ガイドの第2部では、ニューラルネットワークがランダムフォレストよりもこのタスクに効果的に対処できるかどうかを確認し、古典的な方法の最大の欠点であるデータシーケンスを処理できないことを考慮しようとします。
ある意味、このステップは冗長です。会話中に(少なくとも現在の開発段階および特定の標準条件で)人の性別は変わらないため、精度の向上を期待しないでください。 しかし、学術目的のために、私たちは試してみます。
 /フォト・トリスタン・バワーソックス / CC-SA
/フォト・トリスタン・バワーソックス / CC-SA
ニューラルネットワークの仕組みに関する次の章
人工ニューラルネットワーク(ニューラルネットワーク)は、人間の脳の数学的モデルであると考えられています。 実はそうではありません :50-60年前、あるレベルの生物学者は脳の電気的プロセスを研究し、数学者は単純化されたモデルを作成し、それをプログラムしました。
そのような構造はいくつかの単純な問題を解決することができることが判明しましたが、a)従来の方法よりも劣り、b)はるかに遅いです。 そして否定できない現状は半世紀にわたって維持されました-科学者は理論(教授法、アーキテクチャ、基本的な数学的質問)を開発し、コンピューター技術とソフトウェアは非常に開発され、家庭用PCでいくつかの問題をグローバルレベルで解決することが可能になりました。
しかし、すべてがそれほどスムーズではありません 。ニューラルネットワークは、チーターとヒョウを区別することを学ぶことができ、斑点のあるソファをこれらの動物の1つとして数えることができます。 さらに、人と機械を教えるプロセスは異なります。コンピュータには何千ものトレーニングサンプルが必要ですが、人にはいくつかのトレーニングサンプルが必要です。 明らかに、人工ニューラルネットワークの作業は人間の思考にあまり似ておらず、脳のコンピューターモデルではなく、リスト上の別のクラスのモデル:ランダムフォレスト、SVM、XGBoostなど、有利な機能を備えています。
歴史的に、ニューラルネットワークの最初の動作アーキテクチャは、多層パーセプトロンです。 レイヤーで構成され、各レイヤーはニューロンで構成されています。 信号は、最初の層から最後の層へと一方向に送信され、現在の層の各ニューロンは、前の層のすべてのニューロンに、異なる重みで接続されます。 2つのニューロン間の接続の重みには、その重要性の物理的意味があります。値が大きいほど、ニューロンの出力値への寄与が大きくなります。 ニューラルネットワークをトレーニングするには、出力層で必要なものが得られるような重みの値を見つける必要があります。
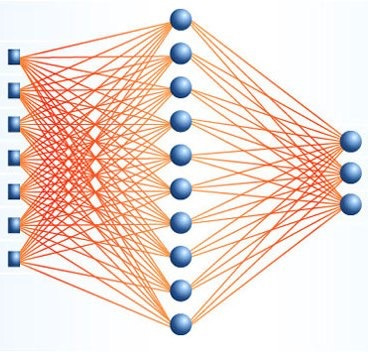
完全に接続されたアーキテクチャは、定性的に古典的な方法とは異なりません:数のベクトルを入力として受け入れ、何らかの方法で処理し、結果はクラスの1つに属する入力ベクトルの確率のセットです(これは分類問題のためですが、他のものも考慮できます)。 実際には、他のアーキテクチャ(畳み込み、反復)を使用して入力機能を処理し、いわゆる高レベル機能を取得してから、完全に接続されたレイヤーを使用して処理します。
畳み込みネットワークの動作の分析は、 こことここで見つけることができます (数千あるので、選択は読者に任せます)。リカレントネットワークを個別に分析します。 記号、信号値、または単語ラベルに関係なく、入力として数値のシーケンスを使用します。 それらのためのニューロンの役割は通常、入力信号を加算して出力を取得することに加えて、追加のパラメーターのセットを持っている特別なセルによって実行されます-内部値は記憶され、セルの出力値に影響します。
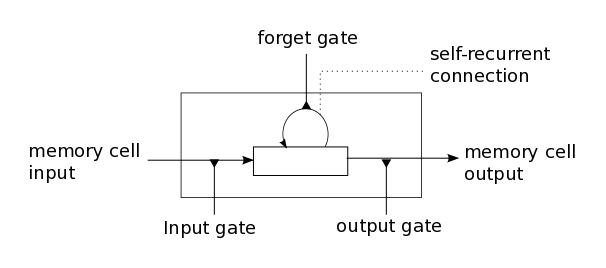
現在、最も広く使用されているリカレントアーキテクチャは、Long Short-Term Memory(LSTM)です。 最も単純な実装では、各セルには入力、出力、および忘却弁の3つの個別の要素が含まれます。 最も有用な信号が出力されるように、処理された入力データと保存された値を「混合」する必要がある割合を決定します。 LSTMネットワークを訓練することは、最初の層のLSTMセルと最後の層のニューロンの間の接続の重みとゲートのそのようなパラメータを見つけることです。入力シーケンスでは、出力層は各クラスに属する確率を返します。
初期設定
このガイドの最初の部分をお読みください。 その中には、音声ベースの説明、計算された特徴、およびランダムフォレスト分類器の結果があります。 彼は、属性の統計について訓練され、音声の良いセクション(特定の制限まで)、フィルター処理されたセクションで計算されました。 各記号について、平均値、中央値、最小値、最大値、および標準偏差が考慮されました。
ニューラルネットワークは、トレーニングの例の数をより要求します。 最後の部分では、 VCTKデータベースから取得した109人のスピーカーからの436個のオーディオフラグメント(それぞれ4つのステートメント)を調査しました 。 テストしたニューラルネットワークアーキテクチャのいずれも妥当な精度で学習できなかったため、さらに多くのフラグメント(5000のみ)を取得しました。しかし、サンプルを増やしても精度は大幅に向上しませんでした-正しく分類されたフラグメントの98.5%。 設定する最初の実験は、同じ機能セットで完全に接続されたニューラルネットワークをトレーニングすることです。
すべてのコードを引き続きPythonで記述し、必要なアーキテクチャを数行で実装できる最も便利なライブラリであるKerasからニューラルネットワークの実装を取得します。
必要なものをすべてインポートします。
import csv, os import numpy as np import sklearn from sklearn.ensemble import RandomForestClassifier as RFC from sklearn.model_selection import GroupKFold from keras.models import Model from keras.callbacks import ModelCheckpoint from keras.layers import Input, Dense, Dropout, LSTM, Activation, BatchNormalization from keras.layers.wrappers import Bidirectional from keras.utils import to_categorical
sklearnからランダムフォレストを実装し、そこからグループによる相互検証を行います。 Kerasから、モデル、レイヤー、双方向LSTMを使用できる双方向ラッパー、およびワンホットベクトルでクラスラベルをエンコードするto_categorical関数の基本クラスを取得します。
すべてのデータを読み取ります。
with open('data.csv', 'r')as c: r = csv.reader(c, delimiter=',') header = next(r) data = [] for row in r: data.append(row) data = np.array(data) genders = data[:, 0].astype(int) speakers = data[:, 1].astype(int) filenames = data[:, 2] times = data[:, 3].astype(float) pitch = data[:, 4:5].astype(float) features = data[:, 4:].astype(float)
そして、サンプルを取得します。
def make_sample(x, y, subj, names, statistics=[np.mean, np.std, np.median, np.min, np.max]): avx = [] avy = [] avs = [] keys = np.unique(names) for ki, k in enumerate(keys): idx = names == k v = [] for stat in statistics: v += stat(x[idx], axis=0).tolist() avx.append(v) avy.append(y[idx][0]) avs.append(subj[idx][0]) return np.array(avx), np.array(avy).astype(int), np.array(avs).astype(int) filter_idx = pitch[:, 0] > 1 filtered_average_features, filtered_average_genders, filtered_average_speakers = make_sample(features[filter_idx], genders[filter_idx], speakers[filter_idx], filenames[filter_idx])
ここでは、周波数によるフィルタリングを適用しました。ピッチ周波数が決定されていない音声のセクションを考慮から除外しました。 これは次の2つの場合に発生する可能性があります。フレームが音声にまったく対応しないか、子音またはささやきに対応する。 このタスクでは、ピッチなしですべてのフレームを完全に捨てることができますが、他の多くでは、フィルタリングはあまり貪欲に行われるべきではありません。
次に、完全に接続されたニューラルネットワークを実装する必要があります。
def train_dnn(x, y, tx, ty): yc = to_categorical(y) # one-hot encoding for y tyc = to_categorical(ty)# one-hot encoding for y_test inp = Input(shape=(x.shape[1],)) model = BatchNormalization()(inp) model = Dense(100, activation='tanh')(model) model = Dropout(0.5)(model) model = Dense(100, activation='tanh')(model) model = Dropout(0.5)(model) model = Dense(100, activation='sigmoid')(model) model = Dense(2, activation='softmax')(model) model = Model(inputs=[inp], outputs=[model]) model.compile(optimizer='sgd', loss='categorical_crossentropy', metrics=['acc']) modelcheckpoint = ModelCheckpoint('model.weights', monitor='val_loss', verbose=1, save_best_only=True, mode='min') model.fit(x, yc, validation_data=(tx, tyc), epochs=100, batch_size=100, callbacks=[modelcheckpoint], verbose=2) model.load_weights('model.weights') return model
ネットワークの最初の層はBatch Normalizationです。 これにより、データを正規化する必要がなくなり、学習プロセスが高速化され、再トレーニングを回避することがある程度可能になります。 最初に、各バッチ(トレーニングの各反復でのデータ)をそれぞれの平均と標準偏差に正規化し、次に線形変換を使用してスケーリングします。そのパラメーターは最適化の対象となります。
ほぼ同じ目的で、完全に接続された各レイヤーの後にドロップアウトレイヤーがあります。 前のレイヤーのニューロンの一部(この例では半分)をランダムに選択し、出力値をゼロにします。 これにより、ネットワークをより安定させることができます。リンクの一部を削除しても、正しい答えが得られます。 まさにこの理由で、実際には、2倍の数のニューロンと50%のドロップアウトを持つレイヤーは、従来のレイヤーよりも効果的です。
高密度-直接完全に接続されたレイヤー。 それらの出力は、いくつかの重みで重み付けされた入力信号の古典的な合計であり、活性化関数を使用して非線形に変換されます。 最初の層ではtanh 、最後では-softmaxであるため、出力信号の合計は1に等しく、いずれかのクラスに属する確率に対応します。 モデルチェックポイントは、テストサンプルのエラーの測定値- 検証損失 -が以前に保存されたモデルの測定値よりも小さい場合にのみ、トレーニングの各時代の後にモデルを書き直す装飾的なものです。 これにより、最も効率的なモデルがmodel.weightsに書き込まれます 。
スピーカーによる相互検証プロセスを説明し、同じデータで上記の完全に接続されたネットワークとランダムフォレストを比較することは残ります。
def subject_cross_validation(clf, x, y, subj, folds): gkf = GroupKFold(n_splits=folds) scores = [] for train, test in gkf.split(x, y, groups=subj): if clf == 'dnn': model = train_dnn(x[train], y[train], x[test], y[test]) score = model.evaluate(x[test], to_categorical(y[test]))[1] scores.append(score) elif clf == 'lstm': model = train_lstm(x[train], y[train], x[test], y[test]) score = model.evaluate(x[test], to_categorical(y[test]))[1] scores.append(score) else: clf.fit(x[train], y[train]) scores.append(clf.score(x[test], y[test])) return np.mean(scores) score_filtered = subject_cross_validation(RFC(n_estimators=1000), filtered_average_features, filtered_average_genders, filtered_average_speakers, 5) print score_filtered score_filtered = subject_cross_validation('dnn', filtered_average_features, filtered_average_genders, filtered_average_speakers, 5) print('Utterance classification an averaged features over filtered frames, accuracy:', score_filtered)
ほぼ同じ精度値を取得しました-ランダムフォレストで98.6%、ニューラルネットワークで98.7%。 おそらく、パラメーターを最適化してより高い精度を得ることができますが、すぐにそれが本来の目的であるリカレントネットワークから始めます。
def make_sequences(x, y, subj, names): sx = [] sy = [] ss = [] keys = np.unique(names) sequence_length = 100 for ki, k in enumerate(keys): idx = names == k v = x[idx] w = np.zeros((sequence_length, v.shape[1]), dtype=float) sh = v.shape[0] if sh <= sequence_length: dh = sequence_length - sh if dh % 2 == 0: w[dh//2:sequence_length-dh//2, :] = v else: w[dh//2:sequence_length-1-dh//2, :] = v else: dh = sh - sequence_length w = v[sh//2-sequence_length//2:sh//2+sequence_length//2, :] sx.append(w) sy.append(y[idx][0]) ss.append(subj[idx][0]) return np.array(sx), np.array(sy).astype(int), np.array(ss).astype(int)
最初に、シーケンスを選択する必要があります。 Kerasは、その単純さにも関わらず、細心の注意を要する場合があり、ここでは.fitまたは.fit_on_batchメソッドの入力変数を自然にテンソルに変換できる必要があります。 たとえば、異なる長さのシーケンス(これはまさに私たちの場合です)は、このプロパティを所有していません。
ライブラリのこの純粋に技術的な制限は、いくつかの方法で回避できます。 1つはサイズ1のバッチでのトレーニングで、このアプローチの明らかな欠点は、 バッチの正規化が適用できないことと、トレーニング時間の壊滅的な増加です。
2番目の方法は、ゼロをシーケンスに追加して(パディング)、目的の次元を取得することです。 一見、これは間違っているように見えますが、ネットワークはそのような値に応答しないことを学びます。 また、これらの方法は組み合わせることができます-各ホールドパディングとトレーニング内で、長さシーケンスをいくつかのグループに分けます。
長さ100のシーケンスを考えます。これは、音声の1秒に相当します。 これを行うために、正確に100個のポイントが残り、さらに中央を中心に対称になるように長いシーケンスをトリミングし、短いものの先頭と末尾にゼロを追加して目的の長さにします。
def train_lstm(x, y, tx, ty): yc = to_categorical(y) tyc = to_categorical(ty) inp = Input(shape=(x.shape[1], x.shape[2])) model = BatchNormalization()(inp) model = Bidirectional(LSTM(100, return_sequences=True, recurrent_dropout=0.1), merge_mode='concat')(model) model = Dropout(0.5)(model) model = Bidirectional(LSTM(100, return_sequences=True, recurrent_dropout=0.1), merge_mode='concat')(model) model = Dropout(0.5)(model) model = Bidirectional(LSTM(2, return_sequences=False, recurrent_dropout=0.1), merge_mode='ave')(model) model = Activation('softmax')(model) model = Model(inputs=[inp], outputs=[model]) model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['acc']) modelcheckpoint = ModelCheckpoint('model.weights', monitor='val_loss', verbose=1, save_best_only=True, mode='min') model.fit(x, yc, validation_data=(tx, tyc), epochs=100, batch_size=50, callbacks=[modelcheckpoint], verbose=2) model.load_weights('model.weights') return model
双方向ラッパーは、 merge_modeを使用して、通常の入力シーケンスの引数レイヤーの出力を逆順で接着します。 私たちの場合、これは100セルのLSTMレイヤーです。 return_sequencesフラグは、セルの内部状態のシーケンスを返すか、最後のセルのみを返すかを決定します。
LSTM内および繰り返しレイヤーの後にドロップアウトが適用され、最後のレイヤー( return_sequences = False )の後にsoftmaxアクティベーション関数があります。 また、モデルは、確率的勾配降下法の修正であるRmspropオプティマイザーでコンパイルします。 実際には、リカレントネットワークではより適切に機能することがよくありますが、これは厳密には証明されておらず、常に異なる場合があります。
filter_idx = pitch[:, 0] > 1 filtered_sequences_features, filtered_sequences_genders, filtered_sequences_speakers = make_sequences(features[filter_idx], genders[filter_idx], speakers[filter_idx], filenames[filter_idx]) score_lstmfiltered = subject_cross_validation('lstm', filtered_sequences_features, filtered_sequences_genders, filtered_sequences_speakers, 5) print score_lstm_filtered
やった! 99.1%が、スピーカーによる5倍交差検証でポイントを正しく分類しました。 これは、考慮されるすべてのアーキテクチャの中で最良の結果です。
おわりに
機械学習ガイド、記事、およびノンフィクション教材の大部分は、画像認識専用です。 まれに-強化トレーニング。 あまり一般的ではないのが音声処理です。 おそらく、これはおそらく、音声処理の「すぐに使える」方法が機能しないという事実によるものであり、プロセス、データの前処理、およびその他の避けられない反復を理解するのに時間を費やす必要があります。 しかし、タスクを面白くしているのは複雑さです。
性の認識は、人がほぼ正確に対処するため、単純な作業のようです。 しかし、機械学習の方法による「正面」のソリューションは、約70%の精度を実証していますが、これは客観的には小さいです。 ただし、すべてが正しく行われていれば、単純なアルゴリズムでも約97〜98%の精度を達成できます。たとえば、ソースデータを除外します。 高度なニューラルネットワークアプローチにより、精度が99%以上に向上します。これは、人間のパフォーマンスと基本的にほとんど変わりません。
実際、この記事のリカレントニューラルネットワークの可能性は完全には明らかにされていません。 分類タスク(1対多)でも、より効率的に使用できます。 しかし、もちろん、これはまだ行いません。 フレームをフィルタリングせずに行うことができるため、ネットワーク自体が必要なフレームのみを処理する方法を学習し、より長い(またはより短い、または間引かれた)シーケンスを考慮することができます。
材料に取り組んだ:
- Grigory Sterling 、数学者、機械学習とデータ分析のニューロデータラボエキスパート
- Eva Kazimirova 、生物学者、生理学者、音響学の分野のNeurodata Lab専門家、音声および音声信号の分析
私たちと一緒に。