最近、 @ FakeUnicodeからこのツイートに出会いました 。 非常に無害に見えるが、隠されたメッセージを表示するJavaScriptスニペットがありました。 何が起こっているのか理解するのにしばらく時間がかかりました。 私の調査のステップを記録することは、誰かにとって興味深いかもしれないと思います。
以下がそのスニペットです。

彼に何を期待しますか?
これは
for in
ループを使用し、オブジェクトの列挙されたプロパティを調べます。 プロパティ
A
のみ
A
指定されているため、文字
メッセージが表示されると想定できます。 まあ...私は間違っていました。 :D
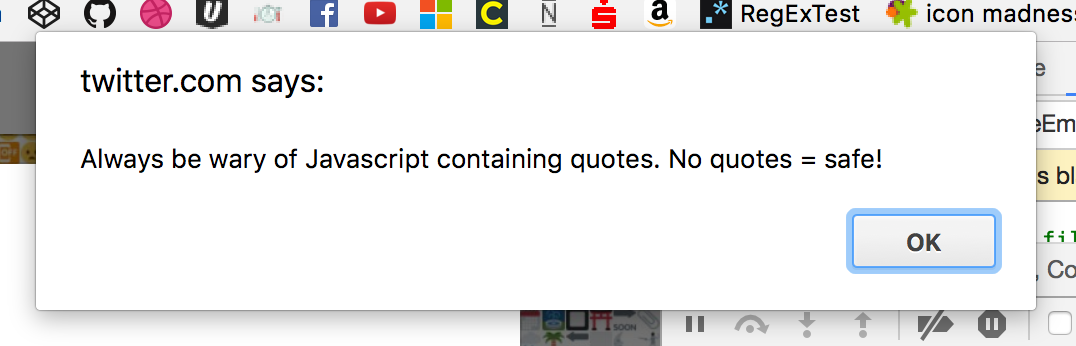
これには驚いたので、Chromeコンソールからデバッグを開始しました。
非表示の文字コードを開く
最初にしたことは、スニペットを単純化することでした。
for(A in {A:0}){console.log(A)}; // A
うーん...大丈夫、ここに何もない、先に進みましょう。
for(A in {A:0}){console.log(escape(A))}; // A%uDB40%uDD6C%uDB40%uDD77%uDB40%uDD61%uDB40%uDD79%uDB40%uDD73%uDB40%uDD20%uDB40%uDD62%uDB40%uDD65%uDB40%uDD20%uDB40%uDD77%uDB40%uDD61%uDB40%uDD72%uDB40%uDD79%uDB40%uDD20%uDB40%uDD6F%uDB40%uDD66%uDB40%uDD20%uDB40%uDD4A%uDB40%uDD61%uDB40%uDD76%uDB40%uDD61%uDB40%uDD73%uDB40%uDD63%uDB40%uDD72%uDB40%uDD69%uDB40%uDD70%uDB40%uDD74%uDB40%uDD20%uDB40%uDD63%uDB40%uDD6F%uDB40%uDD6E%uDB40%uDD74%uDB40%uDD61%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD67%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD2E%uDB40%uDD20%uDB40%uDD4E%uDB40%uDD6F%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD20%uDB40%uDD3D%uDB40%uDD20%uDB40%uDD73%uDB40%uDD61%uDB40%uDD66%uDB40%uDD65%uDB40%uDD21
神の母! どこから来たの?
私は一歩下がって、文字列の長さを見なければなりませんでした。

面白い。 次に、オブジェクトから
をコピーしまし
すぐに、Chromeコンソールが何か隠された状態で動作していることに気付きました。カーソルが「フリーズ」し、左右のいくつかのキーストロークに反応しなかったからです。
しかし、中身を見て、129個すべてのコードユニットの値を取得してみましょう。

ここでは、コード単位の値が
65
の文字
に続いて、55千から56千の領域にいくつかのコード単位があり、
console.log
よく知られている疑問符で視覚化されています。 これは、システムがこのコード単位を処理する方法を知らないことを意味します。
JavaScriptのサロゲートペア
これらの値は、いわゆるサロゲートペアの一部です。 サロゲートペアは 、16ビットを超える値を持つコードポイント(つまり、
65536
を超えるコードポイント)です。 Unicode自体が1,114,122の異なるコードポイントを定義し、JavaScriptがUTF-16文字列形式を持っているため、これが必要です。 つまり、最初の65536個のUnicodeコードポイントのみがJavaScriptコードユニットの1つの要素として表現できます。
クレイジーな数式をペアに適用することで、より大きな値を計算できます。その結果、値は
65536
超えます。
無作法な挿入:このトピックについて具体的に説明しました。これは、コードポイント、絵文字、サロゲートペアの概念を理解するのに役立ちます。
そのため、129個のコードユニットが見つかりました。そのうち128個は64個のコードポイントを表すサロゲートペアです。 それでは、これらのコードポイントは何ですか?
文字列からコードポイント値を取得するには、文字列のコードポイント(最初の
for
ループのようなコード単位ではない)を実行する
for
ループと、
for of
使用される
...
演算子が非常に便利
for of
。

console.log
はこれらのコードポイントを表示する方法すら知らないので、何を扱っているかを自分で把握する必要があります。

注:JavaScriptには、コード単位とコードポイントcharCodeAtおよびcodePointAtを処理するための2つの関数があることに注意してください。 動作が少し異なるため、注意してください。
JavaScriptオブジェクトの識別子名
コードポイント
917868
以降は、
917879
Variation Selectors Supplementの一部です。 Unicodeのバリアントセレクタは、数学記号、絵文字、モンゴルの四角文字、および互換性のある東洋の表意文字に対応する東洋の単一表意文字の標準化されたバリアントシーケンスを示すために使用されます。 通常、それらは単独では使用されません。
素晴らしいですが、それは何と関係がありますか?
ECMAScript仕様を見ると、プロパティ識別子の名前には「通常の文字」以外のものを含めることができます。
Identifier :: IdentifierName but not ReservedWord IdentifierName :: IdentifierStart IdentifierName IdentifierPart IdentifierStart :: UnicodeLetter $ _ \ UnicodeEscapeSequence IdentifierPart :: IdentifierStart UnicodeCombiningMark UnicodeDigit UnicodeConnectorPunctuation <ZWNJ> <ZWJ>
ご覧のとおり、識別子は
IdentifierName
と
IdentifierPart
構成できます。
IdentifierPart
の定義は重要です。 識別子の最初の文字に加えて、他のすべての名前は完全に有効です。
const examples = { // UnicodeCombiningMark example somethingî: 'LATIN SMALL LETTER I WITH CIRCUMFLEX', somethingi\u0302: 'I + COMBINING CIRCUMFLEX ACCENT', // UnicodeDigit example something١: 'ARABIC-INDIC DIGIT ONE', something\u0661: 'ARABIC-INDIC DIGIT ONE', // UnicodeConnectorPunctuation example something﹍: 'DASHED LOW LINE', something\ufe4d: 'DASHED LOW LINE', // ZWJ and ZWNJ example something\u200c: 'ZERO WIDTH NON JOINER', something\u200d: 'ZERO WIDTH JOINER' }
したがって、この式を計算すると、次の結果が得られます。
{ somethingî: "ARABIC-INDIC DIGIT ONE", somethingî: "I + COMBINING CIRCUMFLEX ACCENT", something١: "ARABIC-INDIC DIGIT ONE" something﹍: "DASHED LOW LINE", something: "ZERO-WIDTH NON-JOINER", something: "ZERO-WIDTH JOINER" }
これは私をその日のメインのオープニングに導いた 。
ECMAScript仕様によると:
Unicode標準と標準的に同等の2つのIdentifierNameは、同じコードユニットのシーケンスで正確に表されるまで同じではありません。
つまり、オブジェクト識別子の2つのキーはまったく同じように見えても、異なるコード単位で構成されている可能性があります。つまり、両方がオブジェクトに含まれます。 シンボル
î
場合と同様に、これは値
00ee
コード単位とサーカムフレックス
COMBINING CIRCUMFLEX ACCENT
シンボル
i
対応します。 したがって、これは同じものではなく、doubleプロパティがオブジェクトに含まれています。 Zero-Width joinerまたはZero-Width non-joinerの文字についても同じです。 同じように見えますが、違います!
しかし、トピックに戻ります。バリアントセレクターの見つかった値は、
UnicodeCombiningMark
カテゴリーに属し、有効な識別子名になります(たとえ非表示であっても)。 高い確率で、有効な組み合わせで使用された場合にのみ結果が表示されるため、これらは見えません。
エスケープ関数と文字列の置換
escape
関数は、すべてのコードユニットを
escape
し、それらをエスケープとして扱います 。 つまり、彼女は最初の文字
とサロゲートペアのすべての部分を受け取り、それらを再び文字列に変換します。 目に見えない値は「文字列形式に変換」されます。 したがって、記事の冒頭で見た長いシーケンスが表示されます。
A%uDB40%uDD6C%uDB40%uDD77%uDB40%uDD61%uDB40%uDD79%uDB40%uDD73%uDB40%uDD20%uDB40%uDD62%uDB40%uDD65%uDB40%uDD20%uDB40%uDD77%uDB40%uDD61%uDB40%uDD72%uDB40%uDD79%uDB40%uDD20%uDB40%uDD6F%uDB40%uDD66%uDB40%uDD20%uDB40%uDD4A%uDB40%uDD61%uDB40%uDD76%uDB40%uDD61%uDB40%uDD73%uDB40%uDD63%uDB40%uDD72%uDB40%uDD69%uDB40%uDD70%uDB40%uDD74%uDB40%uDD20%uDB40%uDD63%uDB40%uDD6F%uDB40%uDD6E%uDB40%uDD74%uDB40%uDD61%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD69%uDB40%uDD6E%uDB40%uDD67%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD2E%uDB40%uDD20%uDB40%uDD4E%uDB40%uDD6F%uDB40%uDD20%uDB40%uDD71%uDB40%uDD75%uDB40%uDD6F%uDB40%uDD74%uDB40%uDD65%uDB40%uDD73%uDB40%uDD20%uDB40%uDD3D%uDB40%uDD20%uDB40%uDD73%uDB40%uDD61%uDB40%uDD66%uDB40%uDD65%uDB40%uDD21
秘 Theは、 @ FakeUnicodeが特定のバリアントセレクター(実際のキャラクターに送り返す番号で終わるセレクター)を選択したことです。 例を見てみましょう。
// a valid surrogate pair sequence '%uDB40%uDD6C'.replace(/u.{8}/g,[]); // %6C 6C (hex) === 108 (dec) LATIN SMALL LETTER L unescape('%6C') // 'l'
この例で唯一のものは、空の配列
[]
を置換文字列として使用することは少し理解しにくいままです。
toString()
を介して、つまり
''
変換されて評価されます。
空の文字列もその役割を果たします。 ポイント
[]
は、この方法で、引用フィルターなどをバイパスできることです。
これにより、メッセージ全体を非表示の文字でエンコードできます。
一般的な機能
もう一度例を見ると:

次のことが起こります。
-
A:0
ここA
は多くの「隠しコード単位」が含まれます - これらの文字は
escape
表示されます - マッピングは
replace
を使用しreplace
行われます - 結果は再びエスケープ解除され、通知ウィンドウに表示する準備ができます
かなりクールだと思います!
追加のリソース
この小さな例は、多くのUnicodeトピックをカバーしています。 さらに詳しく知りたい場合は、 Matthias BinensのUnicodeおよびJavaScriptの記事を読むことを強くお勧めします。