかったため、ラッピングに従事している人はいませんでした。
時間が経つにつれて、サイト、および発行を操作することを望むサイトは、顕著になりました。 また、検索会社は、ページを検索するだけでなく、ユーザーのリクエストに最も関連性の高いページを選択する必要もあります。 世紀の変わり目に、技術はまだページのテキストを「理解」し、それらをユーザーの興味と比較することを許可していなかったため、より簡単な解決策が最初に見つかりました。 検索はサイト間のリンクを考慮し始めました。 リンクが多いほど、リソースの信頼性は高くなります。 そして、彼らが十分でなくなると、彼は人々の行動を考慮し始めました。 そして、その品質を大きく左右するのは、まさに検索のユーザーです。
ある時点で、これらすべての要因が蓄積されすぎて、ランキング式の作成に対処するのをやめました。 もちろん、最高の開発者を採用することもできますし、彼らは多かれ少なかれ機能する検索アルゴリズムを作成しますが、マシンはより良くなりました。 そのため、2009年にYandexは独自のMatrixnet機械学習方法を導入しました。これは、今日まで、使用可能なすべての要因を考慮したランキング式を構築しています。 私たちは長い間、この要素に、間接的な機能(リンク、動作など)ではなくページの関連性を反映するものを追加することを夢見てきましたが、そのコンテンツを「理解」します。 そして、ニューラルネットワークの助けを借りて成功しました。
冒頭で、ドキュメントのテキスト内の単語の頻度を考慮する要因について説明しました。 これは、ページがクエリに一致するかどうかを判断する非常に原始的な方法です。 最新の計算能力により、他のどの機械学習方法よりも優れた自然情報(テキスト、音声、画像)の分析に対応するニューラルネットワークを使用できます。 簡単に言えば、機械が単語による検索から意味による検索に移行できるようにするのは、ニューラルネットワークです。 そして、これは昨年Palekhアルゴリズムで始めたものです。
リクエスト+ヘッダー
パレフについての詳細はここに書かれていますが、コロレフの根底にあるのはパレフであるため、この記事ではこのアプローチをもう一度簡単に思い出します。
個人のリクエストと、トップSERPにあると主張するページのタイトルがあります。 それらが意味で互いにどのように対応するかを理解する必要があります。 これを行うには、クエリテキストと見出しテキストをそのようなベクトルの形式で提示します。そのスカラー積が大きいほど、この見出しを持つドキュメントの関連性が高くなります。 言い換えると、蓄積された検索統計を使用して、意味が近いテキストに対して類似のベクトルを生成するようにニューラルネットワークを訓練し、意味的に関連のないクエリとベクトルヘッダーは異なるはずです。
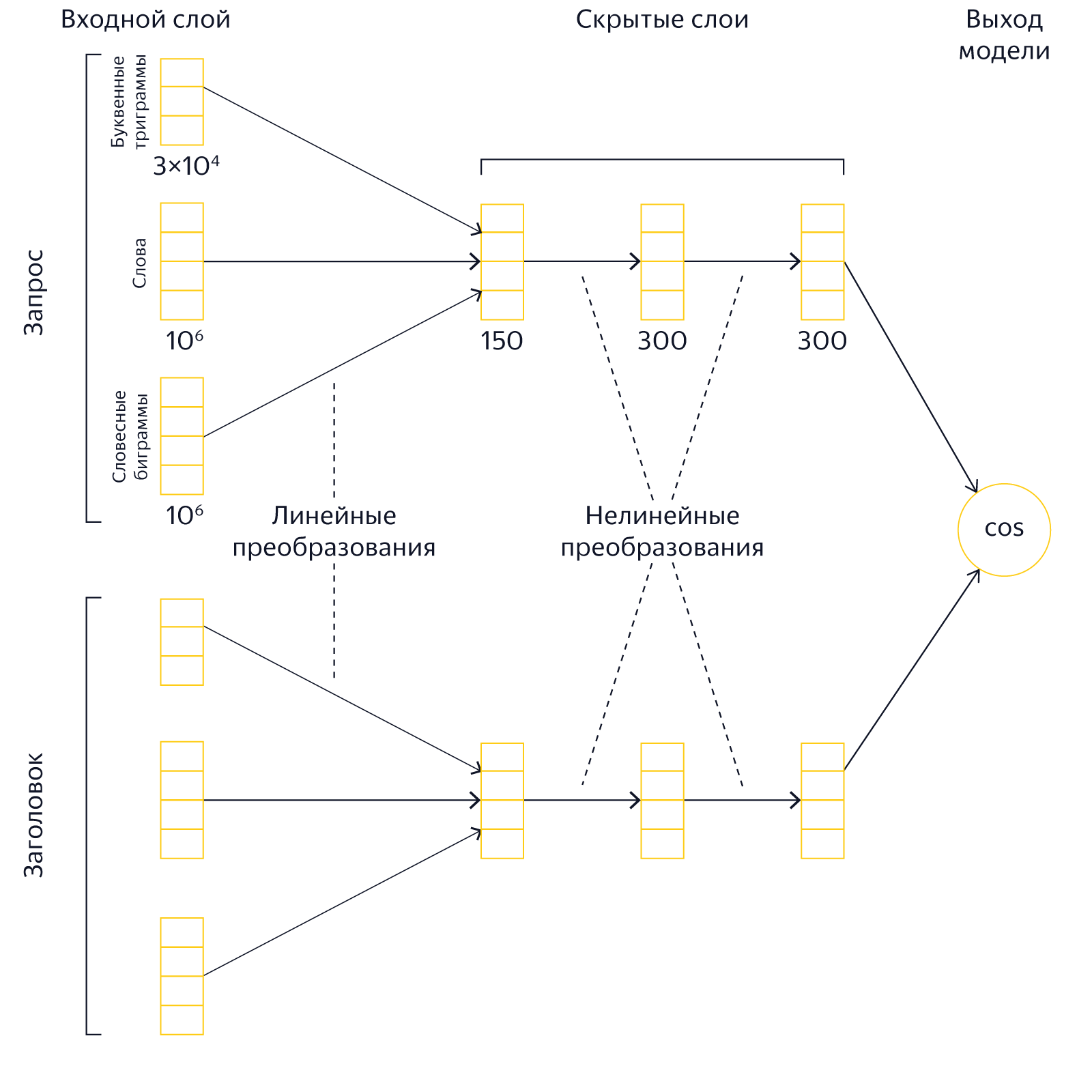
人がYandexでリクエストを入力するとすぐに、サーバーはリアルタイムでテキストをベクトルに変換し、それらを比較します。 この比較の結果は、検索エンジンによって要因の1つとして使用されます。 Palekhモデルでは、リクエストのテキストとページタイトルのテキストをセマンティックベクトルの形式で提示することで、特定が難しいかなり複雑なセマンティックリンクをキャッチできるため、検索の品質に影響します。
Palekhは優れていますが、大きな未実現の可能性がありました。 しかし、それを理解するには、まずランキングプロセスがどのように機能するかを覚えておく必要があります。
ランキングの段階
検索は非常に複雑なものです。数百万のページからクエリに最も関連性の高いものを見つけるのは、ほんの一瞬で必要です。 そのため、現代の検索エンジンでのランキングは、通常、カスケードのカスケードを使用して実行されます。 つまり、検索エンジンはいくつかのステージを使用します。各ステージでドキュメントがソートされ、その後、下位のドキュメントが破棄され、最高のドキュメントで構成される最上位が次のステージに転送されます。 その後の各段階で、ますます重いランキングアルゴリズムが適用されます。 これは主に検索クラスターのリソースを節約するために行われます。計算量の多い要因と数式は、比較的少数の最良のドキュメントに対してのみ計算されます。

Palekhは比較的重いアルゴリズムです。 クエリとドキュメントのベクトルを取得するためにいくつかの行列を乗算し、それらを同様に乗算する必要があります。 行列の乗算は貴重なプロセッサ時間を費やし、あまりにも多くのドキュメントに対してこの操作を実行する余裕はありません。 したがって、Palekhでは、ランキングの最新の段階(L3)でのみ、神経モデルを適用しました-最高の約150のドキュメントに。 一方で、これは悪くありません。 ほとんどの場合、トップ10に表示する必要があるすべてのドキュメントは、これらの150のドキュメントの中のどこかにあり、それらを正しく並べ替える必要があります。 その一方で、ランキングの初期段階でまだ良いドキュメントが失われ、トップに入らないことがあります。 これは、複雑で低頻度のクエリの場合に特に当てはまります。 したがって、ニューラルネットワークモデルの能力を使用して、できるだけ多くのドキュメントをランク付けする方法を学ぶのは非常に魅力的でした。 しかし、それを行う方法は?
コロレフ:記憶と引き換えに計算
複雑なアルゴリズムを単純にできない場合は、少なくともリソースの消費を再配分できます。 この場合、プロセッサ時間をメモリに交換することが有益です。 クエリの実行中にドキュメントのタイトルを取得してそのセマンティックベクトルを計算する代わりに、このベクトルを事前に計算して検索データベースに保存できます。 つまり、作業のかなりの部分を事前に行うことができます。つまり、ドキュメントのマトリックスを乗算し、結果を保存します。 次に、クエリの実行中に、検索インデックスからドキュメントベクトルを取得し、クエリベクトルでスカラー乗算を実行するだけで済みます。 これは、ベクトルを動的に計算するよりも大幅に高速です。 もちろん、この場合、事前に計算されたベクターを保存する場所が必要です。

事前計算されたベクトルに基づくアプローチにより、ニューラルモデルが適用される上部(L3、L2、L1)の深さを根本的に増やすことができました。 コロレフの新しいモデルは、リクエストごとに20万文書という驚くべき深さで計算されます。 これにより、ランキングの初期段階で非常に有用なシグナルを取得することができました。
しかし、それだけではありません。 ベクトルの予備計算とメモリへの保存の成功経験は、私たちが新しいモデルへの道を切り開く前に明らかにしました。
コロレフ:リクエスト+ドキュメント
Palekhでは、ページタイトルのみがモデル入力に送られました。 通常、見出しは、その内容を簡単に説明するドキュメントの重要な部分です。 それでも、ページの本文には、ドキュメントとクエリのセマンティック対応を効果的に判断するのに非常に役立つ情報も含まれています。 では、なぜ最初に見出しに限定したのですか? 実際には、フルテキストモデルの実装には、多くの技術的な困難が伴います。
第一に、メモリが高価です。 クエリの実行中にテキストにニューラルモデルを適用するには、このテキストを「手元に」、つまりRAMに置く必要があります。 また、見出しのような短いテキストをRAMに入れると、自由に使用できる容量では非常に現実的であり、ドキュメントの全文でこれを行うことはできません。
第二に、CPUに負荷がかかります。 モデル計算の初期段階では、ドキュメントをニューラルモデルの最初の非表示層に投影します。 これを行うには、テキストを1回通過させる必要があります。 実際、この段階では、n * mの乗算を実行する必要があります。ここで、nはドキュメント内の単語の数で、mはモデルの最初のレイヤーのサイズです。 したがって、モデルの適用に必要なプロセッサ時間は、テキストの長さに線形に依存します。 短いヘッダーに関しては、これは問題ではありません。 ただし、ドキュメント本文の平均長は大幅に長くなります。
これはすべて、検索クラスタのサイズを根本的に増やすことなく、全文を使用してモデルを実装することは不可能であるかのように聞こえます。 しかし、我々はそれなしでやった。
問題を解決するための鍵は、ヘッダー内のモデルに対してすでにテストしたものと同じ事前に計算されたベクトルでした。 実際、ドキュメントの全文は必要ありません-浮動小数点数の比較的小さな配列のみを保存すれば十分です。 インデックス作成の段階でドキュメントの全文を取得し、一連の操作を適用して、複数の行列を順番に乗算し、ニューラルモデルの最後の内部層で重みを取得できます。 さらに、レイヤーのサイズは固定されており、ドキュメントのサイズに依存しません。 さらに、プロセッサからメモリへのこのような負荷の再分配により、ニューラルネットワークのアーキテクチャを再確認することができました。
コロレフ:レイヤーのアーキテクチャ
古いPalekhモデルでは、サイズが150、300、および300の3つの隠れ層がありました。 このアーキテクチャは、コンピューティングリソースを節約する必要があるためです。クエリの実行中に大きな行列を乗算するのは高価です。 さらに、モデル自体を保存するためにRAMも必要です。 特に強く、モデルのサイズは最初の隠れ層のサイズに依存するため、「Palekh」では比較的小さく、150ニューロンでした。 最初の非表示レイヤーを減らすと、モデルのサイズを大幅に減らすことができますが、同時に表現力が低下します。
新しいKorolevモデルでは、ボトルネックは最後の非表示レイヤーのサイズのみです。 事前計算されたベクトルを使用する場合、リソースは、インデックス内の最後のレイヤーの保存と、クエリベクトルによるスカラー乗算にのみ費やされます。 したがって、最初の隠れ層が増加し、反対に最後の層が減少する場合、新しいモデルに、より「くさび形」の形状を与えることが合理的なステップです。 実験では、隠れ層のサイズを500、500、および40ニューロンに等しくすれば、品質を大幅に向上できることが示されました。 最初の内層の増加の結果として、モデルの表現力は顕著に増加しましたが、最後の層は品質の低下がほとんどない数十個のニューロンに減らすことができます。
それにもかかわらず、すべての最適化にもかかわらず、検索でのニューラルネットワークのそのような深遠なアプリケーションには、かなりの計算能力が必要です。 また、アプリケーションのリソースを解放する別のプロジェクトではなくても、実装にどれだけ時間がかかるかを誰が知っていますか?
コロレフ:追加インデックス
ユーザーリクエストを受け取ると、数百万のインデックスページの中から、最適なページを徐々に選択し始めます。 それはすべてステージL0で始まります。これは実際にはフィルタリングです。 無関係なドキュメントのほとんどを除外し、他のステージはすでにメインランキングに参加しています。
従来の検索モデルでは、逆インデックスを使用してこの問題を解決します。 単語ごとに、それが発生するすべてのドキュメントが保存され、リクエストが到着すると、これらのドキュメントをクロスしようとします。 主な問題は頻出語です。 たとえば、「ロシア」という単語は、10ページごとに表示される場合があります。 その結果、必要なものが失われないように、10番目ごとのドキュメントを確認する必要があります。 しかし一方で、リクエストを入力したばかりのユーザーが同じ瞬間に答えを見るのを待っているので、フィルタリング段階は厳密に制限されています。 頻度の高い単語のすべてのドキュメントを巡回する余裕はなく、さまざまなヒューリスティックを使用しました:無関心の関連性リクエストの値でドキュメントをソートするか、十分な数の良いドキュメントがあると思われるときに検索を停止しました。 一般に、このアプローチはうまく機能しましたが、有用なドキュメントが失われることがありました。
新しいアプローチでは、すべてが異なります。 それは仮説に基づいています:複数の単語のクエリに対して各単語またはフレーズの最も関連性の高いドキュメントのリストをあまり大きく取らない場合、それらの中にはすべての単語に同時に関連するドキュメントがあります。 実際には、これはこれを意味します。 すべての単語と一般的な単語のペアについて、ページのリストとクエリとの予備的な関連性を含む追加のインデックスが生成されます。 つまり、ステージL0からインデックス作成ステージまでの作業に参加します。 これにより何が得られますか?
計算の厳しい時間の制約は、単純な事実に関連しています-ユーザーを強制的に待機させることはできません。 ただし、これらの計算を事前にオフラインで実行できる場合(つまり、リクエストの入力時ではない場合)、そのような制限はありません。 マシンにインデックスからすべてのドキュメントをバイパスさせることができ、1つのページが失われることはありません。
検索の完全性が重要です。 しかし、それほど重要ではないという事実は、RAM消費のコストで、出力を構築する瞬間を大幅にアンロードし、重いニューラルネットワークモデルのリクエスト+ヘッダーおよびリクエスト+ドキュメントのコンピューティングリソースを解放するという事実です。 そして彼らだけではありません。
コロレフ:リクエスト+リクエスト
新しい検索に取り組み始めたとき、どの方向が最も有望かについてはまだ確信がありませんでした。 したがって、神経モデルの研究に2つのチームを割り当てました。 しばらくの間、彼らは独立して働き、彼ら自身のアイデアを発展させ、そしてある程度まで彼らの間で競争しました。 そのうちの1人は、すでに上で説明したリクエストとドキュメントを使用したアプローチに取り組みました。 2番目のチームは、まったく異なる視点から問題に取り組みました。
インターネット上のどのページでも、複数のリクエストを作成できます。 クエリ[VKontakte]、[VKontakte login]、または[VKontakte social network]を使用して、同じ「VKontakte」を検索できます。 要求は異なりますが、その背後にある意味は1つです。 そして、それを使用することができます。 2番目のチームの同僚は、ユーザーが入力したばかりのクエリと、ベストアンサーが確実にわかっている別のクエリのセマンティックベクトルを比較するというアイデアを思いつきました。 また、ベクトル(およびクエリの意味)が十分に近い場合、検索結果は類似しているはずです。
その結果、両方のアプローチで良い結果が得られ、チームが力を合わせたことがわかりました。 これにより、迅速に調査を完了し、Yandexの検索に新しいモデルを導入できました。 たとえば、クエリ[Mongoliaの怠yな猫]を入力すると、マヌルに関する情報を一番上に引き出すのに役立つのはニューラルネットワークです。
次は?
Korolevは特定のモデルではなく、Yandex検索でニューラルネットワークをより深く適用するための一連のテクノロジーです。 これは、将来に向けたもう1つの重要なステップです。このステップでは、検索は、人よりも悪くないリクエストとページの意味的な対応に焦点を合わせます。 またはさらに良い。
上記のすべてはすでに機能しており、他のいくつかのアイデアが翼で待っています。 たとえば、L0検索段階でニューラルネットワークを使用して、セマンティックベクトルがクエリに意味は近いがクエリワードをまったく含まないドキュメントを検索できるようにしたいと思います。 また、パーソナライズを追加したかった(人間の興味に対応する別のベクトルを想像してください)。 しかし、これには時間と知識だけでなく、メモリとコンピューティングリソースも必要です。ここでは、新しいデータセンターがなければできません。 そして、Yandexにはすでに1つあります。 しかし、これは別の話であり、近い将来に私たちが確実に語ることになるでしょう。 出版物に従ってください。