少し前まで、Elasticsearchクラスターのリソース消費を最適化する問題を解決しました。 エラスティック自体の構成に失敗したため、「逆」検索またはパーコレーターと呼ばれるアプローチを使用して、検索結果のキャッシュのような処理を行いました。 カットの下で、メタデータメトリックとパーコレーター自体をどのように使用するかについてのストーリー。
私たちが開発している監視サービスの目的は、問題の原因を示すことです。そのため、クライアントインフラストラクチャのさまざまなサブシステムに関する多くの詳細なメトリックを削除します。
一方では、数千のホストから多数のメトリックを記録するという問題を解決します。他方では、メトリックはリポジトリ内で無重量ではなく、常に読み取られます。
- クライアントは、数千のメトリックを読み取ることができる描画中にチャートを見る
- 一般的な問題を検出するための多くの事前設定されたトリガーがあり、それぞれが常に多くのメトリックを読み取ることができます
メトリックとは何ですか?
okmeterの開発を始めたとき(当時、influxdbのパブリックバージョンはまだありませんでした)、メトリックが「フラット」であってはならないことがすぐにわかりました。 私たちの場合、メトリック識別子はキーと値のディクショナリです(私たちにとっては歴史的にlabel_setと呼ばれています)
{ "name": "nginx.requests.rate", "status": "403", "source_hostname": "front3", "file": "/var/log/access.log", "cache_status": "MISS", "url": "/order" }
このようなメトリックごとに、特定の時点(時系列)に関連付けられた値があります。
メトリックスを保存する方法
各メトリックのlabel_setからのハッシュに基づいて、文字列キーが計算され、これによりリポジトリ内のメトリックが識別されます。 そして、ここでは、キーによってメトリック値を保存するタスクと、メタメタ情報を保存および処理するタスクを分離します。

この記事ではメトリック値の保存については考慮しませんが、メタデータについて詳しく説明します。
メタメタデータは、キー自体、label_set、作成時間、更新時間、およびその他のサービスフィールドです。
この情報はcassandraに保存され、メトリックキーで受信できます。 メインのメタデータリポジトリに加えて、一部のユーザー検索クエリのメトリックキーのセットを返すインデックスがelasticsearchにあります。
記録メトリック
メトリックのパックがクライアントのサーバーにインストールされたエージェントから取得されると、各メトリックのサーバーで次のことが発生します。
metric_keyを計算し、このメトリックがメタ情報ストレージにあるかどうかを確認します(C *)
必要に応じて、新しいものを登録します(C *およびESに記録)
updated_tsを上げて、更新するかどうかを計算します(ESでのインデックス作成の負荷を軽減するために、12時間ごとに更新されます)
時間になったら-C *およびESでupdated_tsを更新します
- metric_storageに値を書き込む
指標の読み取り
メトリックを読み取るためのリクエストには、主に2つのソースがあります。グラフ化のためのユーザーリクエストとトリガー検証システムです。 このようなリクエストは、dslの一部の表現です。
top(5, sum_by(url, metric(name=“nginx.requests.rate”, status=“5*”)))
この式には以下が含まれます。
メトリックの「セレクタ」(メトリック()関数の引数)。これは、ユーザーが関心のあるすべてのメトリックを選択するための検索クエリです。 この場合、「nginx.requests.rate」という名前と「5」のプレフィックスを持つステータスラベルを持つすべてのメトリックを選択します(すべてのhttp-5xxエラーをカウントしたい)
- メトリック変換関数。 この場合、選択したすべてのメトリックを(合計で)URLラベルでグループ化し(たとえば、異なるサーバーまたはファイルからの値を合計します)、合計で上位5つのURLのみを取得し、ラベル「〜other」で値にテールを追加します
さらに、リクエストは常に特定の時間間隔で機能します:[since_ts = X、to_ts = Y]
メトリックセレクターはelasticsearchリクエストのようなものに変換されます(有効なjsonリクエストはより冗長です):
{"name": “nginx.requests.rate”, "status_prefix": "5", "created_lt": "Y", "updated_gt": "X+12h"}
N個(多くの場合数千個)のキーを取得しました
C *に移動して、キーでlabel_setsを受け取ります
metric_storageにアクセスして、キーでデータを受信します
- 式top(5、sum_by(...))を評価します
負荷とデータサイズ
現時点では、クラウドはレコードごとに1秒あたり10万以上のメトリックを処理しています。 Paskovyは平均で約350 rpsを要求します(トリガーの90%)。 各検索クエリは、1〜3個のESインデックス用で、各インデックスは100ミリン文書(〜30 GB)までです。
同時に、CPUエラスティックの消費により、ホスティングに費やされたお金を考慮する誰もが無関心になることはありません。
Elasticsearch
リクエストが繰り返される場合に備えて、組み込みのクエリキャッシュが作成されたことを期待して、elasticsearch設定を変更しようとしました。 これらの要求のキャッシュ無効化を防ぐために、一部の要求に対して更新が行われないインデックスをシミュレートしようとしました。
しかし、残念なことに、私たちのすべてのエクササイズは、消費されるリソースの減少も、エラスティックの応答時間の短縮ももたらしませんでした。
外部キャッシュ
ESの外部に検索結果のキャッシュを作成することを決定し、ESに関する次の要件を策定しました。
検索は常に時間間隔で行われます
着信を停止するメトリックはキャッシュから出るはずです
- 新しいメトリックは1分以内に検索結果に表示されるはずです
このような要件がある場合、ヒットレートがないことは明らかですが、ESレスポンスを1分間だけキャッシュすることができます。 その結果、キャッシュを行わないという結論に達しましたが、既知の各検索クエリの検索結果を含む実体化された表現のようなものです。
パーコレーター
アイデアは、メトリックの各レコードで、どの既知の検索クエリが一致するかをチェックするというものでした。 偶然の場合、メトリックはキャッシュに書き込まれます。
このようなアプローチは、 「前向き検索」、別名「逆検索」、別名「パーコレーター」と呼ばれます。
私が理解しているように、ここではプロセスの類似性のために「パーコレーション」という用語が使用されます。多くの検索クエリを通じてドキュメントの「フロー」を確認します。
通常の検索問題では、ドキュメントがあり、それらからインデックスを構築します。インデックスは、(非常に単純化された)各「単語」がこの単語が出現するドキュメントのリストに対応します。

パーコレーションの場合、以前に既知の検索クエリがあり、各ドキュメントは検索クエリです。
パーコレーターの実装:
- elasticsearchにパーコレートクエリがあります
- solrにはオープンチケットがあります。いつか完成するでしょう
- Luwak -LuceneベースのJava用ライブラリ
- Google App Engine Prospective Search APIはGAE向けのサービスですが、既に廃止されています
パーコレーターが将来のドキュメントの構造を記述する特別なタイプのインデックスであるelasticsearchのみを考慮しました:ドキュメントが持つフィールドの種類とそのタイプ(マッピング)。 このインデックスにさらにリクエストを保存し、その後ドキュメントを入力に送信して検索します。
ES内では、各パーコレーションリクエストで、一時インデックスがメモリに作成されます。これは、提出した1つのドキュメントのみで構成されています。 保存されたすべてのクエリのうち、明らかにフィールドセットドキュメントに適さないクエリは破棄されます。 次に、残りの候補リクエストごとに、一時インデックスによって検索が実行されます。
単純なベンチマークでは、パーコレーターでの1つの要求への準拠について1つのドキュメントをチェックするために2〜10ミリ秒を受け取りました。 ドキュメントのストリームでは、これは非常に高価になります。 さらに、elasticsearchを「クック」する方法を学んだことはありません。
自家製ナイーブパーコレーター
メトリックに戻りましょう。 上で言ったように、私たちのドキュメントはキーバリュー辞書です。 検索クエリは、完全一致またはプレフィックスフィールドの一致による検索です。 つまり、そのため、全文検索は必要ありません。
パーコレーターの「単純な」実装、つまり、額の既知のすべての要求に対する各メトリックの対応を確認することにしました。 1秒あたり約10万メトリックの書き込みストリームがあり、各メトリックは約100クエリに準拠しているかどうかを確認する必要があります。
1つのチェックのベンチマーク(このコードの一部はgolangで動作し、プロトタイプを作成しました)は約300nsを示しました。 これは完全にCPUにバインドされたタスクであるため、時間を合計する権利があります。
100k * 100 = 10M
10M * 300ns = 3 = 3
キャッシュのロジックは次のようなものでした:

メトリックを記録するプロセスに追加の手順が追加されました。
- このクライアントの保存されたすべてのリクエストをCから発生させます*
- リクエストごとに一致する各メトリックをチェックします
- 一致した場合、メトリックに関するメタ情報をキャッシュに書き込むと、同じメトリックをキャッシュに何度も書き込むことができます(キャッサンダーは重複を削除します)
新しいリクエストを登録した後、そのリクエストのキャッシュがすぐに有効にならないことに注意してください。 すでに開始されていて、既知の要求のリストに新しい要求が表示されていない書き込み要求が終了するまで待機する必要があります。 したがって、メトリックの書き込み要求のタイムアウトまでにキャッシュの初期化を延期します。
キャッシュはどのように配置されますか?
キャッシュをcassandraに保存します。各リクエストの結果は時間ごとに分割されます(各ピースは24時間です)。 これは、結果から停止したメトリックが確実に洗い落とされるようにするために行われます。
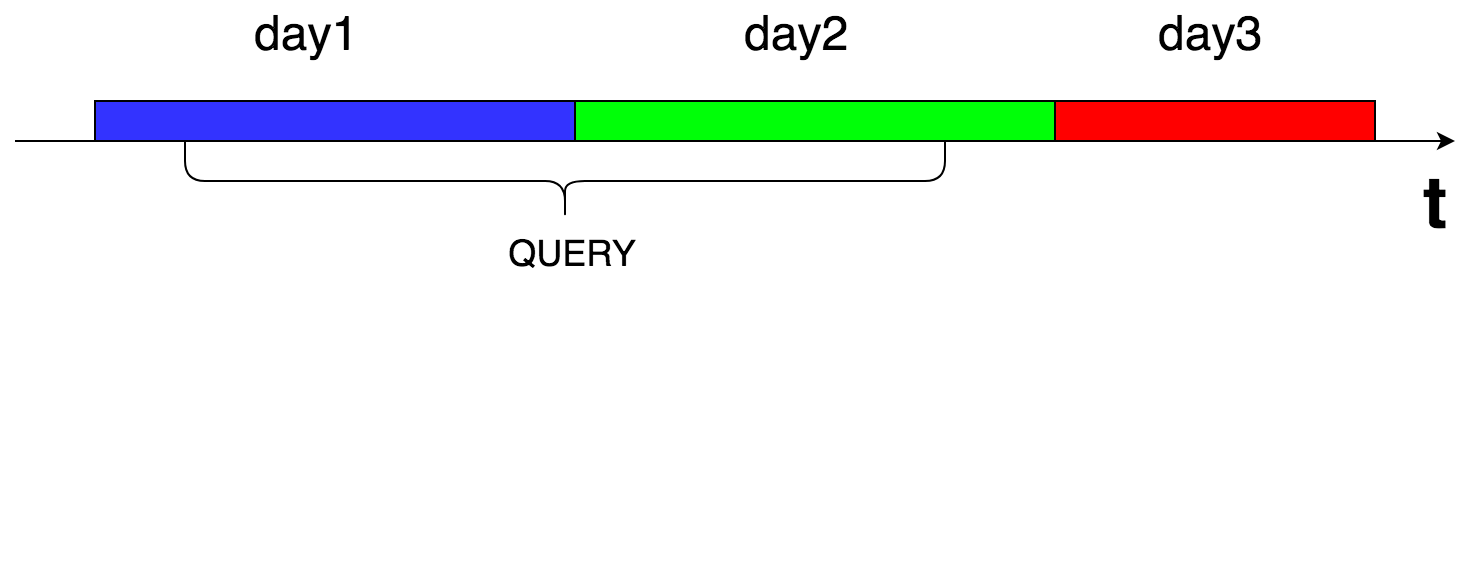
リクエストに応じて、関心のある時間間隔に該当する毎日のチャンクをすべて減算し、結果をメモリに結合します。
値は、メトリックキーディクショナリとlabel_setのjson表現です。 したがって、キャッシュからの結果を使用する場合、ESから結果を受信した後に行ったように、キーごとのメトリックデータについてもcassandraに追加で移動する必要はありません。
生産で展開
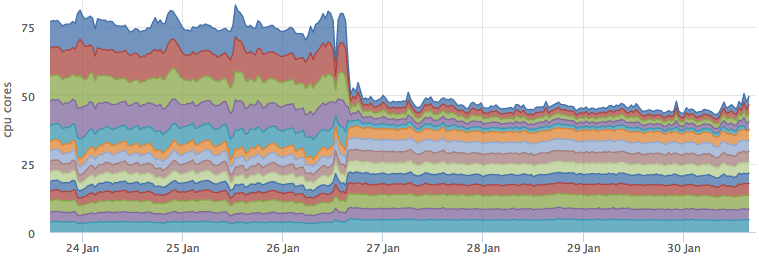
キャッシュをバトルに展開し、ほとんどのリクエストで有効になった後、ESの負荷が大幅に低下しました。
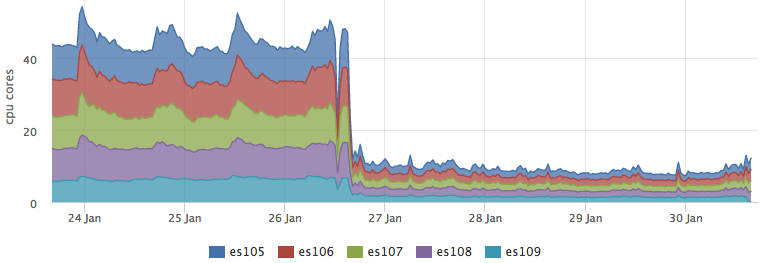
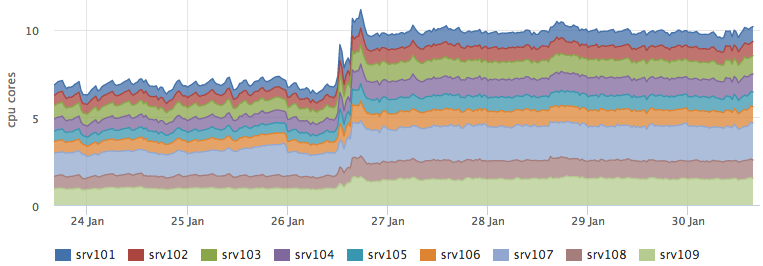
同時に、cassandraによるリソースの消費は変更されていません。
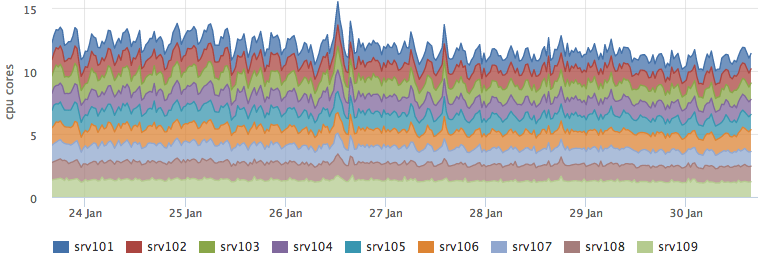
そして、パーコレーションを実行するバックエンドは、予測された〜3コアだけ成長しました。
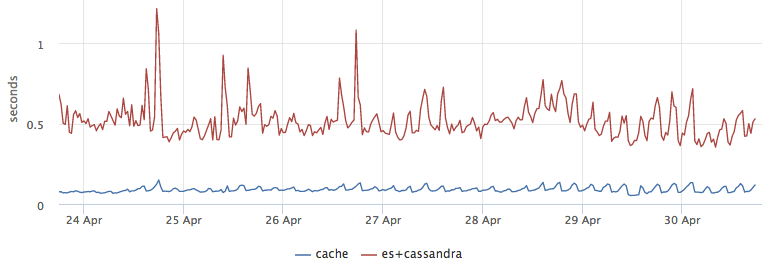
おまけとして、キャッシュからの結果がESに移動してからCからメタ情報を取得するよりも5倍高速であることが判明したため、優れたレイテンシ最適化が得られました。
一貫性チェック
キャッシュロジックを混乱させないように、最初の数日間は検索結果をESとキャッシュの両方で調べ、結果を比較して適切なメトリックを作成しました。 負荷をキャッシュに切り替えた後、キャッシュ検証ロジックをカットアウトせず、リクエストの1%に対してESで投機的なリクエストを行いました。 同じリクエストはESにとっても「ウォーマー」です。そうしないと、ロードインデックスがなければページキャッシュに入らず、ユーザーリクエストはバカになります。
合計
外部キャッシュを作成するのではなく、ESが内部キャッシュを使用するように強制しました。 しかし、私はサイクリングに対処しなければなりませんでした。 しかし、プラスもあります。パーコレーターに追加のロジックを掛けます。
結果によると、私たちは腺でかなりうまくいきましたが、自家製のパーコレーターは非常にうまくスケーリングします。 これは、クライアントの数と各クライアントサーバーからのメトリックの数の両方で急速に成長しているため、私たちにとって十分に重要です。