最初の情報
GitHubがプロダクションでKubernetesを実装しているという事実は、アーロンブラウンのSREエンジニアのTwitterアカウントから1か月前に初めて知られるようになりました。 それから彼は簡単に報告しました:
つまり、「今日GitHubのページにアクセスすると、今日からすべてのWebコンテンツがKubernetesを使用して配信されるという事実に興味を持つかもしれません。」 その後の応答により、Kubernetesが管理するDockerコンテナへのトラフィックがWebフロントエンドとGistサービスに切り替えられ、APIアプリケーションが移行中であることが明らかになりました。 GitHubでのコンテナ化はステートレスアプリケーションにのみ影響しました。ステートフル製品と「[メンテナンスのため] MySQL、Redis、Git、[GitHubで既に広範な自動化を行っています] Kubernetesの選択は、GitHubの従業員にとって最適と呼ばれ、「Mesos / Nomadは悪くも良くもありません。ただ違うだけです。」
情報はほとんどありませんでしたが、GitHubのエンジニアはすぐに詳細について話すことを約束しました。 そして昨日、会社のシニアSREであるJesse Newlandが待望のメモ「 GitHubでKubernetes 」を発行し、文字通りハブでのこの発行の8時間前に、前述のアーロンブラウンはApprendaでのKubernetesの2周年の遅れたお祝いで対応するレポートで話しました:

アーロンのレポートからの引用:「「ホストのセットアップにもっと時間を費やすことを夢見ています」-エンジニアなし、決して」
GitHubでKubernetesを使用する理由
最近のイベントまで、Ruby on Railsで書かれたメインのGitHubアプリケーションは、作成されてから過去8年間ほとんど変わっていません。
- UbuntuがPuppetで構成されたサーバーで、GodプロセスマネージャーがUnicorn Webサーバーを起動しました。
- 展開には、SSHを介して各フロントエンドサーバーに接続し、コードを更新してプロセスを再起動したCapistranoを使用しました。
- ピーク負荷が使用可能な容量を超えた場合、SREエンジニアは、ワークフローでgPanel、IPMI、iPXE、Puppet Facter、Ubuntu PX-imageを使用して新しいフロントエンドサーバーを追加しました(詳細については、 こちらをご覧ください ) 。
GitHub(従業員、機能とサービスの数、ユーザーリクエスト)の成長に伴い、特に次のような困難が生じました。
- 一部のチームは、個別の起動/展開のために、大規模なサービスから機能の一部を「抽出」する必要がありました。
- サービス数の増加により、多数のアプリケーションで多くの同様の構成をサポートする必要が生じました(サーバーのサポートとプロビジョニングにより多くの時間が費やされました)。
- 新しいサービスの展開(複雑さに応じて)には、数日、数週間、さらには数か月かかりました。
時間が経つにつれて、このアプローチでは、世界クラスのサービスを作成するために必要な柔軟性がエンジニアに提供されないことが明らかになりました。 私たちのエンジニアには、新しいサービスの実験、展開、スケーリングに使用できるセルフサービスプラットフォームが必要でした。 さらに、同じプラットフォームがメインのRuby on Railsアプリケーションの要件を満たす必要があったため、エンジニアやロボットは負荷の変化に対応し、追加のコンピューティングリソースを数時間、数日、またはそれ以上ではなく数秒で割り当てることができました。
エンジニアと開発者は、これらの問題を解決するために共同プロジェクトを開始し、既存のコンテナオーケストレーションプラットフォームの研究と比較に至りました。 Kubernetesを評価するとき、彼らはいくつかの利点を特定しました。
- プロジェクトをサポートするアクティブなオープンソースコミュニティ。
- 最初の起動の肯定的な経験(小さなクラスターでのアプリケーションの最初の展開には数時間しかかかりませんでした);
- Kubernetesの作者の経験に関する広範な情報が、既存のアーキテクチャにつながった。
Kubernetesを使用した展開
Kubernetesベースのインフラストラクチャを使用してメインのGitHub Rubyアプリケーションの展開を整理するために、いわゆるレビューラボが作成されました。 次のプロジェクトで構成されていました。
- AWS VPCクラウドで実行され、Terraformとkopsで管理されるKubernetesクラスター。
- プロジェクトの開始時に積極的に使用されていたKubernetes一時クラスターでテストを実行する、Bashでの一連の統合テスト。
- アプリケーションの
Dockerfile
。 - コンテナのアセンブリとレジストリでの公開をサポートするための内部継続的統合プラットフォーム(CI)の改善。
- Kubernetesが使用する50以上のリソースのYAMLビュー。
- KubernetesリソースをリポジトリからKubernetes名前空間に「転送」し、Kubernetesシークレットを(内部ストレージから)作成するための内部展開アプリケーションの改善。
- UniProxy囲炉裏から既存のサービスにトラフィックをリダイレクトするためのHAProxyおよびconsul-templateに基づくサービス。
- Kubernetesから内部エラー管理システムにアラームイベントを転送するサービス。
- chatops-rpcと互換性があり、チャットユーザーにkubectlコマンドへの制限付きアクセスを提供するkube-meサービス。
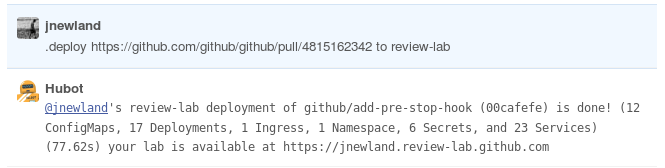
一番下の行は、プルリクエストにGitHubアプリケーションをデプロイするためのチャットベースのインターフェースです。
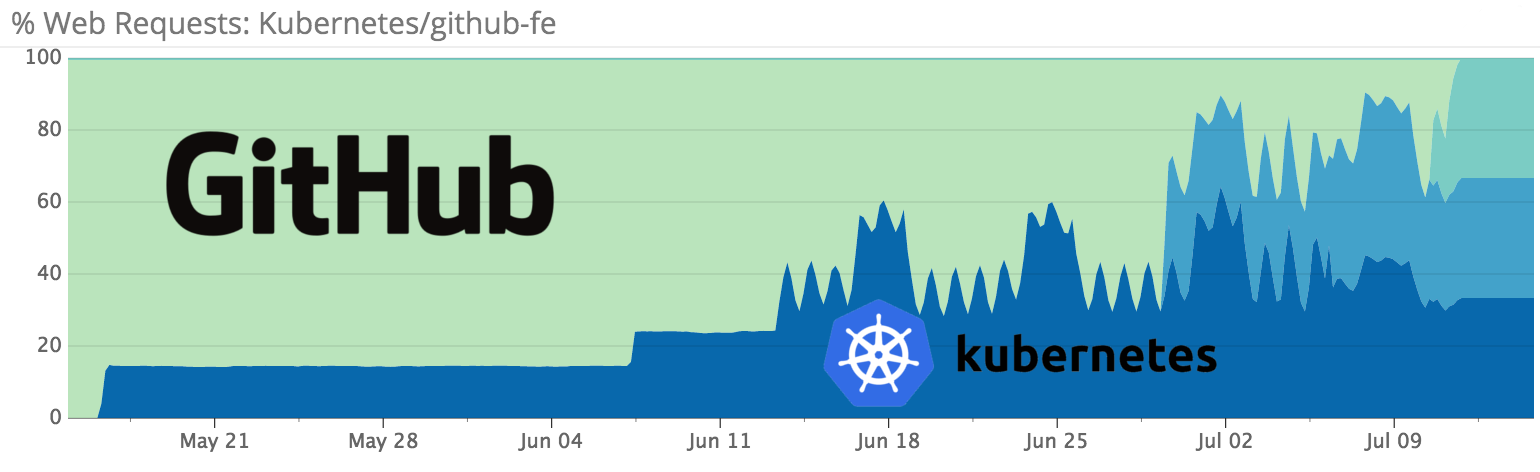
実験室の実装は優れていることが判明し、6月の初めまでに、GitHubの展開全体が新しいスキームに切り替わりました。
インフラストラクチャ向けKubernetes
Kubernetesの実装における次のステップは、同社の主要な生産サービスであるgithub.comのための非常に要求の厳しいインフラストラクチャパフォーマンスと信頼性インフラストラクチャの構築でした。
GitHubの基本的なインフラストラクチャは、いわゆるメタルクラウド (独自のデータセンターの物理サーバーで実行されるクラウド)です。 もちろん、Kubernetesは仕様を考慮して実行する必要がありました。 このために、同社のエンジニアは再び多くの支援プロジェクトを実施しました。
- ネットワークプロバイダーとして、「
ipip
モードでクラスターを迅速にデプロイするために必要な機能をすぐに提供する」Calicoを選択しました。 - Kubernetesを繰り返し(「少なくとも12回」)読み取ることで、手動で保守された複数のサーバーを一時的なKubernetesクラスターにアセンブルし、既存のAWSクラスターで使用される統合テストに合格しました。
- 使用するPuppetおよびシークレットストレージシステムによって認識される形式で、各クラスターのCAと構成を生成する小さなユーティリティを作成します。
- 2つのロール(KubernetesノードとKubernetes apiserver)の構成の人形化。
- コンテナログを収集し、キー値形式のメタデータを各行に追加し、ホストのsyslogに送信するサービス(Go言語)を作成します。
- Kubernetes NodePortサービスのサポートを負荷分散( GLB )に追加します。
その結果、鉄製サーバー上のKubernetesクラスターが内部テストに合格し、1週間以内にAWSからの移行に使用されるようになりました。 このようなクラスターを追加作成した後、GitHubエンジニアはKubernetesで戦闘github.comのコピーを起動し、(GLBを使用して)アプリケーションの元のインストールとKubernetesのバージョンを切り替えるボタンを従業員に提供しました。 サービスアーキテクチャは次のとおりです。
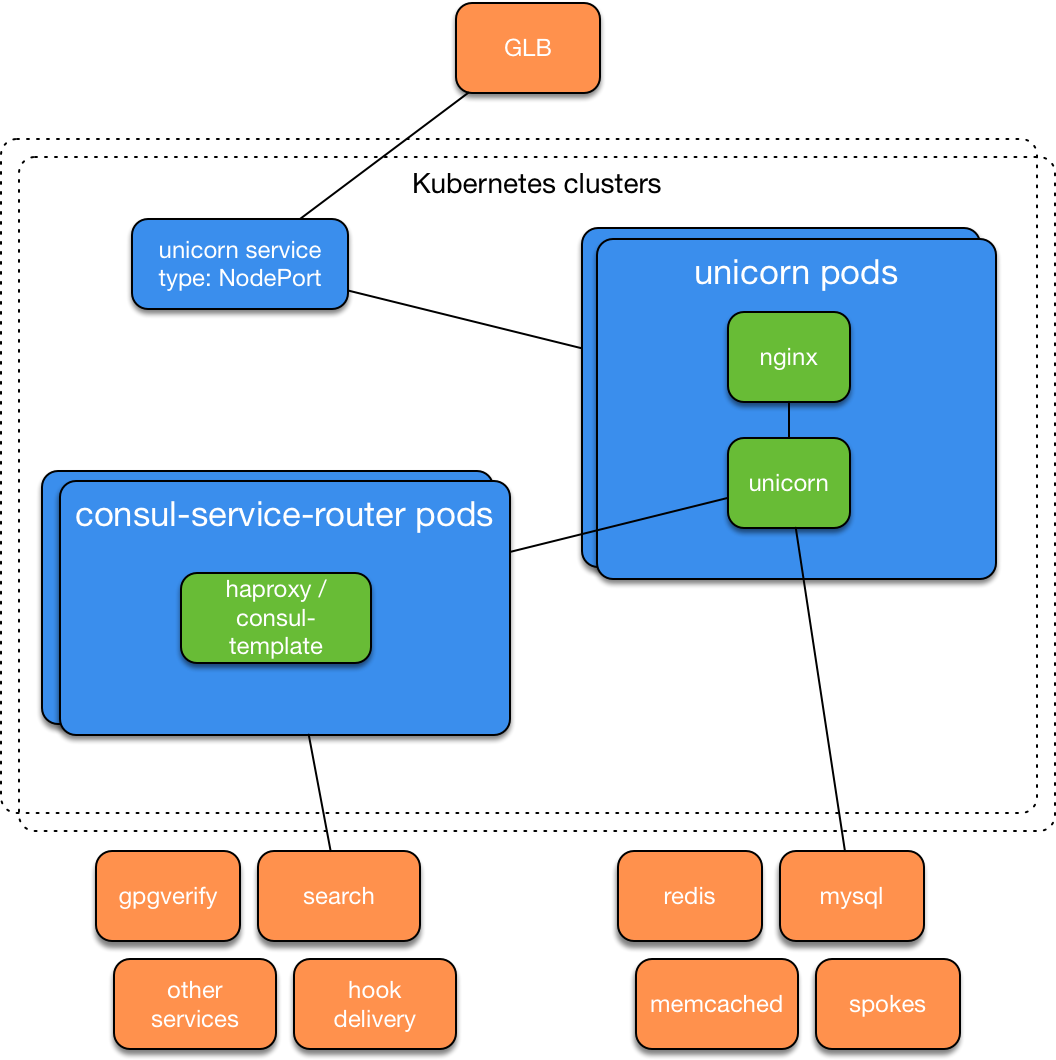
従業員が発見した問題を修正した後、ユーザートラフィックの新しいクラスターへの段階的な切り替えが開始されました。まず、1秒あたり100リクエスト、次にgithub.comおよびapi.github.comへのすべてのリクエストの10%です。
トラフィックの10%から100%に切り替えるのに急いでいませんでした。 部分負荷テストは予期しない結果を示しました:1つのKubernetes apiserverホストの障害は、一般に利用可能なリソースの可用性にマイナスの影響を与えました-「明らかに」理由は、apiserver(calico-agent、kubelet、kube -proxy、kube-controller-manager)、およびapiserverノードのフォール中の内部ロードバランサーの動作。 そのため、GitHubは、異なる場所にあるいくつかのクラスターでメインアプリケーションを実行し、問題のあるクラスターから動作中のクラスターにリクエストをリダイレクトすることにしました。
今年の7月中旬までに、GitHubの生産トラフィックの100%がKubernetesベースのインフラストラクチャにリダイレクトされました。
同社のエンジニアによると、残っている問題の1つは、一部のKubernetesノードの高負荷時にカーネルパニックが発生し、その後再起動することです。 外見上はユーザーには目立ちませんが、SREチームはこの動作の理由を見つけてそれらを排除することに高い優先度を持っています。 。 それにもかかわらず、著者は一般的に得られた経験に満足しており、そのようなアーキテクチャへの移行をさらに実施し、Kubernetesでのステートフルサービスの立ち上げの実験を開始します。
サイクルからの他の記事
- 「 Kubernetesの生産における成功事例。 パート1: eBayの4,200の囲炉裏とTessMaster 」
- 「 Kubernetesの生産における成功事例。 パート2: ConcurとSAP 。」
- 「 Kubernetesの生産における成功事例。 パート4: SoundCloud(著者プロメテウス) 。」
- 「 Kubernetesの生産における成功事例。 パート5: Monzo Digital Bank。 」
- 「 Kubernetesの生産における成功事例。 パート6: BlaBlaCar 。」
- 「 Kubernetesの生産における成功事例。 パート7: BlackRock 。」
- 「 Kubernetesの生産における成功事例。 パート8: Huawei 。」
- 「 Kubernetesの生産における成功事例。 パート9: CERNおよび210 K8sクラスター。
- 「 Kubernetesの生産における成功事例。 パート10: Reddit 。」